前言
这篇是MySQL 数据库规范的最后一篇--调优篇,旨在提供我们发现系统性能变弱、MySQL系统参数调优,SQL脚本出现问题的精准定位与调优方法。
哈哈,文尾有福利彩蛋哦
目录
1.MySQL 调优金字塔理论
2.MySQL 慢查询分析--mysqldumpslow、pt_query_digest工具的使用(SQL脚本层面)
3.选择合适的数据类型
4.去除无用的索引--pt_duplicate_key_checker工具的使用(索引层面)
5.反范式化设计(表结构)
6.垂直水平分表
7.MySQL 重要参数调优(系统配置)
1.MySQL 调优金字塔理论
如下图所示:
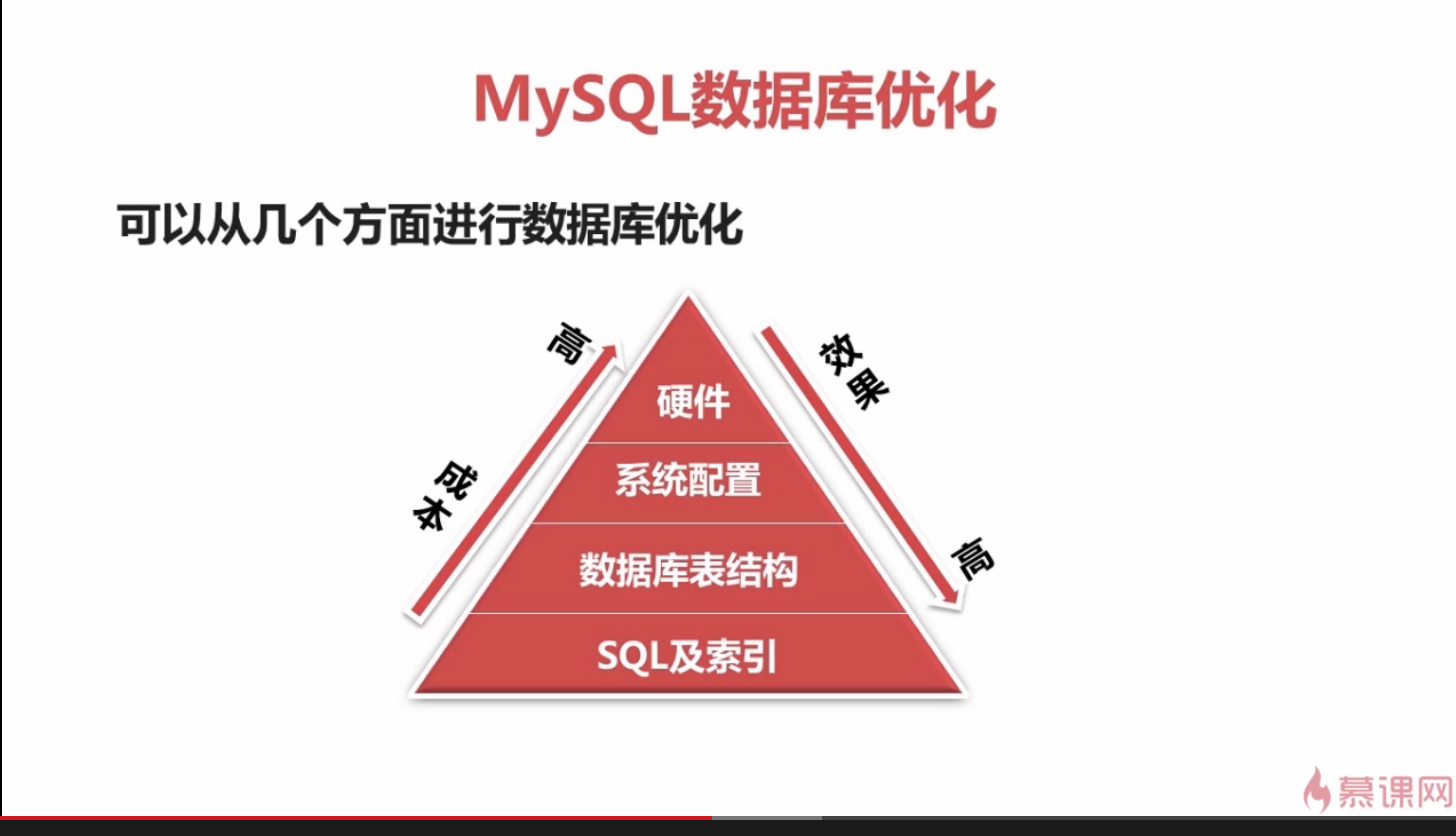
如上图所示:
数据库优化维度有四个:
硬件、系统配置、数据库表结构、SQL及索引
优化成本:
硬件>系统配置>数据库表结构>SQL及索引
优化效果:
硬件<系统配置<数据库表结构<SQL及索引
2.MySQL 慢查询分析
对于系统中慢查询的分析,有助于我们更高效的定位问题,分析问题。
mysqldumpslow、pt_query_digest是进行慢查询分析的利器。
前置条件
1.查看本机MySQL Server 慢查询是否打开
show variables like 'slow%';
慢查询打开的情况如下所示:
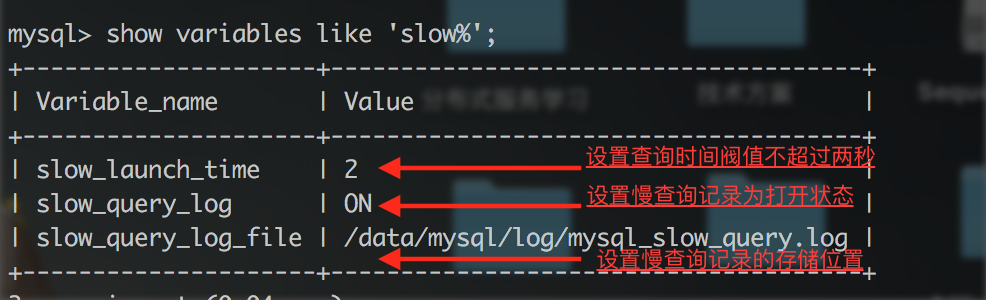
若慢查询未打开则通过如下脚本设置慢查询:
set global slow_query_log = on;
即
set global [上图中选项] = [你要设置的参数值]
注意 slow_query_log_file 路径要加单引号,因为路径varchar 类型的。
2.1 mysqldumpslow分析慢查询
mysqldumpslow 是MySQL自带的分析数据库慢查询的原生利器,使用方法如下:
mysqldumpslow -t 3 /data/mysql/log/mysql_slow_query.log | more \G;
-t 3 显示前3条慢查询。
慢查询信息及分析

但是 mysqldumpslow 显示的信息比较少,比如说此条sql执行次数在整体的执行次数中占用的百分比。类似于上述信息在 mysqldumpslow 的分析结果中是不存在的。
接下里我们介绍另一种工具 pt_query_digest
2.2 pt_query_digest分析慢查询
之所以使用 pt_query_digest 工具对慢查询日志进行分析,主要原因是上述工具分析的内容更佳丰富,更加方便我们分析慢查询。
前置条件
安装 pt_query_digest ,Google搜索应该一大把。
确保 pt_query_digest 安装成功 执行如下操作:
pt-query-digest /data/mysql/log/mysql_slow_query.log > slow_log.report
上述命令表示分析本机慢查询,并输出报表(文件)
接下来分析生成的报表:
tail slow_log.report
按如下图所示信息:
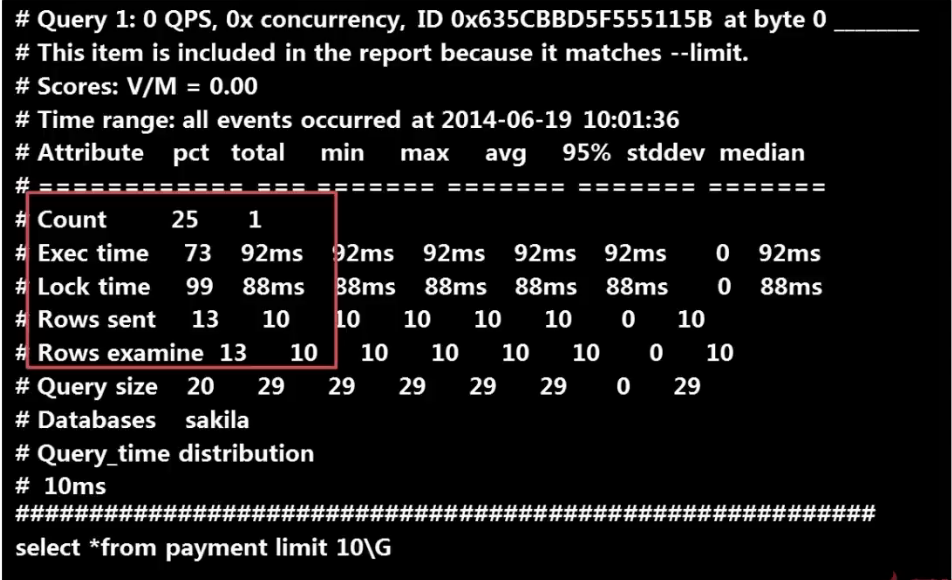
我们对以上红色框图标记的报表信息进行详细描述,事实上这也是我们需要掌握的重点:
1.pct :sql语句某执行属性占所有慢查询语句某执行属性的百分比
1.total:sql语句某执行属性的所有属性时间。
2.Count:sql语句执行的次数,对应的pct 表示此sql 语句执行次数占所有慢查询语句执行次数的%比。上图为25%,total:表示总共执行了1次。
3.Exec time:sql执行时间
4.Lock time:sql执行期间被锁定的时间
5.Rows sent:传输的有效数据,在select 查询语句中才有值
6.Rows examine:总共查询的数据,非目标数据。
7.Query_time distribution:查询时间分布
8.SQL 语句:上图中为 select * from payment limit 10\G;
举例说明:加入某执行次数(count) 占比较高的sql语句,执行时间很长,Rows sent 数值很小,Rows examine 数值很大则表明(I/O较大)。那就表明有可能 sql 查询语句走了全表扫描,或者全索引扫描。那么就要建立合适索引或者优化sql语句了。
如下很好的展示了我们在分析慢查询时需要着重分析的三点:

3.选择合适的数据类型
可以参考MySQL开发规范--设计篇中的1.6 数据表设计与规划
如下图是常用字段类型的选择建议:

4.去除无用的索引--pt_duplicate_key_checker工具的使用(索引层面)
此工具可以分析选定的 database 中的所有表中建立的index 中可能重复的索引,并给出了删除建议。
5.反范式化设计(表结构)
关于范式的理解,请参考--MySQL 数据库规范--设计篇1.1 数据库表的设计范式(三范式&反范式)
先看一个不满足第三范式的数据表设计:
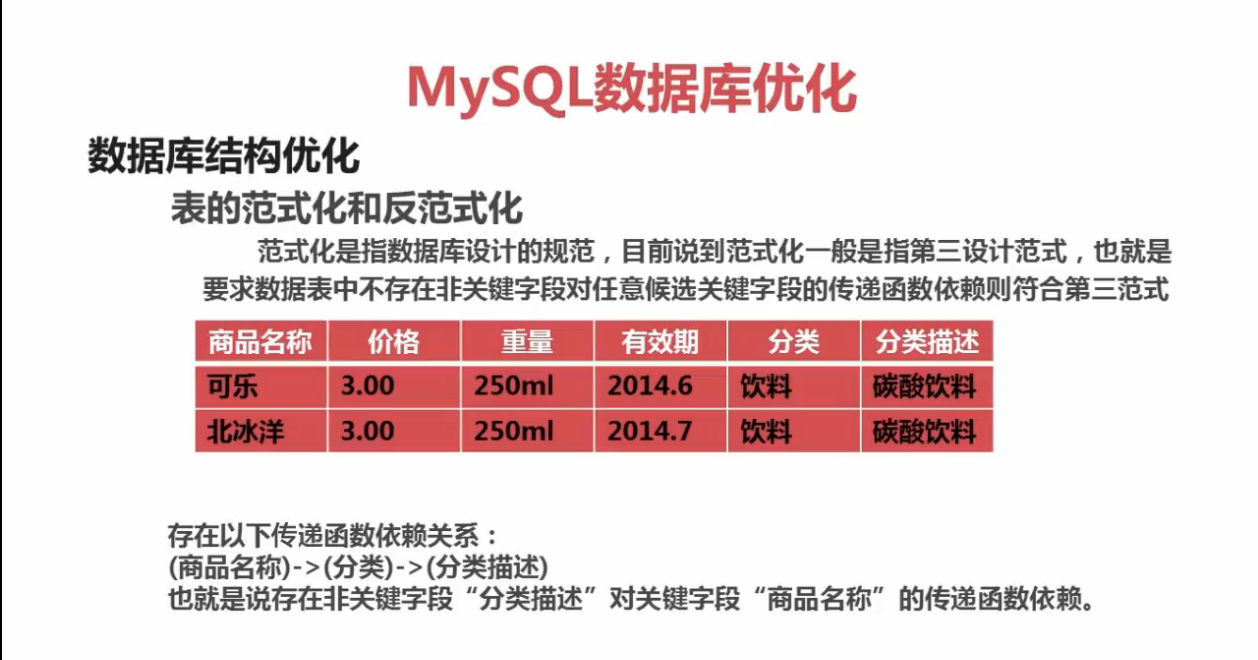
不满足第三范式产生的问题:
假如将表中属于饮料分类的数据全部删除了,那么饮料分类也就不存在了,饮料的分类描述也就没了,查询不到了。这明显是不合理的。
重点:满足第三范式要求非键属性之间没有任何依赖关系,上图中分类与分类描述存在直接依赖关系。所以不符合第三范式的要求,那么要让表符合第三范式需要怎样做呢?
拆分后满足第三范式的表:
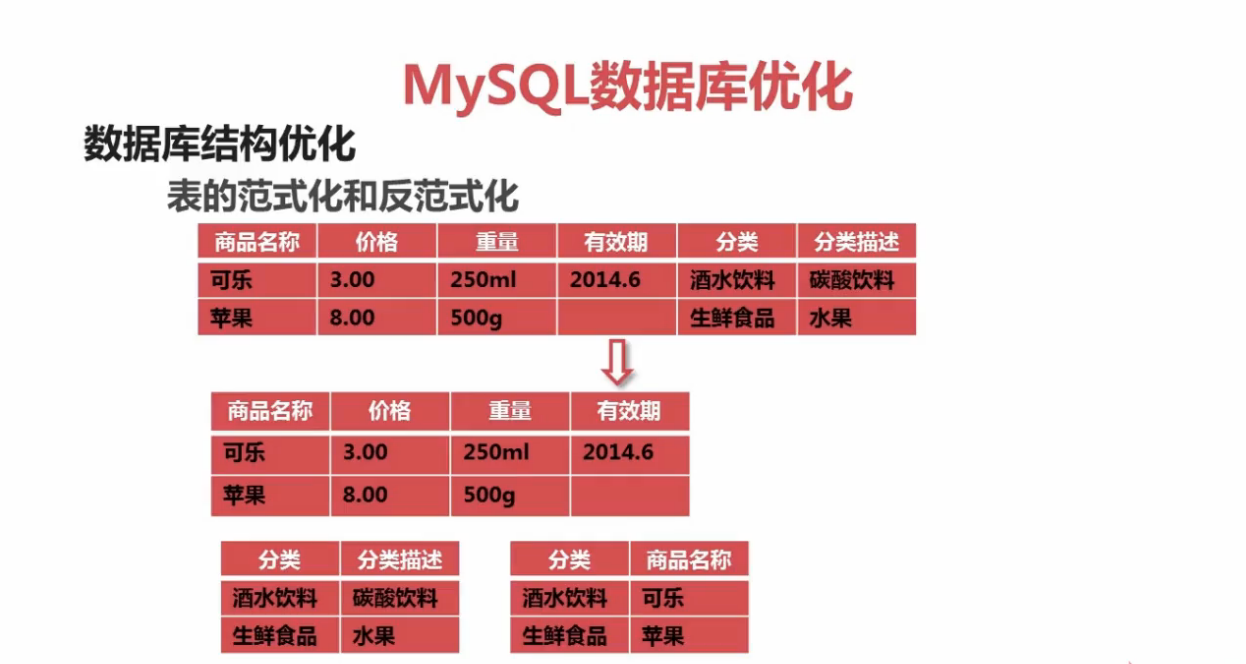
我们采用一张 分类--商品名称 中间表来充当分表之后的中间桥梁。
当然如果一直遵循范式化设计,什么设计都向第三范式靠拢,当查询需要连接很多表的时候,建立索引已经起不到什么作用了,因为字段都不在同一张表中,所以建立索引是无用功,那么就要考虑反范式化的设计了。
6.垂直、水平分表
原则上当表中数据记录的数量超过3000万条,再好的索引也已经不能提高数据查询的速度了,这时候就需要将表拆分成更多的小表,来进行查询。
分表的机制有两种:
垂直分表:也就是将一部分列割裂开将数据放置在新设置的表中,优先选择字段值长度较长,类型较重的字段进行垂直分离。
水平分表:将表中数据水平切分,可以按照范围、取模运算、hash运算进行数据切割,每张表的结构信息都是一样的。
7.MySQL 重要参数调优(系统配置)
7.1 操作系统配置优化


简要介绍一下:
1.tcp连接配置,超时时间配置
2.linux上文件打开数量限制
3.除此之外,最好在MySQL 服务器上关闭iptables,selinux 等防火墙软件。
7. 2 MySQL 配置文件优化
MySQL 可以通过启动时制定配置参数和使用配置文件两种方法进行配置,在大多数情况下配置文件位于/etc/my.cnf或是/etc/mysql/my.cnf MySQL查找配置文件顺序可以通过以下方法获得:
$ /usr/sbin/mysqld --verbose --help | grep -A 1 'Default options'
注意:如果多个位置存在配置文件,后面的会覆盖前面的
7.2.1 innodb_buffer_pool_size
innodb_buffer_pool_size 是非常重要的一个参数,用户配置Innodb 的缓冲池大小。如果数据库中只有Innodb表,则推荐配置量为总内存的75%。
一般情况下运行如下命令,即可获得配置innodb_buffer_pool_size 参数的最佳值:
select engine round(sum(data_length+index_length)/1024/1024,1) as
'total MB' from information_schema.tables where table_schema not in ("information_schema","performance_schema") group by engine;
Innodb_buffer_pool_size > Total MB;
7.2.2 innodb_buffer_pool_instance
MySQL 系统中有一些资源是需要独占使用的,比如缓冲去就是这样一种资源,因此如果系统中只有一个缓冲池,那么会增加阻塞的几率。我们多分成多个,则可以增加并发性能。
7.2.3 innodb_log_buffer_size
innodb log缓冲的大小,设置大小只能能容得下1s中产生的事务日志就可以。
7.2.4 innodb_flush_log_at_trx_commit
关键参数,对innodb 的I/O影响很大。默认值为1,可以去0,1,2三个值,一般建议为2,但如果数据安全性要求较高则默认使用1。
- 0:每隔1s中才将事务提交的变更记录刷新到磁盘
- 1:每一次事务提交都把变更日志刷新到磁盘(最安全的方式)
- 2:每一次提交将日志刷新到缓冲区,隔1s之后会将日志刷新到磁盘。
7.2.5 innodb_read_io_threads && innodb_write_io_threads
这两个参数决定了Innodb读写的I/O进程数,默认为4。
决定这两个参数数值的因素也有两个:cpu核数、应用场景中读写事务比例。
7.2.6 innodb_file_per_table
关键参数,默认情况下配置为off。
控制innodb每一个表使用独立的表空间,默认情况下,所有的表都会建立在共享表空间当中。
使用共享表空间会带来什么问题:
1.多个表对共享表空间的操作,是顺序进行的,这样的话操作效率在并发情况下回降低。
2.如果现在要删除一张表,会导致共享表空间先要将数据导出来,再重组。
7.2.7 innodb_stats_on_metadata
作用:决定了MySQL在什么情况下会刷新innodb表的统计信息。
保证数据库优化器能使用到最新的索引,但不能太频繁,一般设置为off。
福利彩蛋
职位:腾讯OMG 广告后台高级开发工程师;
Base:深圳;
场景:海量数据,To B,To C,场景极具挑战性。
基础要求:
熟悉常用数据结构与算法;
熟悉常用网络协议,熟悉网络编程;
熟悉操作系统,有线上排查问题经验;
熟悉MySQL,oracle;
熟悉JAVA,GoLang,c++其中一种语言均可;
可内推,欢迎各位优秀开发道友私信[微笑]
期待关注我的开发小哥哥,小姐姐们私信我,机会很好,平台对标抖音,广告生态平台,类似Facebook 广告平台,希望你们用简历砸我~
联系方式 微信 13609184526
博客搬家:大坤的个人博客
欢迎评论哦~
