标题中的英文首字母大写比较规范,但在python实际使用中均为小写。
2018年7月27日笔记
学习内容:
1.从文件中读取数据
2.将数据写入文件
3.利用数学和统计分析函数完成实际统计分析应用
4.掌握数组相关的常用函数
1.文本文件读写
1.1使用numpy.savetxt方法写入文本文件
numpy.savetxt方法需要2个参数:第1个参数是文件名,数据类型为字符串str;
第2个参数是被写入文件的nda数据,数据类型为ndarray对象。
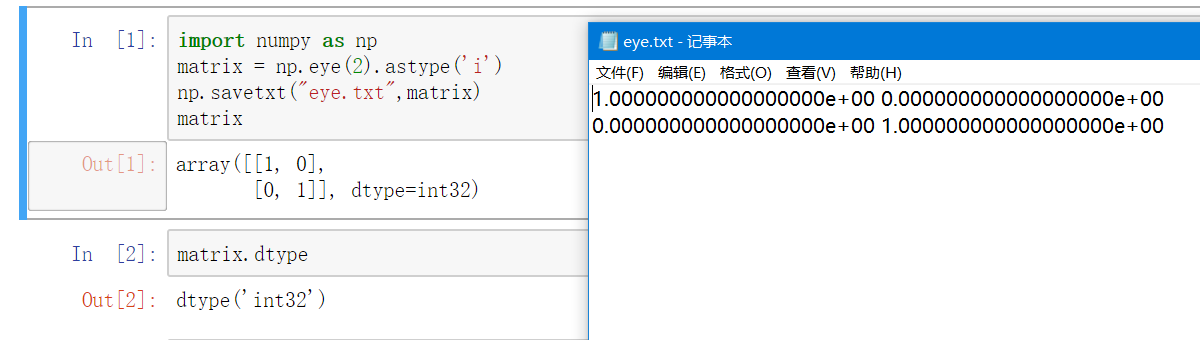
从上图可以看出,ndarray对象中的元素数据类型 原本为int,但写入文件时 转变为float。
1.2使用numpy.loadtxt方法读取文本文件
numpy.loadtxt方法需要1个参数:参数使文件名,数据类型为字符串str。
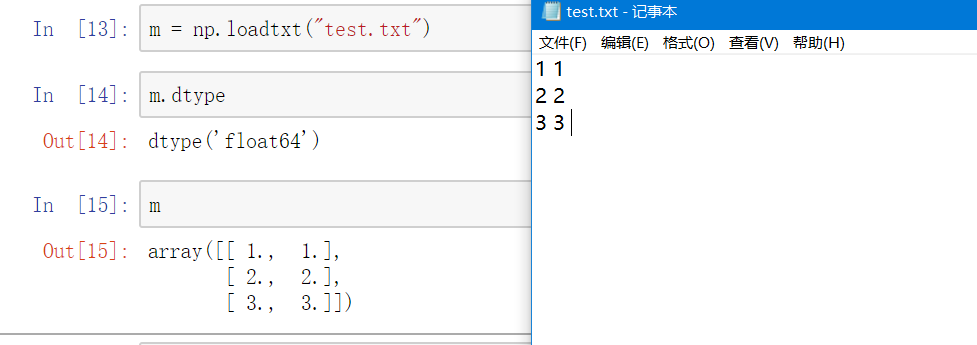
从上图可以看出,使用numpy.loadtxt方法载入的数据赋值给m变量,m变量的数据类型为ndarray对象。
原本test.txt文本中数据的数据类型为int,但利用numpy.loadtxt方法后数据类型为float64。
2.使用numpy.loadtxt方法读取CSV文件
CSV文件格式概念:CSV格式是一种常见的文件格式。通常,数据库的转存文件就是CSV格式的,文件中的各个字段对应于数据库中的列。而且Mircosoft Excel也可以处理CSV文件
下面练习需要用到的data.csv文件下载链接: https://pan.baidu.com/s/1bo-PLzYICmF6Hc87tMG1uA 密码: spwr
文件下载后打开如下图所示:
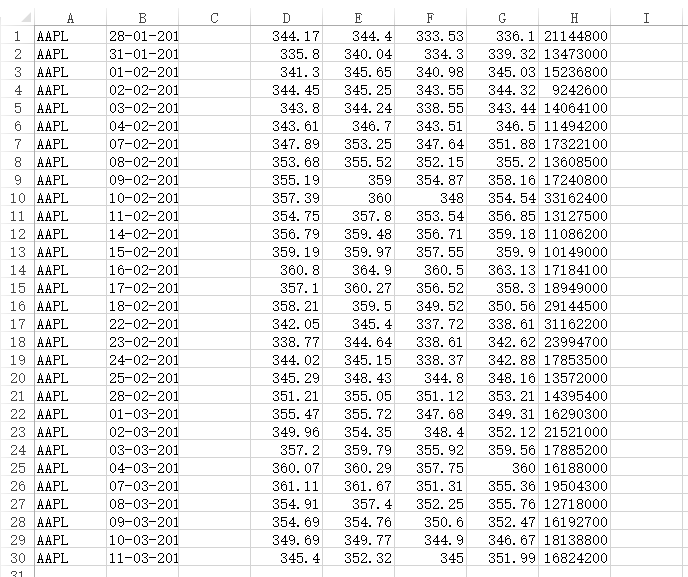
第4-8列,即EXCEL表格中的D-H列,分别为股票的开盘价,最高价,最低价,收盘价,成交量。
import numpy as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (6,7),
unpack = True
)
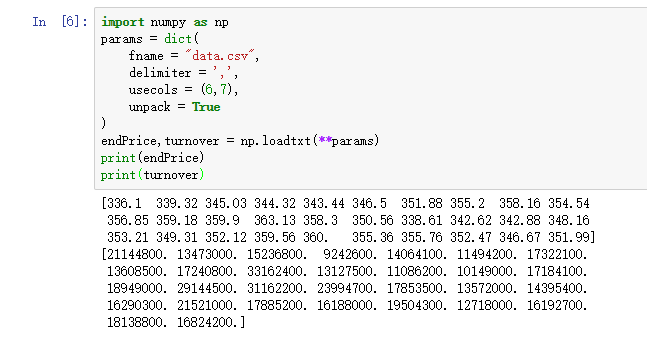
endPrice,turnover = np.loadtxt(**params)
print(endPrice)
print(turnover)
numpy.loadtxt需要传入4个关键字参数:
1.fname是文件名,数据类型为字符串str;
2.delimiter是分隔符,数据类型为字符串str;
3.usecols是读取的列数,数据类型为元组tuple,其中元素个数有多少个,则选出多少列;
4.unpack是是否解包,数据类型为布尔bool。
上面一段代码的运行结果如下图所示:
3.基于Numpy的股价统计分析应用
在第2节的基础上,对股价进行统计分析
3.1 计算成交量加权平均价格
概念:成交量加权平均价格,英文名VWAP(Volume-Weighted Average Price,成交量加权平均价格)是一个非常重要的经济学量,代表着金融资产的“平均”价格。
某个价格的成交量越大,该价格所占的权重就越大。VWAP就是以成交量为权重计算出来的加权平均值。
import numpy as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (6,7),
unpack = True
)
endPrice,turnover = np.loadtxt(**params)
print(np.average(endPrice))
print(np.average(endPrice,weights=turnover))
上面一段代码的运行结果如下:
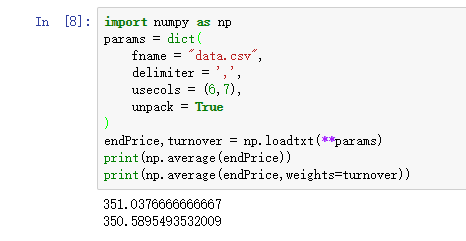
从上面的运行结果可以看出:
1.对于numpy.average方法,是否加权重weights,结果会有区别。
2.如果numpy.average方法没有weights参数,与numpy.mean方法效果相同。
3.经过作者实验,np.mean(endPrice)和endPrice.mean()效果相同。
3.2 计算最大值和最小值
使用方法:numpy.max(highPrice)和highPrice.max()相同
numpy.min(lowPrice)和lowPrice.min()相同
计算股价近期最高价的最大值和最低价的最小值
最高价位于excel中的第4列,最低价位于excel中的第5列,所以usecols=(4,5)
import numpy as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (4,5),
unpack = True
)
highPrice,lowPrice = np.loadtxt(**params)
print("max=",highPrice.max())
print("min=",lowPrice.min())
上面一段代码的运行结果如下:
max= 364.9
min= 333.53
3.3 计算极差
使用方法:numpy.ptp(highPrice)和highPrice.ptp()相同
计算股价近期最高价的最大值和最小值的差值
计算股价近期最低价的最大值和最小值的差值
import numpy as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (4,5),
unpack = True
)
highPrice,lowPrice = np.loadtxt(**params)
print("max - min of high price:", highPrice.ptp())
print("max - min of low price:", lowPrice.ptp())
上面一段代码的运行结果如下:
max - min of high price: 24.859999999999957
max - min of low price: 26.970000000000027
3.4计算中位数
使用方法:不能使用endPrice.median(),可以使用numpy.median(endPrice)
计算收盘价的中位数
import numpy as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = 6,
)
endprice = np.loadtxt(**params)
print("median =",np.median(endPrice))
上面一段代码的运行结果如下:
median = 352.055
3.5计算方差
使用方法:endPrice.var()和numpy.var(endPrice)效果相同
计算收盘价的方差
import numpy as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = 6,
)
endprice = np.loadtxt(**params)
print("variance =",np.var(endPrice))
print("variance =",endPrice.var())
上面一段代码的运行结果如下:
variance = 50.126517888888884
variance = 50.126517888888884
3.6计算股票收益率、年波动率及月波动率
在投资学中,波动率是对价格变动的一种度量,历史波动率可以根据历史价格数据计算得出。计算历史波动率时,需要用到对数收益率。
年波动率等于对数收益率的标准差除以其均值,再乘以交易日的平方根,通常交易日取252天。
月波动率等于对数收益率的标准差除以其均值,再乘以交易月的平方根。通常交易月取12月。
下面代码中求得对数收益率赋值给logReturns
import numpy as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = 6,
)
endprice = np.loadtxt(**params)
logReturns = np.diff(np.log(endPrice))
annual_volatility = logReturns.std()/logReturns.mean()*np.sqrt(252)
monthly_volatility = logReturn.std()/logReturns.mean()*np.sqrt(12)
print("年波动率",annual_volatility)
print("月波动率",monthly_volatility)
上面一段代码的运行结果如下:
年波动率 129.27478991115134
月波动率 28.210071915112593
4.其他常用函数
4.1 计算阶乘
import numpy as np
a = np.arange(1,8)
print("a is:", a)
print("a.prod is:", a.prod())
print("a.cumprod is:", a.cumprod())
上面一段代码的运行结果如下:
a is: [1 2 3 4 5 6 7]
a.prod is: 5040
a.cumprod is: [ 1 2 6 24 120 720 5040]
4.2 修剪
利用ndarray对象的clip方法,将所有比给定值还大的元素全部设为给定的最大值,将所有比给定值还小的元素全部设定为给定的最小值。
import numpy as np
a = np.arange(1,20)
print("a is:",a)
print("a.clip(5,15) is:",a.clip(5,15))
上面一段代码的运行结果如下:
a is: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
a.clip(5,15) is: [ 5 5 5 5 5 6 7 8 9 10 11 12 13 14 15 15 15 15 15]
4.3 压缩
选出ndarray对象中满足条件的数
import numpy as np
a = np.arange(1,20)
print("a is:",a)
print("a>10 is:", a>10)
print("a[a>10] is:",a[a>10])
print("a.compress(a>10 is:", a.compress(a>10))
上面一段代码的运行结果如下:
a is: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
a>10 is: [False False False False False False False False False False True True
True True True True True True True]
a[a>10] is: [11 12 13 14 15 16 17 18 19]
a.compress(a>10 is: [11 12 13 14 15 16 17 18 19]
从运行结果可以看出a[a>10]和a.compress(a>10)效果相同,a>10是元素为布尔bool的ndarray对象。
练习
练习1.股票统计分析
文件中的数据为给定时间范围内某股票的数据,现要求:
1.获取该时间范围内交易日周一、周二、周三、周四、周五分别对应的平均收盘价
2.平均收盘价最低,最高分别为星期几
import numpy as np
import datetime
def dateStr2num(s):
s = s.decode("utf-8")
return datetime.datetime.strptime(s, "%d-%m-%Y").weekday()
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (1,6),
converters = {1:dateStr2num},
unpack = True
)
date, closePrice = np.loadtxt(**params)
average = []
for i in range(5):
average.append(closePrice[date==i].mean())
print("星期%d的平均收盘价为:" %(i+1), average[i])
print("\n平均收盘价最低是星期%d" %(np.argmin(average)+1))
print("平均收盘价最高是星期%d" %(np.argmax(average)+1))
上面一段代码的运行结果如下:
星期1的平均收盘价为: 351.7900000000001
星期2的平均收盘价为: 350.63500000000005
星期3的平均收盘价为: 352.1366666666666
星期4的平均收盘价为: 350.8983333333333
星期5的平均收盘价为: 350.0228571428571平均收盘价最低是星期5
平均收盘价最高是星期3
练习2. offer的选择
小明接收到两家公司的offer,纠结该去哪家?
| A公司 | A公司 | B公司 | B公司 | |
|---|---|---|---|---|
| 职位 | 薪资 | 人数 | 薪资 | 人数 |
| 经理 | 100000 | 1 | 20000 | 1 |
| 主管 | 10000 | 15 | 11000 | 20 |
| 普通员工 | 7500 | 20 | 9000 | 15 |
companyA = np.array([100000] + [10000] * 15 + [7500] * 20)
companyB = np.array([20000] + [11000] * 20 + [9000] * 15)
print("带权平均值对比:")
print("A公司:%.2f" %companyA.mean(),"B公司:%.2f" %companyB.mean())
print("中位数对比:")
print("A公司:",np.median(companyA),"B公司:",np.median(companyB))
上面一段代码的运行结果如下:
带权平均值对比:
A公司:11111.11 B公司:10416.67
中位数对比:
A公司: 7500.0 B公司: 11000.0
从上面的分析可以看出,B公司工资的中位数更大。
所以作为一名普通员工,小明应该选择去B公司。


![[深度学习实战]基于PyTorch的深度学习实战(中)[线性回归、numpy矩阵的保存、模型的保存和导入、卷积层、池化层](二)](https://ucc.alicdn.com/pic/developer-ecology/u4n2puyxrj26a_230871bbe1ee46428c2311a4c06971d9.png?x-oss-process=image/resize,h_160,m_lfit)

![[深度学习实战]基于PyTorch的深度学习实战(中)[线性回归、numpy矩阵的保存、模型的保存和导入、卷积层、池化层](一)](https://ucc.alicdn.com/pic/developer-ecology/u4n2puyxrj26a_7141a9e5a75741ad8cc99cc4720add8a.png?x-oss-process=image/resize,h_160,m_lfit)