bs4中文叫做美丽汤第4版,是用Python写的一个HTML/XML的解析器。中文文档链接:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
requests中文叫做请求,是用来发起http请求和接收http相应的库。官方文档链接:
http://docs.python-requests.org/zh_CN/latest/api.html
2018年8月22日笔记
新手学习如何编写爬虫,可以注册1个网易账号,在网易云课堂上学习《Python网络爬虫实战》,链接:http://study.163.com/course/courseMain.htm?courseId=1003285002
0.制定需求
爬取每个运动员的姓名name、位置position、图片链接img_url、性别sex、生日birthday、国家country这6个字段。
该网站未设置反爬策略,网页中的字段为静态信息,容易爬取。
目录页面有姓名name、位置position、图片链接img_url这3个字段;
详情页面有性别sex、生日birthday、国家country这3个字段。
1.观察数据
2018年23岁以下世界赛艇锦标赛链接:http://www.worldrowing.com/events/2018-world-rowing-under-23-championships/u23-mens-eight/
网站页面如下图所示:
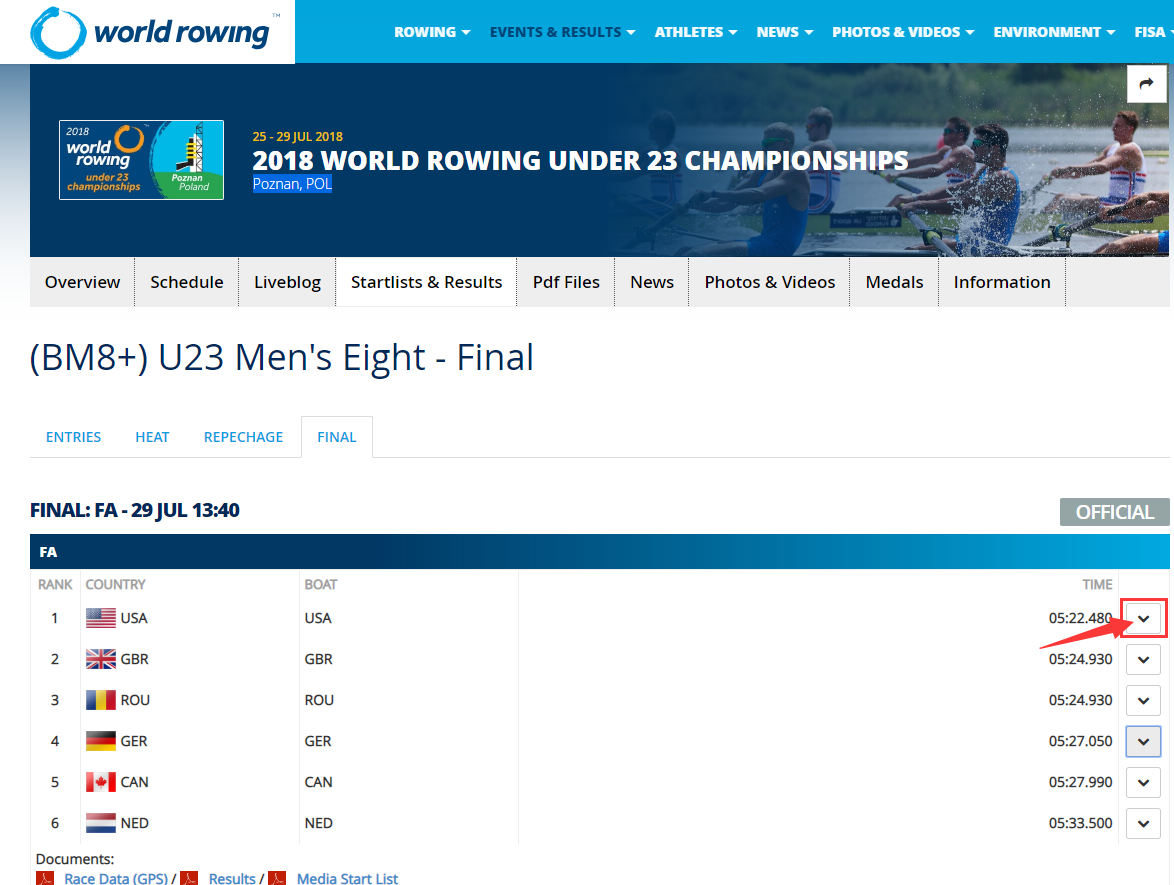
点击上图红色箭头所示位置,会出现运动员列表,如下图所示:
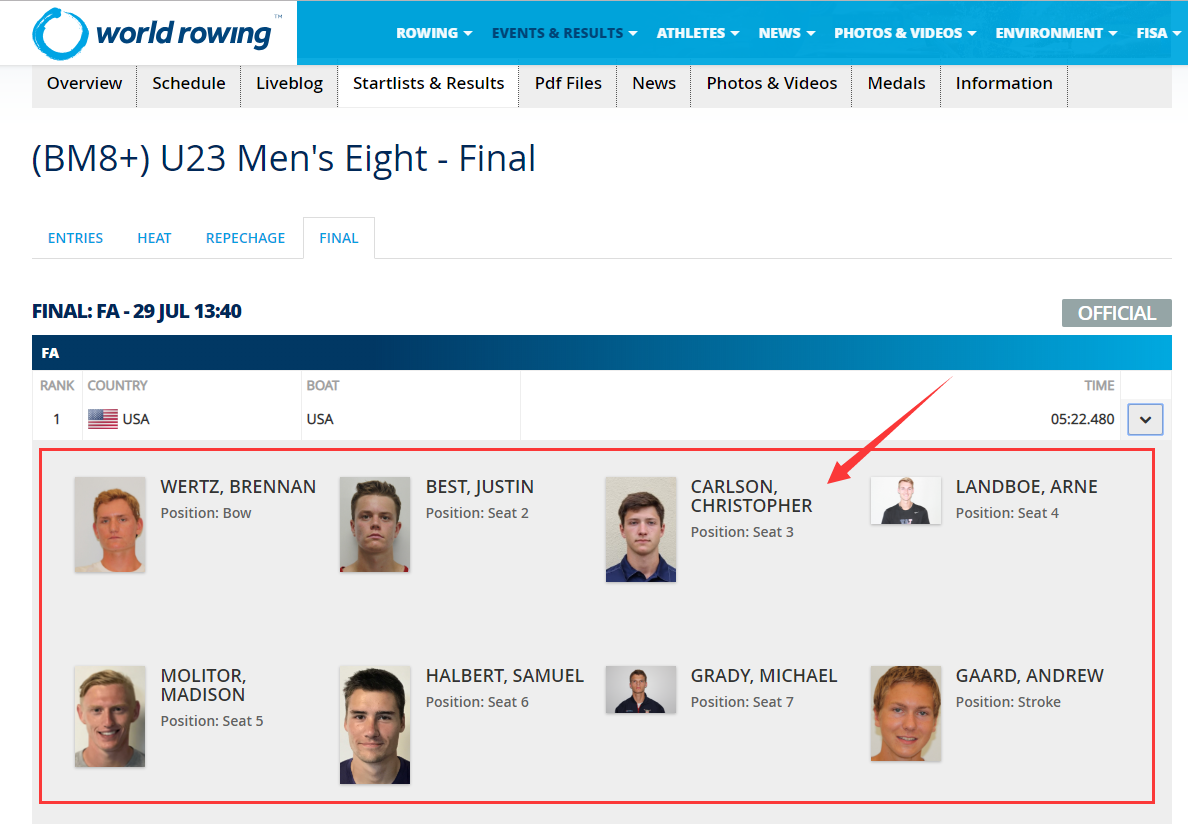
2.查看标签
在chrome浏览器中点击F12键,可以弹出程序员调试工具。
360浏览器使用了一部分的chrome浏览器内核,也可以点击F12键弹出程序员调试工具。
调试工具中有一个按钮可以直接找出网页内容在网页源代码中的位置。
点击下面红色箭头标注的按钮,如下图所示:
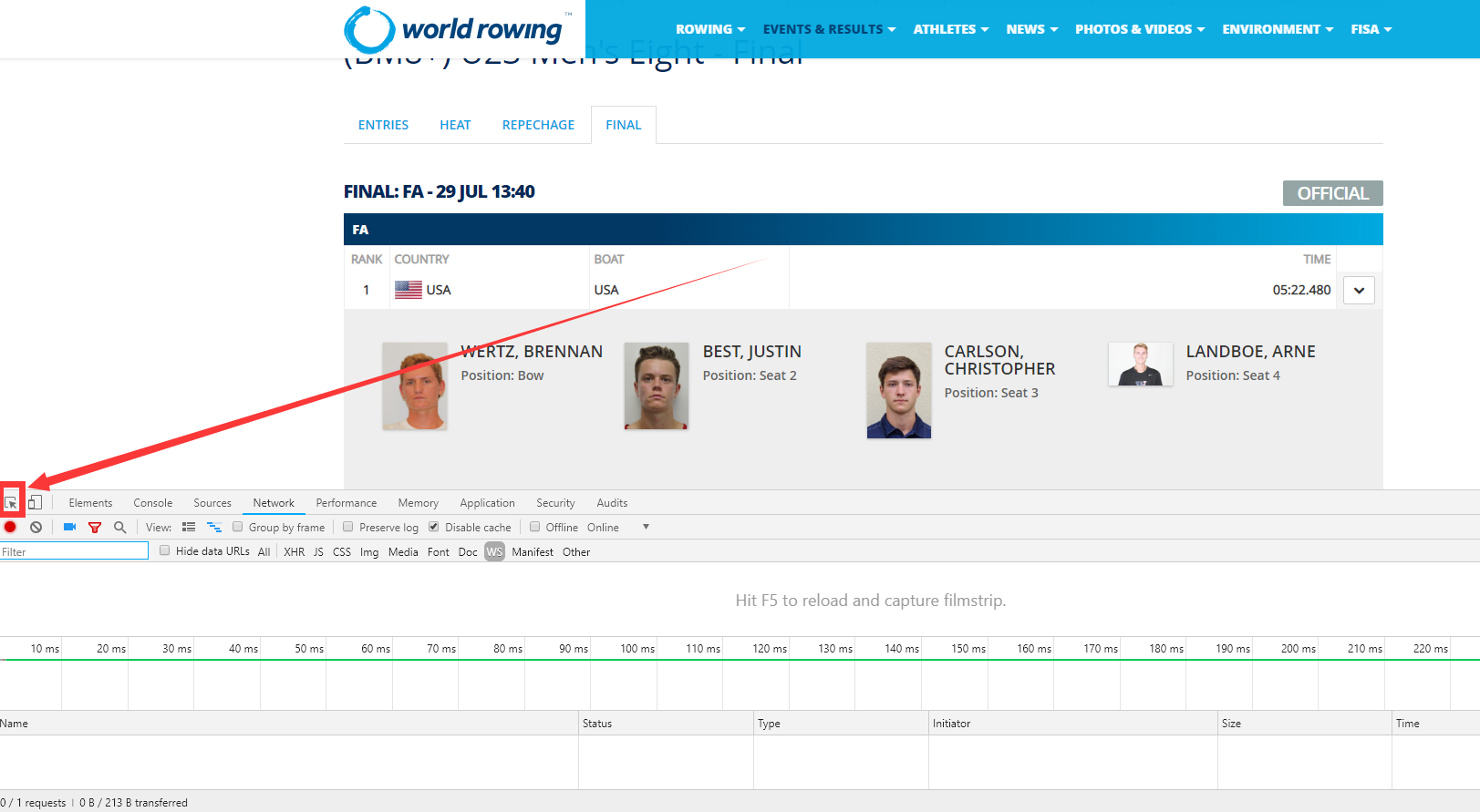
点击上图所示按钮后,再选中下图红色方框所示位置:

此时在程序员调试工具中可以看到已经准确定位 第1位运动员名字在源代码中的位置,如下图所示:
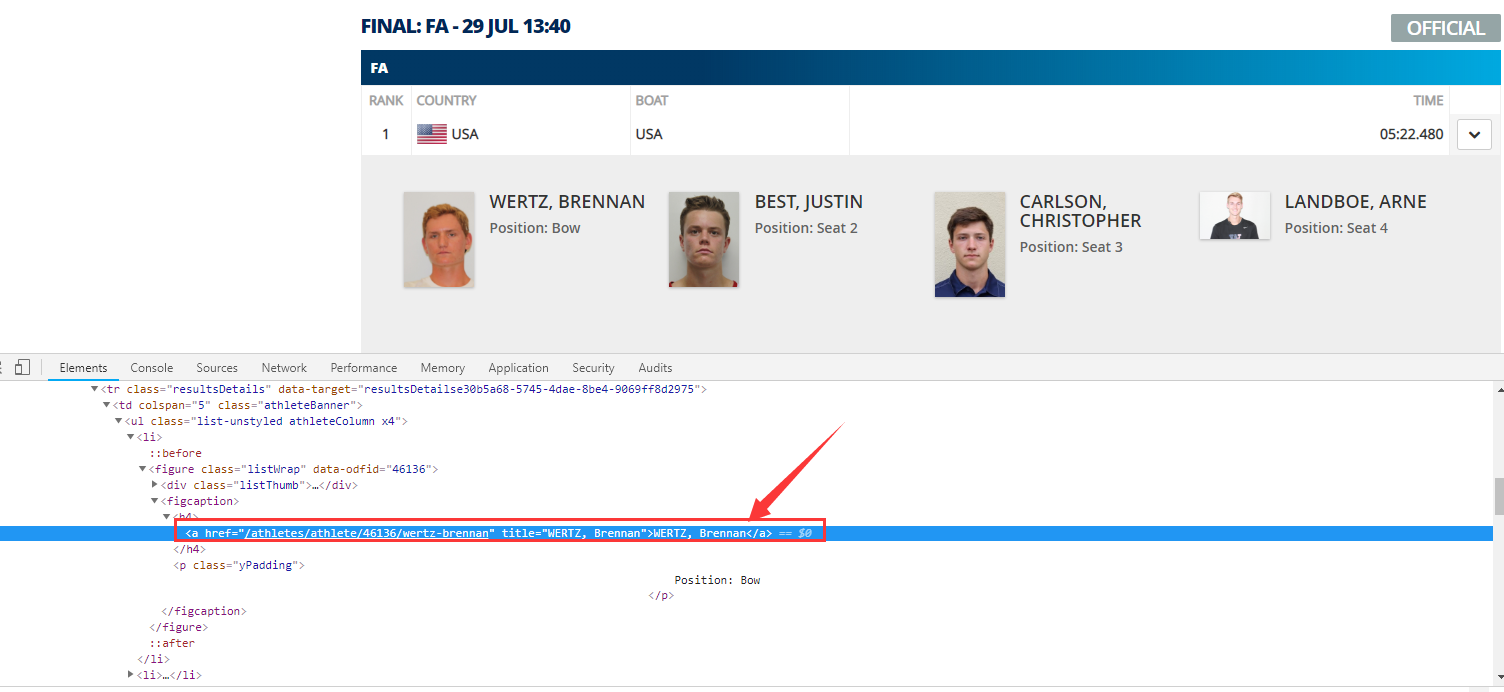
通过观察网页html文件查看 字段对应标签和标签的层次结构,我们就可以开始编写代码实现我们的爬虫。
其他字段的观察方法相同。
3.编写爬虫代码
编写代码的编程环境为jupyter notebook,如何打开jupyter notebook查看此链接:https://www.jianshu.com/p/bb0812a70246
requests库用于发送网页请求,并获得网页响应。
bs4库是BeautifulSoup工具的第4个版本,用于解析网页。
下面2行代码导入2个库,如果不导入则无法使用此库的方法。
第1行代码从bs4库中导入BeautifulSoup方法,取个别名bs,可以少编写代码。
from bs4 import BeautifulSoup as bs
import requests
requests库的get方法是模拟浏览器发送请求,需要1个参数,参数为请求链接,参数的数据类型为字符串。
bs4库的BeautifulSoup方法是实例化对象,需要2个参数。第1个参数为网页源代码,参数的数据类型为字符串;第2个参数为解析网页方法,参数的数据类型为字符串。
response = requests.get('http://www.worldrowing.com/events/2018-world-rowing-under-23-championships/u23-mens-eight/')
soup = bs(response.text, 'html.parser')
从目录页面获取100个运动员的姓名name、位置position、图片链接img_url这3个字段,并打印,代码如下:
因为图片展示效果,取运动员的前5个打印,athlete_list[:5]即选前5个。
athlete_list = soup.select('tr.resultsDetails li')
for athlete in athlete_list[:5]:
name = athlete.select('h4 a')[0].text
position = athlete.select('p.yPadding')[0].text.strip()
img_url = 'http://www.worldrowing.com' + athlete.select('img')[0]['src']
print(name, position, img_url)
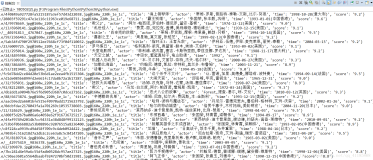
上面一段代码的运行结果如下图所示:

爬取详情页面时,需要使用requests库的get方法重新发起请求,再使用bs4库的方法进行解析。
4.完整代码
第8行代码循环遍历每个运动员。
第9行代码定义变量item为字典,每抓取1个字段信息,则保存为字典的1个键值对。
第19行代码item_list.append(item)将变量item加入列表item_list中。
第21、22行代码将抓取的信息保存为athleteRecord.xlsx文件。
代码如下:
from bs4 import BeautifulSoup as bs
import requests
response = requests.get('http://www.worldrowing.com/events/2018-world-rowing-under-23-championships/u23-mens-eight/')
soup = bs(response.text, 'html.parser')
athlete_list = soup.select('tr.resultsDetails li')
item_list = []
for athlete in athlete_list:
item = {}
item['name'] = athlete.select('h4 a')[0].text
item['position'] = athlete.select('p.yPadding')[0].text.strip()
item['img_url'] = 'http://www.worldrowing.com' + athlete.select('img')[0]['src']
detail_url = 'http://www.worldrowing.com' + athlete.select('h4 a')[0]['href']
response = requests.get(detail_url)
soup = bs(response.text, 'html.parser')
item['sex'] = soup.select('div.dd')[0].text
item['birthdday'] = soup.select('div.dd')[1].text
item['country'] = soup.select('h1.athleteInfoTitle span')[0].text
item_list.append(item)
import pandas as pd
df = pd.DataFrame(item_list, columns=item_list[0].keys())
df.to_excel('athleteRecord.xlsx')