热门
万字长文:一文彻底搞懂Elasticsearch中Geo数据类型查询、聚合、排序
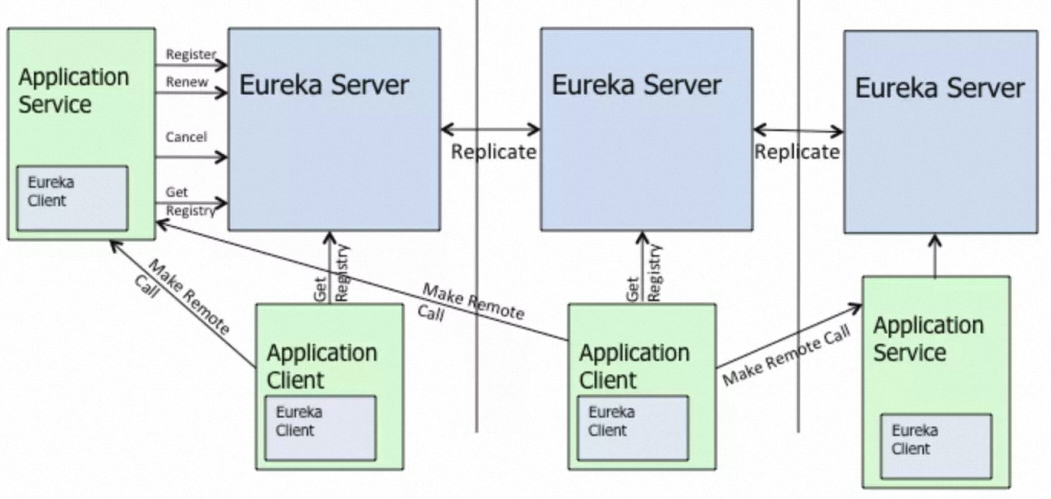
上一任留下的 Eureka,我该如何提升她的性能和稳定性(含数据比对)?
蚂蚁流场景状态演进和优化
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
对象存储oss使用问题之文件上传在暂停时报错:ResponseError: socket hang up如何解决
Vite中使用 echart
Vite挂载方法函数到全局
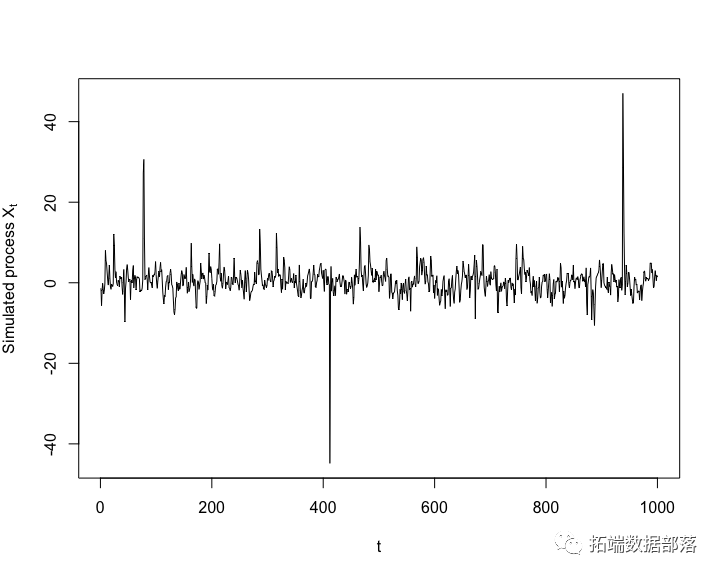
R语言连续时间马尔科夫链模拟案例 Markov Chains
解决Vue3.0项目多次运行后,项目体积增大问题(高达60G)
R语言中实现马尔可夫链蒙特卡罗MCMC模型
node安装常用工具
机器学习的线性模型简介
js校验统一社会信用代码
【Hive】sort by 和 order by 的区别
vue中高精度小数问题(加减乘除方法封装)处理
vue多页面系统配置步骤
对象存储oss使用问题之获取临时访问凭证报错:It is not a map value.如何解决
py获取时间戳
python的request库如何拿到json的返回值
py如何把字符串转出json
C++ 递归与面向对象编程基础
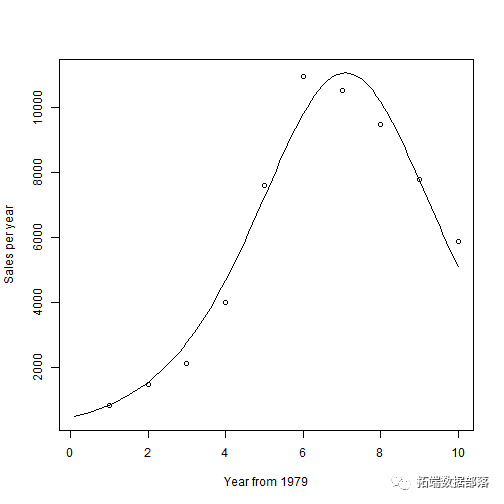
R语言Bass模型进行销售预测
【Hive】为什么要对数据仓库分层?
虎扑论坛数据分析
对象存储oss使用问题之进行文件上传时报错java.io.EOFException如何处理
ChatGLM3 源码解析(三)
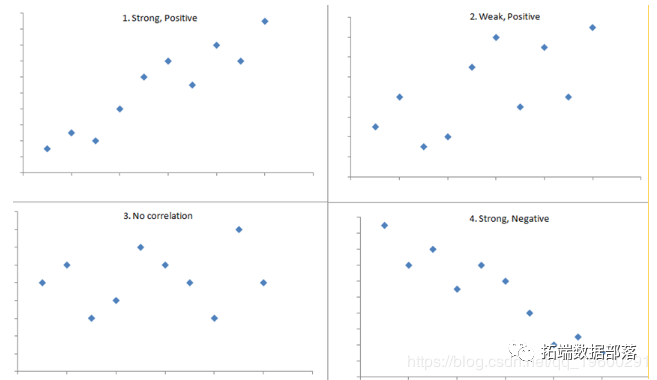
回归分析与相关分析的区别和联系
R如何与Tableau集成分步指南
用广义加性模型GAM进行时间序列分析
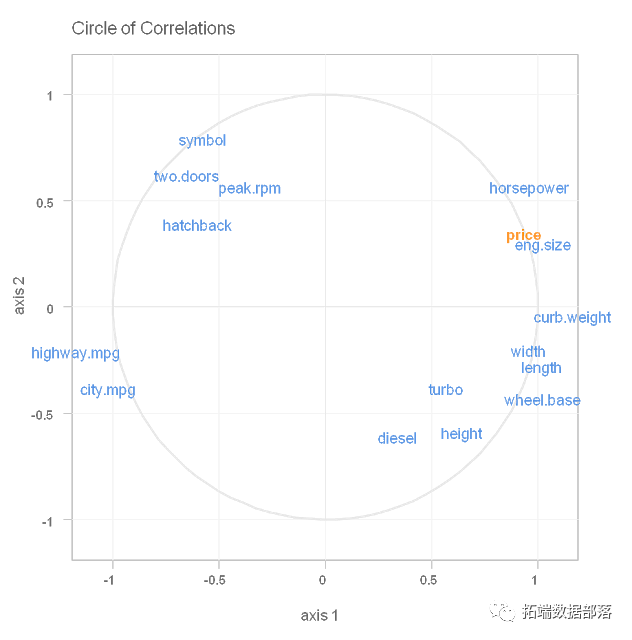
R语言中的偏最小二乘PLS回归算法
PokéLLMon 源码解析(六)(4)
PokéLLMon 源码解析(六)(3)
基于keras平台CNN神经网络模型的服装识别分析
R语言CRAN软件包Meta分析
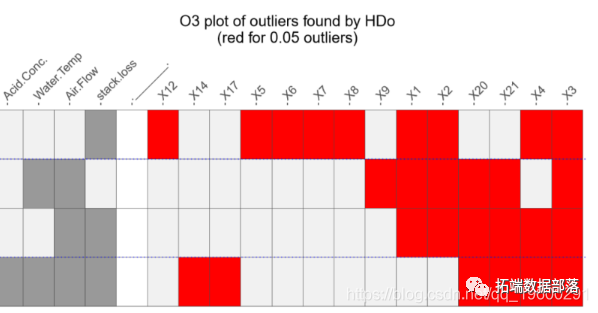
R语言异常值检测方法比较
PokéLLMon 源码解析(六)(2)
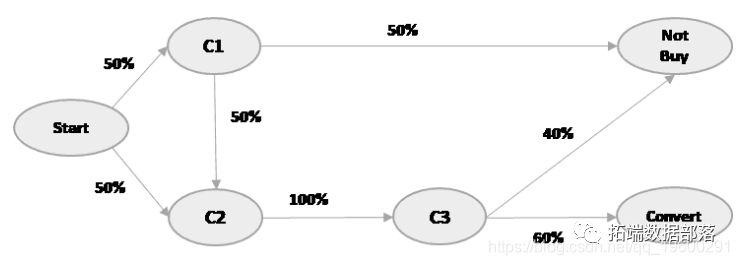
使用马尔可夫链对营销中的渠道归因建模
【Java NIO】那NIO为什么速度快?
基于ARCH模型股价波动率建模分析
PokéLLMon 源码解析(六)(1)
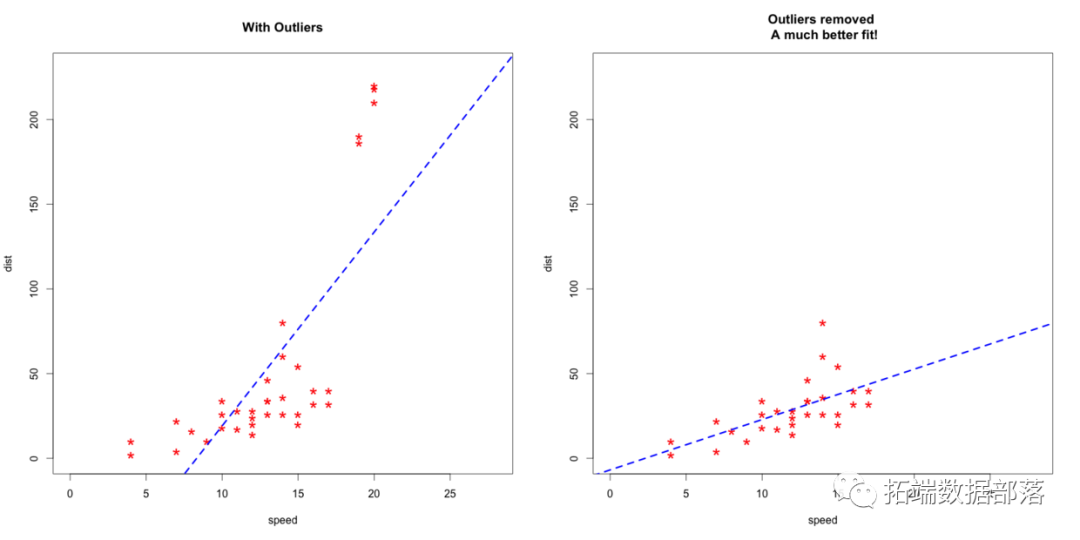
R语言离群值处理分析
R语言基于ARMA-GARCH过程的VaR拟合和预测
机器学习与深度学习
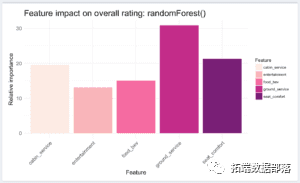
R语言用随机森林和文本挖掘提高航空公司客户满意度
R语言中实现层次聚类模型
如何通过评估方法评估机器学习模型的性能
公有云与人工智能的机会点
PokéLLMon 源码解析(五)(4)
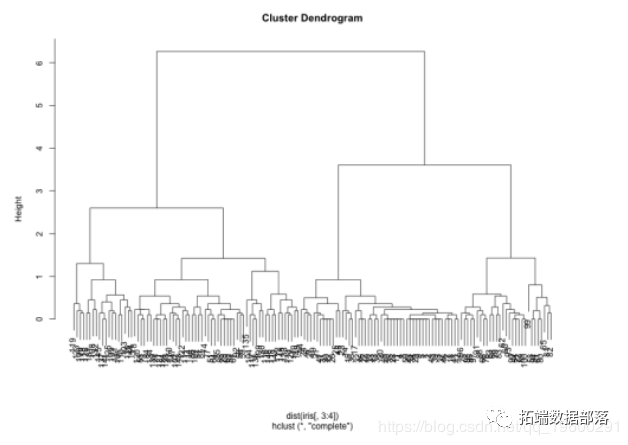
R语言鸢尾花iris数据集的层次聚类分析