
负荷
下午,我用 Python 深度学习框架 Keras 训练了一个包含3层神经网络的回归模型,预测波士顿地区房价。
这是来自于 “Deep Learning with Python” 书上的一个例子。

运行的时候,代码有两个大循环。
第一个把数据跑100遍(epochs),第二个把数据跑500遍。
我的笔记本电脑算起来很吃力,风扇一直在响。
大热天的,看着好可怜。
用笔记本电脑进行机器学习,还是不大合适的。
我要是有一块 GPU 就好了……
此时,突发奇想。
我虽然没有带 nVidia GPU 的设备,不过谁说非要在本地机器运行代码了?
早已是云时代了啊!
能否用云端 GPU 跑机器学习代码,让我的笔记本少花些力气呢?
偶遇
有这个想法,是因为最近在 Youtube 上面,我看到了 Siraj Raval 的一段新视频。
这段视频里,他推荐了云端 GPU 提供平台 FloydHub。

我曾经试过 AWS GPU 产品。
那是在一门深度学习网课上。
授课老师跟 AWS 合作,为全体学生免费提供若干小时的 AWS 计算能力,以便大家顺利完成练习和作业。
我记得那么清楚,是因为光如何配置 AWS ,他就专门录了数十分钟的视频。
AWS 虽然已经够简单,但是对于新手来说,还是有些门槛。
FloydHub 这个网站,刚好能解决用户痛点。
首先它能够包裹 AWS ,把一切复杂的选择都过滤掉。
其次它内置了几乎全部主流深度学习框架,自带电池,开箱即用;
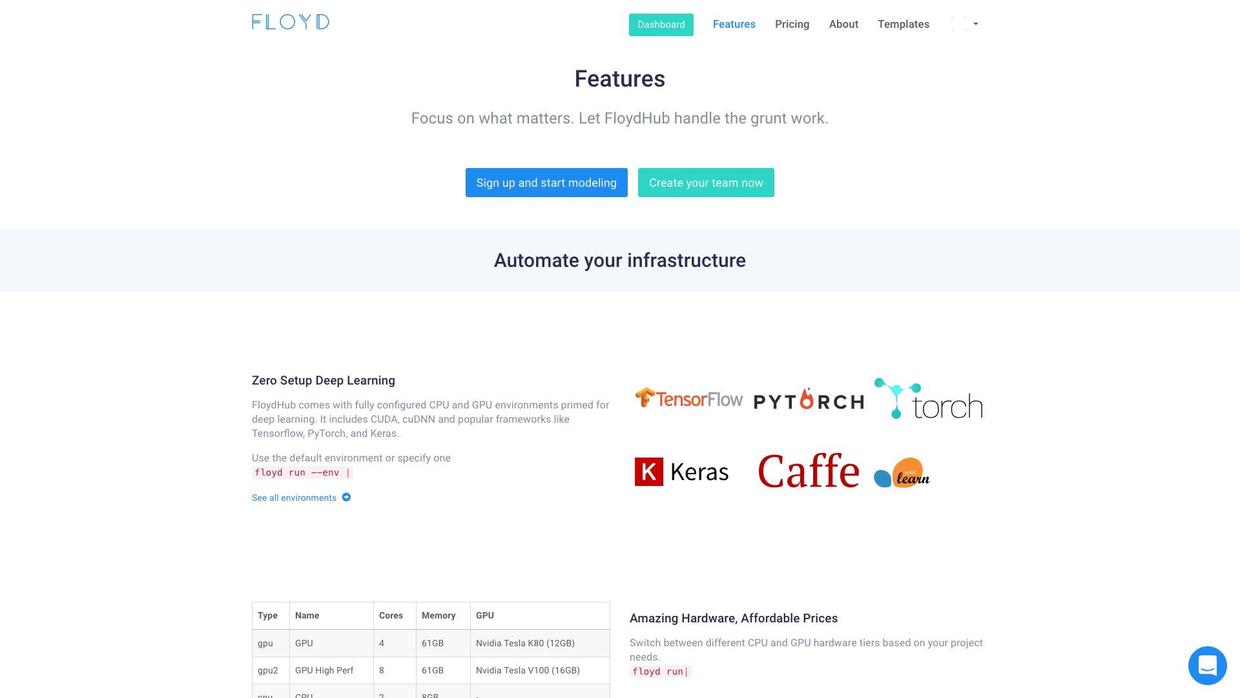
另外,它提供了丰富而简明的文档,用户可以快速上手。
正如它的主页宣称的:
Focus on what matters. Let FloydHub handle the grunt work.
翻译过来就是:
关注你想做的事儿。脏活累活,扔给 FloydHub 吧。
凡是设计给懒人用的东西,我都喜欢。
我于是立即注册了账户,并且做了邮件验证。
之后,我免费获得了2个小时的 GPU 时间,可以自由尝试运行机器学习任务。
为了能把珍贵的 GPU 运算时间花在刀刃上,我认真地阅读了快速上手教程。
几分钟后,我确信自己学会了使用方法。
尝试
首先,我到 FloydHub 的个人控制面板上,新建了一个任务,起名叫做 “try-keras-boston-house-regression”。
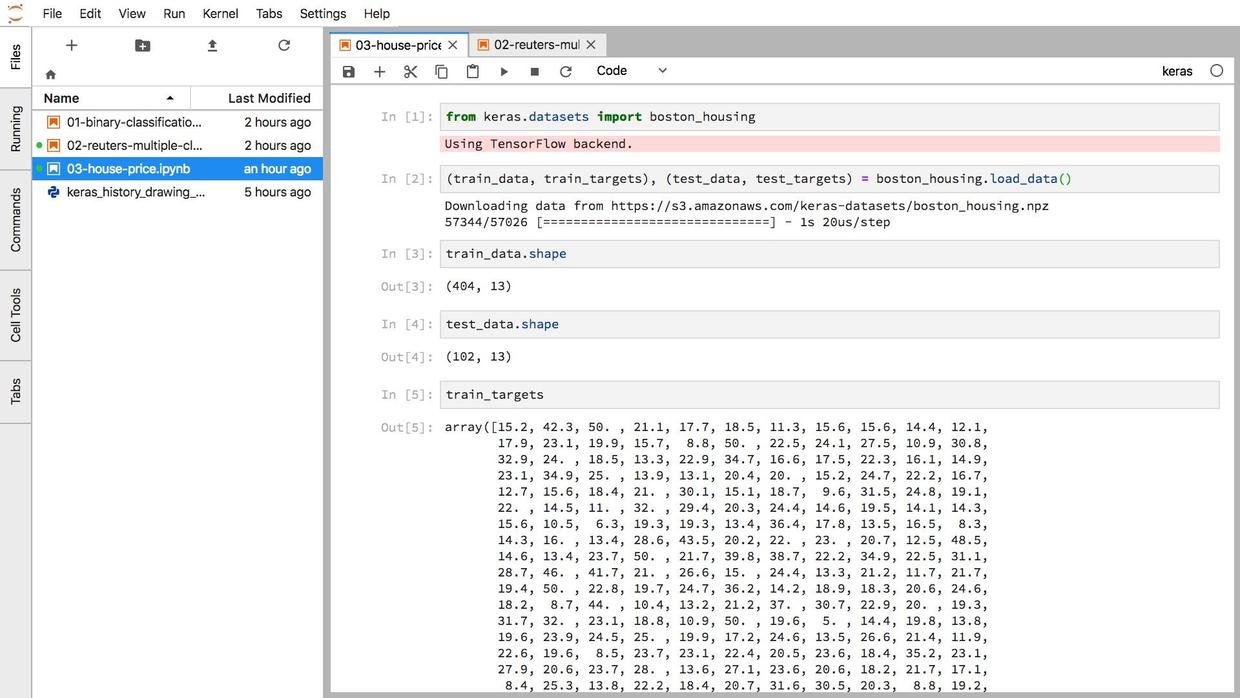
然后,我在本地的 Jupyter Notebook 里,把代码导出为 Python 脚本文件,如下图所示。
我新建了一个目录,把脚本文件拷贝了进来。
这个 Python 脚本,我仅仅在最后加了3行代码:
import pickle
with open('data.pickle', 'wb') as f:
pickle.dump([all_scores, all_mae_histories], f)
加入这几行代码,是因为我们需要记录运行中的一些数据(即 all_scores 和 all_mae_histories)。
然后,进入终端,利用 cd 命令,进入到这个文件夹。
执行:
pip install floyd-cli
这样,本地的 FloydHub 命令行工具就安装好了。
执行下面命令登录进去:
floyd login
系统会提示你,输入 FloydHub 上的账号信息。
输入正确后,执行:
floyd init try-keras-boston-house-regression
注意这个名称,必须和刚才在控制面板新建的任务名称一致。
配置都完成了,下面直接运行就可以了。
输入:
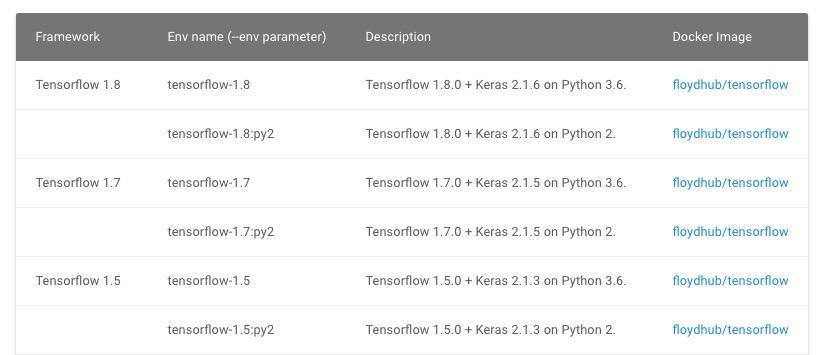
floyd run --gpu --env tensorflow-1.8 "python 03-house-price.py"
这句话的意思是:
- 使用 GPU 计算;
- 运行环境选用 Tensorflow 1.8 版本,及对应的 Keras (2.1.6)。
如果你希望使用其他深度学习框架或版本,可以参考这个链接。
FloydHub 对我们的命令,是这样回应的:
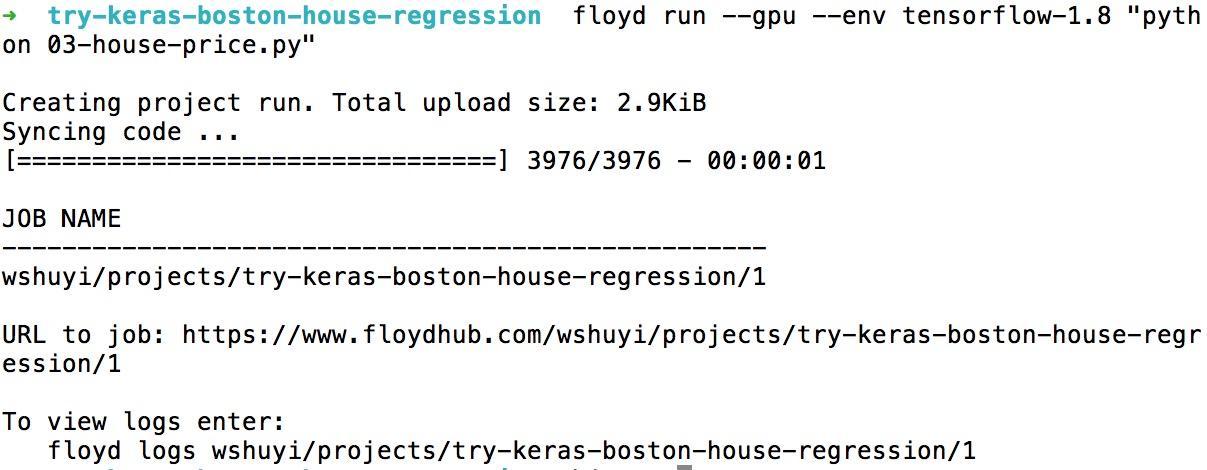
操作结束?
对,就这么简单。
你的任务,已在云端运行了。
结果
然后,我就忙自己的事儿去了。
喝茶,看书,还扫了几眼微信订阅号。
虽然是按时计费,但你不用因为怕多算钱,就死死盯住云端运行过程。
一旦任务结束,它自己会退出运行,不会多扣你一分钟珍贵的 GPU 运行时间。
等我回到电脑前面,发现任务已完成。
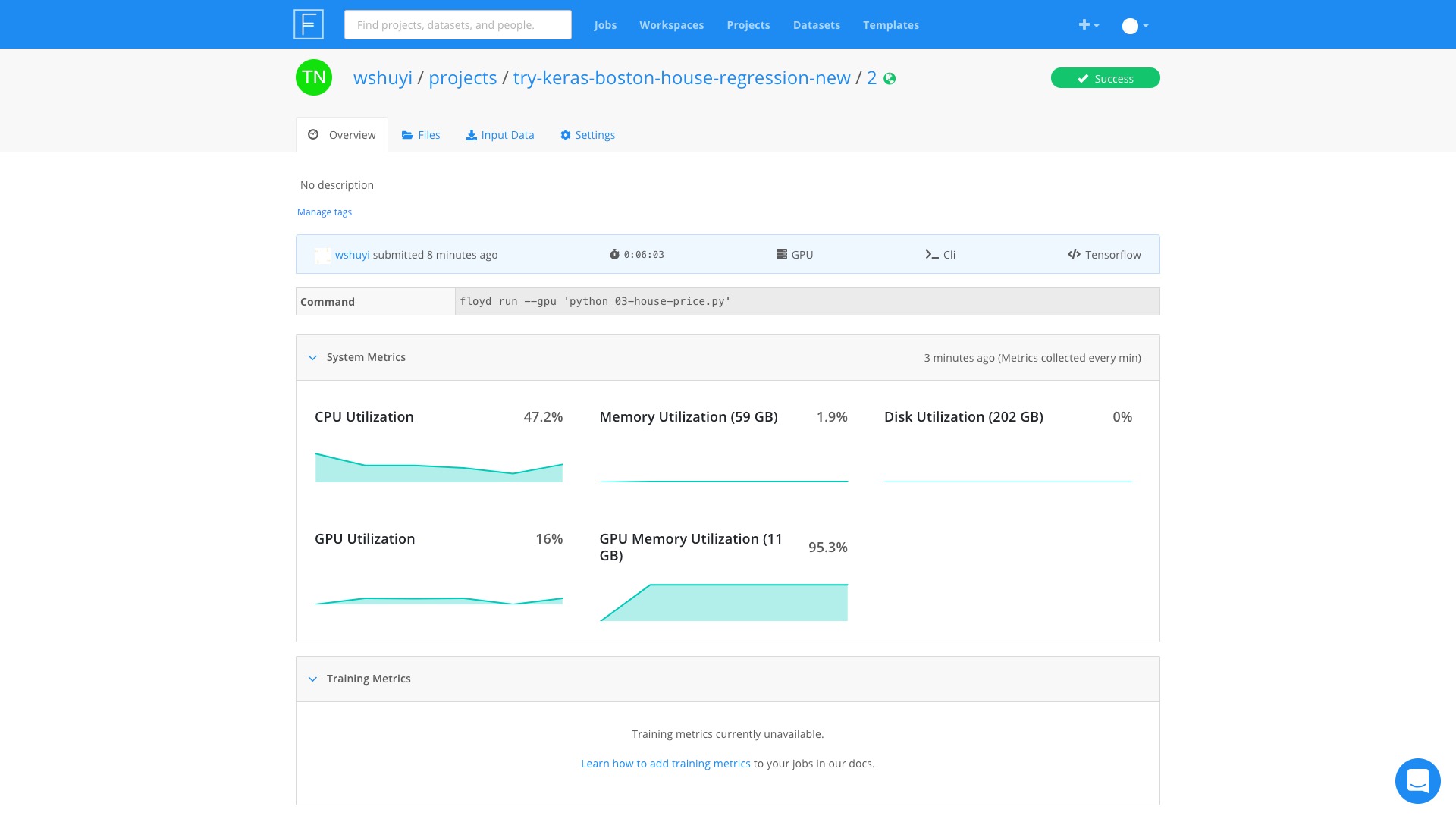
整个儿过程中,GPU 内存着实够忙碌的(占用率一直超过90%)。
不过 GPU 好像很清闲的样子,一直在百分之十几晃悠。
看来,我们的神经网络,层数还是太少了,结构不够复杂。
GPU 跑起来,很不过瘾。
往下翻页,看看输出的结果。
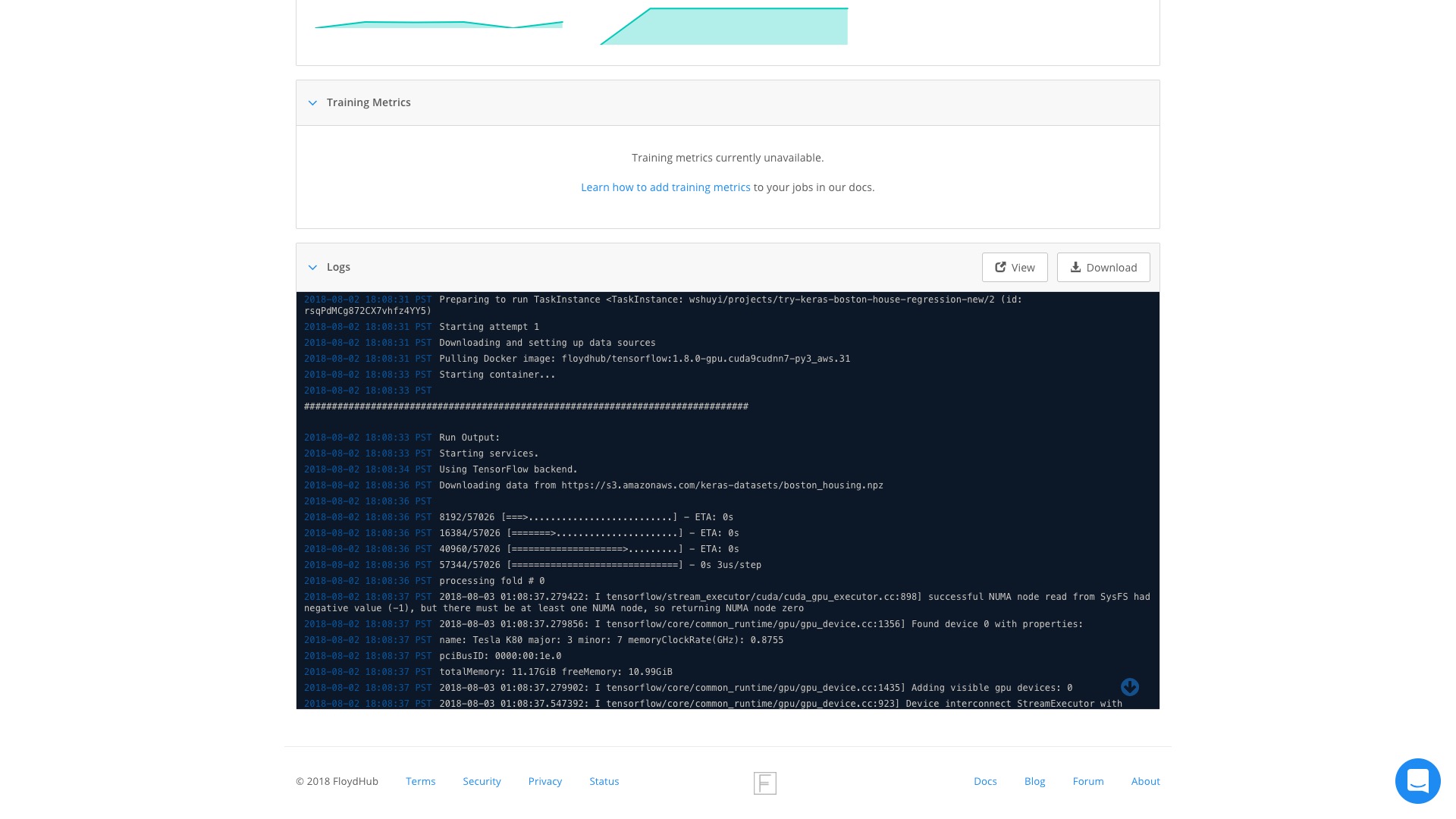
程序的输出,包括 GPU 资源创建、调用的一些记录,这里都有。
打开 Files 标签页,咱们看看结果。
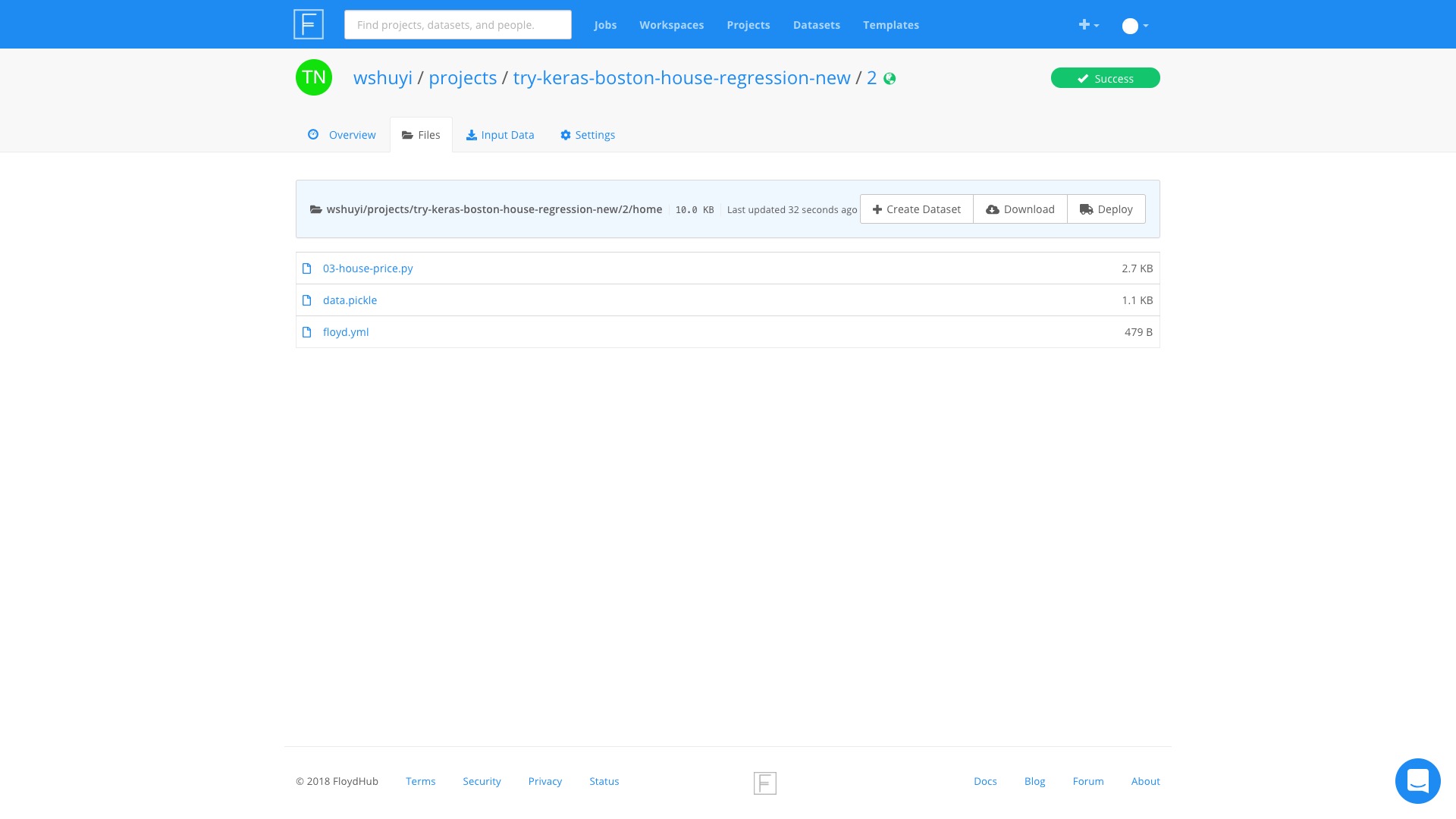
之前追加3行代码,生成的 pickle 记录文件,就在这里了。
看来,FloydHub 确实帮我们完成了繁复的计算过程。
我的笔记本电脑,一直凉凉快快,等着摘取胜利果实。
选择下载,把这个 pickle 文件下载到本地。跟我们的 Jupyter Notebook 放在一个目录下。
回到 Jupyter Lab 运行界面。
新开一个 ipynb 文件。
我们输入以下代码,查看运行记录是否符合我们的需要。
import pickle
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
with open('data.pickle', 'rb') as f:
[all_scores, all_mae_histories] = pickle.load(f)
num_epochs = 500
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)
]
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
这些代码,只是为了绘图,本身没有任何复杂运算。
这是运行结果:
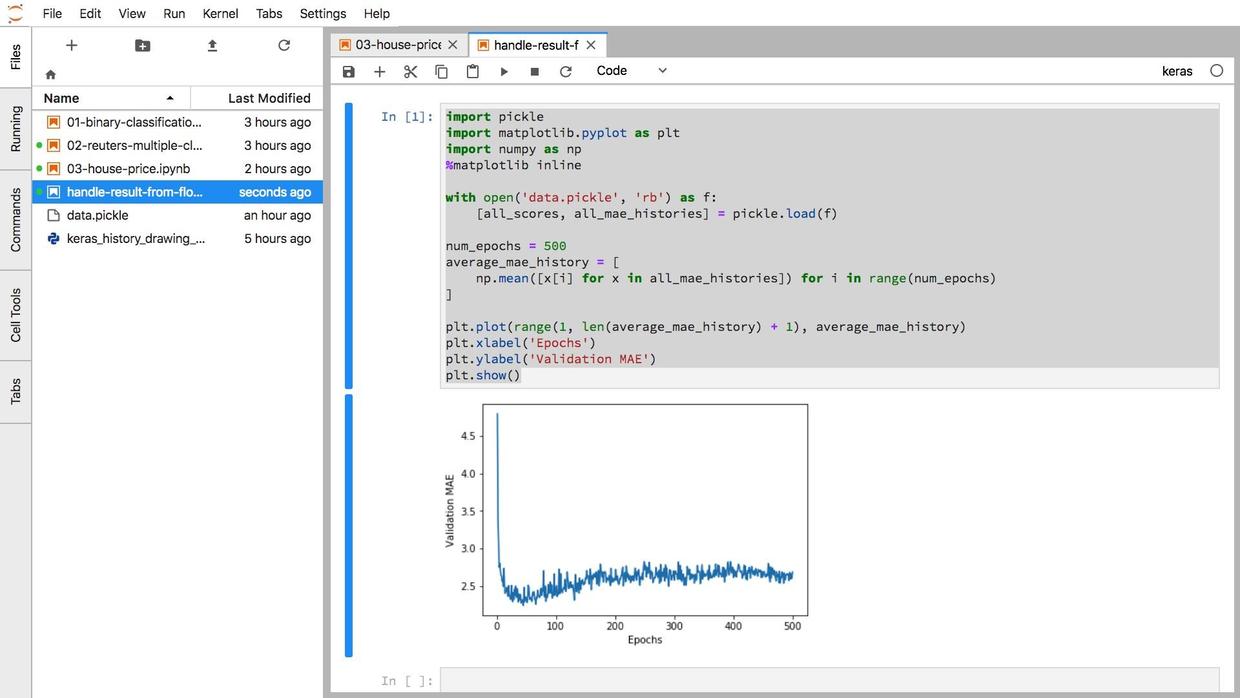
可视化结果与书上的一致。
证明机器学习代码在云端运行过程一切顺利。
我们还可以查看剩余的可用免费时长。
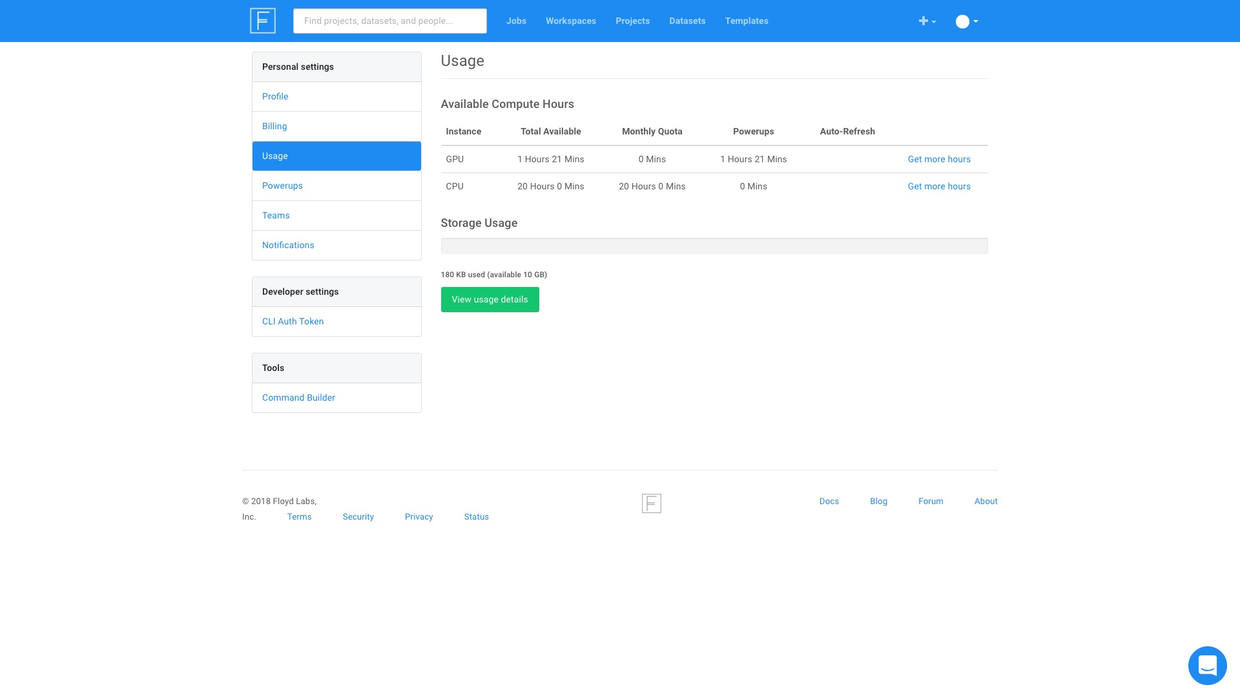
嗯,还剩下1个多小时 GPU 运算时间呢,回头接着玩儿。
Workspace
刚才咱们展示的,是命令行下的使用方法。如果你对于命令行操作很熟悉,建议你使用这种方式。因为控制感更强一些。
但是对于初学者,我推荐你使用另外一种更为简便的方法。
在主页点击上方的 Workspace 标签。
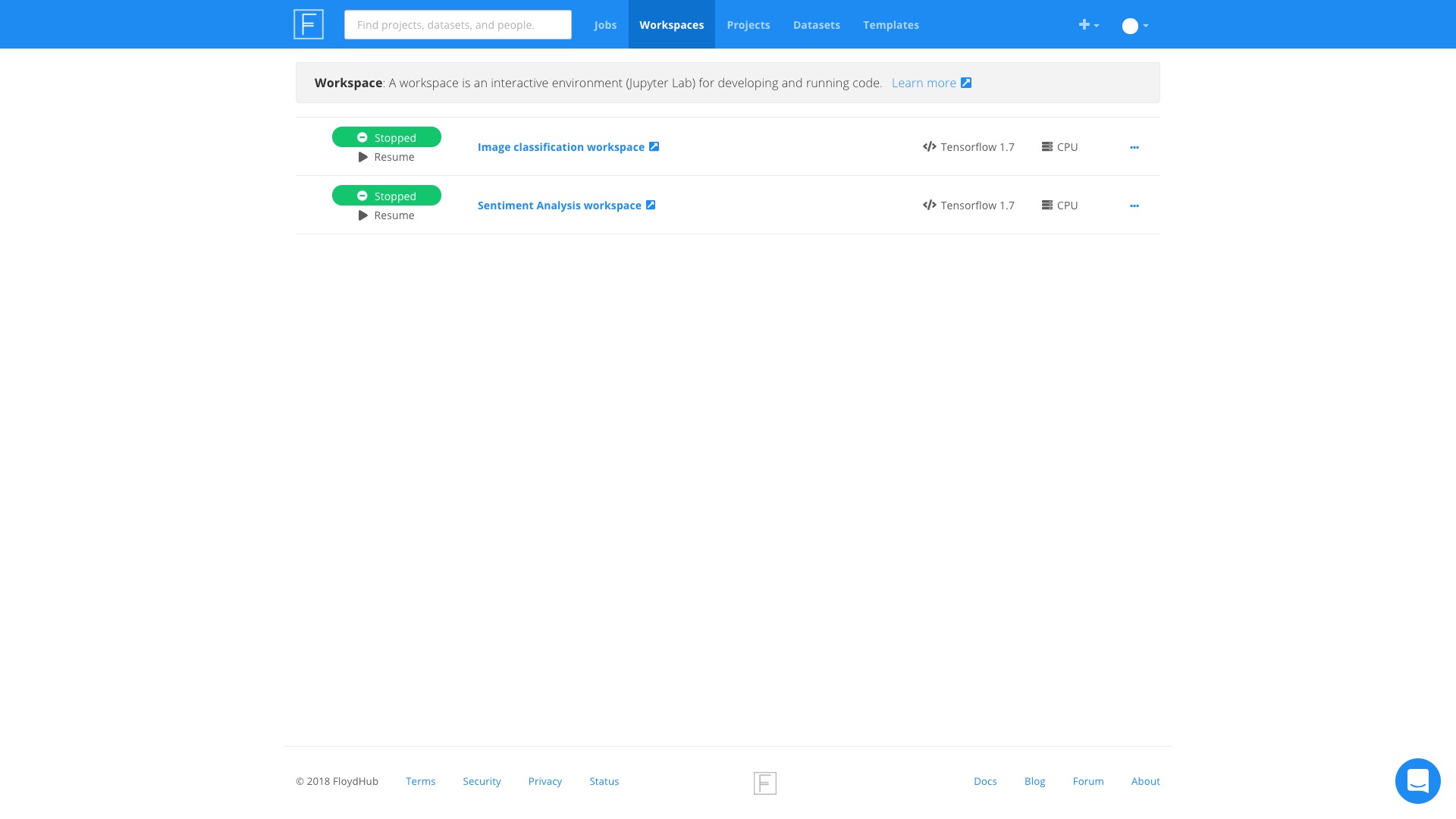
你会看到已有的2个样例 Workspace 。
尝试打开其中第一个,看看内容。
点击右上方的 Resume 绿色按钮,你会看到系统在认真地为我们准备环境。
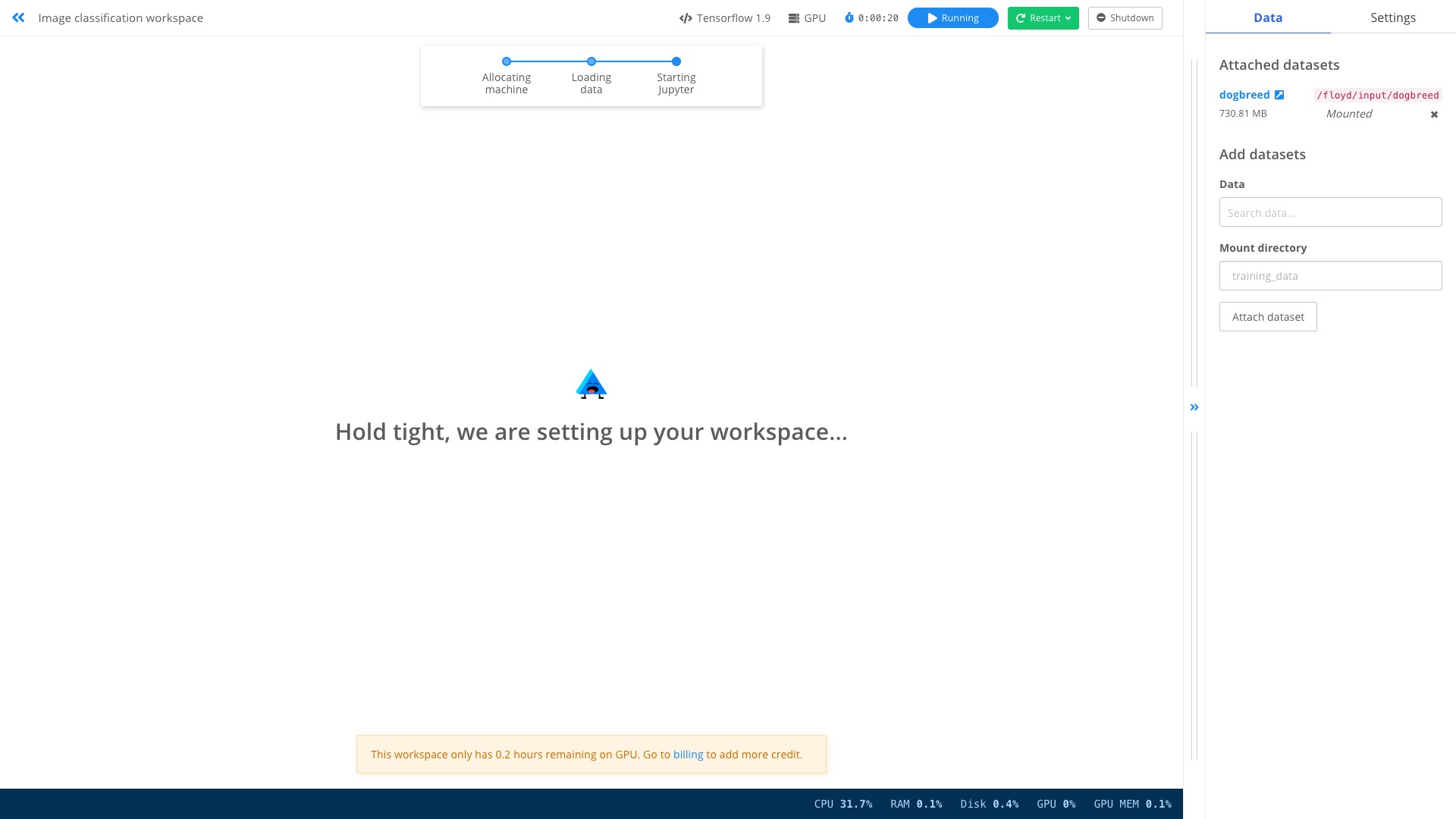
准备工作结束后,你会看到出现了熟悉的 Jupyter lab 界面。
双击左侧文件区域的 dog-breed-classification.ipynb ,打开。
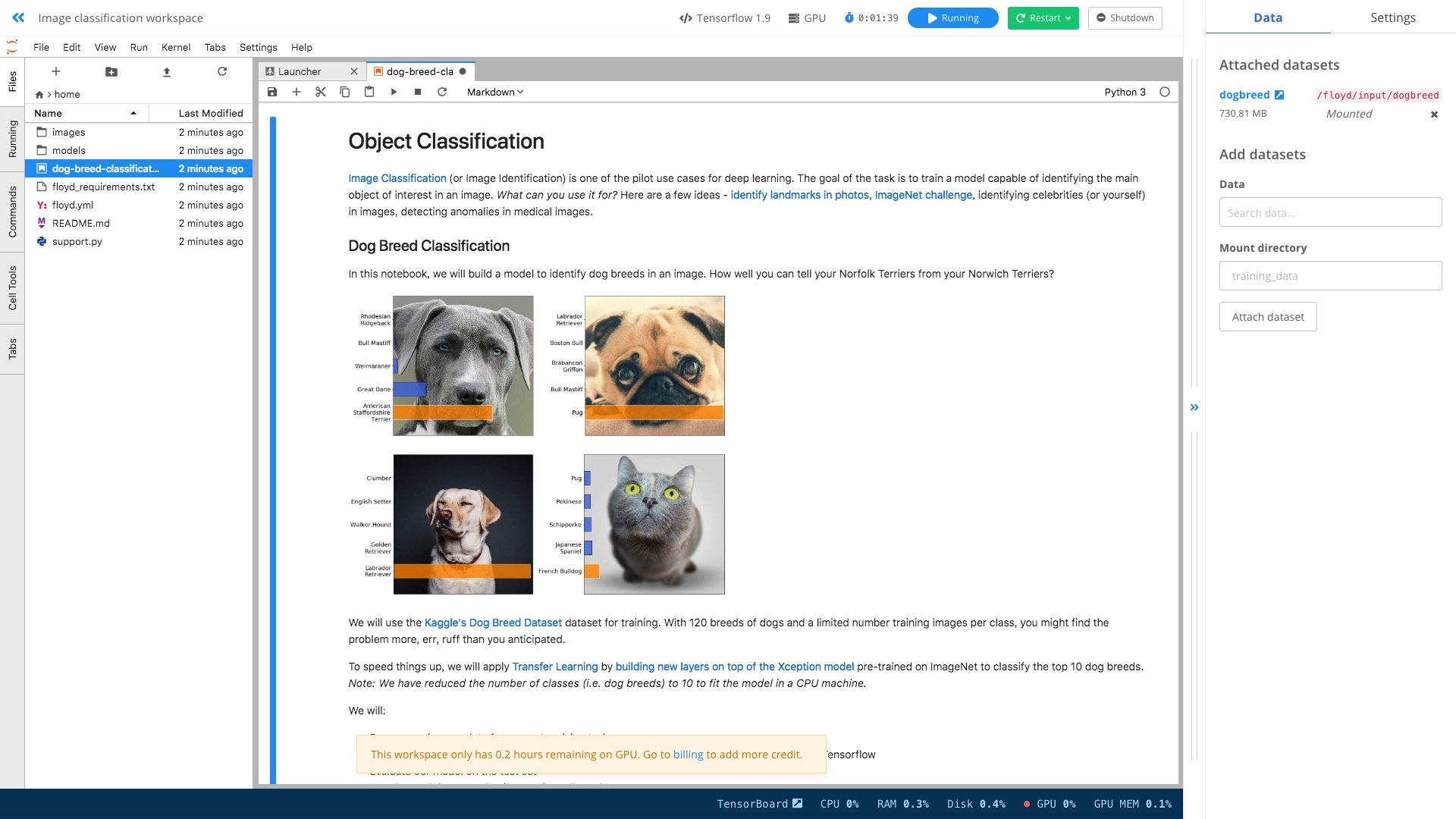
这里是个猫狗分辨的完整样例。
咱们执行一下。方式是执行菜单栏里面的 Run -> Restart Kernel and Run All Cells:
你会发现,跟在本地执行起来,没有什么区别。
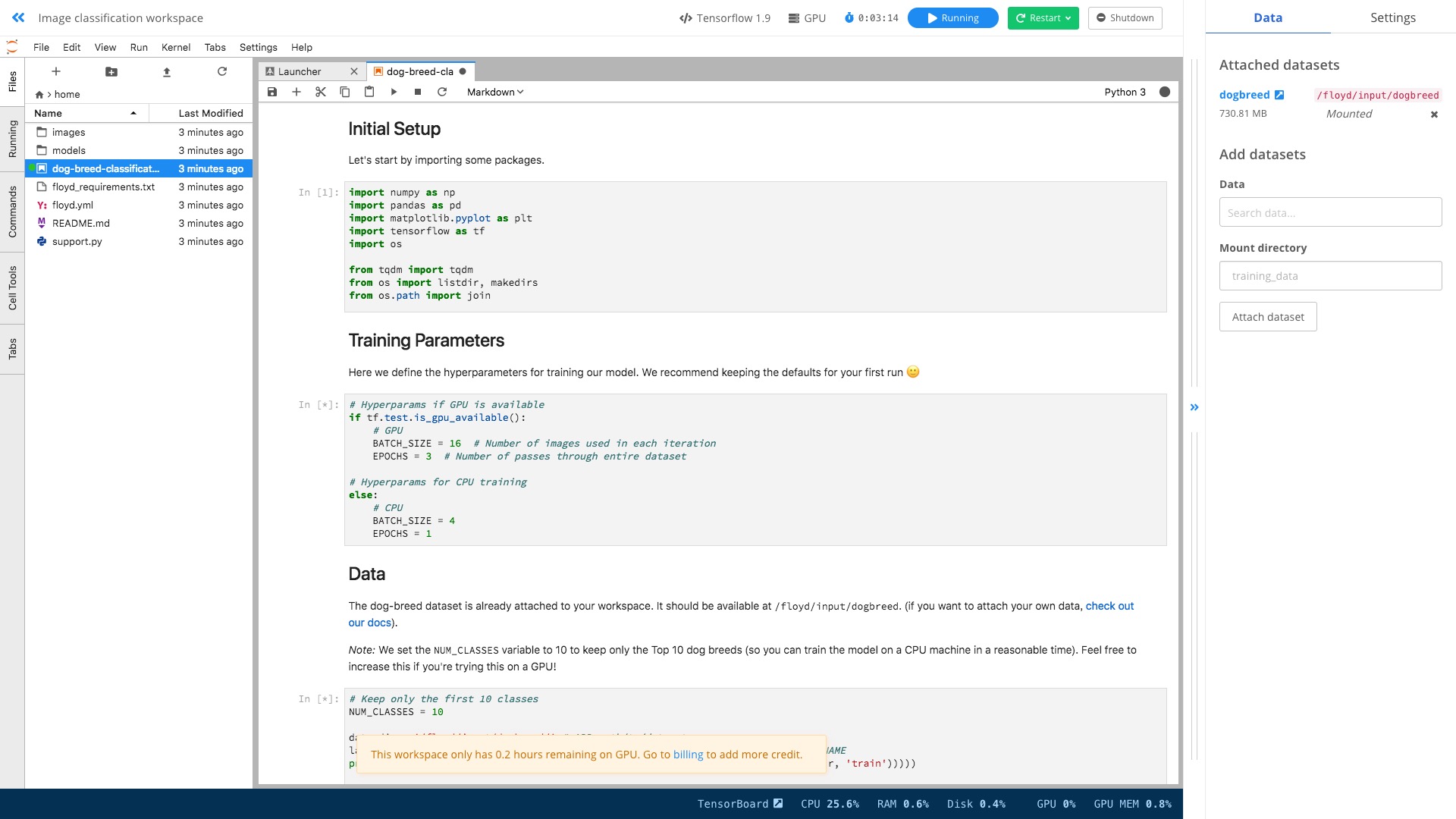
唯一的差别,是你在用 GPU 加速哦!
如果想建立自己的 Workspace ,该怎么办呢?
很简单,回到咱们的 Project 页面下,本例是这个链接。
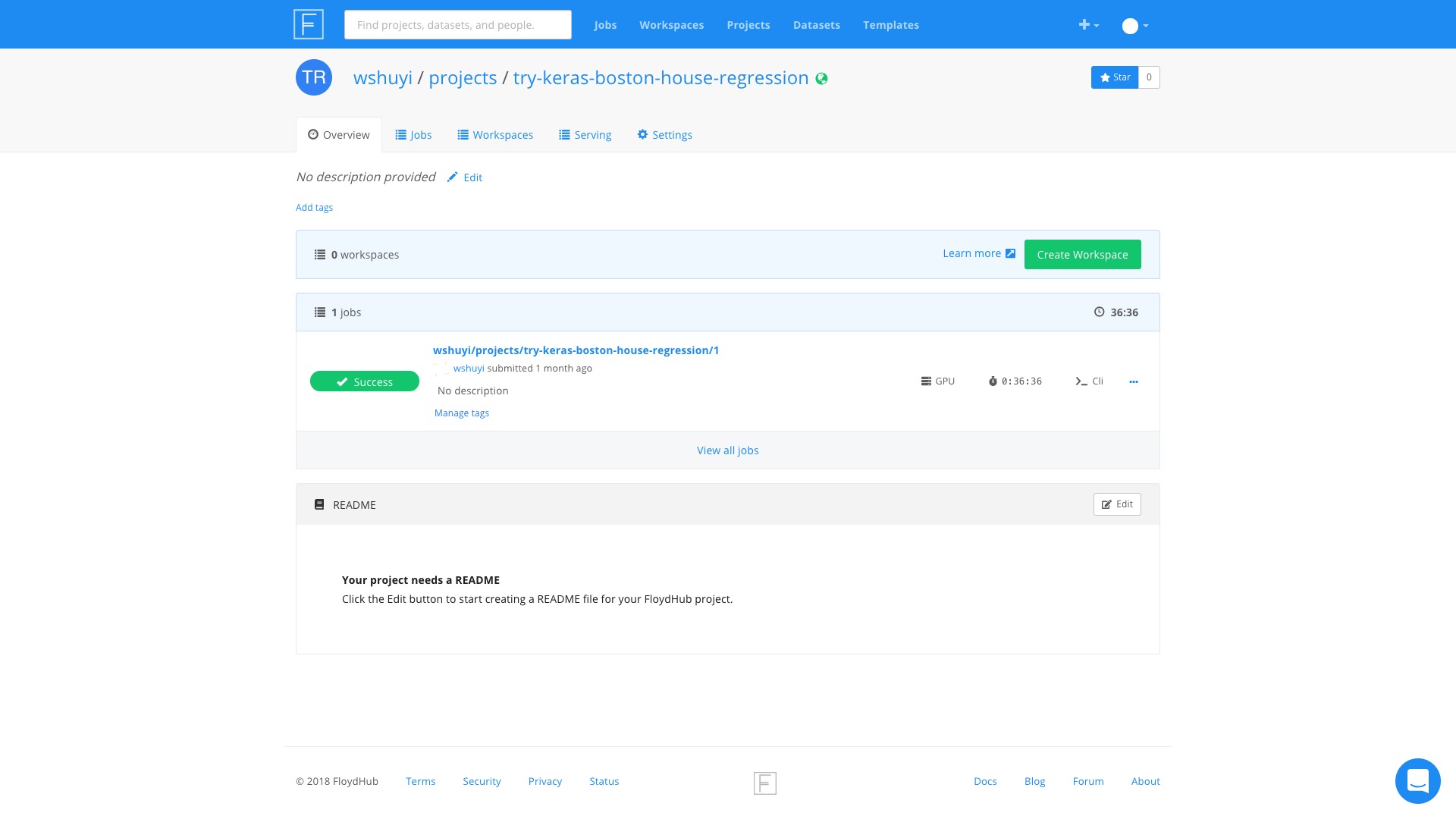
你会看到,每个项目下,都可以使用 Create Workspace 这个按钮创建新的 Workspace 。
Floydhub 会询问你,使用哪种方式建立新的 Workspace 。
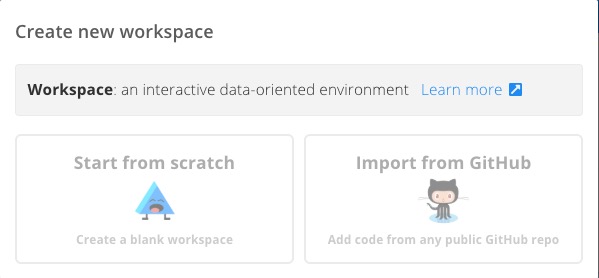
这里咱们选择左侧的 Start from scratch 。
下面选择使用的环境。
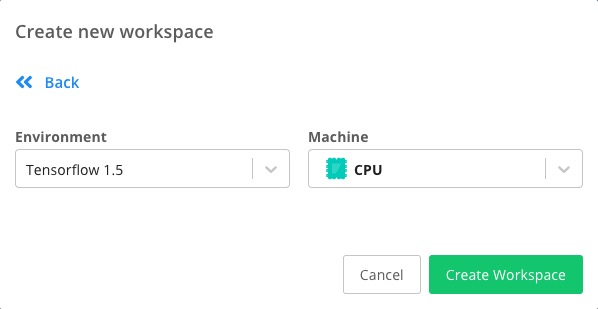
我们将其改成 Tensorflow 1.9 和 GPU 环境。
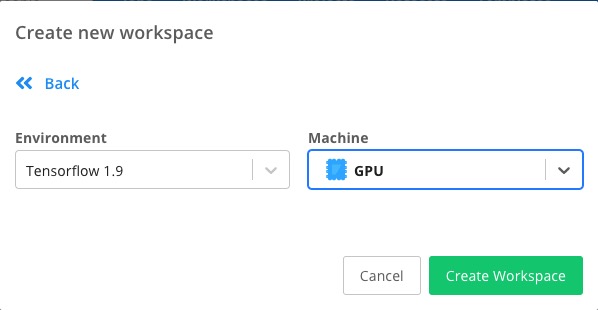
点击 Create Workspace 按钮,就创建完毕了。
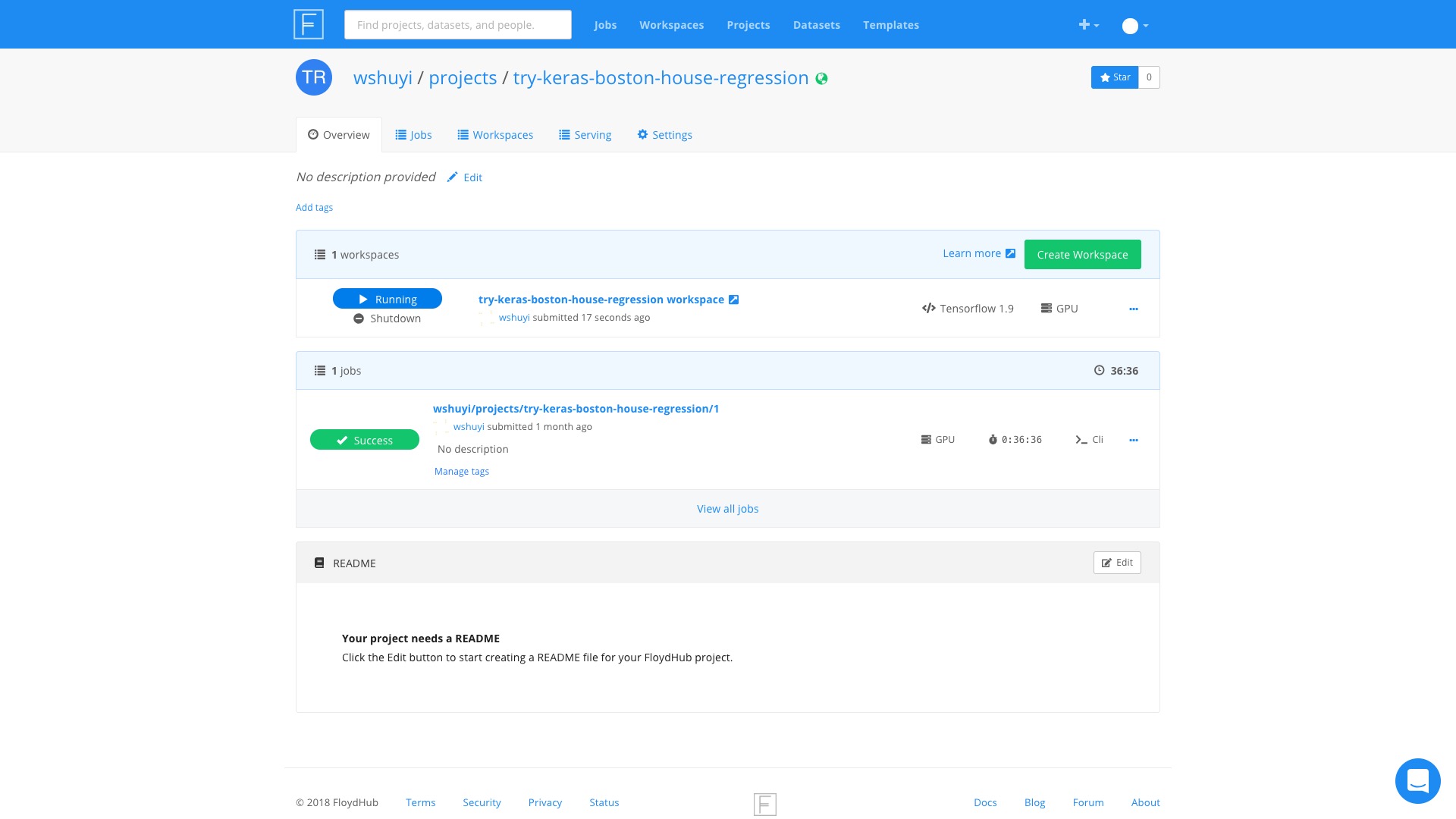
点击 try-keras-boston-house-regression workspace 这个链接。
我们就可以看到,一个 Jupyter Lab 界面为我们准备好了。
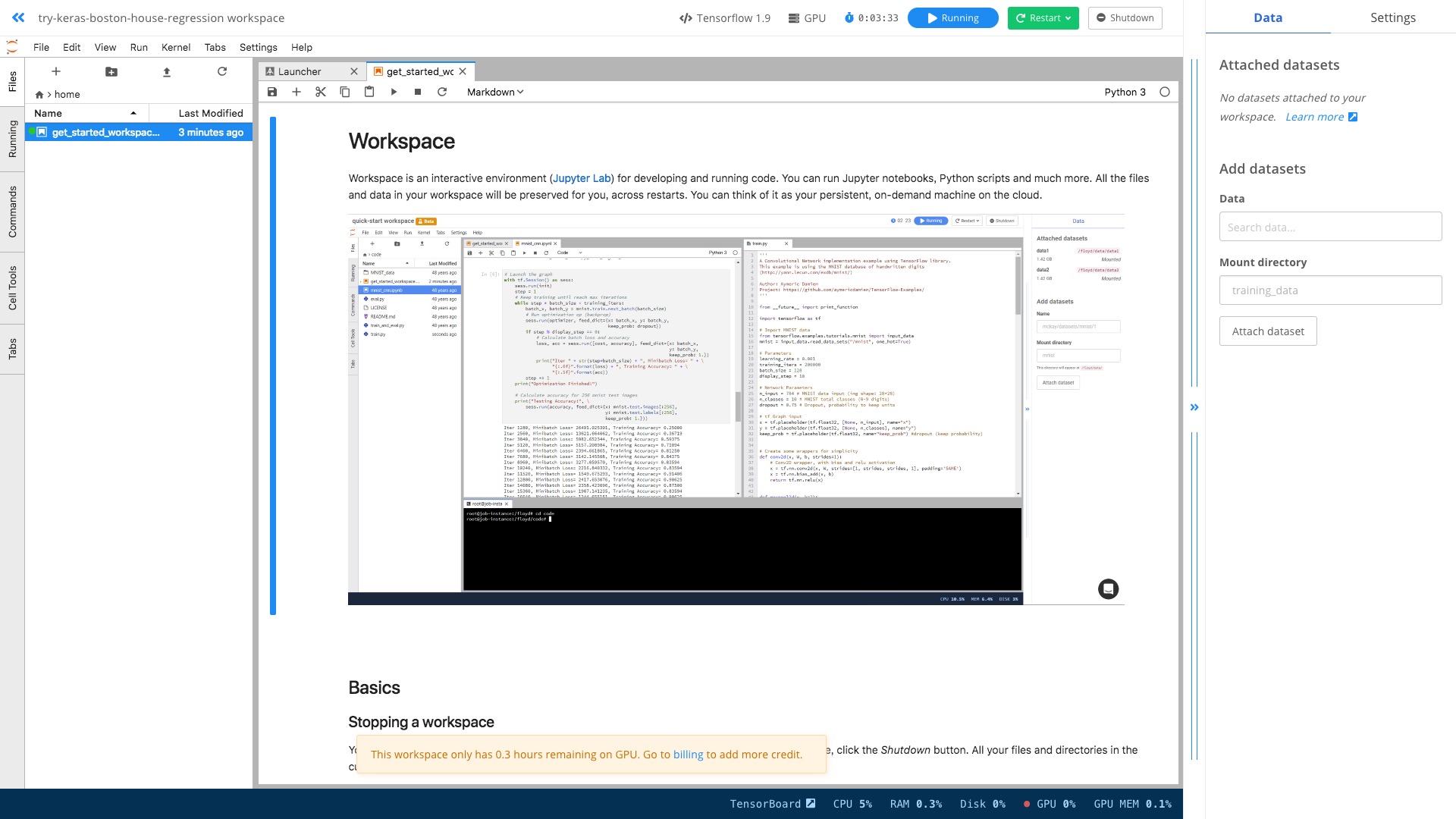
这个环境里面,Tensorflow 和 GPU 的配置都是现成的。
你不用去考虑如何执行 CLI 命令,只需要在其中像平时一样输入 Python 代码,调用 Keras 与 Tensorflow 命令就可以了。
是不是更方便呢?
利用 Floydhub ,开始你的深度学习之旅吧。
小结
做深度学习任务,不一定非得自己购置设备。主要看具体需求。
假如你不需要全天候运行深度学习代码,只是偶尔才遇到计算开销大的任务,这种云端 GPU ,是更为合适的。
你花钱买了深度学习硬件设备,就只有贬值的可能。而且如果利用率低,也是资源浪费。
而同样的租赁价格,你可以获得的计算能力,却是越来越强的。
这就是摩尔定律的威力吧。
你用没用过其他的云端 GPU 服务?价格和易用程度,与 FloydHub 相较如何?
如果你对数据科学感兴趣,欢迎阅读我的系列教程。索引贴为《如何高效入门数据科学?》。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
