免费开通大数据服务:https://www.aliyun.com/product/odps
背景
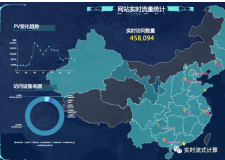
每年的双十一除了“折扣”,全世界(特别是阿里人)都关注的另一个焦点是面向媒体直播的“实时大屏”(如下图所示)。包括总成交量在内的各项指标,通过数字维度展现了双十一狂欢节这一是买家,卖家及物流小二一起创造的奇迹!

双十一媒体直播大屏
这一大屏背后需要实时处理海量的庞大电商系统各个模块产生的交易日志,例如双十一当前产生的日志量达到了3.7PB,而每秒处理的峰值更是达到了近1亿事件!
如此大规模、高吞吐和低延时计算,带来一系列世界级的技术挑战,包括:
1. 实时编程:流式的数据处理给业务逻辑的表达和推理带来了很多的复杂性。特别面对不断变化的业务需求,如何帮助用户快速地编写和验证实时计算逻辑是至关重要的。
2. 低延时:实时计算强调计算延时和结果的时效性。例如实时大屏对计算延时特别敏感,每年的双十一都超越前一年更早地达到相同的成交量,系统需要在秒级甚至毫秒级反应出每一笔交易。即使在流量高峰时(双十一晚0:00点)也需要保证延时!
3. 集群利用率:为提高资源利用率,我们将不用业务的实时处理逻辑共享一个集群。这样的共享也带来性能隔离的问题,即如何让同一台物理机上的不同逻辑任务不互相干扰。这也是大部分开源框架忽略的重要问题。
4. 严格容错及数据一致性:随着应对高吞吐而不断扩大的集群规模,各种软硬件故障都难以避免。如何保证实时计算在任何故障下都能产生准确、一致的计算结果,不遗漏、重复事件输出,也不引起内部状态的偏差,是另一个重大挑战。
5. 多样化场景支持:随着实时决策对业务的价值越来越多,系统还需要支持越来越复杂和多样化的场景,如在线机器学习、结合图计算实现的动态关系网络分析等等。
下文介绍StreamCompute的重要技术创新,简要描述它们如何帮助应对以上技术挑战。
SQL与增量计算——复用熟悉的离线思维,自动实现增量(流式)计算!
为了简化用户编程,特别是利用原有的离线计算作业快速实现实时计算,StreamCompute允许通过高层描述性语言,如用户熟悉的SQL来编写流计算作业。例如下面的例子,通过简单几行SQL代码就可以实现过滤、维表关联等业务逻辑。

在执行时,由于数据是以流式进入系统的,用户的SQL就像数据库视图一样,被自动增量更新,并以一定的频率输出结果,供下游计算和展示。
这一独特的编程设计,不仅帮助用户借助熟悉的离线处理思维表达实时计算逻辑,也因为同样的程序可以在离线系统运行,使得结果的对比变得易如反掌。
高性能优化引擎——实现低延时计算!
用户的SQL脚本经过编译优化,生成数据流图,然后运行于StreamCompute的分布式引擎之上。相比开源数据流引擎,StreamCompute引擎在“阿里巴巴规模”下,面对真实复杂的业务场景做了很多优化。包括自适应的消息打包、自定义序列化、数据行+列压缩、先进的内存管理、和内部缓存队列和线程模型,以及基于下游向上游“反向”传递压力的流控策略等。

图:StreamCompute优化执行流和运行时模块
经过以上一系列的优化,StreamCompute相比去年提升了6倍左右的吞吐性能。下图显示了StreamCompute相比开源系统的性能优势。在面对今年双十一3倍于去年的峰值情况下,表现非常稳健。

图:开源框架性能对比,通过“窗口WordCount(6组参数)”基准测试获取
灵活的资源调度
StreamCompute面对阿里巴巴集团众多业务场景,将不同业务放置于大规模(几千台服务器组成的)共享集群中,以提高资源利用率。另一方面也随之带来了“多租户”环境下的作业资源隔离问题,它直接影响资源的有效利用和作业的计算性能。
经过多年的积累,StreamCompute支持CPU、内存、网络和磁盘I/O等多维度资源的隔离。例如,对于CPU的隔离支持灵活的min-max策略,既保证了每个作业最基本的资源需求,也使的空闲的资源被最大限度利用。

图:作业维度的CPU资源min-max共享模型
在此基础上,StreamCompute的资源调度还支持一定比例的“超卖”、作业优先级调度、动态负载均衡和微作业共享单一物理核等多种机制。对于资源消耗特别大的作业还支持动态按需分配(即资源的弹性分配)。在满足复杂的运维要求和实时计算连续性的同时,实现了高效的资源利用和性能隔离。
容错与状态管理
流计算需要连续处理可能无界的输入和连续产生输出。在长时间运行中,大规模计算集群的各种软件或硬件故障难以避免。由此对于计算和中间结果(如内存状态)的容错就至关重要。为了做到精确的容错和故障恢复,保证结果的准确性。StreamCompute支持多种灵活的容错策略,以在不同计算特性下,权衡容错资源消耗和恢复性能。如基于输入的重新计算、状态检查点(checkpoint),甚至是多副本的状态和计算容错等。
特别是自动的分布式增量检查点功能,系统自动利用内存、本地磁盘和远程存储构成的多级存储,在不影响流计算延时的情况下异步实现了计算状态的持久化。当有故障发生时,保存的状态可以被快速加载。这一切对用户都是无感知的。

图:自动利用多级存储的流计算状态管理
开放可编程API(兼容Apache Beam)
除了SQL这样高层的描述语言和用户自定义逻辑(UDF),StreamCompute还支持Apache Beam API,以提供更为灵活的实时逻辑编程。Beam是一个统一开放的大数据应用编程接口,可以同时描述离线和在线逻辑,最早由Google提出。Beam提供了功能丰富的编程接口,能有效的处理有界、无界、乱序的数据流输入。 下面显示了通过Beam实现的流式WordCount的例子:
1.指定Runner(底层计算引擎)创建一个Pipeline。
2.使用Source在Pipeline上生成一个PCollection,输入数据。
3.对PCollection应用Transforms操作,比如wordCount中的count操作。
4.对最后的PCollection应用Sink,输出结果到外部存储中。
5.Run Pipeline到底层的计算引擎中。
使用Beam实现WordCount代码样例
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}
借助Beam,用户可以利用高性能的StreamCompute引擎,定制面向特定领域的系统交互接口。同时,StreamCompute今后也将兼容更多生态(如Spark Streaming和Flink Streaming API)。
可视化集成开发平台和自动化运维
StreamCompute还提供了“一站式”的集成开发环境——贝叶斯(Bayes,https://data.aliyun.com/product/sc)和自动化运维平台——特斯拉(Tesla当前仅服务阿里集团内部,未来逐步开放对外服务)。通过它们,用户可以方便地管理流计算应用的生命周期,包括编程、调试、监控运维,极大地降低了流计算系统的使用门槛。

图:贝叶斯集成开发环境
双十一的宝贵工程经验!
为保障系统在双十一平稳支撑业务,在以上功能基础上,我们还总结了完整的全链路保障方法:
· 主备双链路容灾:利用StreamCompute对多副本执行的支持,面向双十一重点媒体大屏等实时业务,实现了跨机房的多链路副本。哪怕是整个机房的故障,都能在秒级自动切换到另一副本上执行,保障了双十一系统高可用。
· 实时全链路监控:我们从数据采集、读取、消费、入库各个环节都增加延时指标的埋点,可以清晰地看到整条链路各个阶段的延时,快速分析哪个组件性能瓶颈。另外,针对作业本身运行情况,比如输入吞吐、流量、CPU和内存消耗,都做了实时分析和展示的系统,能在秒级发现作业的异常。
· 运维诊断工具:为应对各种应急响应,我们做了一套完整的运维诊断工具用于发现集群热点机器、热点作业。在Tesla页面上能快速找到集群的热点机器,通过“机器分析”工具查看这台机器上实时跑的任务,并且能定位到相应的业务和用户。通过“作业分析”工具能自动诊断异常,结合作业的优先级,实现了一键负载均衡、启停、续跑等运维操作。
通过这些保障设施,双十一当天,即使在发生交换机硬件故障的情况下,面向全球直播的媒体大屏业务并没有受到任何影响!
总结
拥有这些和其它诸多能力,StreamCompute已经具备了相当完善的实时计算能力,也提供了“一站式”的解决方案。今年双十一当天,StreamCompute处理了3.7PB数据,处理峰值达到了1亿事件每秒,平均处理延迟在毫秒级!除了双十一媒体大屏,StreamCompute还支撑着阿里巴巴集团内外众多实时业务,包括数据运营、广告营销、搜索个性化、智能客服、物流调度、支付宝、聚划算等。