这篇文章是基于我开发读写分离中间件和数据库智能运维平台时的经验总结而成。网上对数据库连接系统分析的文章非常少,甚至几乎没有。这篇文章很多内容都参杂了我个人的见解,不一定全,但是每一个知识点都是我验证过的。
JDBC
JDBC (Java Database Connectivity) API,即Java数据库编程接口,是一组标准的Java语言中的接口和类,使用这些接口和类,Java客户端程序可以访问各种不同类型的数据库。比如建立数据库连接、执行SQL语句进行数据的存取操作。JDBC是jdk中关于数据库操作的接口定义,在rt.jar包中。
Oracle、Mysql等数据库产商自行实现JDBC,也就是我们所说的数据库驱动,Oracle是oracle.jdbc.driver.OracleDriver,Mysql是com.mysql.jdbc.Driver
JDBC API提供以下接口和类
- DriverManager:此类管理数据库驱动程序列表。 使用通信子协议将来自java应用程序的连接请求与适当的数据库驱动程序进行匹配。在JDBC下识别某个子协议的第一个驱动程序将用于建立数据库连接。
- Driver:此接口处理与数据库服务器的通信。我们很少会直接与Driver对象进行交互。 但会使用DriverManager对象来管理这种类型的对象。 它还提取与使用Driver对象相关的信息。
- Connection:此接口具有用于联系数据库的所有方法。 连接(Connection)对象表示通信上下文,即,与数据库的所有通信仅通过连接对象。
- Statement:使用从此接口创建的对象将SQL语句提交到数据库。 除了执行存储过程之外,一些派生接口还接受参数。
- ResultSet:在使用Statement对象执行SQL查询后,这些对象保存从数据库检索的数据。 它作为一个迭代器并可移动ResultSet对象查询的数据。
- SQLException:此类处理数据库应用程序中发生的任何错误。
一次数据库请求的步骤
//0.调用Class.forName()方法加载驱动程序
Class.forName("com.mysql.jdbc.Driver");
//1.getConnection()方法,连接MySQL数据库!!
Connection con = DriverManager.getConnection(url,user,password);
//2.创建statement类对象,用来执行SQL语句!!
//1)执行静态SQL语句。通常通过Statement实例实现。
//2)执行动态SQL语句。通常通过PreparedStatement实例实现。
//3)执行数据库存储过程。通常通过CallableStatement实例实现。
Statement statement = con.createStatement();
PreparedStatement pst = con.prepareStatement(sql);
//3.执行sql获取的结果集!!
ResultSet rs = statement.executeQuery(sql);
ResultSet rs = psmt.execute();
关于Class.forName("com.mysql.jdbc.Driver")能够加载驱动,原因在于Drive的静态方法,在类加载JVM时,已经将Driver注册到DriverManager中了。
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
//
// Register ourselves with the DriverManager
//
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
}
与JDBC相关的jar包分析
以我们公司项目开发使用的框架为例,我们使用mybatis作为ORM框架,druid作为数据库连接池实现。数据连接涉及以下5个jar包,其中mybatis-spring.jar是和mybatis.jar配套使用,可以理解为4种类型的jar包,各jar包的业务域如下图:
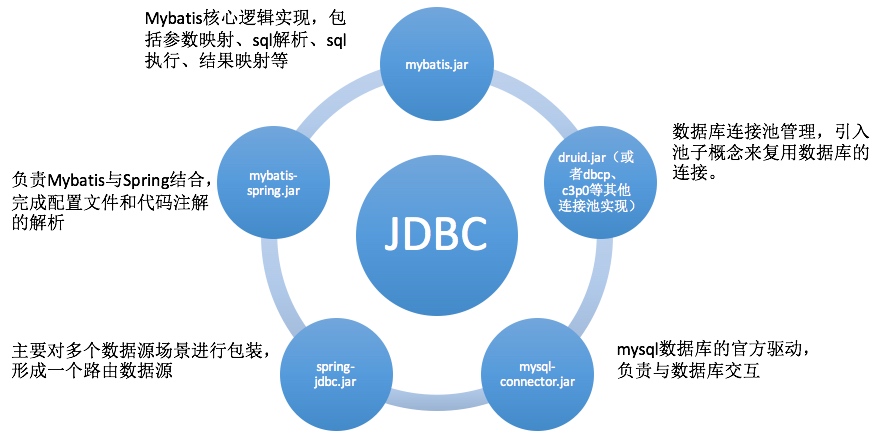
这几个jar之间的逻辑层次关系如下图总结:
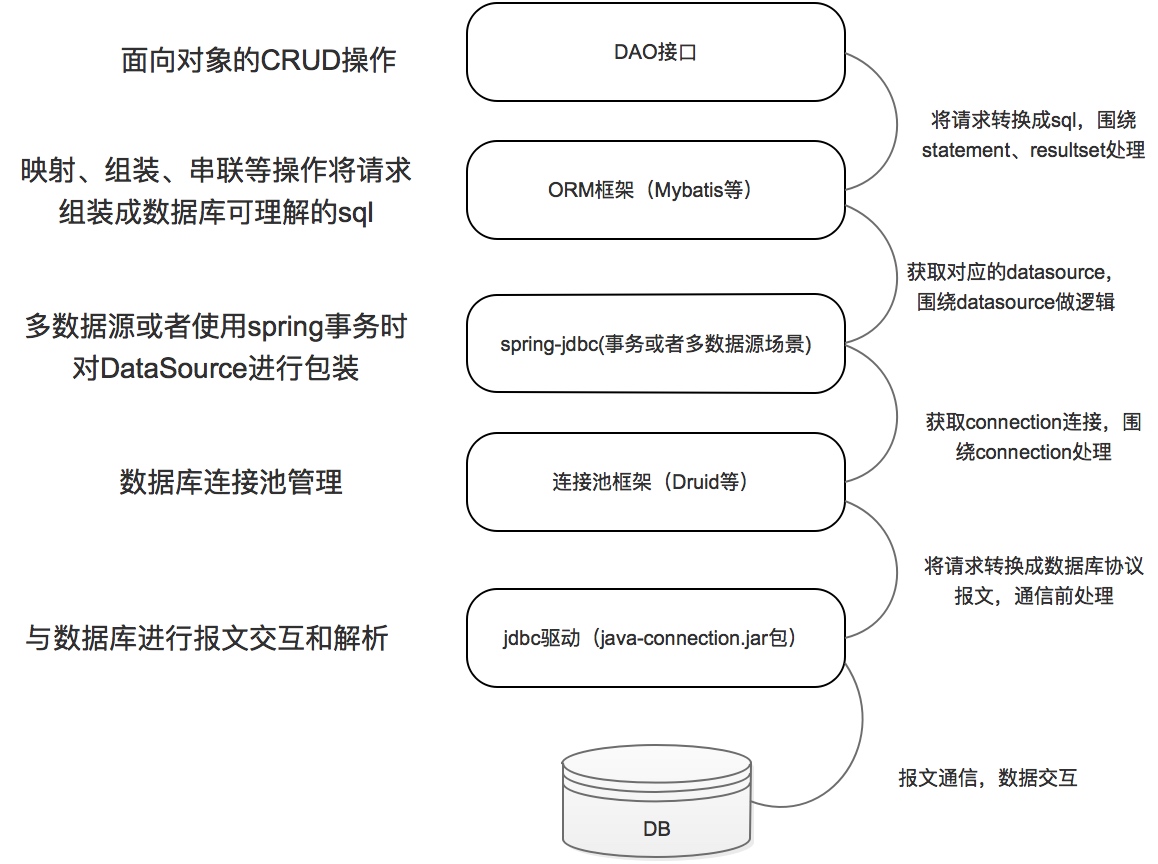
java应用程序要完成数据库的读写,除了最底层的jdbc驱动是必须依赖的,其他层的jar包都是非必需的。
druid是为了复用数据库连接(底层连接的建立是非常消耗时间的)而存在的,spring-jdbc当然可以不依赖druid或类似的线程池实现jar包,而直接实现DataSource接口,直接调用jdbc驱动来完成数据库操作。spring-jdbc.jar中的DriverManagerDataSource类就是为这种场景而存在的。通过下面的配置而绕过druid等数据源连接池的DataSource实现。
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName">
<value>${jdbc.driverClassName}</value>
</property>
<property name="url"><value>${jdbc.url}</value></property>
<property name="username"><value>${jdbc.username}</value></property>
<property name="password"><value>${jdbc.password}</value></property>
</bean>
Spring-jdbc.jar的业务域是围绕数据源DataSource而展开的。主要包括数据源事务管理(DataSourceTransactionManager和面向用户使用的TransactionTemplate),数据源实现(面向多数据源的抽象实现AbstractRoutingDataSource和简单实现DataSource接口的DriverManagerDataSource),面向CRUD接口的数据库操作模版类JdbcTemplate(JdbcTemplate类封装了jdbc操作,当我们不使用ORM框架时,我们可以直接使用JdbcTemplate的方法来实现数据库操作,所以JdbcTemplate一定层度上可以替代ORM框架)。
ORM框架也不是必须的,上面已经说过JdbcTemplate就可以替代ORM直接对接用户的CRUD请求。甚至spring-jdbc也省了,直接按照上面介绍的一次数据库请求(这样就无法实现java面向对象编程的思想)。
Mybatis架构设计分析
Mybatis从功能模块上可以分成以下3层:
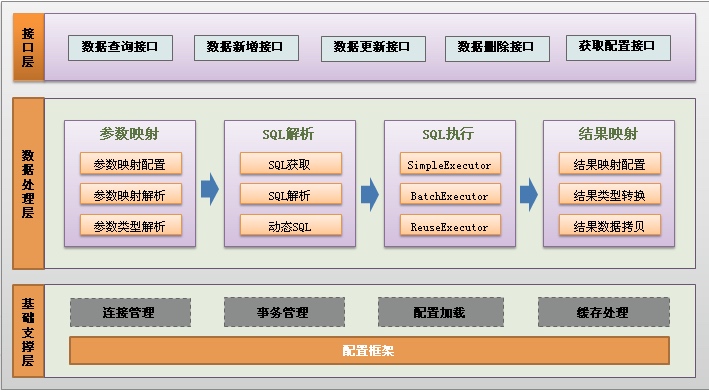
功能架构讲解:
我们把Mybatis的功能架构分为三层:
(1)API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵数据库。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理。
(2)数据处理层:负责具体的SQL查找、SQL解析、SQL执行和执行结果映射处理等。它主要的目的是根据调用的请求完成一次数据库操作。
(3)基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的支撑。
通过以下几个Mybatis核心类可以看出Mybatis的大致设计,通过实现InitializingBean的afterPropertiesSet方法在类初始化时,将xml配置文件中数据源配置、Domain对象位置、sql文件位置等信息解析成sqlSessionFactoryBean中的属性,供后续做参数处理、sql解析、结果映射提供参数。
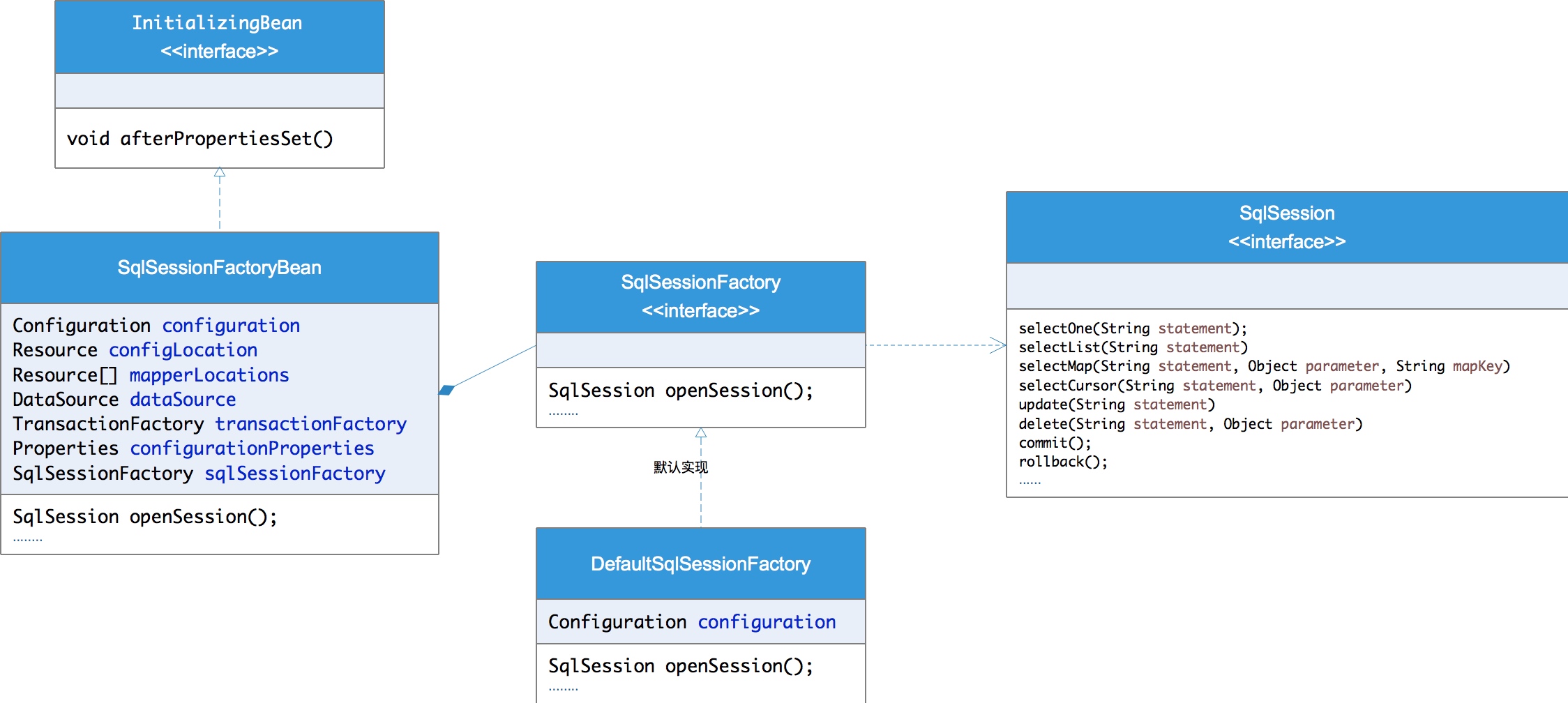
总体流程如下:
(1)加载配置并初始化
触发条件:加载配置文件
配置来源于两个地方,一处是配置文件,一处是Java代码的注解,将SQL的配置信息加载成为一个个MappedStatement对象(包括了传入参数映射配置、执行的SQL语句、结果映射配置),存储在内存中。
(2)接收调用请求
触发条件:调用Mybatis提供的API
传入参数:为SQL的ID和传入参数对象
处理过程:将请求传递给下层的请求处理层进行处理。
(3)处理操作请求
触发条件:API接口层传递请求过来
传入参数:为SQL的ID和传入参数对象
处理过程:
(A)根据SQL的ID查找对应的MappedStatement对象。
(B)根据传入参数对象解析MappedStatement对象,得到最终要执行的SQL和执行传入参数。
(C)获取数据库连接,根据得到的最终SQL语句和执行传入参数到数据库执行,并得到执行结果。
(D)根据MappedStatement对象中的结果映射配置对得到的执行结果进行转换处理,并得到最终的处理结果。
(E)释放连接资源。
(4)返回处理结果
将最终的处理结果返回。
MyBatis的主要构件及其相互关系
从MyBatis代码实现的角度来看,MyBatis的主要的核心部件有以下几个:
| 类或接口 | 描述 |
|---|---|
| SqlSession | 作为MyBatis工作的主要顶层API(sqlSessionFactory生产的),表示和数据库交互的会话,定义了数据库增删改查以及事务提交回滚等接口 |
| Executor | MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护,SqlSession通过调用Executor执行对应的sql,SqlSession中的insert方法和update方法都调用Executor中的update方法,select相关方法转成query相关方法 |
| StatementHandler | 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数、将Statement结果集转换成List集合。 |
| ParameterHandler | 负责对用户传递的参数转换成JDBC Statement 所需要的参数 |
| ResultSetHandler | 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合 |
| TypeHandler | 负责java数据类型和jdbc数据类型之间的映射和转换 |
| MappedStatement | MappedStatement维护了一条<select或update或delete或insert>节点的封装 |
| SqlSource | 负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回 |
| BoundSql | 表示动态生成的SQL语句以及相应的参数信息 |
| Configuration | MyBatis所有的配置信息都维持在Configuration对象之中。 |
交互逻辑如下图:
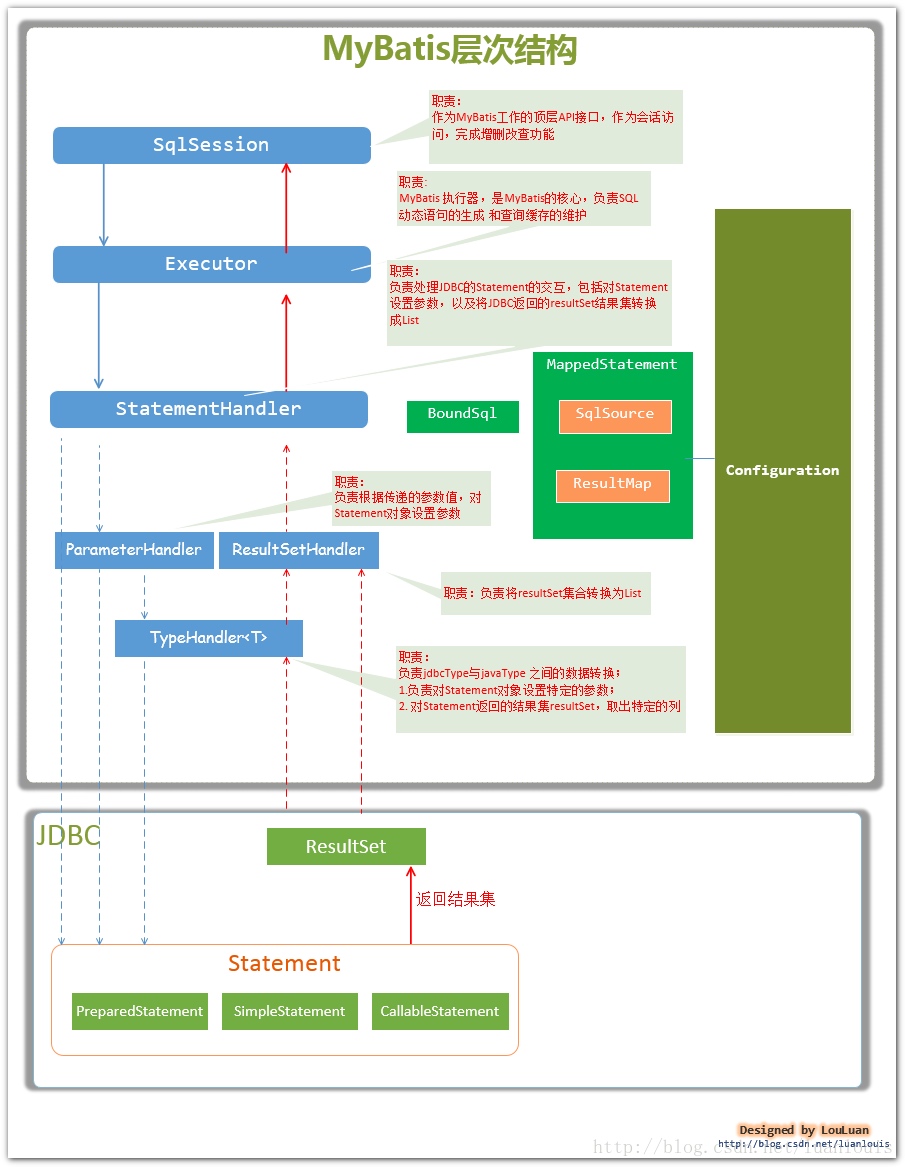
spring-jdbc源码分析
Spring-jdbc.jar的业务域是围绕数据源DataSource而展开的。我认为主要包括以下三个核心功能点:
- 数据源事务管理
- 数据源实现(多数据源的抽象实现和数据源的直接实现)
- 数据源使用接口层,面向CRUD接口的数据库操作模版类JdbcTemplate。
数据源事务管理
Spring事务管理的实现有许多细节,如果对整个接口框架有个大体了解会非常有利于我们理解事务,下面通过讲解Spring的事务接口来了解Spring实现事务的具体策略。
Spring事务管理涉及的接口的联系如下:
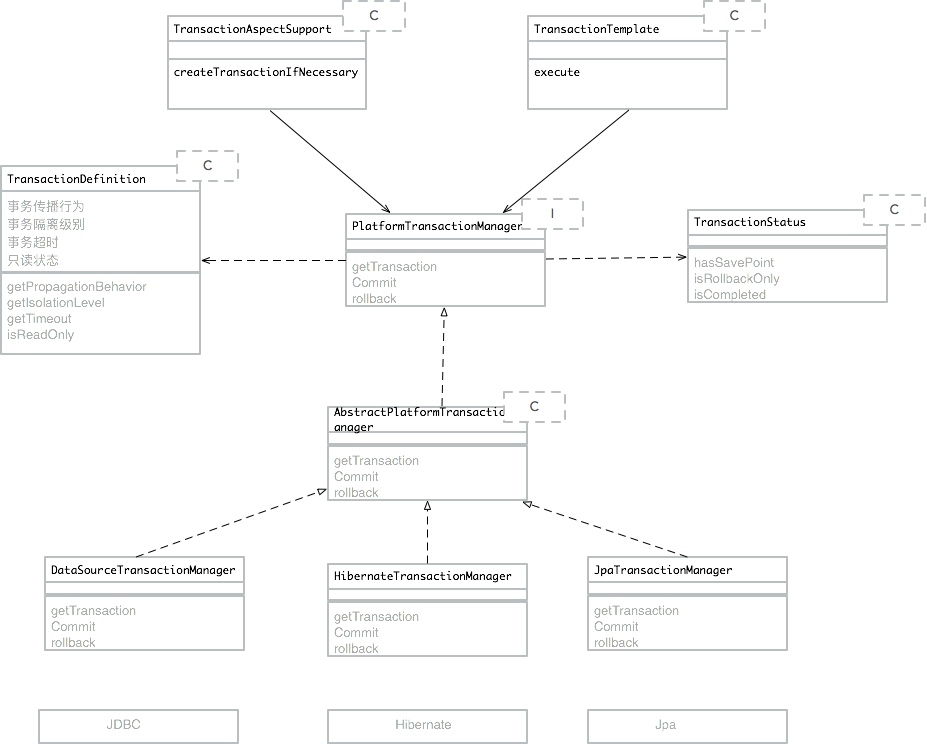
Spring事务管理器的接口是org.springframework.transaction.PlatformTransactionManager,在是Spring事务管理器的基础核心接口,此接口只定义了事务实现的三个方法:getTransaction(获取事务)、commit(事务提交)、rollback(事务回滚)。
从这里可知具体的事务管理机制对Spring来说是透明的,它并不关心那些,那些是对应各个平台需要关心的,所以Spring事务管理的一个优点就是为不同的事务API提供一致的编程模型,如JDBC的直接实现、Hibernate、JPA。以JDBC事务为例:如果应用程序中直接使用JDBC来进行持久化,DataSourceTransactionManager会为你处理事务边界,DataSourceTransactionManager是基于JDBC驱动的事务直接实现。为了使用DataSourceTransactionManager,你需要使用如下的XML将其装配到应用程序的上下文定义中:
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
实际上,DataSourceTransactionManager是通过调用java.sql.Connection来管理事务,而后者是通过DataSource获取到的。通过调用连接的commit()方法来提交事务,同样,事务失败则通过调用rollback()方法进行回滚。
上面讲到的事务管理器接口PlatformTransactionManager通过getTransaction(TransactionDefinition definition)方法来得到事务,这个方法里面的参数是TransactionDefinition类,这个类就定义了一些基本的事务属性。
那么什么是事务属性呢?事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。事务属性包含了5个方面(回滚规则以及以下定义的4个),对应的TransactionDefinition接口内容如下:
public interface TransactionDefinition {
int getPropagationBehavior(); // 返回事务的传播行为
int getIsolationLevel(); // 返回事务的隔离级别,事务管理器根据它来控制另外一个事务可以看到本事务内的哪些数据
int getTimeout(); // 返回事务必须在多少秒内完成
boolean isReadOnly(); // 事务是否只读,事务管理器能够根据这个返回值进行优化,确保事务是只读的
}
Spring的事务管理大致原理如下:
- 配置文件开启注解驱动,在相关的类和方法上通过注解@Transactional标识(或者tx标签、拦截器、代理等,下文会讲解5种方式),获取相应事务配置。
- spring 在启动的时候会去解析生成相关的bean,这时候会查看拥有相关注解的类和方法,并且为这些类和方法生成代理,并根据@Transaction的相关参数进行相关配置注入,这样就在代理中为我们把相关的事务处理掉了(开启正常提交事务,异常回滚事务)。
真正的数据库层的事务提交和回滚是通过connection对象往数据库发送相应指令,数据库必须支持事务,通常是通过binlog或者redo log实现的。
Spring事务传播
所谓spring事务的传播属性,就是定义在存在多个事务同时存在的时候,spring应该如何处理这些事务的行为。这些属性在TransactionDefinition中定义,具体常量的解释见下表:
| 常量名称 | 常量解释 |
|---|---|
| PROPAGATION_REQUIRED | 支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择,也是 Spring 默认的事务的传播。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。新建的事务将和被挂起的事务没有任何关系,是两个独立的事务,外层事务失败回滚之后,不能回滚内层事务执行的结果,内层事务失败抛出异常,外层事务捕获,也可以不处理回滚操作 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY | 支持当前事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果一个活动的事务存在,则运行在一个嵌套的事务中。如果没有活动事务,则按REQUIRED属性执行。它使用了一个单独的事务,这个事务拥有多个可以回滚的保存点。内部事务的回滚不会对外部事务造成影响。它只对DataSourceTransactionManager事务管理器起效。 |
Spring中事务实现的方式
Spring提供了对编程式事务和声明式事务的支持,编程式事务允许用户在代码中精确定义事务的边界,而声明式事务(基于AOP)有助于用户将操作与事务规则进行解耦。
简单地说,编程式事务侵入到了业务代码里面,但是提供了更加详细的事务管理;而声明式事务由于基于AOP,所以既能起到事务管理的作用,又可以不影响业务代码的具体实现。
** 编程事务 **
Spring提供两种方式的编程式事务管理,分别是:使用TransactionTemplate和直接使用PlatformTransactionManager。
使用TransactionTemplate
采用TransactionTemplate和采用其他Spring模板,如JdbcTempalte和HibernateTemplate是一样的方法。它使用回调方法,把应用程序从处理取得和释放资源中解脱出来。如同其他模板,TransactionTemplate是线程安全的。代码片段:
TransactionTemplate tt = new TransactionTemplate(); // 新建一个TransactionTemplate
Object result = tt.execute(
new TransactionCallback(){
public Object doTransaction(TransactionStatus status){
//DML操作
return resultOfUpdateOperation();
}
}); // 执行execute方法进行事务管理
使用PlatformTransactionManager
示例代码如下:
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(); //定义一个某个框架平台的TransactionManager,如JDBC、Hibernate
dataSourceTransactionManager.setDataSource(this.getJdbcTemplate().getDataSource()); // 设置数据源
DefaultTransactionDefinition transDef = new DefaultTransactionDefinition(); // 定义事务属性
transDef.setPropagationBehavior(DefaultTransactionDefinition.PROPAGATION_REQUIRED); // 设置传播行为属性
TransactionStatus status = dataSourceTransactionManager.getTransaction(transDef); // 获得事务状态
try {
// 数据库操作
dataSourceTransactionManager.commit(status);// 提交
} catch (Exception e) {
dataSourceTransactionManager.rollback(status);// 回滚
}
声明式事务
根据代理机制的不同,总结了四种Spring事务的配置方式,配置文件如下:
使用代理
<bean id="transactionProxy" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean" abstract="true">
<property name="transactionManager" ref="transactionManager"></property>
<property name="transactionAttributes">
<props>
<prop key="add*">PROPAGATION_REQUIRED, -Exception</prop>
<prop key="modify*">PROPAGATION_REQUIRED, -Exception</prop>
<prop key="del*">PROPAGATION_REQUIRED, -Exception</prop>
<prop key="*">PROPAGATION_REQUIRED, readOnly</prop>
</props>
</property>
</bean>
<bean id="userDao" parent="transactionProxy">
<property name="target">
<!-- 用bean代替ref的方式-->
<bean class="com.dao.UserDaoImpl">
<property name="sessionFactory" ref="sessionFactory"></property>
</bean>
</property>
</bean>
使用拦截器(不常用)
<bean id="transactionInterceptor" class="org.springframework.transaction.interceptor.TransactionInterceptor">
<property name="transactionManager" ref="transactionManager"></property>
<property name="transactionAttributes">
<props>
<prop key="add*">PROPAGATION_REQUIRED, -Exception</prop>
<prop key="modify*">PROPAGATION_REQUIRED, -Exception</prop>
<prop key="del*">PROPAGATION_REQUIRED, -Exception</prop>
<prop key="*">PROPAGATION_REQUIRED, readOnly</prop>
</props>
</property>
</bean>
<bean id="proxyFactory" class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator">
<property name="interceptorNames">
<list>
<value>transactionInterceptor</value>
</list>
</property>
<property name="beanNames">
<list>
<value>*Dao</value>
</list>
</property>
</bean>
使用tx标签配置的拦截器
<tx:advice id="txadvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="add*" propagation="REQUIRED" rollback-for="Exception" />
<tx:method name="modify*" propagation="REQUIRED" rollback-for="Exception" />
<tx:method name="del*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="*" propagation="REQUIRED" read-only="true"/>
</tx:attributes>
</tx:advice>
<aop:config>
<aop:pointcut id="daoMethod" expression="execution(* com.dao.*.*(..))"/>
<aop:advisor pointcut-ref="daoMethod" advice-ref="txadvice"/>
</aop:config>
全注解
<!--开启注解方式-->
<context:annotation-config />
<!-- 配置sessionFactory -->
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean">
<property name="configLocation">
<value>classpath:config/hibernate.cfg.xml</value>
</property>
<property name="packagesToScan">
<list>
<value>com.entity</value>
</list>
</property>
</bean>
<!-- 配置事务管理器 -->
<bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory"></property>
</bean>
<tx:annotation-driven transaction-manager="transactionManager"/>
此时在DAO上需加上@Transactional注解
Spring数据源实现
这里只分析面向多数据源的抽象实现AbstractRoutingDataSource和简单实现DataSource接口的DriverManagerDataSource。
多数据源的抽象实现
在我阅读分库分表sharingjdbc源码时以及我自己写读写分离中间件时,都用到了AbstractRoutingDataSource。实现数据源切换的功能就是自定义一个类扩展AbstractRoutingDataSource抽象类,其实该相当于数据源DataSource的路由中介,可以实现在项目运行时根据相应key值切换到对应的数据源DataSource上。先看看AbstractRoutingDataSource的源码:
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean {
/* 只列出部分代码 */
private Map<Object, Object> targetDataSources;
private Object defaultTargetDataSource;
private boolean lenientFallback = true;
private DataSourceLookup dataSourceLookup = new JndiDataSourceLookup();
private Map<Object, DataSource> resolvedDataSources;
private DataSource resolvedDefaultDataSource;
@Override
public Connection getConnection() throws SQLException {
return determineTargetDataSource().getConnection();
}
@Override
public Connection getConnection(String username, String password) throws SQLException {
return determineTargetDataSource().getConnection(username, password);
}
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
protected abstract Object determineCurrentLookupKey();
}
从源码可以看出AbstractRoutingDataSource继承了AbstractDataSource并实现了InitializingBean,AbstractRoutingDataSource的getConnection()方法调用了determineTargetDataSource()的该方法,这里重点看determineTargetDataSource()方法代码,方法里使用到了determineCurrentLookupKey()方法,它是AbstractRoutingDataSource类的抽象方法,也是实现数据源切换要扩展的方法,该方法的返回值就是项目中所要用的DataSource的key值,拿到该key后就可以在resolvedDataSource中取出对应的DataSource,如果key找不到对应的DataSource就使用默认的数据源。
自定义类扩展AbstractRoutingDataSource类时就是要重写determineCurrentLookupKey()方法来实现数据源切换功能。
下面是我写读写分离中间件时自定义的扩展AbstractRoutingDataSource类的部分实现。通过在获取连接Connection时根据sql类型判断是DML还是DQL,在线程的本地环境变量中放入选择主库master还是从库slave的key,然后在determineCurrentLookupKey方法中根据线程的本地变量中的key决定使用主库的DataSource还是从库的:
/**
*
* @Type DynamicDataSource
* @Desc 动态数据源,决定选择主库还是从库
* @author zhuyunkai
* @date 2017年11月20日
* @Version V1.0
*/
public class DynamicDataSource extends AbstractRoutingDataSource implements InitializingBean{
@Override
public Object determineCurrentLookupKey() {
// 使用DataSourceContextHolder保证线程安全,并且得到当前线程中的数据源key
if (DataSourceContextHolder.isSlave()) {
currentSlaveKey = getSlaveKey();
return currentSlaveKey;
}
Object key = "master";
return key;
}
}
Spring的DataSource简单实现
Spring中简单实现DataSource接口的DriverManagerDataSource类,直接和数据源驱动交互。
DriverManagerDataSource建立连接是只要有连接就新建一个connection,根本没有连接池的作用。当连接数到达一定的大小会出现异常。DriverManagerDataSource的配置如下:
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName">
<value>${jdbc.driverClassName}</value>
</property>
<property name="url"><value>${jdbc.url}</value></property>
<property name="username"><value>${jdbc.username}</value></property>
<property name="password"><value>${jdbc.password}</value></property>
</bean>
在正式项目或流量稍微大点的项目,我们都建议使用数据库的连接池实现DBCP或Druid。关于DriverManagerDataSource这里我们也不多做分析。
JdbcTemplate
面向CRUD接口的数据库操作模版类JdbcTemplate一定层度上可以替代ORM框架。JDBCTemplate帮我们省去了如下麻烦:
- 指定数据库连接参数.
- 打开数据库连接.
- 预编译并执行SQL语句.
- 遍历查询结果(如果需要的话).
- 处理抛出的任何异常.
- 处理事务.
- 关闭数据库连接
jdbctemplate的定义和使用非常简单,JdbcTemplate的dataSource属性就是注入配置的数据源。
<!-- 定义jdbctemplate -->
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource"/>
</bean>
JdbcTemplate主要提供以下五类方法:
execute方法:可以用于执行任何SQL语句,一般用于执行DDL语句;
update方法及batchUpdate方法:update方法用于执行新增、修改、删除等语句;batchUpdate方法用于执行批处理相关语句;
query方法及queryForXXX方法:用于执行查询相关语句;
call方法:用于执行存储过程、函数相关语句。
Druid源码分析
Druid不仅仅是一个数据库连接池,通过druid源码的包分类,可以看出druid的核心功能分为:数据库连接池、SQL解析、过滤器、统计监控、防攻击。其中数据库连接池和SQL解析是核心基础,这篇文章主要围绕这两块进行分析。
数据库连接池
我们就看看几个基本的类,以及它们之间的持有关系。
1、DruidDataSource持有一个DruidConnectionHolder的数组,保存所有的数据库连接
private volatile DruidConnectionHolder[] connections; // 注意这里的volatile
2、DruidConnectionHolder持有数据库连接,还有所在的DataSource等
private final DruidAbstractDataSource dataSource;
private final Connection conn;
3、DruidPooledConnection持有DruidConnectionHolder,所在线程等
protected volatile DruidConnectionHolder holder;
private final Thread ownerThread;
设计是有道理的。一个Connection对象可以产生多个Statement对象,当我们想同时保存Connection和对应的多个Statement的时候,就比较纠结。再看看DruidConnectionHolder的成员变量
private PreparedStatementPool statementPool;
private final List<Statement> statementTrace = new ArrayList<Statement>(2);
这样的话,既可以做缓存,也可以做统计。
最终我们对Connection的操作都是通过DruidPooledConnection来实现,比如commit、rollback等,它们大都是通过实际的数据库连接完成工作。而我比较关心的是close方法的实现,close方法最核心的逻辑是recycle方法:
public void recycle() throws SQLException {
if (this.disable) {
return;
}
DruidConnectionHolder holder = this.holder;
if (holder == null) {
if (dupCloseLogEnable) {
LOG.error("dup close");
}
return;
}
if (!this.abandoned) {
DruidAbstractDataSource dataSource = holder.getDataSource();
dataSource.recycle(this);
}
this.holder = null;
conn = null;
transactionInfo = null;
closed = true;
}
通过最后几行代码,能够看出,并没有调用实际数据库连接的close方法,而只是断开了DruidPooledConnection对DruidConnectionHolder的持有。用这种方式,来实现数据库连接的复用。
SQL解析
在 Druid 的 SQL 解析器中,有三个重要的组成部分,它们分别是:
- Parser(词法分析和语法分析)
- AST(Abstract Syntax Tree,抽象语法树)
- Visitor
这三者的关系如下图所示:
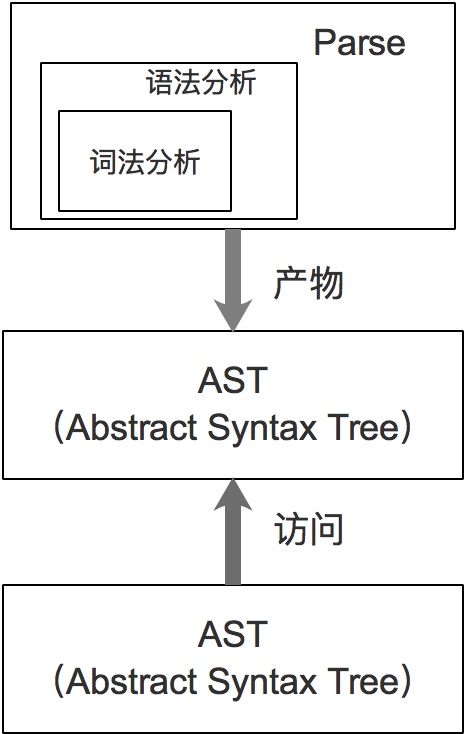
一个sql解析的基本步骤如下
String sql = "select * from user order by id";
// 新建 MySQL Parser
SQLStatementParser parser = new MySqlStatementParser(sql);
// 使用Parser解析生成AST,这里SQLStatement就是AST
SQLStatement statement = parser.parseStatement();
// 使用visitor来访问AST
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
statement.accept(visitor);
一开始,需要初始化一个 Parser,在这里 SQLStatementParser 是一个父类,真正解析Mysql语句的Parser实现是 MySqlStatementParser 。
Parser 的解析结果是一个SQLStatement,这是一个内部维护了树状逻辑结构的类。
词法分析
Druid 的代码里,代表语法分析和词法分析的类分别是 SQLParser 和 Lexer 。并且,Parser拥有一个Lexer。
public class SQLParser {
protected final Lexer lexer;
protected String dbType
public SQLParser(String sql, String dbType){
this(new Lexer(sql), dbType);
this.lexer.nextToken();
}
public SQLParser(Lexer lexer, String dbType){
this.lexer = lexer;
this.dbType = dbType;
}
}
SQLparse有两个子类SQLExprParser 和 SQLSelectParser。其中SQLExprParser是SQLSelectParser类中的一个私有对象,查询语句中的表达式解析是通过SQLExprParser来完成的。
每一种方言都有继承于Lexer的特定实现,比如mysql的Lexer为MySqlLexer。Lexer 作为词法分析器,必然拥有其词汇表,在Lexer里,以 Keywords 表示。
protected Keywords keywods = Keywords.DEFAULT_KEYWORDS;
Keywords 实际上是 key 为单词,value 为 Token 的字典型结构,其中 Token 是单词的类型,比如说,“select” 的 Token 类型就是 Select Token,而 “abc” 的 Token类型,则是标识符,也表示为Identifier Token。
MySqlLexer类,除了沿用其父类的 Keywords 外,也有属于MySQL数据库 SQL 方言的关键字集合。
Parser是Lexer的使用者,站在Parser的角度看,它会怎么去使用Lexer,或者说,Lexer应该具备怎样的功能,才能满足 Parser 的使用需求。
Lexer应该具备一个函数,能让使用者命令它解析一个单词,并且 Lexer 还必须提供一个函数,供使用者获取Lexer上一次解析到的单词以及单词的类型。
在 Lexer 中,nextToken() 这个方法提供了第一个需求,只要被调用,它就按顺序从 SQL 语句的开头到结尾,解析出下一个单词; token() 方法,则返回了上一次解析的单词的 Token 类型,如果 Token 类型是标识符(Identifier),Lexer 还提供了一个 stringVal() 方法,让使用者能拿到标识符的值。
走进 Lexer 的 nextToken() 方法,可以发现它的代码充斥着if语句和switch语句,因为解析单词的时候,是一个字符一个字符地解析,这就意味着,这个方法每次扫描一个字符,都必须判断单词是否结束,应该用什么方式来验证这个单词等等。这个过程,就是一个 状态机 运作的过程,每解析到一个字符,都要判断当前的状态,以决定应该进入下一个什么状态。
Select语法分析
有了 Lexer 这样的犀利工具,接下来就是 Parser 发挥的时候了,从 Demo 代码里可以看到,解析的开始,在于调用 parser.parseStatement() 方法。进到这个方法看看,发现清一色是形似如下格式的代码:
if (lexer.token() == Token.xxx) {
// 这里解析 xxx 类型
return;
}
if (lexer.token() == Token.aaa) {
// 这里解析 aaa 类型
return;
}
显然,如果是分析对Select类型语句的解析,那么应该关注以下的代码:
if (lexer.token() == Token.SELECT) {
statementList.add(parseSelect());
continue;
}
重点是 parseSelect() 方法, MySqlStatementParser 重载了它的父类的这个方法,因此这个方法实际上的实现细节是这样的
@Override
public SQLStatement parseSelect() {
MySqlSelectParser selectParser = new MySqlSelectParser(this.exprParser);
SQLSelect select = selectParser.select();
if (selectParser.returningFlag) {
return selectParser.updateStmt;
}
return new SQLSelectStatement(select, JdbcConstants.MYSQL);
}
初始化一个针对 MySQL Select 语句的 Parser,然后调用 select() 方法进行解析,把返回结果SQLSelect放到SQLSelectStatement里,而这个SQLSelectStatement,便是我最关心的 AST 抽象语法树,SQLSelect 是它的第一个子节点。
抛开解析的细节不谈,实际上我会非常关心这棵 AST 的层次结构。
打开SQLSelectStatement的代码,主要成员就是SQLSelect这个对象。SQLSelect中的主要三个对象:
protected SQLWithSubqueryClause withSubQuery; //这个对象可能是递归的
protected SQLSelectQuery query;
protected SQLOrderBy orderBy;
递归其实就是我们理解的树,在 Druid 眼里,它是这样看待一条 Select 语句的所有成员部分的。
Visitor
从 demo 代码中可以看到,有了 AST 语法树后,则需要一个 visitor 来访问它。其实对应的就是树的遍历问题。
// 使用visitor来访问AST
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
statement.accept(visitor);
System.out.println(visitor.getColumns());
System.out.println(visitor.getOrderByColumns());
statement 调用 accept 方法,以 visitor 作为参数,开始了访问之旅。在这里 statement 的实际类型是 SQLSelectStatement 。
在 Druid 中,一条 SQL 语句中的元素,无论是高层次还是低层次的元素,都是一个 SQLObject ,statement 是一种 SQLObject,表达式 expr 也是一种 SQLObject,函数、字段、条件等等,这些都是一种 SQLObject,SQLObject 是一个接口, accept 方法便是它定义的,目的是为了让访问者在访问 SQLObject 时,告知访问者一些事情,好让访问者在访问的过程中能够收集到关于该 SQLObject 的一些信息。
具体的 accept() 实现,在 SQLObjectImpl 这个类中,代码如下所示:
public final void accept(SQLASTVisitor visitor) {
if (visitor == null) {
throw new IllegalArgumentException();
}
visitor.preVisit(this);
accept0(visitor);
visitor.postVisit(this);
}
这是一个 final 方法,意味着所有的子类都要遵循这个模板,首先 accept 方法前和后,visitor 都会做一些工作。真正的访问流程定义在 accept0() 方法里,而它是一个 抽象方法 。
因此要知道 Druid 中是如何访问 AST 的,先拿 SQLSelectStatement 的 accept0() 方法来探探究竟。
protected void accept0(SQLASTVisitor visitor) {
if (visitor.visit(this)) {
acceptChild(visitor, this.select);
}
visitor.endVisit(this);
}
首先,使 visitor 访问自己,访问自己后,visitor 会决定是否还要访问自己的子元素。
打开 MySqlSchemaStateVisitor 的 visit 方法,可以看到,visitor 做了一些事,初始化了自己的 aliasMap,然后 return true,这意味着还要访问 SQLSelectStatement 的子节点。
public boolean visit(SQLSelectStatement x) {
setAliasMap();
return true;
}
接下来访问子元素
protected final void acceptChild(SQLASTVisitor visitor, SQLObject child) {
if (child == null) {
return;
}
child.accept(visitor);
}
由此可以看出,SQLObject 负责通知 visitor 要访问自己的哪些元素,而 visitor 则负责访问相应元素前,中,后三个过程的逻辑处理。
数据源连接参数解析
目前公司业务系统的数据源配置使用DBCP和DRUID两种,部分开发对连接的参数理解不是很清晰,对参数的配置没有依据业务系统的实际情况,导致连接等资源浪费。下面具体分析一下这两个数据源的配置参数。
| 参数名称 | DBCP默认参数 | DRUID默认参数 | 说明 |
|---|---|---|---|
| name(DRUID独有) | 无 | 无 | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this). 另外配置此属性至少在1.0.5版本中是不起作用的,强行设置name会出错。详情-点此处 |
| url | 无 | 无 | 连接数据库的url,不同数据库不一样。例如:</br>mysql : jdbc:mysql://10.20.153.104:3306/druid2</br>oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto |
| username | 无 | 无 | 连接数据库的用户名 |
| password | 无 | 无 | 连接数据库的密码。如果你不希望密码直接写在配置文件中,DRUID可以使用ConfigFilter。详细看这里 |
| driverClassName | 根据url自动识别 | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName |
| initialSize | 0 | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时。建议和minIdle一样 |
| maxActive | 8 | 8 | 最大连接池数量 |
| maxIdle | 8 | 8(已废弃) | 最大等待连接中的数量。超过空闲时间,数据库连接将被标记为不可用,然后被释放。druid已经不再使用,配置了也没效果 |
| minIdle | 0 | 0 | 连接池中最小的空闲的连接数,低于这个数量会被创建新的连接(默认为0,调整为5,该参数越接近maxIdle,性能越好,因为连接的创建和销毁,都是需要消耗资源的;但是不能太大,因为在机器很空闲的时候,也会创建低于minidle个数的连接,类似于jvm参数中的Xmn设置)。最小连接池数量,建议值参见下面的计算公式 |
| maxWait | 无限 | 2000ms | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。建议配置2000ms |
| poolPreparedStatements | false | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxPoolPreparedStatementPerConnectionSize(DRUID独有) | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 | |
| validationQuery | 无 | 无 | 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 |
| validationQueryTimeout | -1 | -1 | 单位:秒,检测连接是否有效的超时时间。 |
| testOnBorrow | true | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。建议值:false |
| testOnReturn | false | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testWhileIdle | false | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| removeAbandonedTimeout(或removeAbandonedTimeoutMillis) | 300(或300x1000) | 300(或300x1000) | 处理活跃连接(未关闭),针对连接泄漏、数据库死锁问题。超过时间限制,回收无用的连接(默认为 300秒),removeAbandoned必须为 true。数据库连接的状态:关闭、未关闭(活跃)、在执行(这个值执行前后会设置)。还在执行的连接不会被回收。 |
| removeAbandoned | true | false | 处理活跃连接,针对连接泄漏问题。是否清除已经超过removeAbandonedTimeout设置的无效连接。建议值:true |
| logAbandoned | false | false | 用于连接泄漏场景,关闭abandonded连接时是否输出错误日志。建议值:true |
| keepAlive(仅DRUID有) | false(1.0.28) | 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。 | |
| timeBetweenEvictionRunsMillis | 1分钟 | 1分钟(1.0.14) | 1) Destroy线程定时监测的间隔, Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
| numTestsPerEvictionRun(DBCP独有) | 3 | 不再使用 | 设定在进行后台对象清理时,每次检查几个链接,建议设置和maxActive一样大或者-1,这样每次可以有效检查所有的链接。DRUID不再使用,一个DruidDataSource只支持一个EvictionRun |
| minEvictableIdleTimeMillis | 30分钟 | 30分钟 | 连接保持空闲而不被驱逐的最长时间。建议值:5* timeBetweenEvictionRunsMillis |
| connectionInitSqls | 无 | 无 | 物理连接初始化的时候执行的sql |
| connectionProperties | 无 | 无 | 建立新连接时将发送到JDBC驱动程序的连接属性。字符串的格式必须为[propertyName = property;] 注 - “用户”和“密码”属性将被明确传递,因此不需要在此处包含**。 |
其中maxActive、minIdle、minEvictableIdleTimeMillis的配置需要根据业务的特性来配置。不根据实际情况,往大配置,会浪费数据库的资源,甚至影响其他应用。数据库最大连接默认值是100,最大值是16384,我们公司配置的是2000。
依据参数:
业务所有机器的平均QPS、峰值QPS、QPS平均RT(单位s,理论上是db的平均执行时间)、平均TPS、峰值TPS、TPS平均RT(单位s),业务机器数。
计算公式:
minIdle=(平均QPS* QPS平均RT +平均TPS* TPS平均RT)/业务机器数
maxActive=(峰值QPS* QPS平均RT +峰值TPS* TPS平均RT)/业务机器数
或者maxActive= 容器处理请求的线程池大小 (前提:业务代码中没有另起多线程)
以公司某工程为例(之前统计的TPS峰值是1700,一次TPS可能对应多条sql,以下QPS、TPS已经远超过实际值):
平均QPS=1000、峰值QPS=5000、QPS平均RT(单位s)= 0.0039、平均TPS=2000、峰值TPS=8000、TPS平均RT(单位s)=0.002、业务机器数=7
minIdle=(10000.0039+20000.002)/7=1
maxActive=(50000.0039+80000.002)/7=6
为了稳妥起见,按两倍(或者三倍)的容量评估,则minIdle配置成2。maxActive配置成12。
配置示例
DRUID数据源链接配置参数示例:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
<property name="maxActive" value="${参考计算公式}" />
<property name="maxWait" value="2000" />
<property name="logAbandoned" value="true" />
<property name="removeAbandoned" value="true" />
<property name="removeAbandonedTimeout" value="180" />
<property name="initialSize" value="5" />
<property name="minIdle" value="${参考计算公式}" />
<property name="minEvictableIdleTimeMillis" value="${参考计算公式}" />
<property name="validationQuery" value="SELECT 'x'" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="poolPreparedStatements" value="true" />
<property name="connectionInitSqls" value="set names utf8mb4;" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<bean/>
DBCP数据源链接配置参数示例:
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value=" com.mysql.jdbc.Driver" /><!—可以不配置 –->
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<property name="maxActive" value="${参考计算公式}" />
<property name="initialSize" value="${和minIdle 一样}" />
<property name="maxWait"><value>2000</value></property>
<property name="maxIdle" value="${和maxActive一样}" />
<property name="minIdle" value="${参考计算公式}" />
<property name="removeAbandoned"><value>true</value></property>
<property name="removeAbandonedTimeout"><value>180</value></property>
<property name="timeBetweenEvictionRunsMillis"><value>60000</value></property>
<property name="minEvictableIdleTimeMillis"><value>30000</value></property>
<property name="connectionProperties"><value>useUnicode=true;characterEncoding=utf-8</value></property>
<property name="testWhileIdle"><value>true</value></property>
<property name="testOnBorrow"><value>false</value></property>
<property name="testOnReturn"><value>false</value></property>
<property name="validationQuery"><value>SELECT @@version</value></property>
<property name="numTestsPerEvictionRun"><value>-1</value></property>
</bean>