利用Python机器学习框架scikit-learn,我们自己做一个分类模型,对中文评论信息做情感分析。其中还会介绍中文停用词的处理方法。

疑惑
前些日子,我在微信后台收到了一则读者的留言。

我一下子有些懵——这怎么还带点播了呢?
但是旋即我醒悟过来,好像是我自己之前挖了个坑。
之前我写过《 如何用Python从海量文本抽取主题? 》一文,其中有这么一段:
为了演示的流畅,我们这里忽略了许多细节。很多内容使用的是预置默认参数,而且完全忽略了中文停用词设置环节,因此“这个”、“如果”、“可能”、“就是”这样的停用词才会大摇大摆地出现在结果中。不过没有关系,完成比完美重要得多。知道了问题所在,后面改进起来很容易。有机会我会写文章介绍如何加入中文停用词的去除环节。
根据“自己挖坑自己填”的法则,我决定把这一部分写出来。
我可以使用偷懒的办法。
例如在原先的教程里,更新中文停用词处理部分,打个补丁。
但是,最近我发现,好像至今为止,我们的教程从来没有介绍过如何用机器学习做情感分析。
你可能说,不对吧?
情感分析不是讲过了吗?老师你好像讲过《 如何用Python做情感分析? 》,《 如何用Python做舆情时间序列可视化? 》和《 如何用Python和R对《权力的游戏》故事情节做情绪分析? 》。
你记得真清楚,提出表扬。
但是请注意,之前这几篇文章中,并没有使用机器学习方法。我们只不过调用了第三方提供的文本情感分析工具而已。
但是问题来了,这些第三方工具是在别的数据集上面训练出来的,未必适合你的应用场景。
例如有些情感分析工具更适合分析新闻,有的更善于处理微博数据……你拿过来,却是要对店铺评论信息做分析。
这就如同你自己笔记本电脑里的网页浏览器,和图书馆电子阅览室的网页浏览器,可能类型、版本完全一样。但是你用起自己的浏览器,就是比公用电脑上的舒服、高效——因为你已经根据偏好,对自己浏览器上的“书签”、“密码存储”、“稍后阅读”都做了个性化设置。
咱们这篇文章,就给你讲讲如何利用Python和机器学习,自己训练模型,对中文评论数据做情感分类。
# 数据
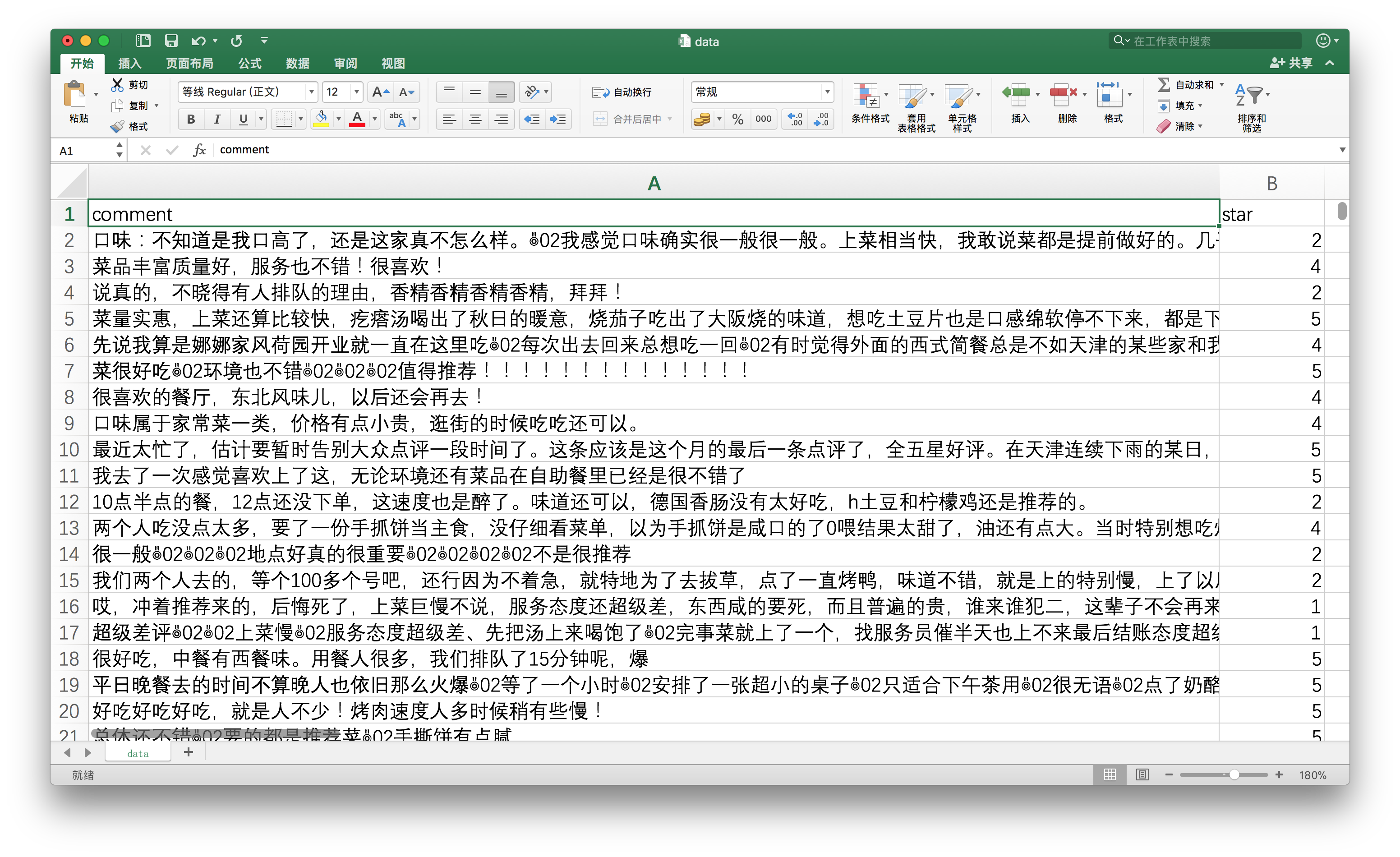
我的一个学生,利用爬虫抓取了大众点评网站上的数万条餐厅评论数据。
这些数据在爬取时,包含了丰富的元数据类型。
我从中抽取了评论文本和评星(1-5星),用于本文的演示。
从这些数据里,我们随机筛选评星为1,2,4,5的,各500条评论数据。一共2000条。
为什么只甩下评星数量为3的没有选择?
你先思考10秒钟,然后往下看,核对答案。
答案是这样的:
因为我们只希望对情感做出(正和负)二元分类,4和5星可以看作正向情感,1和2是负向情感……3怎么算?
所以,为了避免这种边界不清晰造成的混淆,咱们只好把标为3星的内容丢弃掉了。
整理好之后的评论数据,如下图所示。
我已经把数据放到了演示文件夹压缩包里面。后文会给你提供下载路径。
模型
使用机器学习的时候,你会遇到模型的选择问题。
例如,许多模型都可以用来处理分类问题。逻辑回归、决策树、SVM、朴素贝叶斯……具体到咱们的评论信息情感分类问题,该用哪一种呢?
幸好,Python上的机器学习工具包 scikit-learn 不仅给我们提供了方便的接口,供我们调用,而且还非常贴心地帮我们做了小抄(cheat-sheet)。
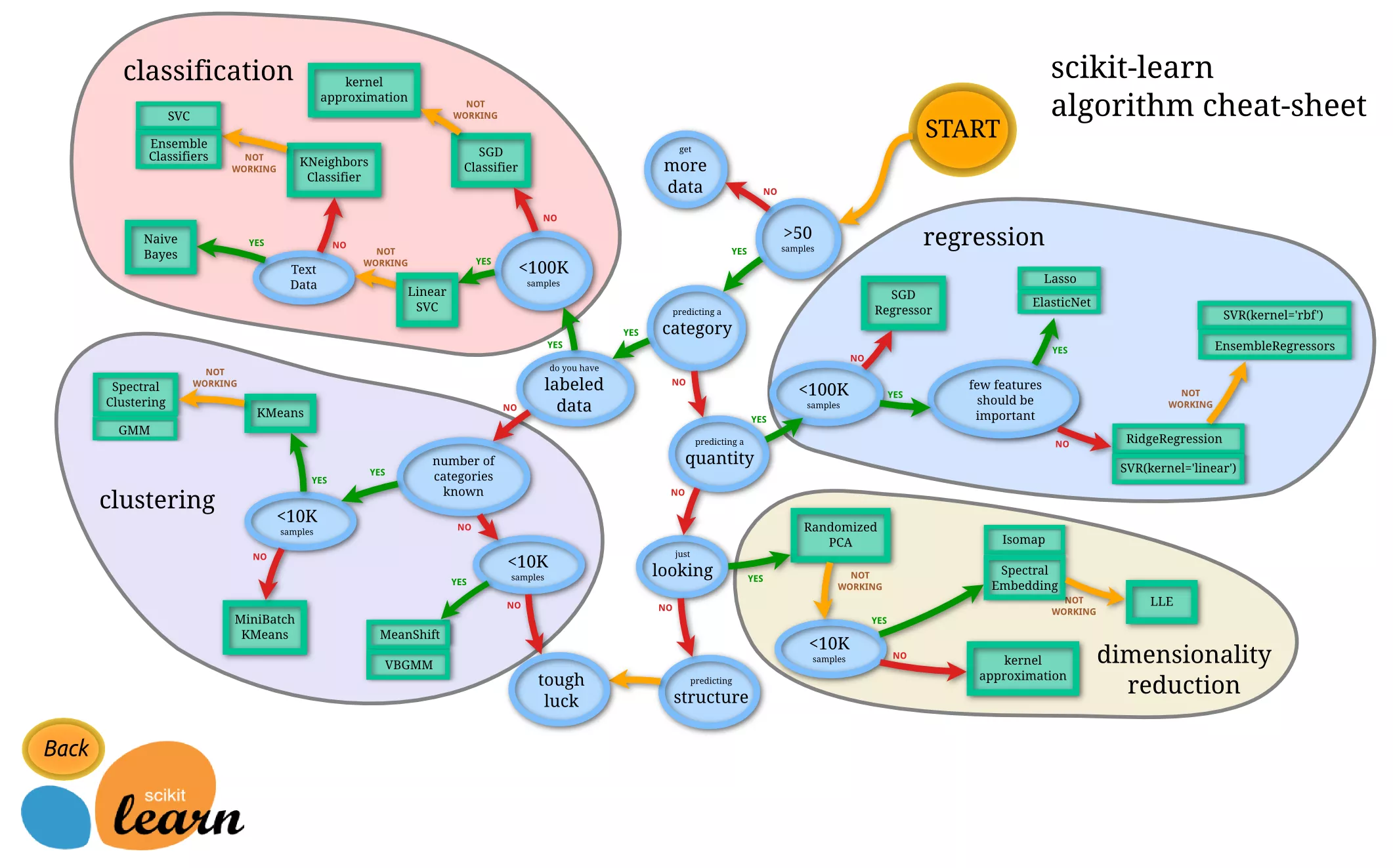
这张图看似密密麻麻,非常混乱,实际上是一个非常好的迷宫指南。其中绿色的方框,是各种机器学习模型。而蓝色的圆圈,是你做判断的地方。
你看,咱们要处理类别问题,对吧?
顺着往下看,会要求你判断数据是否有标记。我们有啊。
继续往下走,数据小于100K吗?
考虑一下,我们的数据有2000条,小于这个阈值。
接下来问是不是文本数据?是啊。
于是路径到了终点。
Scikit-learn告诉我们:用朴素贝叶斯模型好了。
小抄都做得如此照顾用户需求,你对scikit-learn的品质应该有个预期了吧?如果你需要使用经典机器学习模型(你可以理解成深度学习之外的所有模型),我推荐你先尝试scikit-learn 。
向量化
《 如何用Python从海量文本抽取主题? 》一文里,我们讲过自然语言处理时的向量化。
忘了?
没关系。
子曰:
学而时习之,不亦乐乎?
这里咱们复习一下。
对自然语言文本做向量化(vectorization)的主要原因,是计算机看不懂自然语言。
计算机,顾名思义,就是用来算数的。文本对于它(至少到今天)没有真正的意义。
但是自然语言的处理,是一个重要问题,也需要自动化的支持。因此人就得想办法,让机器能尽量理解和表示人类的语言。
假如这里有两句话:
I love the game.
I hate the game.
那么我们就可以简单粗暴地抽取出以下特征(其实就是把所有的单词都罗列一遍):
- I
- love
- hate
- the
- game
对每一句话,都分别计算特征出现个数。于是上面两句话就转换为以下表格:

按照句子为单位,从左到右读数字,第一句表示为[1, 1, 0, 1, 1],第二句就成了[1, 0, 1, 1, 1]。
这就叫向量化。
这个例子里面,特征的数量叫做维度。于是向量化之后的这两句话,都有5个维度。
你一定要记住,此时机器依然不能理解两句话的具体含义。但是它已经尽量在用一种有意义的方式来表达它们。
注意这里我们使用的,叫做“一袋子词”(bag of words)模型。
下面这张图(来自 https://goo.gl/2jJ9Kp ),形象化表示出这个模型的含义。
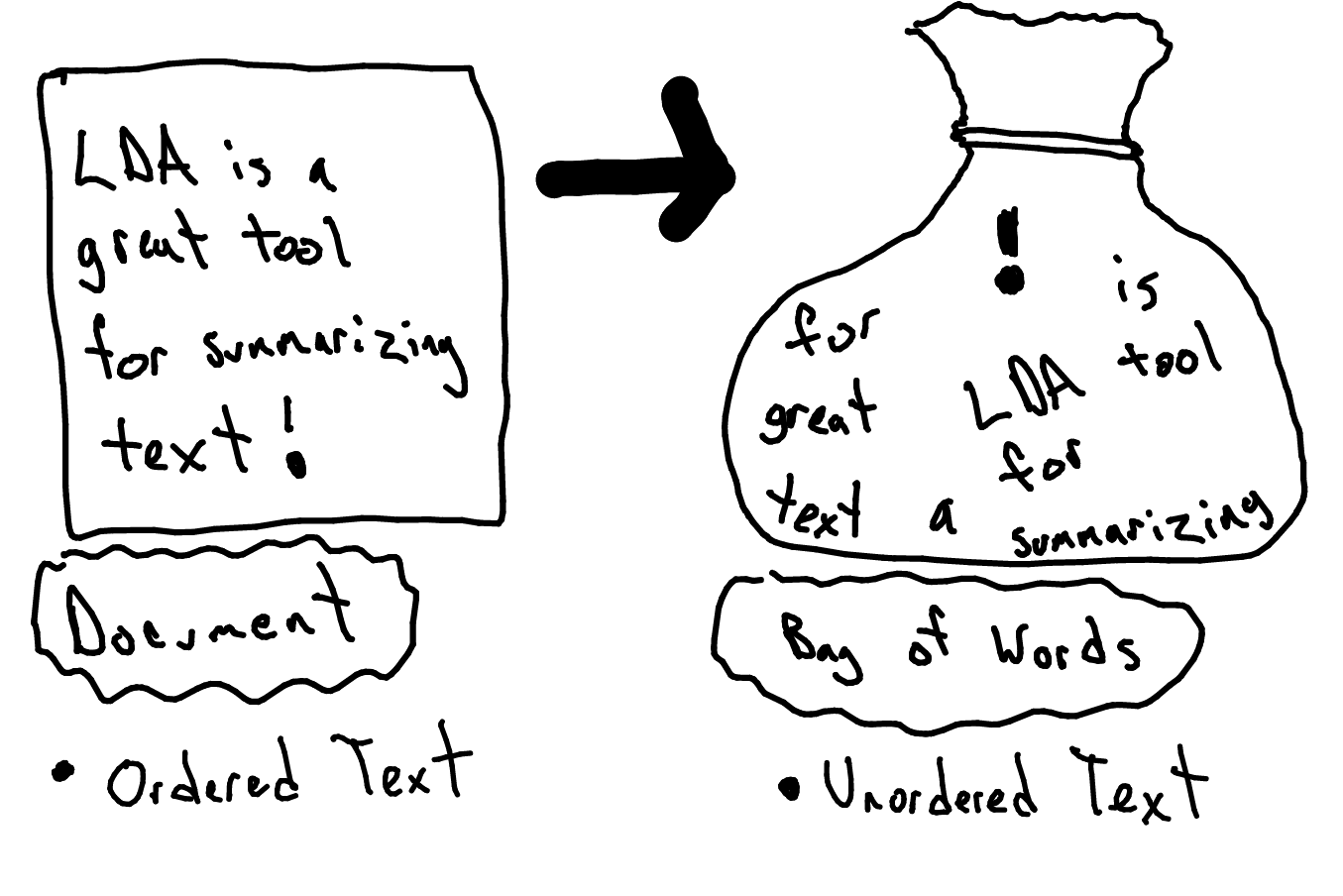
一袋子词模型不考虑词语的出现顺序,也不考虑词语和前后词语之间的连接。每个词都被当作一个独立的特征来看待。
你可能会问:“这样不是很不精确吗?充分考虑顺序和上下文联系,不是更好吗?”
没错,你对文本的顺序、结构考虑得越周全,模型可以获得的信息就越多。
但是,凡事都有成本。只需要用基础的排列组合知识,你就能计算出独立考虑单词,和考虑连续n个词语(称作 n-gram),造成的模型维度差异了。
为了简单起见,咱们这里还是先用一袋子词吧。有空我再给你讲讲……
打住,不能再挖坑了。
中文
上一节咱们介绍的,是自然语言向量化处理的通则。
处理中文的时候,要更加麻烦一些。
因为不同于英文、法文等拉丁语系文字,中文天然没有空格作为词语之间的分割符号。
我们要先将中文分割成空格连接的词语。
例如把:
“我喜欢这个游戏”
变成:
“我 喜欢 这个 游戏”
这样一来,就可以仿照英文句子的向量化,来做中文的向量化了。
你可能担心计算机处理起中文的词语,跟处理英文词语有所不同。
这种担心没必要。
因为咱们前面讲过,计算机其实连英文单词也看不懂。
在它眼里,不论什么自然语言的词汇,都只是某种特定组合的字符串而已。
不论处理中文还是英文,都需要处理的一种词汇,叫做停用词。
中文维基百科里,是这么定义停用词的:
在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。
咱们做的,不是信息检索,而已文本分类。
对咱们来说,你不打算拿它做特征的单词,就可以当作停用词。
还是举刚才英文的例子,下面两句话:
I love the game.
I hate the game.
告诉我,哪些是停用词?
直觉会告诉你,定冠词 the 应该是。
没错,它是虚词,没有什么特殊意义。
它在哪儿出现,都是一个意思。
一段文字里,出现很多次定冠词都很正常。把它和那些包含信息更丰富的词汇(例如love, hate)放在一起统计,就容易干扰我们把握文本的特征。
所以,咱们把它当作停用词,从特征里面剔除出去。
举一反三,你会发现分词后的中文语句:
“我 喜欢 这个 游戏”
其中的“这个”应该也是停用词吧?
答对了!
要处理停用词,怎么办呢?当然你可以一个个手工来寻找,但是那显然效率太低。
有的机构或者团队处理过许多停用词。他们会发现,某种语言里,停用词是有规律的。
他们把常见的停用词总结出来,汇集成表格。以后只需要查表格,做处理,就可以利用先前的经验和知识,提升效率,节约时间。
在scikit-learn中,英语停用词是自带的。只需要指定语言为英文,机器会帮助你自动处理它们。
但是中文……
scikit-learn开发团队里,大概缺少足够多的中文使用者吧。
好消息是,你可以使用第三方共享的停用词表。
这种停用词表到哪里下载呢?
我已经帮你找到了 一个 github 项目 ,里面包含了4种停用词表,来自哈工大、四川大学和百度等自然语言处理方面的权威单位。
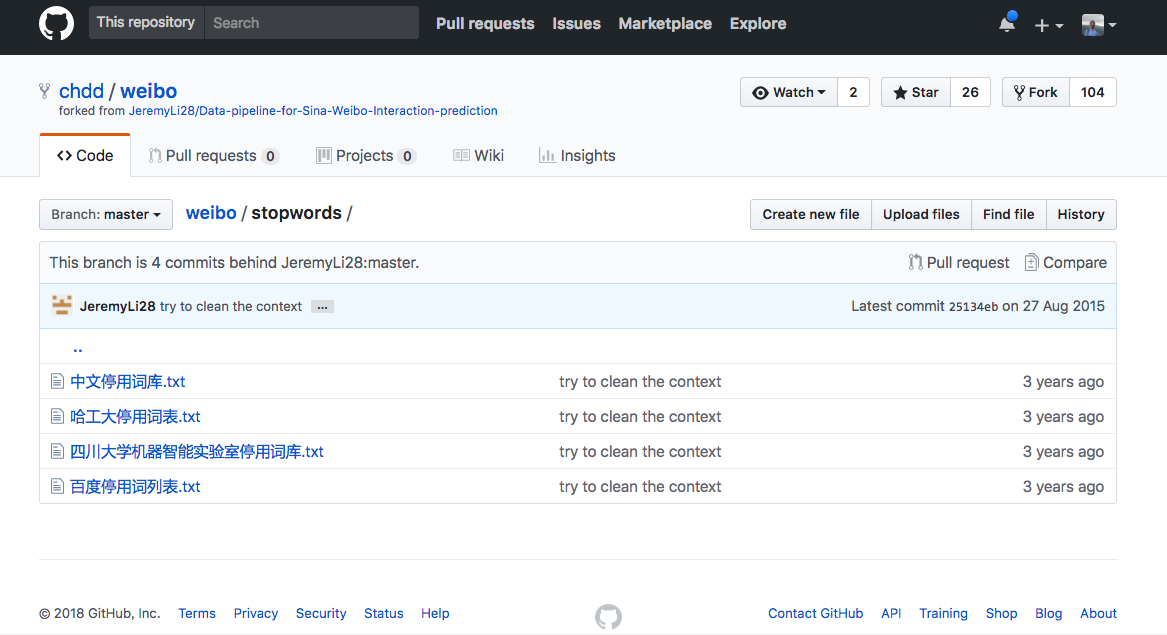
这几个停用词表文件长度不同,内容也差异很大。为了演示的方便与一致性,咱们统一先用哈工大这个停用词表吧。
我已经将其一并存储到了演示目录压缩包中,供你下载。
# 环境
请你先到 这个网址 下载本教程配套的压缩包。
下载后解压,你会在生成的目录里面看到以下4个文件。
下文中,我们会把这个目录称为“演示目录”。
请一定注意记好它的位置哦。
要装Python,最简便办法是安装Anaconda套装。
请到 这个网址 下载Anaconda的最新版本。
请选择左侧的 Python 3.6 版本下载安装。
如果你需要具体的步骤指导,或者想知道Windows平台如何安装并运行Anaconda命令,请参考我为你准备的 视频教程 。
打开终端,用cd命令进入演示目录。如果你不了解具体使用方法,也可以参考 视频教程 。
我们需要使用许多软件包。如果每一个都手动安装,会非常麻烦。
我帮你做了个虚拟环境的配置文件,叫做environment.yaml ,也放在演示目录中。
请你首先执行以下命令:
conda env create -f environment.yaml
这样,所需的软件包就一次性安装完毕了。
之后执行,
source activate datapy3
进入这个虚拟环境。
注意一定要执行下面这句:
python -m ipykernel install --user --name=datapy3
只有这样,当前的Python环境才会作为核心(kernel)在系统中注册。
确认你的电脑上已经安装了 Google Chrome 浏览器。如果没有安装请到这里 下载 安装。
之后,在演示目录中,我们执行:
jupyter notebook
Google Chrome会开启,并启动 Jupyter 笔记本界面:
你可以直接点击文件列表中的demo.ipynb文件,可以看到本教程的全部示例代码。
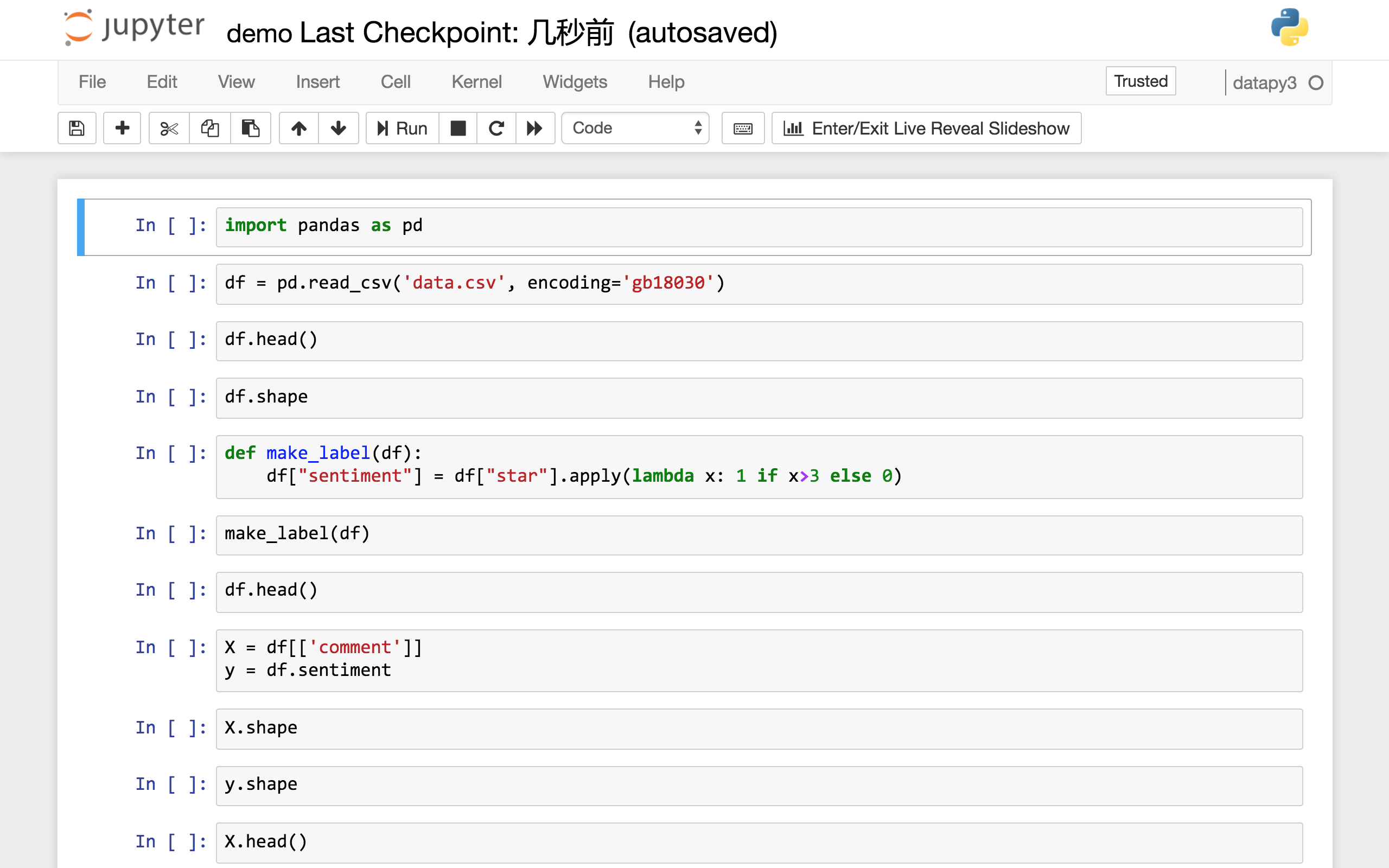
你可以一边看教程的讲解,一边依次执行这些代码。
但是,我建议的方法,是回到主界面下,新建一个新的空白 Python 3 (显示名称为datapy3的那个)笔记本。
请跟着教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含义,更高效地把技能内化。
准备工作结束,下面我们开始正式输入代码。
代码
我们读入数据框处理工具pandas。
import pandas as pd
利用pandas的csv读取功能,把数据读入。
注意为了与Excel和系统环境设置的兼容性,该csv数据文件采用的编码为GB18030。这里需要显式指定,否则会报错。
df = pd.read_csv('data.csv', encoding='gb18030')
我们看看读入是否正确。
df.head()
前5行内容如下:

看看数据框整体的形状是怎么样的:
df.shape
(2000, 2)
我们的数据一共2000行,2列。完整读入。
我们并不准备把情感分析的结果分成4个类别。我们只打算分成正向和负向。
这里我们用一个无名函数来把评星数量>3的,当成正向情感,取值为1;反之视作负向情感,取值为0。
def make_label(df):
df["sentiment"] = df["star"].apply(lambda x: 1 if x>3 else 0)
编制好函数之后,我们实际运行在数据框上面。
make_label(df)
看看结果:
df.head()
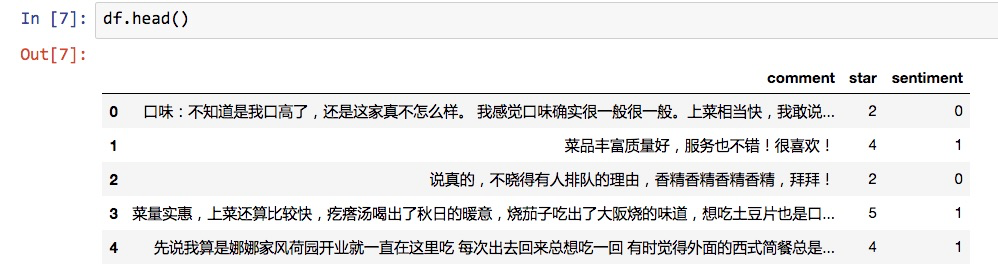
从前5行看来,情感取值就是根据我们设定的规则,从评星数量转化而来。
下面我们把特征和标签拆开。
X = df[['comment']]
y = df.sentiment
X 是我们的全部特征。因为我们只用文本判断情感,所以X实际上只有1列。
X.shape
(2000, 1)
而y是对应的标记数据。它也是只有1列。
y.shape
(2000,)
我们来看看 X 的前几行数据。
X.head()
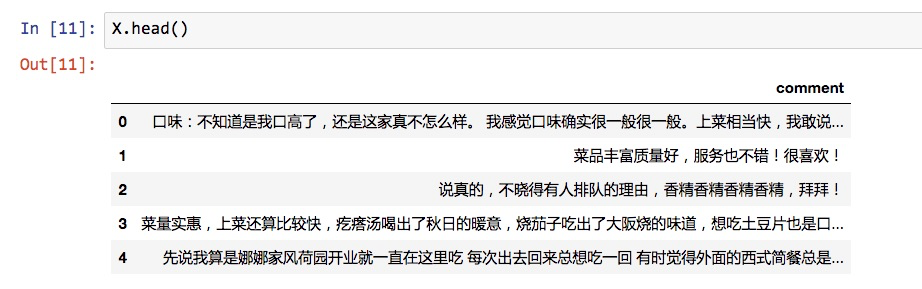
注意这里评论数据还是原始信息。词语没有进行拆分。
为了做特征向量化,下面我们利用结巴分词工具来拆分句子为词语。
import jieba
我们建立一个辅助函数,把结巴分词的结果用空格连接。
这样分词后的结果就如同一个英文句子一样,单次之间依靠空格分割。
def chinese_word_cut(mytext):
return " ".join(jieba.cut(mytext))
有了这个函数,我们就可以使用 apply 命令,把每一行的评论数据都进行分词。
X['cutted_comment'] = X.comment.apply(chinese_word_cut)
我们看看分词后的效果:
X.cutted_comment[:5]
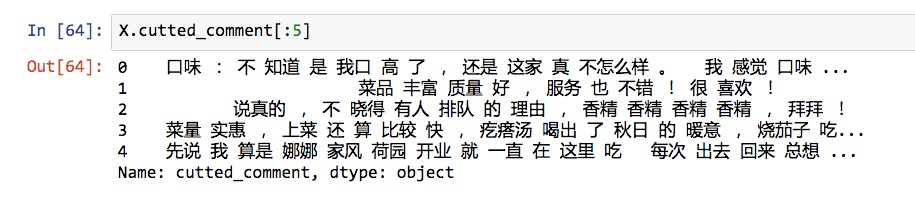
单词和标点之间都用空格分割,符合我们的要求。
下面就是机器学习的常规步骤了:我们需要把数据分成训练集和测试集。
为什么要拆分数据集合?
在《贷还是不贷:如何用Python和机器学习帮你决策?》一文中,我已解释过,这里复习一下:
如果期末考试之前,老师给你一套试题和答案,你把它背了下来。然后考试的时候,只是从那套试题里面抽取一部分考。你凭借超人的记忆力获得了100分。请问你学会了这门课的知识了吗?不知道如果给你新的题目,你会不会做呢?答案还是不知道。所以考试题目需要和复习题目有区别。
同样的道理,假设咱们的模型只在某个数据集上训练,准确度非常高,但是从来没有见过其他新数据,那么它面对新数据表现如何呢?
你心里也没底吧?
所以我们需要把数据集拆开,只在训练集上训练。保留测试集先不用,作为考试题,看模型经过训练后的分类效果。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
这里,我们设定了 random_state 取值,这是为了在不同环境中,保证随机数取值一致,以便验证咱们模型的实际效果。
我们看看此时的 X_train 数据集形状。
X_train.shape
(1500, 2)
可见,在默认模式下,train_test_split函数对训练集和测试集的划分比例为 3:1。
我们检验一下其他3个集合看看:
y_train.shape
(1500,)
X_test.shape
(500, 2)
y_test.shape
(500,)
同样都正确无误。
下面我们就要处理中文停用词了。
我们编写一个函数,从中文停用词表里面,把停用词作为列表格式保存并返回:
def get_custom_stopwords(stop_words_file):
with open(stop_words_file) as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
我们指定使用的停用词表,为我们已经下载保存好的哈工大停用词表文件。
stop_words_file = "stopwordsHIT.txt"
stopwords = get_custom_stopwords(stop_words_file)
看看我们的停用词列表的后10项:
stopwords[-10:]

这些大部分都是语气助词,作为停用词去除掉,不会影响到语句的实质含义。
下面我们就要尝试对分词后的中文语句做向量化了。
我们读入CountVectorizer向量化工具,它依据词语出现频率转化向量。
from sklearn.feature_extraction.text import CountVectorizer
我们建立一个CountVectorizer()的实例,起名叫做vect。
注意这里为了说明停用词的作用。我们先使用默认参数建立vect。
vect = CountVectorizer()
然后我们用向量化工具转换已经分词的训练集语句,并且将其转化为一个数据框,起名为term_matrix。
term_matrix = pd.DataFrame(vect.fit_transform(X_train.cutted_comment).toarray(), columns=vect.get_feature_names())
我们看看term_matrix的前5行:
term_matrix.head()
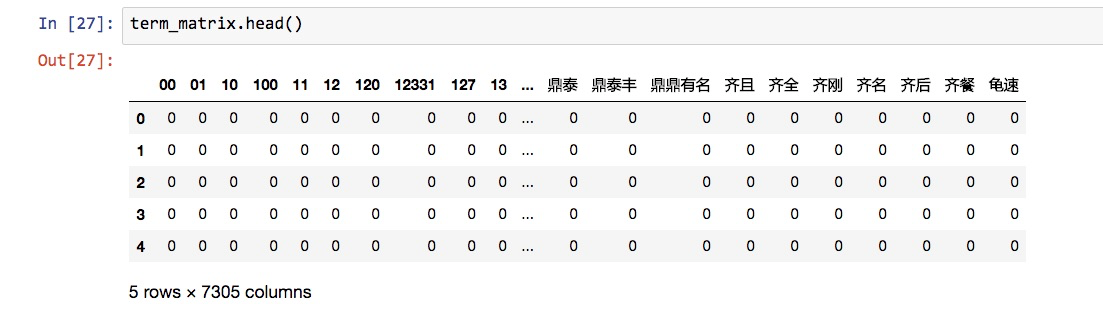
我们注意到,特征词语五花八门,特别是很多数字都被当作特征放在了这里。
term_matrix的形状如下:
term_matrix.shape
(1500, 7305)
行数没错,列数就是特征个数,有7305个。
下面我们测试一下,加上停用词去除功能,特征向量的转化结果会有什么变化。
vect = CountVectorizer(stop_words=frozenset(stopwords))
下面的语句跟刚才一样:
term_matrix = pd.DataFrame(vect.fit_transform(X_train.cutted_comment).toarray(), columns=vect.get_feature_names())
term_matrix.head()
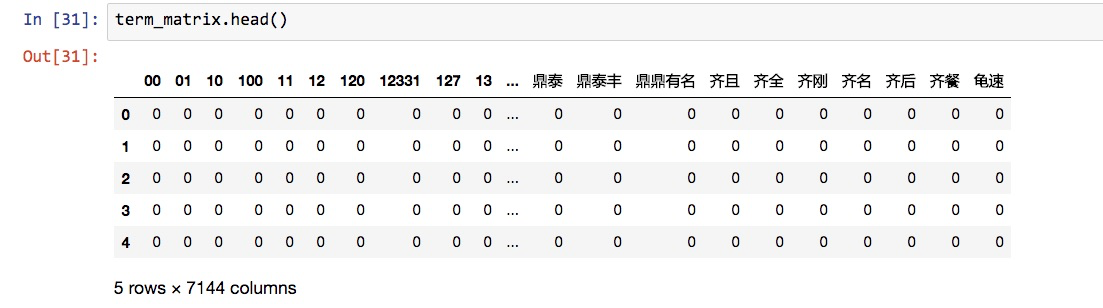
可以看到,此时特征个数从刚才的7305个,降低为7144个。我们没有调整任何其他的参数,因此减少的161个特征,就是出现在停用词表中的单词。
但是,这种停用词表的写法,依然会漏掉不少漏网之鱼。
首先就是前面那一堆显眼的数字。它们在此处作为特征毫无道理。如果没有单位,没有上下文,数字都是没有意义的。
因此我们需要设定,数字不能作为特征。
在Python里面,我们可以设定token_pattern来完成这个目标。
这一部分需要用到正则表达式的知识,我们这里无法详细展开了。
但如果你只是需要去掉数字作为特征的话,按照我这样写,就可以了。
另一个问题在于,我们看到这个矩阵,实际上是个非常稀疏的矩阵,其中大部分的取值都是0.
这没有关系,也很正常。
毕竟大部分评论语句当中只有几个到几十个词语而已。7000多的特征,单个语句显然是覆盖不过来的。
然而,有些词汇作为特征,就值得注意了。
首先是那些过于普遍的词汇。尽管我们用了停用词表,但是难免有些词汇几乎出现在每一句评论里。什么叫做特征?特征就是可以把一个事物与其他事物区别开的属性。
假设让你描述今天见到的印象最深刻的人。你怎么描述?
我看见他穿着小丑的衣服,在繁华的商业街踩高跷,一边走还一边抛球,和路人打招呼。
还是……
我看见他有两只眼睛,一只鼻子。
后者绝对不算是好的特征描述,因为难以把你要描述的个体区分出来。
物极必反,那些过于特殊的词汇,其实也不应该保留。因为你了解了这个特征之后,对你的模型处理新的语句情感判断,几乎都用不上。
这就如同你跟着神仙学了屠龙之术,然而之后一辈子也没有见过龙……
所以,如下面两个代码段所示,我们一共多设置了3层特征词汇过滤。
max_df = 0.8 # 在超过这一比例的文档中出现的关键词(过于平凡),去除掉。
min_df = 3 # 在低于这一数量的文档中出现的关键词(过于独特),去除掉。
vect = CountVectorizer(max_df = max_df,
min_df = min_df,
token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b',
stop_words=frozenset(stopwords))
这时候,再运行我们之前的语句,看看效果。
term_matrix = pd.DataFrame(vect.fit_transform(X_train.cutted_comment).toarray(), columns=vect.get_feature_names())
term_matrix.head()
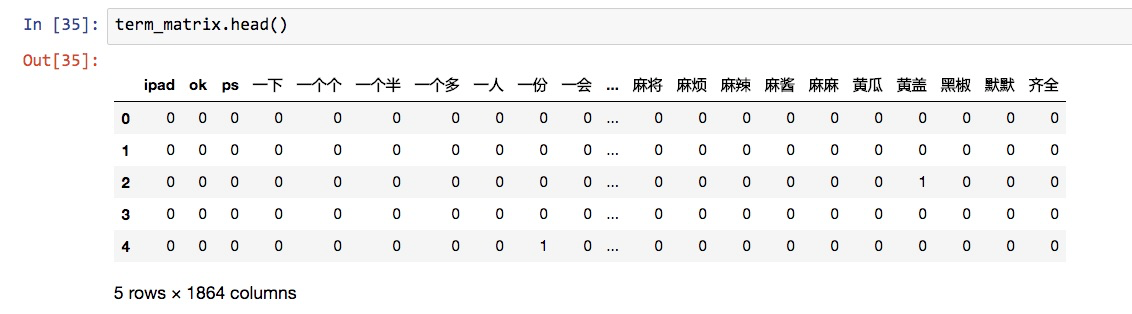
可以看到,那些数字全都不见了。特征数量从单一词表法去除停用词之后的7144个,变成了1864个。
你可能会觉得,太可惜了吧?好容易分出来的词,就这么扔了?
要知道,特征多,绝不一定是好事儿。
尤其是噪声大量混入时,会显著影响你模型的效能。
好了,评论数据训练集已经特征向量化了。下面我们要利用生成的特征矩阵来训练模型了。
我们的分类模型,采用朴素贝叶斯(Multinomial naive bayes)。
from sklearn.naive_bayes import MultinomialNB
nb = MultinomialNB()
注意我们的数据处理流程是这样的:
- 特征向量化;
- 朴素贝叶斯分类。
如果每次修改一个参数,或者换用测试集,我们都需要重新运行这么多的函数,肯定是一件效率不高,且令人头疼的事儿。而且只要一复杂,出现错误的几率就会增加。
幸好,Scikit-learn给我们提供了一个功能,叫做管道(pipeline),可以方便解决这个问题。
它可以帮助我们,把这些顺序工作连接起来,隐藏其中的功能顺序关联,从外部一次调用,就能完成顺序定义的全部工作。
使用很简单,我们就把 vect 和 nb 串联起来,叫做pipe。
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(vect, nb)
看看它都包含什么步骤:
pipe.steps
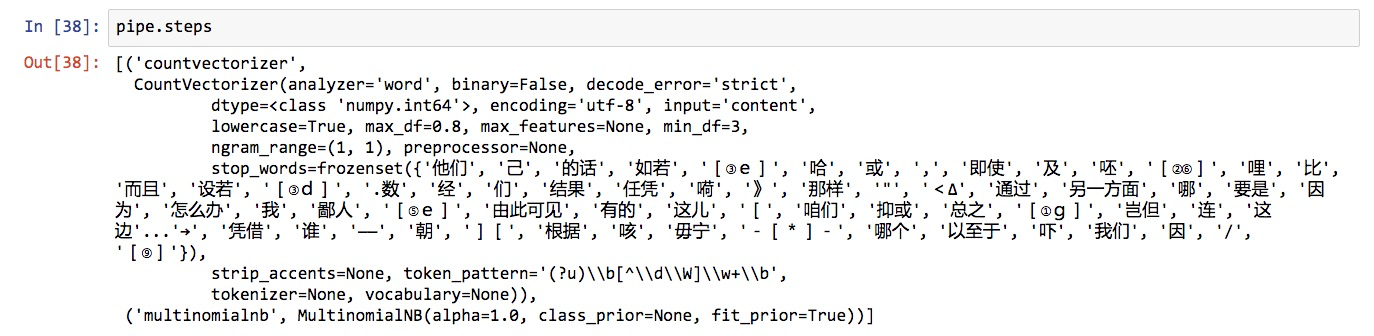
看,我们刚才做的工作,都在管道里面了。我们可以把管道当成一个整体模型来调用。
下面一行语句,就可以把未经特征向量化的训练集内容输入,做交叉验证,算出模型分类准确率的均值。
from sklearn.cross_validation import cross_val_score
cross_val_score(pipe, X_train.cutted_comment, y_train, cv=5, scoring='accuracy').mean()
咱们的模型在训练中的准确率如何呢?
0.820687244673089
这个结果,还是不错的。
回忆一下,总体的正向和负向情感,各占了数据集的一半。
如果我们建立一个“笨模型”(dummy model),即所有的评论,都当成正向(或者负向)情感,准确率多少?
对,50%。
目前的模型准确率,远远超出这个数值。超出的这30%多,其实就是评论信息为模型带来的确定性。
但是,不要忘了,我们不能光拿训练集来说事儿,对吧?下面咱们给模型来个考试。
我们用训练集,把模型拟合出来。
pipe.fit(X_train.cutted_comment, y_train)
然后,我们在测试集上,对情感分类标记进行预测。
pipe.predict(X_test.cutted_comment)
这一大串0和1,你看得是否眼花缭乱?
没关系,scikit-learn给我们提供了非常多的模型性能测度工具。
我们先把预测结果保存到y_pred。
y_pred = pipe.predict(X_test.cutted_comment)
读入 scikit-learn 的测量工具集。
from sklearn import metrics
我们先来看看测试准确率:
metrics.accuracy_score(y_test, y_pred)
0.86
这个结果是不是让你很吃惊?没错,模型面对没有见到的数据,居然有如此高的情感分类准确性。
对于分类问题,光看准确率有些不全面,咱们来看看混淆矩阵。
metrics.confusion_matrix(y_test, y_pred)
array([[194, 43],
[ 27, 236]])
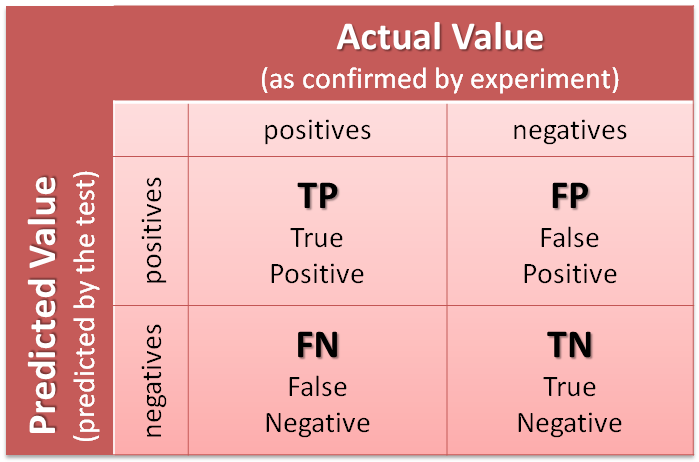
混淆矩阵中的4个数字,分别代表:
- TP: 本来是正向,预测也是正向的;
- FP: 本来是负向,预测却是正向的;
- FN: 本来是正向,预测却是负向的;
- TN: 本来是负向,预测也是负向的。
下面这张图(来自 https://goo.gl/5cYGZd )应该能让你更为清晰理解混淆矩阵的含义:
写到这儿,你大概能明白咱们模型的性能了。
但是总不能只把咱们训练出的模型和无脑“笨模型”去对比吧?这也太不公平了!
下面,我们把老朋友 SnowNLP 呼唤出来,做个对比。
如果你把它给忘了,请复习《如何用Python做情感分析?》
from snownlp import SnowNLP
def get_sentiment(text):
return SnowNLP(text).sentiments
我们利用测试集评论原始数据,让 SnowNLP 跑一遍,获得结果。
y_pred_snownlp = X_test.comment.apply(get_sentiment)
注意这里有个小问题。 SnowNLP 生成的结果,不是0和1,而是0到1之间的小数。所以我们需要做一步转换,把0.5以上的结果当作正向,其余当作负向。
y_pred_snownlp_normalized = y_pred_snownlp.apply(lambda x: 1 if x>0.5 else 0)
看看转换后的前5条 SnowNLP 预测结果:
y_pred_snownlp_normalized[:5]
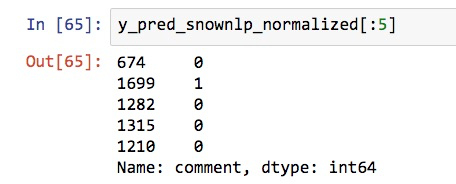
好了,符合我们的要求。
下面我们先看模型分类准确率:
metrics.accuracy_score(y_test, y_pred_snownlp_normalized)
0.77
与之对比,咱们的测试集分类准确率,可是0.86哦。
我们再来看看混淆矩阵。
metrics.confusion_matrix(y_test, y_pred_snownlp_normalized)
array([[189, 48],
[ 67, 196]])
对比的结果,是 TP 和 TN 两项上,咱们的模型判断正确数量,都要超出 SnowNLP。
小结
回顾一下,本文介绍了以下知识点:
- 如何用一袋子词(bag of words)模型将自然语言语句向量化,形成特征矩阵;
- 如何利用停用词表、词频阈值和标记模式(token pattern)移除不想干的伪特征词汇,降低模型复杂度。
- 如何选用合适的机器学习分类模型,对词语特征矩阵做出分类;
- 如何用管道模式,归并和简化机器学习步骤流程;
- 如何选择合适的性能测度工具,对模型的效能进行评估和对比。
希望这些内容能够帮助你更高效地处理中文文本情感分类工作。
讨论
你之前用机器学习做过中文情感分类项目吗?你是如何去除停用词的?你使用的分类模型是哪个?获得的准确率怎么样?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
