
本文为你介绍,如何在 GPU 深度学习云服务里,上传和使用自己的数据集。
疑问
《如何用云端 GPU 为你的 Python 深度学习加速?》一文里,我为你介绍了深度学习环境服务 FloydHub 。
文章发布后,有读者在后台提出来两个问题:
- 我没有外币信用卡,免费时长用完后,无法续费。请问有没有类似的国内服务?
- 我想使用自己的数据集进行训练,该怎么做?
第一个问题,有读者替我解答了。
我看了一下,这里的 Russell Cloud ,确实是一款跟 FloydHub 类似的 GPU 深度学习云服务。
可是感谢之后,我才发现原来他是 Russell Cloud 的开发人员。
于是这几天,使用中一遇到问题,我就直接找他答疑了。
因为有这种绿色通道,响应一直非常迅速。用户体验很好。
这款国内服务的优势,有以下几点:
首先是可以支付宝与微信付款,无需 Visa 或者 Mastercard 信用卡,很方便;
其次是 Russell Cloud 基于阿里云,访问速度比较快,而且连接稳定。在上传下载较大规模数据的时候,优势比较明显。与之相比,FloydHub 上传500MB左右数据的时候,发生了两次中断。
第三是文档全部用中文撰写,答疑也用中文进行。对英语不好的同学,更友好。
第四是开发团队做了微创新。例如可以在微信小程序里面随时查看运行结果,以及查询剩余时长信息。

解决了第一个问题后,我用 Russell Cloud 为你演示,如何上传你自己的数据集,并且进行深度学习训练。
注册
使用之前,请你先到 Russell Cloud 上注册一个免费账号。
因为都是中文界面,具体步骤我就不赘述了。
注册成功后,你就拥有了1个小时的免费 GPU 使用时长。
如果你用我的邀请链接注册,可以多获得4个小时免费 GPU 使用时间。
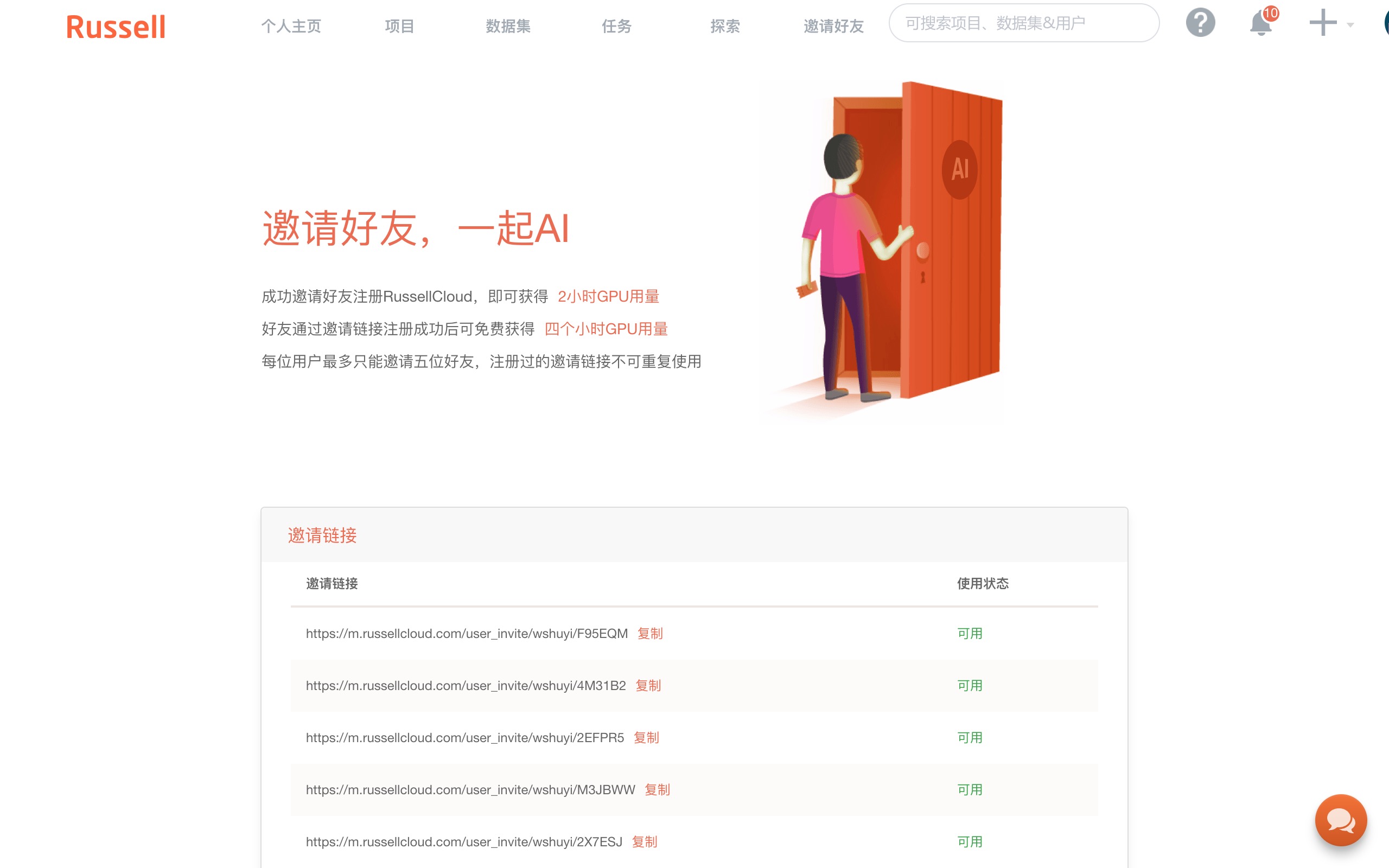
我手里只有这5个可用的邀请链接。你如果需要,可以直接输入。
看谁手快吧。
注册之后,进入控制台,你可以看到自己的相关信息。
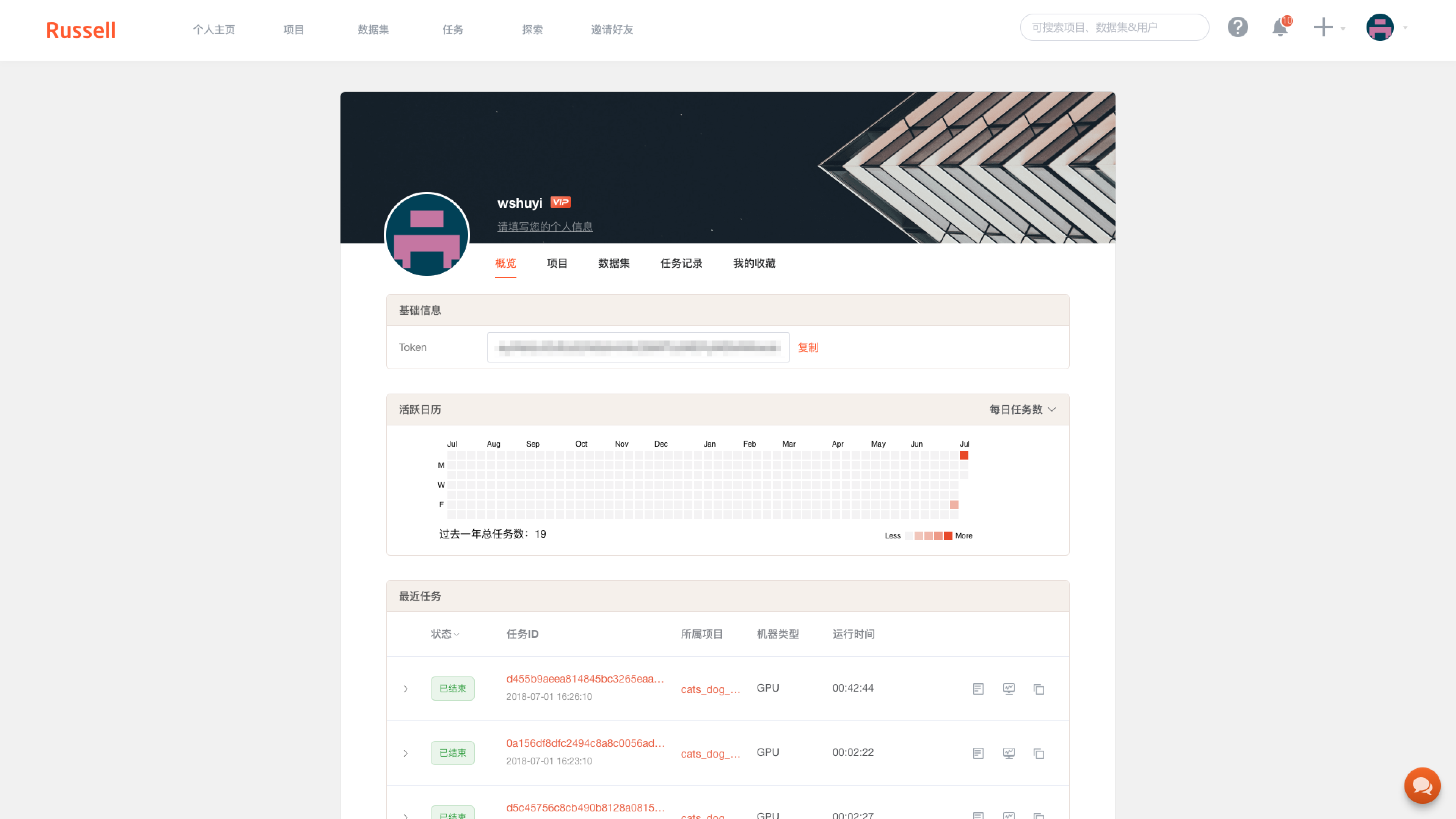
其中有个 Token 栏目,是你的登录信息。下面我给你讲讲怎么用。
你需要下载命令行工具,方法是进入终端,执行:
pip install -U russell-cli
然后你需要登录:
russell login
这时候根据提示,把刚才的 Token 输入进去,登录就完成了。
与 FloydHub 不同,大多数情况下 Russell Cloud 的身份与项目验证,用的都是这种 Token 的方式。
如果你对终端命令行操作还不是很熟悉,欢迎参考我的《如何安装Python运行环境Anaconda?(视频教程)》,里面有终端基本功能详细执行步骤的视频讲解。
环境
下文用到的数据和执行脚本,我都已经放到了这个 gitlab 链接。
你可以直接点击这里下载压缩包,之后解压。
解压后的目录里,包含两个子文件夹。
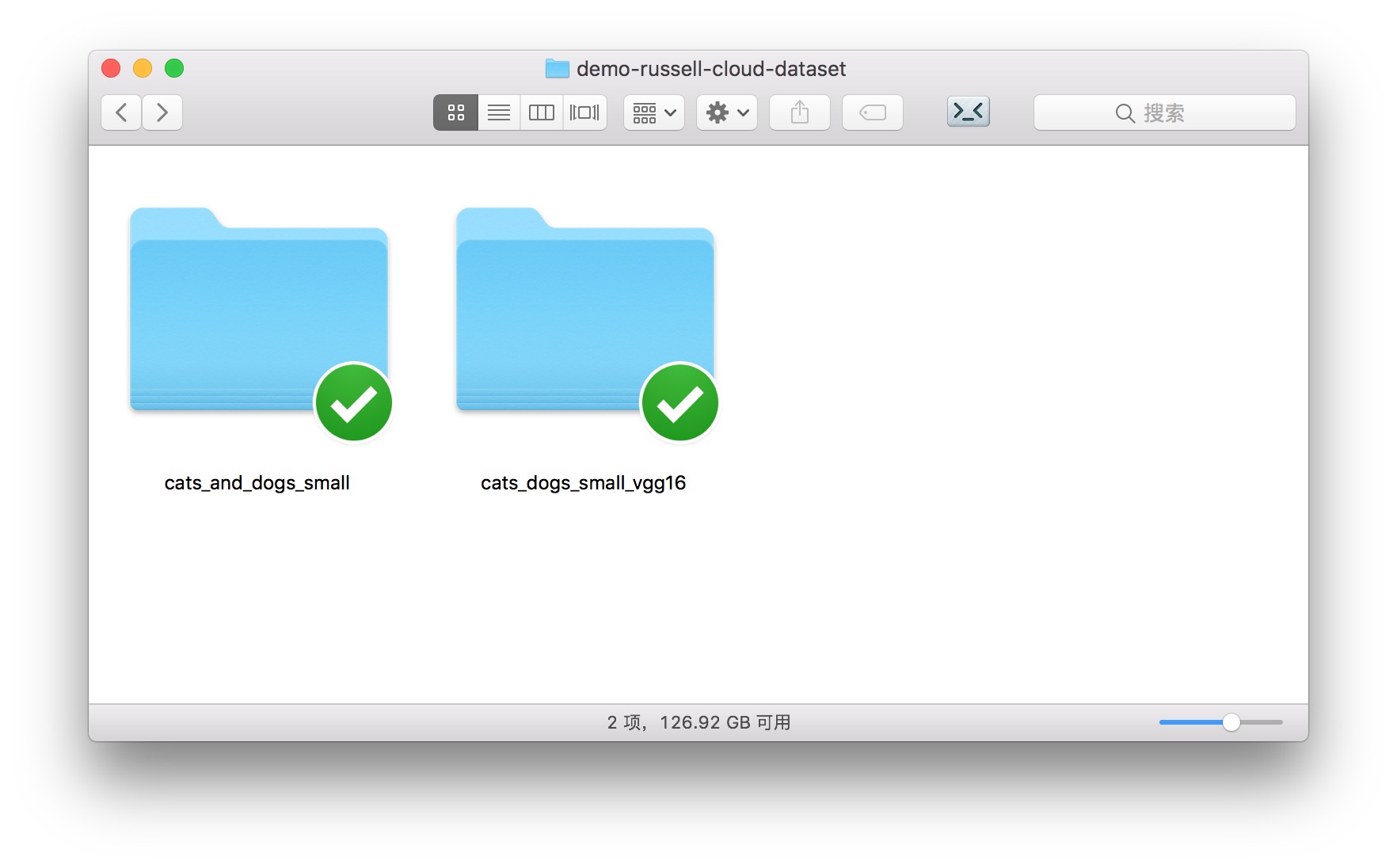
cats_dogs_small_vgg16 包含我们的运行脚本。只有一个文件。
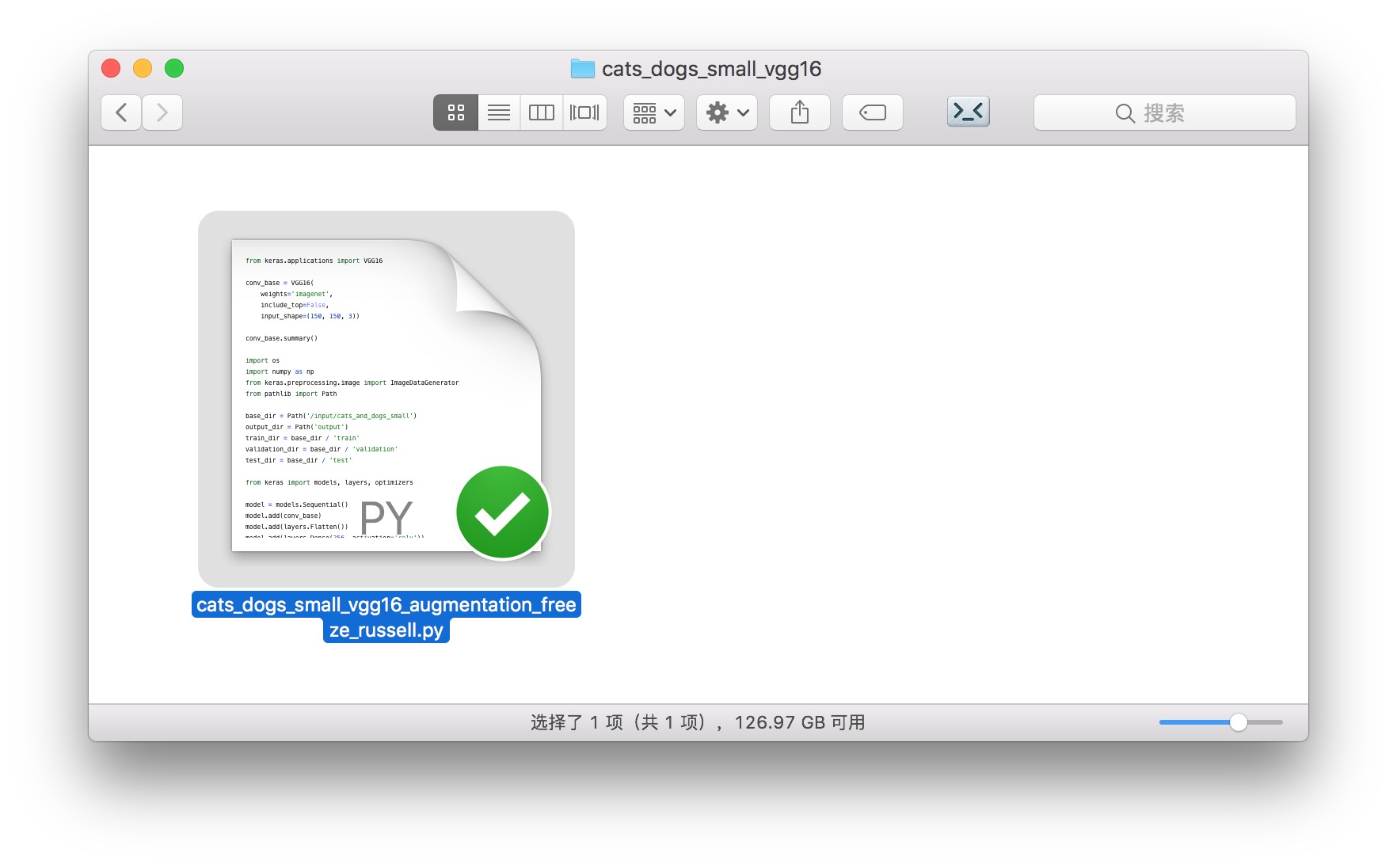
它的使用方法,我们后面会介绍。
先说说,你最关心的数据集上传问题。
数据
解压后目录中的另一个文件夹,cats_and_dogs_small,就包含了我们要使用和上传的数据集。
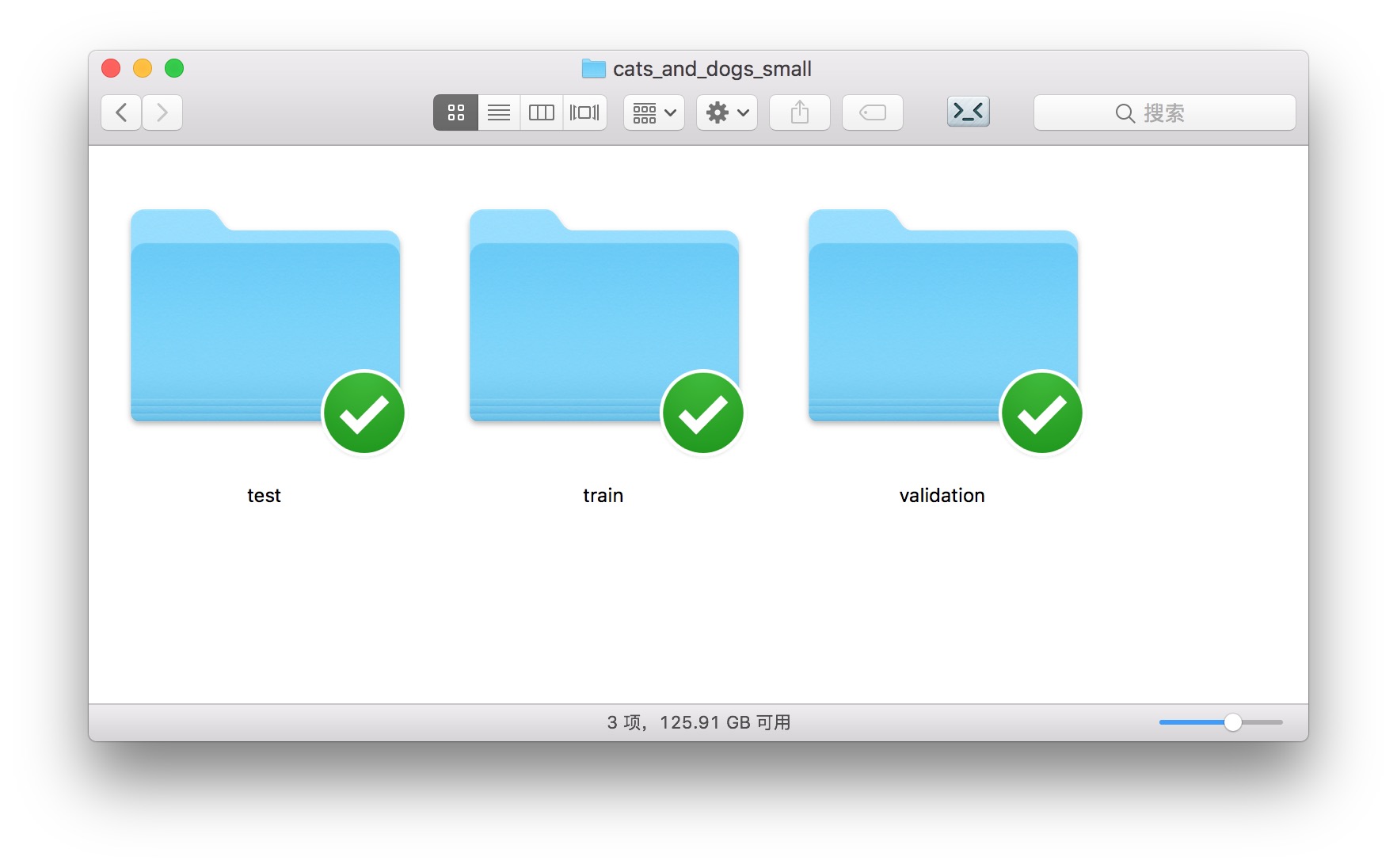
如上图所示,图像数据被分成了3类。
这也是 Keras 默认使用的图像数据分类标准规范。
打开训练集合 train ,下面包含两个目录,分别是“猫”和“狗”。
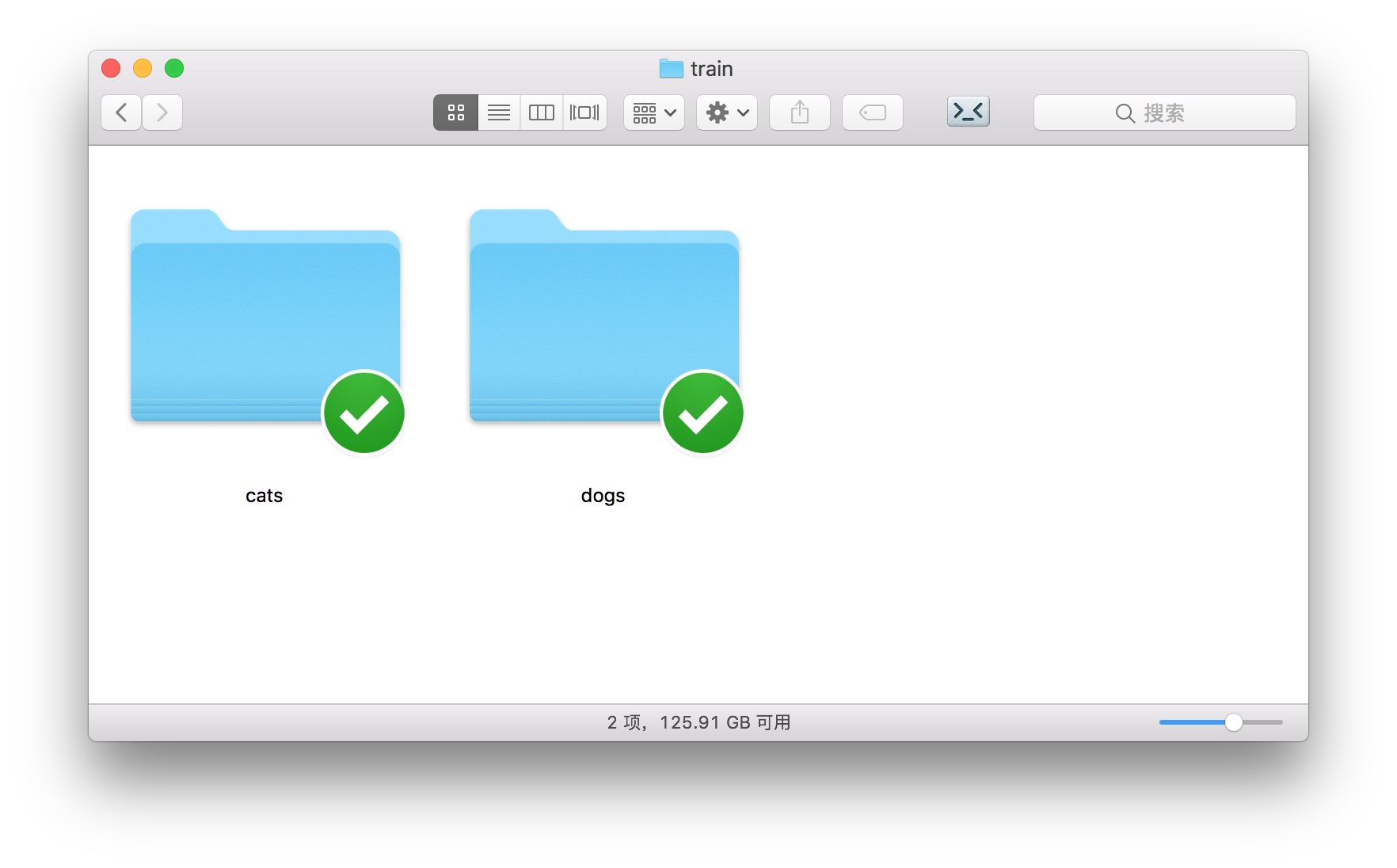
当你使用 Keras 的图片处理工具时,拥有这样的目录结构,你就可以直接调用 ImageDataGenerator 下的flow_from_directory 功能,把目录里的图片数据,直接转化成为模型可以利用的张量(tensor)。
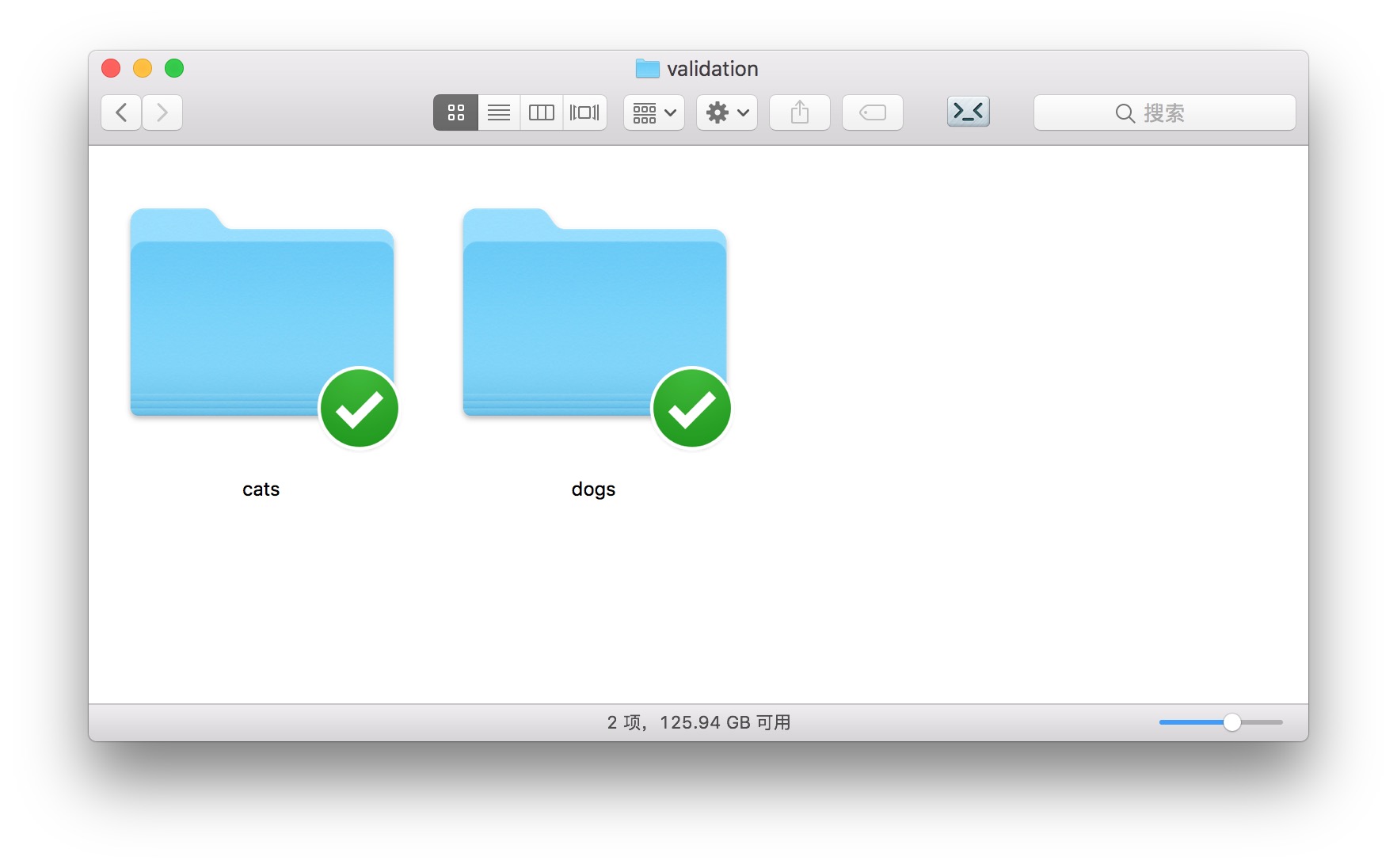
打开 test 和 validation 目录,你会看到的目录结构和 train 相同。
请你先在 Russell Cloud 上建立自己的第一个数据集。
主页上,点击“控制台”按钮。
在“数据集”栏目中选择“创建数据集”。
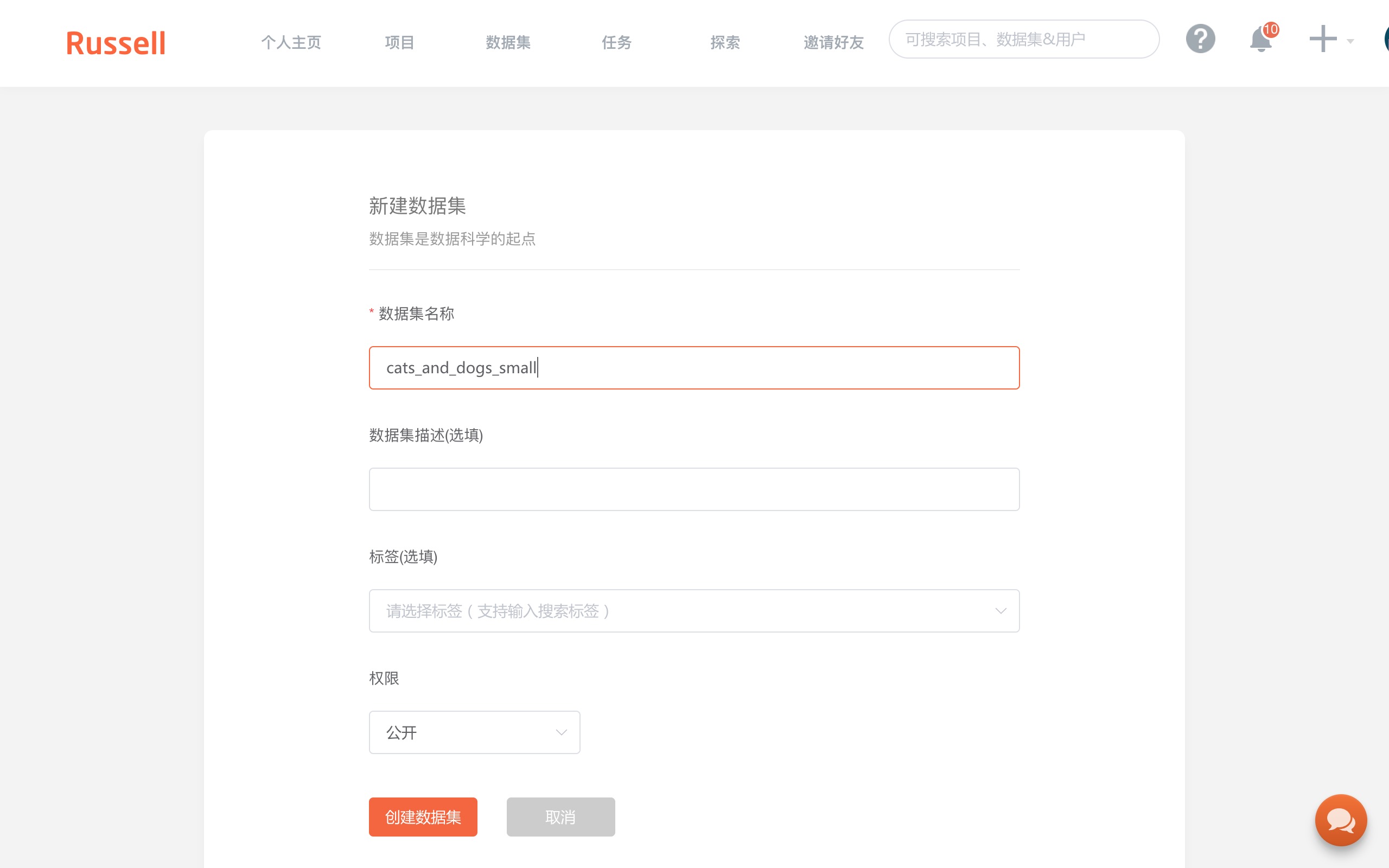
如上图,填写数据集名称为“cats_and_dogs_small”。
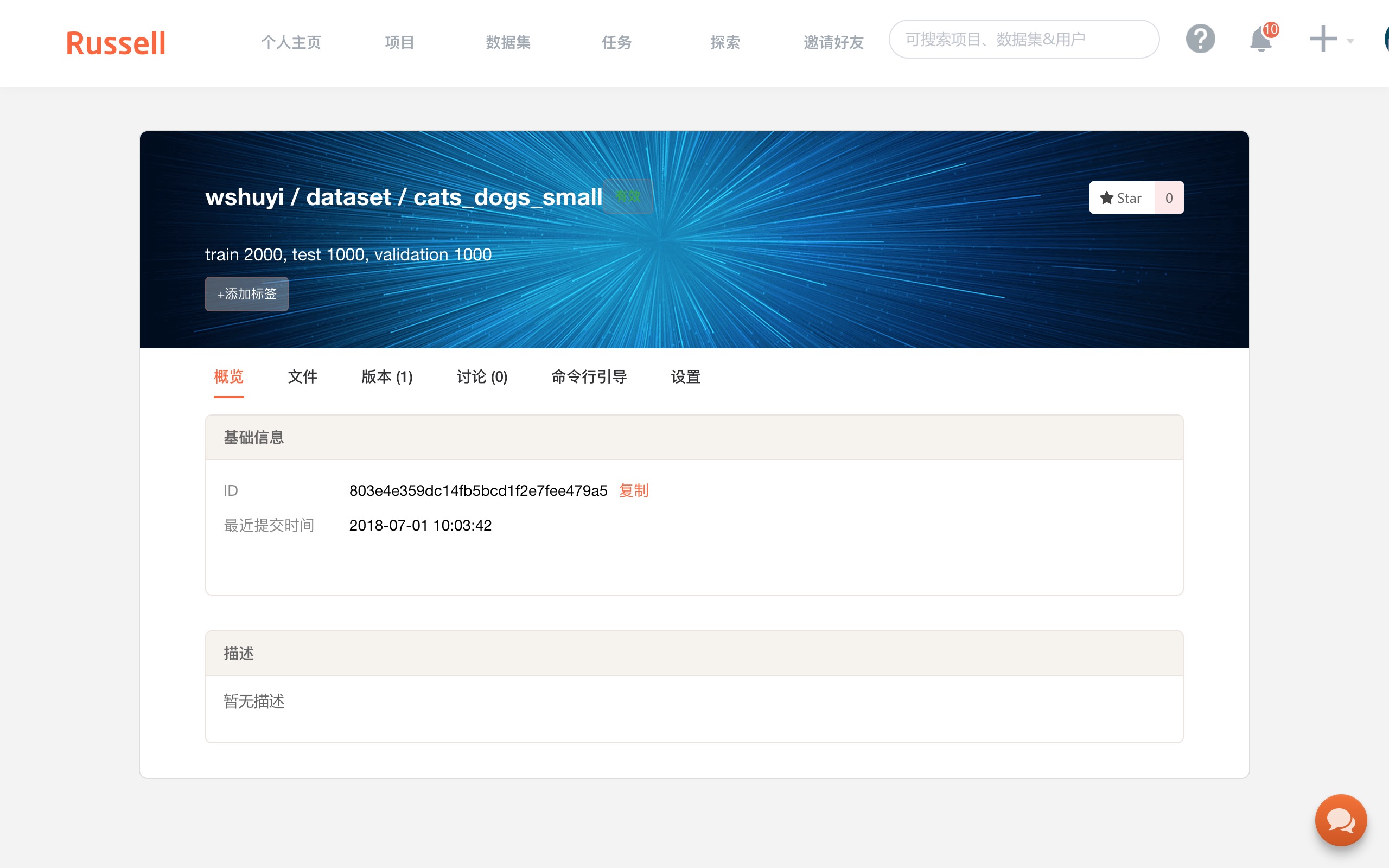
这里会出现数据集的 ID ,我们需要用它,将云端的数据集,跟本地目录连接起来。
回到终端下面,利用 cd 命令进入到解压后文件夹的 cats_and_dogs_small 目录下,执行:
russell data init --id 你的数据集ID
russell data upload
请把上面“你的数据集ID”替换成你真正的数据集ID。
执行这两条命令,数据就被上传到了 Russell Cloud。
上传成功后,回到 Russell Cloud 的数据集页面,你可以看到“版本”标签页下面,出现了1个新生成的版本。
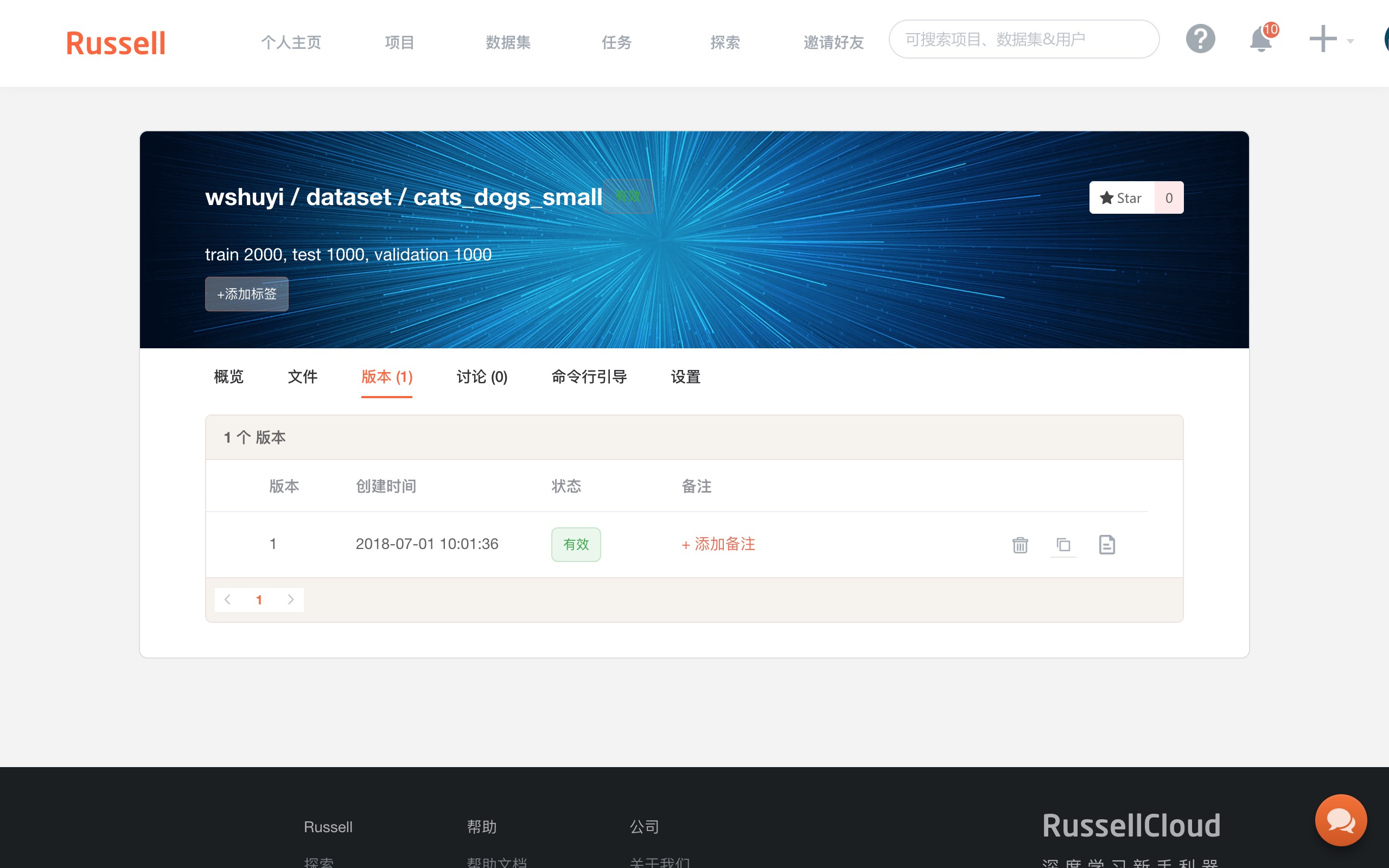
注意上图右侧,有一个“复制”按钮,点击它,复制数据集该版本的 Token 。
一定要注意,是从这里复制信息,而不是数据集首页的 ID 那里。
之前因为搞错了这个事儿,浪费了我很长时间。
运行
要执行你自己的深度学习代码,你需要在 Russell Cloud 上面,新建一个项目。
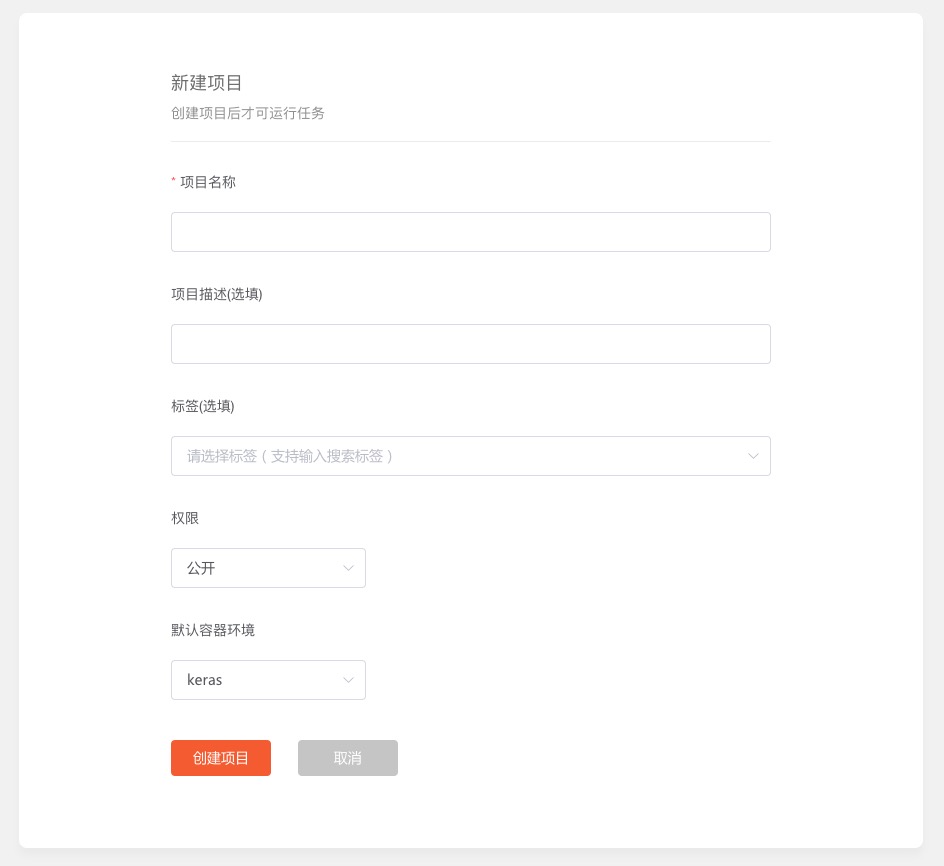
你得给项目起个名称。
可以直接叫做 cats_dog_small_vgg16。
其他项保持默认即可,点击“创建项目”。
出现下面这个页面,就证明项目新建成功。
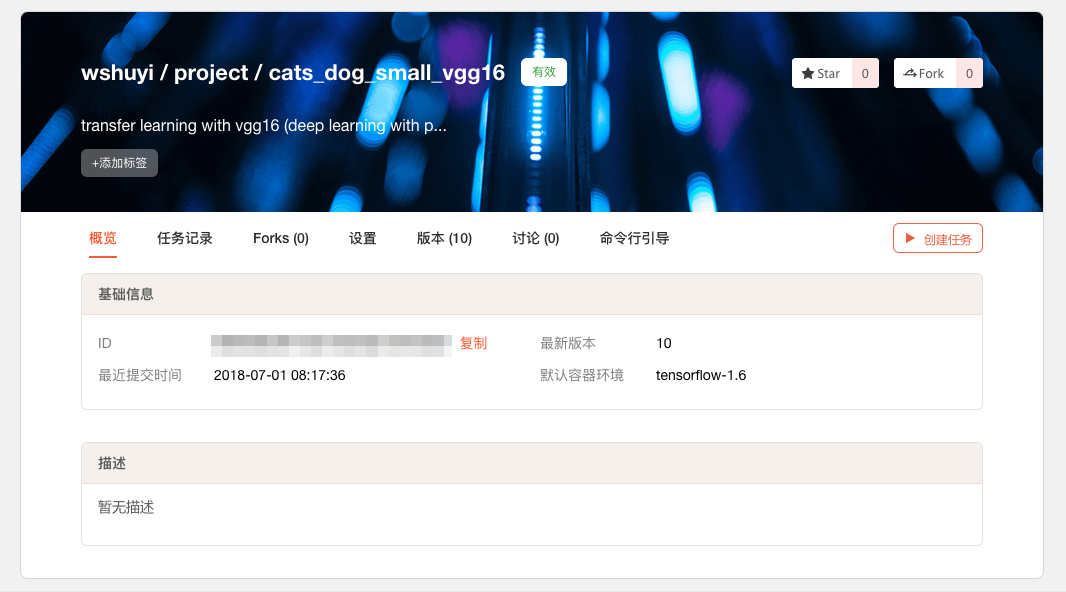
同样,你需要把本地的代码文件夹,和刚刚新建的项目连接起来。
方法是这样的:
复制上图页面的 ID 信息。
回到终端下,利用 cd 命令进入到解压后文件夹的 cats_dogs_small_vgg16 目录下,执行:
russell init --id 你刚才复制的ID
这样,你在本地的修改,就可以被 Russell Cloud 记录,并且更新任务运行配置了。
执行下面这条命令,你就可以利用 Russell Cloud 远端的 GPU ,运行卷积神经网络训练脚本了。
russell run "python cats_dogs_small_vgg16_augmentation_freeze_russell.py" --gpu --data 92e239eca8e649928610d95d54bb3602:cats_and_dogs_small --env tensorflow-1.4
解释一下这条命令中的参数:
-
run后面的引号包括部分,是实际执行的命令; -
gpu是告诉 Russell Cloud,你选择 GPU 运行环境,而不是 CPU; -
data后面的数字串(冒号之前),是你刚刚生成的数据集版本的对应标识;冒号后面,是你给这个数据集挂载目录起的名字。假设这里挂载目录名字叫“potato”,那么在代码里面,你的数据集位置就是“/input/potato”; -
env是集成深度学习库环境名称。我们这里指定的是 Tensorflow 1.4。更多选项,可以参考文档说明。
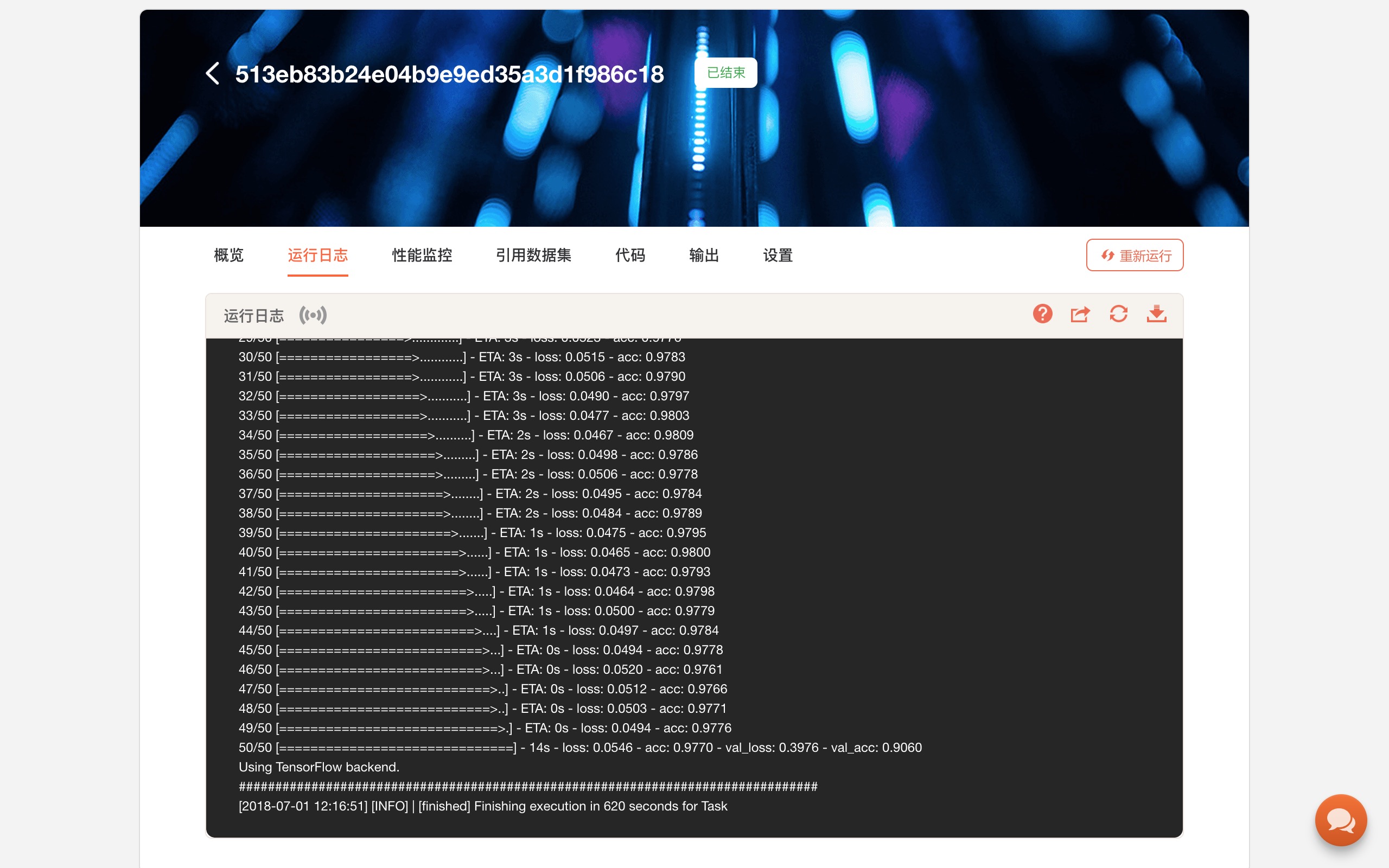
输入上述命令后, Russell Cloud 就会把你的项目代码同步到云端,然后根据你指定的参数执行代码。
你在本地,是看不到执行结果的。
你需要到网页上,查看“任务”下“运行日志”,在系统提供的模拟终端下,查看运行输出结果。
为了把好不容易深度学习获得的结果保存下来,你需要用如下语句保存模型:
saved_model = output_dir / 'cats_and_dogs_small_finetune.h5'
model.save(saved_model)
history.history 对象里,包含了训练过程中的一些评估数据,例如准确率(acc)和损失值(loss),也需要保存。
这里你可以采用 pickle 来完成:
import pickle
with open(Path(output_dir, 'data.pickle'), 'wb') as f:
pickle.dump(history.history, f)
细心的你,一定发现了上述代码中,出现了一个 output_dir, 它的真实路径是 output/。
它是 Russell Cloud 为我们提供的默认输出路径。存在这里面的数据,在运行结束后,也会在云端存储空间中保存下来。
你可以在“任务记录”的“输出”项目下看到保存的数据。它们已被保存成为一个压缩包。
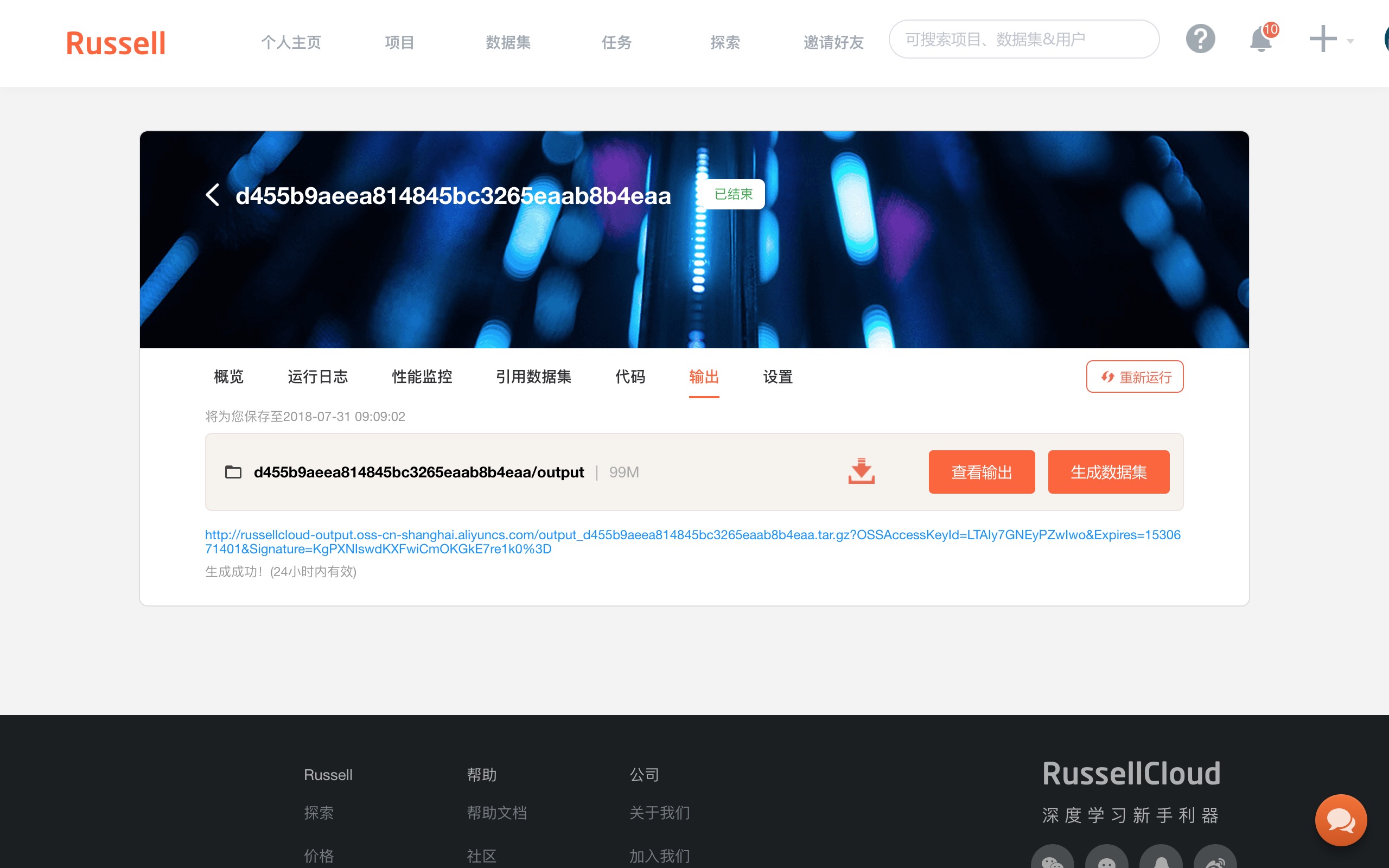
下载下来并解压后,你就可以享受云端 GPU 的劳动果实了。
你可以用 history 保存的内容绘图,或者进一步载入训练好的模型,对新的数据做分类。
改进
在实际使用Russell Cloud中,你可能会遇到一些问题。
我这里把自己遇到的问题列出来,以免你踩进我踩过的坑。
首先,深度学习环境版本更新不够及时。
本文写作时 Tensorflow 稳定版本已经是 1.8 版,而 Russell Cloud 最高支持的版本依然只有 1.6。文档里面的最高版本,更是还停留在 1.4。默认的 Keras,居然用的还是 Python 3.5 + Tensorflow 1.1。
注意千万别直接用这个默认的 Keras ,否则 Python 3.6 后版本出现的一些优秀特性无法使用。例如你将 PosixPath 路径(而非字符串)作为文件地址参数,传入到一些函数中时,会报错。那不是你代码的错,是运行环境过于老旧。
其次,屏幕输出内容过多的时候(例如我跑了 100 个 epoch, 每个显示 100 条训练进度),“运行日志”网页上模拟终端往下拉,就容易出现不响应的情况。变通的方法,是直接下载 log 文件,阅读和分析。
第三,Keras 和 Tensorflow 的许多代码库(例如使用预训练模型),都会自动调用下载功能,从 github 下载数据。但是,因为国内的服务器到 github 之间连接不够稳定,因此不时会出现无法下载,导致程序超时,异常退出。
上述问题,我都已经反馈给开发者团队。对方已表示,会尽快加以解决。
如果你看到这篇文章时,上面这些坑都不存在了,那就再好不过了。
小结
本文为你推荐了一款国内 GPU 深度学习云服务 Russell Cloud 。如果你更喜欢读中文文档,没有外币信用卡,或是访问 FloydHub 和 Google Colab 不是很顺畅,都可以尝试一下。
通过一个实际的深度学习模型训练过程,我为你展示了如何把自己的数据集上传到云环境,并且在训练过程中挂载和调用它。
你可以利用平台赠送的 GPU 时间,跑一两个自己的深度学习任务,并对比一下与本地 CPU 运行的差别。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。




