一、基本概念:
作用:特征点提取在“目标识别、图像拼接、运动
跟踪、图像检索、自动定位”等研究中起着重要作用;
主要算法:
•
SIFT,
Distinctive
ImageFeatures from Scale-Invariant Keypoints,2004
,invariant to image translation, scaling, and rotation, partially invariant toillumination changes and robust to local geometric distortion
•FREAK
•AKAZE等
其中标红的5项是在OpenCV中已经进行了实现的。
特征点识别主要流程为:
1、检测关键点、提取描述向量和特征匹配;
2、通过检测关键点和提取描述向量构造出局部特征描述子,
3、然后进行特征匹配
二、数据准备:
数据集为pascal中取出的6个数据,分别针对特征点提取的6个方面

其中
特征点识别在以下6个方面进行比较
1、算法匹配速度比较 (ubc)
测试方法:在相同的匹配环境下,即使用同样配置的计算机,对相同的一对图像进行比较,测试算法的执行时间
2、旋转变换鲁棒性比较 (bark)
测试方法:对同一图像进行一定角度的旋转,旋转角度逐步递增,旋转后的图像逐一与原始图像进行匹配,比较能够正确匹配的特征点对数,并观察正确匹配对数的变化幅度
3、模糊变换鲁棒性比较 (bikes)
测试方法:对同一图像用不同的高斯核进行模糊处理,模糊处理后的图像逐一与原始图像进
行匹配,比较能够正确匹配的特征点对数,并观察正确匹配对数的变化幅度
4、光照变换鲁棒性比较 (leuven)
测试方法:对同一图像的亮度进行改变,逐
渐降低亮度,改变亮度后的图像逐一与原始图像进行匹配,比较能够正确匹配的特征点对数,并观察正确匹配对数的变化幅度
5、尺度变换鲁棒性比较 (bark)
测试方法:对原图像的尺度大小进行改变,尺度变化后的图像逐一与原始图像进行匹配,比较能够正确匹配的特征点对数,并观察正确匹配对数的变化幅度
6、视角变换鲁棒性比较 (graf)
测试方法:对原场景转一定角度进行拍摄,不同视角的图像逐一与原始图像进行匹配,比较能够正确匹配的特征点对数,并观察正确匹配对
数的变化幅度
三、实验步骤:
1、依次对各个数据集进行特征点提取并进行两两特征点的比较,也就是match。这个流程是正常的流程,执行的过程中要注意错误控制

//使用img1对比余下的图片,得出结果
img1 = imread(files[0],0);
imgn = imread(files[iimage],0);
//生成特征点算法及其匹配方法
Ptr<Feature2D> extractor;
BFMatcher matcher;
switch (imethod)
{
case 0: //"SIFT"
extractor= SIFT::create();
matcher = BFMatcher(NORM_L2);
break;
case 1: //"SURF"
extractor= SURF::create();
matcher = BFMatcher(NORM_L2);
break;
case 2: //"BRISK"
extractor = BRISK::create();
matcher = BFMatcher(NORM_HAMMING);
break;
case 3: //"ORB"
extractor= ORB::create();
matcher = BFMatcher(NORM_HAMMING);
break;
case 4: //"AKAZE"
extractor= AKAZE::create();
matcher = BFMatcher(NORM_HAMMING);
break;
}
try
{
extractor->detectAndCompute(img1,Mat(),keypoints1,descriptors1);
extractor->detectAndCompute(imgn,Mat(),keypoints2,descriptors2);
matcher.match( descriptors1, descriptors2, matches );
}
catch (CException* e)
{
cout<<" 特征点提取时发生错误 "<<endl;
continue;
}
//对特征点进行粗匹配
double max_dist = 0;
double min_dist = 100;
for( int a = 0; a < matches.size(); a++ )
{
double dist = matches[a].distance;
if( dist < min_dist ) min_dist = dist;
if( dist > max_dist ) max_dist = dist;
}
for( int a = 0; a < matches.size(); a++ )
{
if( matches[a].distance <= max(2*min_dist, 0.02) )
good_matches.push_back( matches[a]);
}
if (good_matches.size()<4)
{
cout<<" 有效特征点数目小于4个,粗匹配失败 "<<endl;
continue;
}
2、对match的结果进行RANSAC提纯计算,计算“内点”。主要是RANSAC提纯的一个过程,这个过程在图像拼接中也是很常见的。

//通过RANSAC方法,对现有的特征点对进行“提纯”
std::vector<Point2f> obj;
std::vector<Point2f> scene;
for( int a = 0; a < (int)good_matches.size(); a++ )
{
//分别将两处的good_matches对应的点对压入向量,只需要压入点的信息就可以
obj.push_back( keypoints1[good_matches[a].queryIdx ].pt );
scene.push_back( keypoints2[good_matches[a].trainIdx ].pt );
}
//计算单应矩阵(在calib3d中)
Mat H ;
try
{
H = findHomography( obj, scene, CV_RANSAC );
}
catch (CException* e)
{
cout<<" findHomography失败 "<<endl;
continue;
}
if (H.rows < 3)
{
cout<<" findHomography失败 "<<endl;
continue;
}
//计算内点数目
Mat matObj;
Mat matScene;
CvMat* pcvMat = &(CvMat)H;
const double* Hmodel = pcvMat->data.db;
double Htmp = Hmodel[6];
for( int isize = 0; isize < obj.size(); isize++ )
{
double ww = 1./(Hmodel[6]*obj[isize].x + Hmodel[7]*obj[isize].y + 1.);
double dx = (Hmodel[0]*obj[isize].x + Hmodel[1]*obj[isize].y + Hmodel[2])*ww - scene[isize].x;
double dy = (Hmodel[3]*obj[isize].x + Hmodel[4]*obj[isize].y + Hmodel[5])*ww - scene[isize].y;
float err = (float)(dx*dx + dy*dy); //3个像素之内认为是同一个点
if (err< 9)
{
innersize = innersize+1;
}
}
3、比较“耗时”和“内点比例”两个因素。其中建立数学模型,就是用"准确率“/“内点比例”,这样得到一个正向的结论。
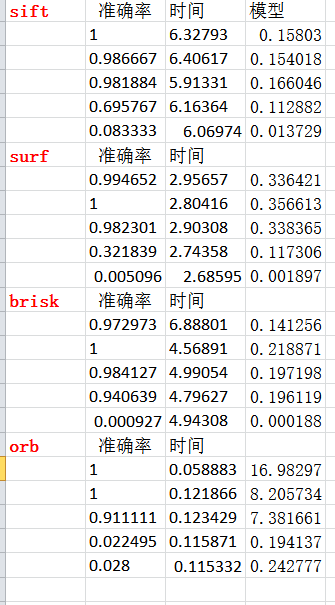
4、结合相关数据,得出综合结论
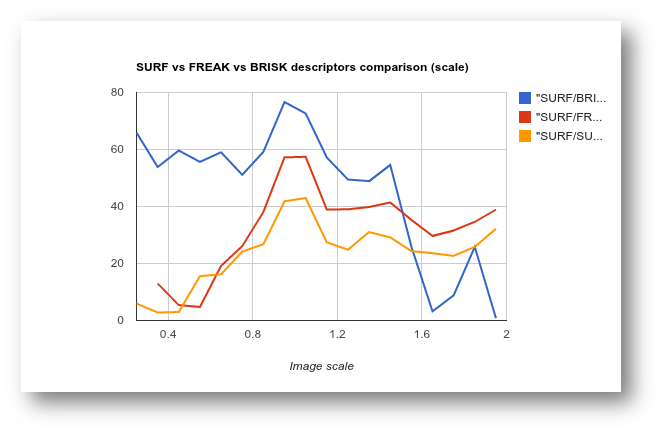
四、实验结果:
1、sift和surf一直提供了较高的准确率,并且结果比较稳定;sift较surf更准一些,但是也有brisk最好的时候;
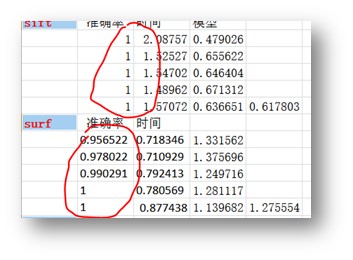
2、orb的速度非常快,但是最容易出现问题;
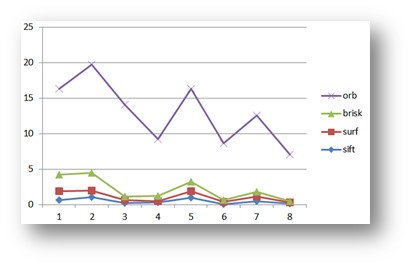
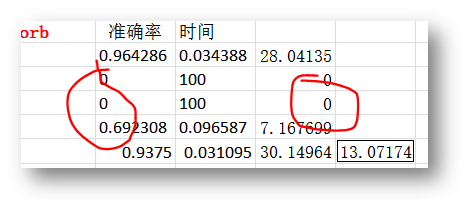
3、AKAZA也很容易出现问题;
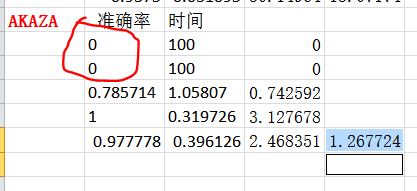
4、其他算法,包括AKAZA,速度的差别都不是很大。
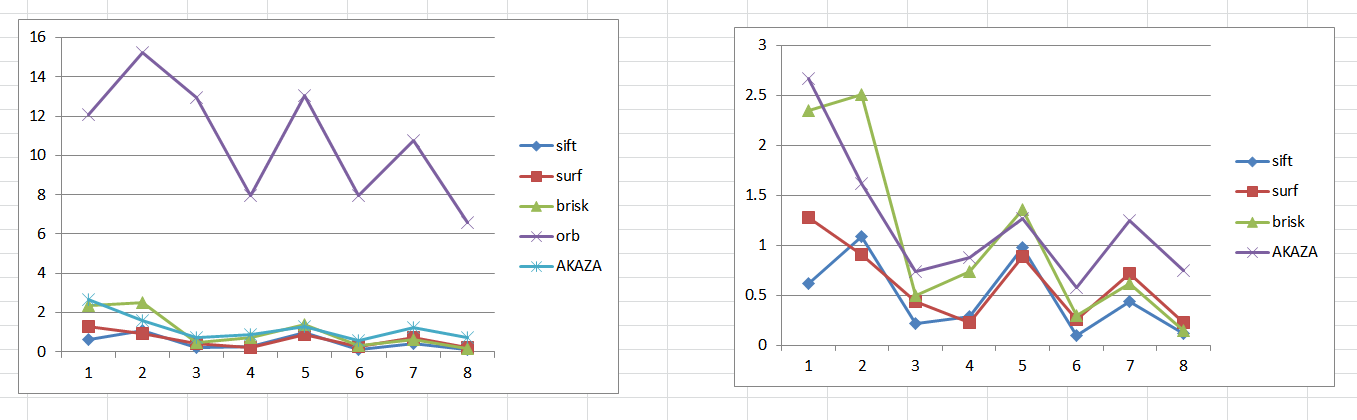
五、结论
那么我们在做大型特征点提取的算法的时候,就需要综合考虑速度、准确率等多种要素;很可能要自己设计新的算法,将这几种典型算法包含其中,扬长避短了。
附:
//遍历dateset,分别对SIFT、SURF、BRISK、ORB、FREAK算法进行运算,得出初步结论
//jsxyhelu 2017年11月3日
#include "stdafx.h"
#include <opencv2/core/utility.hpp>
#include "opencv2/imgproc.hpp"
#include "opencv2/videoio.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/calib3d.hpp"
#include "opencv2/xfeatures2d.hpp"
#include <iostream>
#include <ctype.h>
#include "GOCVHelper.h"
#define DATESET_COUNT 8
#define METHOD_COUNT 5
using namespace cv;
using namespace std;
using namespace xfeatures2d;
void main()
{
string strDateset[DATESET_COUNT];
strDateset[0] = "bark";strDateset[1] = "bikes";strDateset[2] = "boat";strDateset[3] = "graf";strDateset[4] = "leuven";
strDateset[5] = "trees";strDateset[6] = "ubc";strDateset[7] = "wall";
string strMethod[METHOD_COUNT];
strMethod[0] = "SIFT";strMethod[1]="SURF";strMethod[2]="BRISK";strMethod[3]="ORB";strMethod[4]="AKAZE";
////递归读取目录下全部文件
vector<string> files;
Mat descriptors1;
std::vector<KeyPoint> keypoints1;
Mat descriptors2;
std::vector<KeyPoint> keypoints2;
std::vector< DMatch > matches;
std::vector< DMatch > good_matches;
////用于模型验算
int innersize = 0;
Mat img1;
Mat imgn;
int64 t = getTickCount();
std::cout<<"SIFT、SURF、BRISK、ORB、A K A Z E算法测试实验开始"<<endl;
//遍历各种特征点寻找方法
for (int imethod=METHOD_COUNT-1;imethod<METHOD_COUNT;imethod++)
{
string _strMethod = strMethod[imethod];
std::cout<<"开始测试"<<_strMethod<<"方法"<<endl;
//遍历各个路径
for (int idateset = 0;idateset<DATESET_COUNT;idateset++)
{
//获得测试图片绝对地址
string path = "E:/template/dateset/"+strDateset[idateset];
std::cout<<"数据集为"<<strDateset[idateset];
//获得当个数据集中的图片
GO::getFiles(path,files,"r");
std::cout<<" 共"<<files.size()<<"张图片"<<endl;
for (int iimage=1;iimage<files.size();iimage++)
{
//使用img1对比余下的图片,得出结果
img1 = imread(files[0],0);
imgn = imread(files[iimage],0);
//生成特征点算法及其匹配方法
Ptr<Feature2D> extractor;
BFMatcher matcher;
switch (imethod)
{
case 0: //"SIFT"
extractor= SIFT::create();
matcher = BFMatcher(NORM_L2);
break;
case 1: //"SURF"
extractor= SURF::create();
matcher = BFMatcher(NORM_L2);
break;
case 2: //"BRISK"
extractor = BRISK::create();
matcher = BFMatcher(NORM_HAMMING);
break;
case 3: //"ORB"
extractor= ORB::create();
matcher = BFMatcher(NORM_HAMMING);
break;
case 4: //"AKAZE"
extractor= AKAZE::create();
matcher = BFMatcher(NORM_HAMMING);
break;
}
try
{
extractor->detectAndCompute(img1,Mat(),keypoints1,descriptors1);
extractor->detectAndCompute(imgn,Mat(),keypoints2,descriptors2);
matcher.match( descriptors1, descriptors2, matches );
}
catch (CException* e)
{
cout<<" 特征点提取时发生错误 "<<endl;
continue;
}
//对特征点进行粗匹配
double max_dist = 0;
double min_dist = 100;
for( int a = 0; a < matches.size(); a++ )
{
double dist = matches[a].distance;
if( dist < min_dist ) min_dist = dist;
if( dist > max_dist ) max_dist = dist;
}
for( int a = 0; a < matches.size(); a++ )
{
if( matches[a].distance <= max(2*min_dist, 0.02) )
good_matches.push_back( matches[a]);
}
if (good_matches.size()<4)
{
cout<<" 有效特征点数目小于4个,粗匹配失败 "<<endl;
continue;
}
//通过RANSAC方法,对现有的特征点对进行“提纯”
std::vector<Point2f> obj;
std::vector<Point2f> scene;
for( int a = 0; a < (int)good_matches.size(); a++ )
{
//分别将两处的good_matches对应的点对压入向量,只需要压入点的信息就可以
obj.push_back( keypoints1[good_matches[a].queryIdx ].pt );
scene.push_back( keypoints2[good_matches[a].trainIdx ].pt );
}
//计算单应矩阵(在calib3d中)
Mat H ;
try
{
H = findHomography( obj, scene, CV_RANSAC );
}
catch (CException* e)
{
cout<<" findHomography失败 "<<endl;
continue;
}
if (H.rows < 3)
{
cout<<" findHomography失败 "<<endl;
continue;
}
//计算内点数目
Mat matObj;
Mat matScene;
CvMat* pcvMat = &(CvMat)H;
const double* Hmodel = pcvMat->data.db;
double Htmp = Hmodel[6];
for( int isize = 0; isize < obj.size(); isize++ )
{
double ww = 1./(Hmodel[6]*obj[isize].x + Hmodel[7]*obj[isize].y + 1.);
double dx = (Hmodel[0]*obj[isize].x + Hmodel[1]*obj[isize].y + Hmodel[2])*ww - scene[isize].x;
double dy = (Hmodel[3]*obj[isize].x + Hmodel[4]*obj[isize].y + Hmodel[5])*ww - scene[isize].y;
float err = (float)(dx*dx + dy*dy); //3个像素之内认为是同一个点
if (err< 9)
{
innersize = innersize+1;
}
}
//打印内点占全部特征点的比率
float ff = (float)innersize / (float)good_matches.size();
cout<<ff;
//打印时间
cout <<" "<<((getTickCount() - t) / getTickFrequency())<< endl;
t = getTickCount();
//如果效果较好,则打印出来
Mat matTmp;
if (ff == 1.0)
{
drawMatches(img1,keypoints1,imgn,keypoints2,good_matches,matTmp);
char charJ[255];sprintf_s(charJ,"_%d.jpg",iimage);
string strResult = "E:/template/result/"+strDateset[idateset]+_strMethod+charJ;
imwrite(strResult,matTmp);
}
ff = 0;
innersize = 0;
matches.clear();
good_matches.clear();
}
files.clear();
}
}
getchar();
waitKey();
return;
};
目前方向:图像拼接融合、图像识别 联系方式:jsxyhelu@foxmail.com




