数据库智能云平台(Hati,名字越大,责任越大)可以说是我们团队和DBA团队的定情之作。通过Hati项目,我们团队获得了DBA团队的信任,开启了更多合作之旅。Hati平台也将DBA从琐碎繁杂的工作中解脱出来,他们说他们的工作效率提升了60多倍。
在此非常感谢Hati的第一任开发洪阿南,一个后端开发搞定这么多复杂的前端交互设计开发,上线以来前端交互上没有听过任何吐槽,可以说征服了公司的开发。现任主力开发是一个刚入行的小鲜肉,虽是外包,但已出露韧性,应该能接过Hati这一棒。
诉求与背景
数据库是业务系统的根基,是每一个公司最核心的竞争力,关系整个公司的存亡。目前大部分公司业务核心的数据还是放在SQL数据库中,我们公司也不例外。目前我们的数据库智能云平台(Hati)核心功能也是围绕SQL数据库展开设计的。
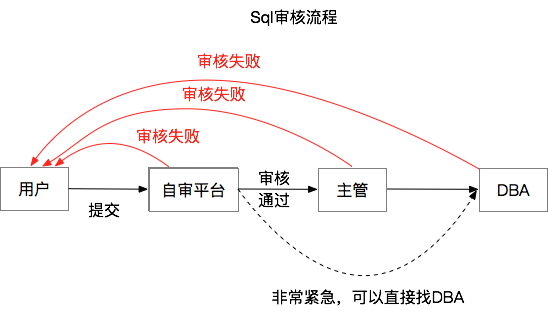
业务的发展、功能的完善离不开大量的建库建表语句、SQL变更语句、业务SQL语句。这些语句的审核执行过去像其他公司一样,都依赖于我们DBA专业素养。工单审核占据着DBA一半以上的工作时间。在数据库智能云平台(Hati)出现之前,开发通过开源的redmine提交SQL语句给DBA,DBA审核SQL时需要基于业务的具体现状,所以审核过程中不可避免会出现频繁的交互,导致效率的低下。
数据安全是任何一个公司不可忽视的问题。不能为了数据安全而不让开发访问数据库,毕竟很多线上问题的排查都离不开线上数据。我们要让开发看到该看的数据,敏感数据的访问需要相关人员的审批,要有访问时效的限制。在Hati出现之前,和很多公司一样,所有的开发通过堡垒机访问线上数据库,大家共享账号密码,或者使用应用配置中的用户名和密码。不但卡顿,对数据安全也带来了严重的安全隐患。
随着业务量的不断增长,数据库表的数据量不断增大。数据表的数据量超过千万,达到亿级别。如果这个时候数据库的访问压力(访问QPS和写入TPS)还在一个可接受的范围内(视sql类型而定,如果都是简单的sql,不存在回表量比较大的sql,每秒并发访问在1万以下)。我们一般还不会分库分表,毕竟分库分表会带来业务开发的复杂性。相信这个阶段每一个公司会经历。在这个时间段中,一般采用 库垂直拆分和分区表 来解决库表数据量比较大的问题,采用 读写分离 来解决访问压力比较大的问题。如果数据量和访问压力都上来了,建议使用分库分表,分库分表建议使用sharingjdbc,这是个客户端的解决方案,相对其他方案会比较轻量级。我们公司也是基于sharingjdbc改造而来。我们公司目前使用的读写分离(DML全部走主库,DQL走主或者从库)方案基于360开源的Atlas,这个框架已经不再维护,存在一些问题,而且是用C写的,目前大部分公司包括我们公司都是Java体系,基于Atlas的不方便做拓展,所以我们自己开发了读写分离中间件robustdb,后面我也会提到robustdb如何配合Hati做读写分离和管理的。
数据库规模迅速增大的同时也带来了巨大的成本压力。只要业务有需求,理论上可以通过增加更多的机器来满足业务需求。但是从另外一个角度来讲,这些机器是不是一定要加,是不是有一些机器可以通过优化节省下来给新的业务服务。同时,每年或者每半年,我们都要做服务器容量规划,规划需要多少机器才能支撑未来业务的增长需求,规划的依据需要全局化的数据支撑,需要基于历史的增长状况进行评估。因此我们需要有全局规模优化的能力,仅仅一个数据库实例内部做的优化都是一些局部优化,以全局角度来看是不够的。未来数据的存储成本都要核算到每一个系统上面,这样才能衡量一个系统的成本与价值。
每个公司在数据库性能优化方面都有很多的经验教训,不同公司对优化的具体做法也不太一样。在方式上大部分企业(之前我们公司也是)应该还是重人工模式,就是由数据库能力比较强的人,比如DBA,来解决数据库性能问题。业务发展速度远远超过了DBA团队发展的速度,单独依靠DBA重人工支持模式变得越来越困难。DBA优化一方面依赖他们的专业知识和经验,另一方面也需要深入了解业务,而且花在业务沟通上时间成本占整个优化时间的绝大部分。 其实我们可以换种思路,为什么解决数据库性能问题要以DBA为主、开发为辅呢?开发是最懂业务的,而且只有开发更懂数据库,才能写出更加稳健的系统,我们应该以开发为主,DBA为辅。同时,我们可以将DBA的优化知识和经验产品化,通过产品解决DBA人工服务的扩展性问题,是我们最直接的诉求,希望能把DBA人工服务产品化。
目前开源系统中没有找到能够满足我们公司数据库运维治理需求的系统,所以我们基于公司内部需求,开发了我们自己的数据库智能云平台Hati,这个平台还在迭代中,后续会引入数据分析、数据挖掘等功能,会采用主动诊断的方式去发现数据库异常,甚至是提前预测到故障的发生并进行及时干预。
业务域
hati是围绕sql审核、查询、数据库监控管理、性能治理等业务点,帮助DBA规范数据库相关操作流程、解决数据库潜在安全隐患、提供给开发者自助排查DB相关问题的统一平台。
通过与DBA深入讨论,我们把DBA在数据库运维、管理、优化等方面需求进行整理,分步骤分阶段的进行迭代开发,目前为止我们已经初步完成了自动化和产品化的建设。未来数据库优化服务会从自动化发展到智能化。比如精确的容量预估,智能的异常发现,故障提前预警等。现在我们有非常多的数据,也有数据加工分析的技术,我们也会进行一些探索,通过数据分析和机器学习等技术手段来解决之前解决不了的问题。比如最简单的容量预估,每年都会做预算,做容量预估。至少我现在还没有看到特别多的公司去用很科学的方式,完全基于业务目标以及历史数据的分析来做容量预估。很多时候容量预估是靠拍脑袋决定的,但是今天有了大量的数据和加工数据的技术手段,我们是不是可以做更精准的容量预估。
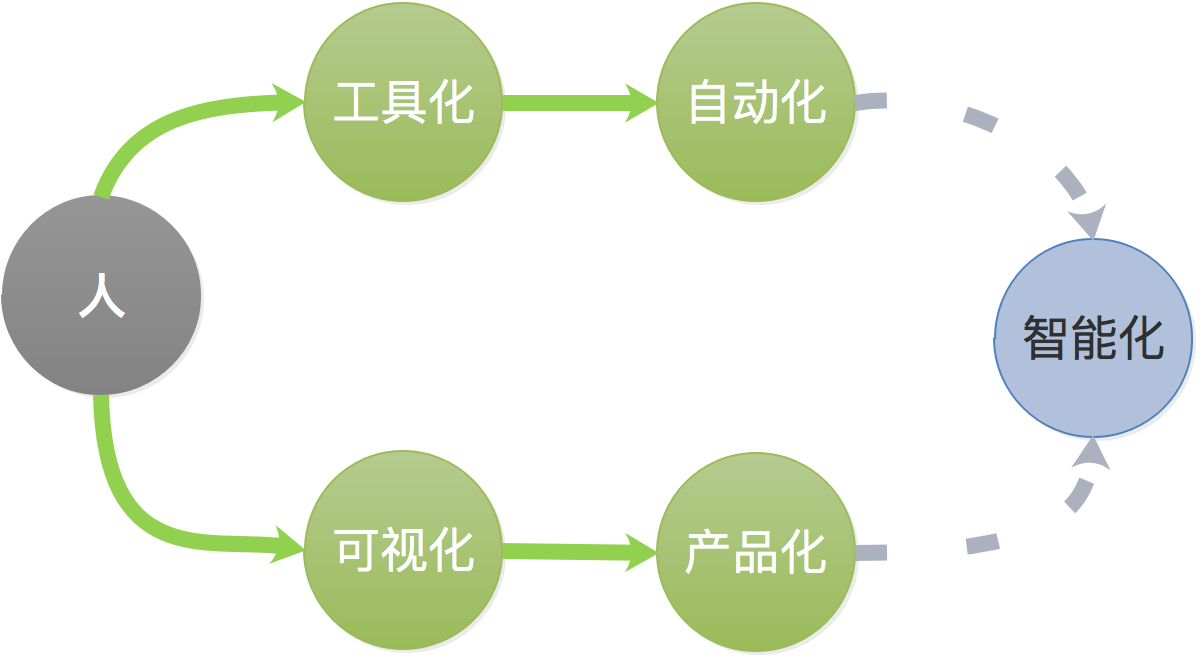
Hati现有业务架构图
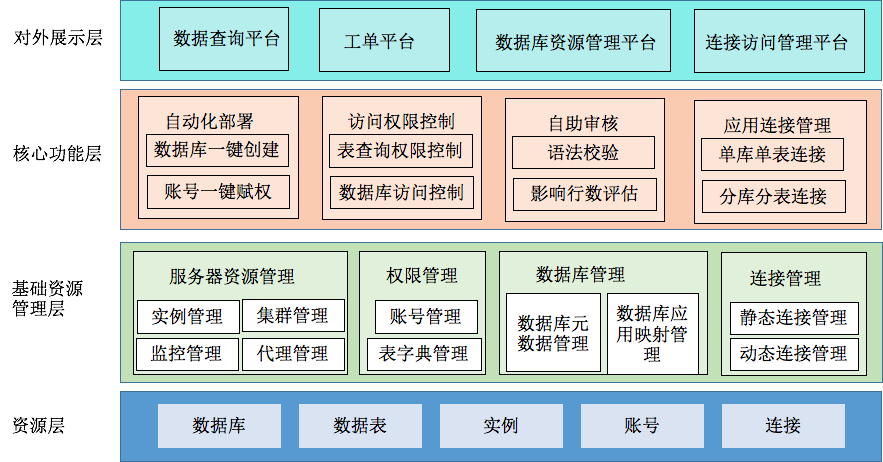
DBA管理的资源除了数据库、数据表还有一切衍生的资源,比如承载数据库的进程级别的实例资源、数据库访问的账号资源,以及数据库连接的配置资源。发现在很多公司(包括我们公司)开发,大家都数据库的认识都不够深,不知道一个数据库连接能处理多少并发请求。很多开发追求的是功能层面的连通,不会根据具体的业务需求去配置数据库的连接资源,通常配置一个很大的值,造成资源的浪费。所以我建议将数据库账号、连接 也交由DBA来控制,这样业务只需要拿一个密钥,去配管中心拉去加密后的数据库连接配置信息。
针对资源层的管理,我们抽取了基础资源管理层,将资源原子化以及服务化,我们抽象出了服务器资源资源管理、权限管理、数据库管理、连接管理。
服务器资源资源管理包括实例管理、集群管理、代理管理、存活监控管理(配合Robustdb组件过渡存在的一个功能)。
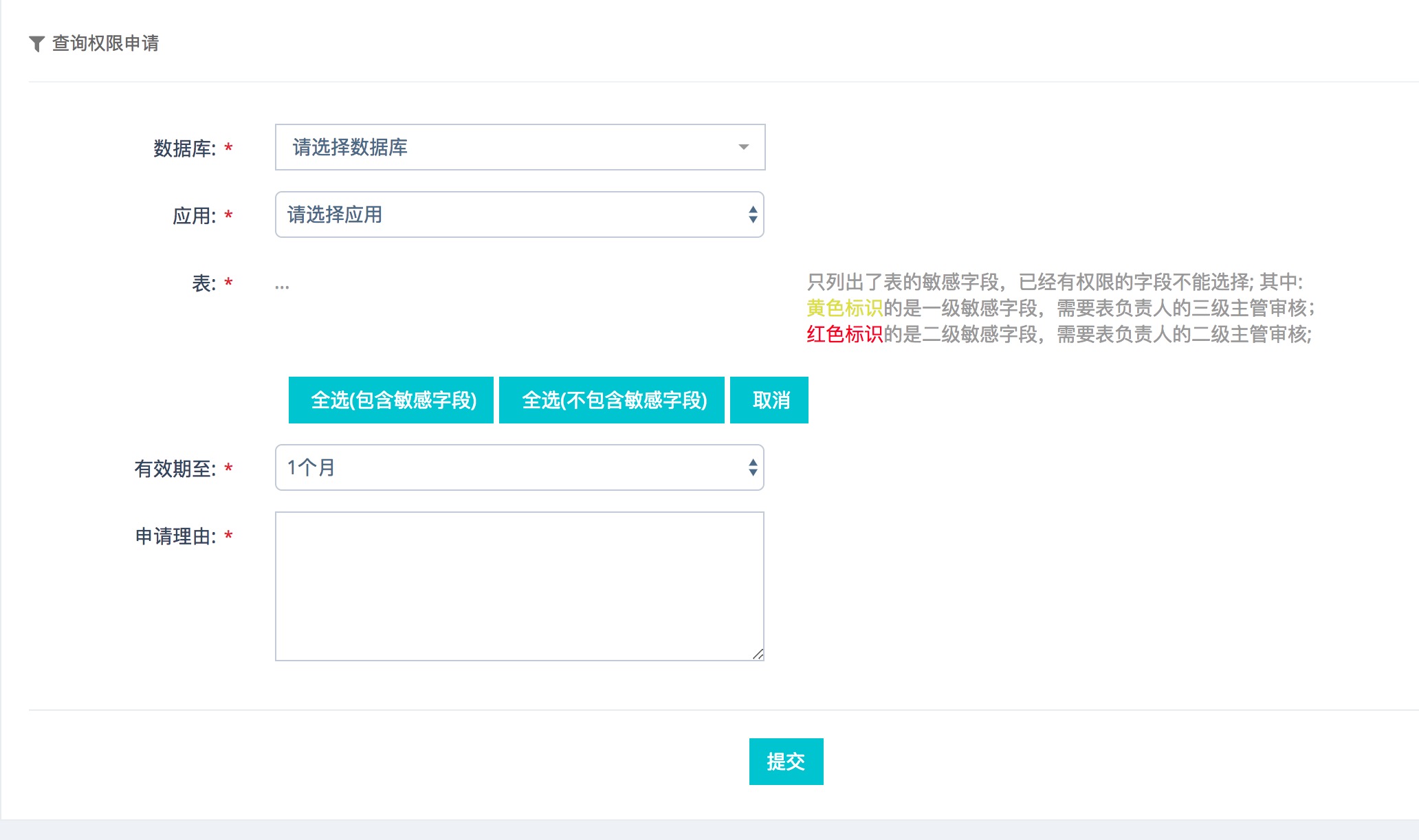
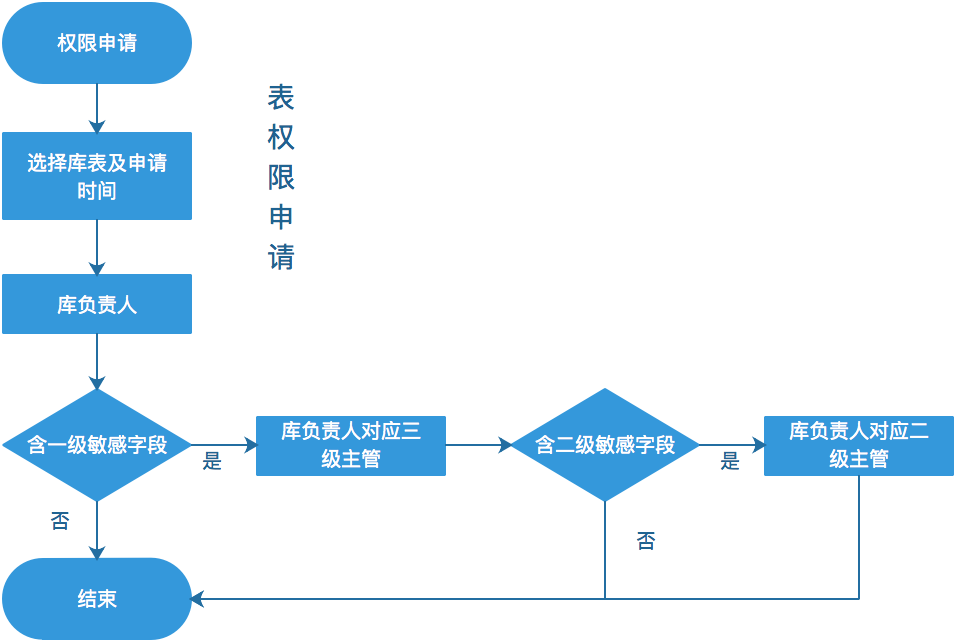
权限管理分账号管理、表字典管理。账号管理指的是库账号管理,主要包括应用访问账号、运维账号的配置管理。表字典管理主要用于控制每个表能被谁访问。每个表会归属到应用下,默认每个应用的开发能访问这个应用下所有表的字段(敏感字段除外),如果开放想访问其他应用的库表,需要在Hati上提交申请。
数据库管理包括数据库元数据管理和库和应用的映射关系。由于历史原因,存在一个库被多个应用使用和一个应用使用多个库。我们不建议一个库被多个应用使用。
连接管理包括静态连接管理、动态连接管理。静态连接指的是和某一个具体库(ip、端口、库名)数据源连接配置。动态库连接由多个静态库连接组成,每个静态库有角色区分(读或者写)以及多个读库的流量比例。
在基础资源管理层上面我们又抽象了核心功能层,包括自动化部署、访问权限控制、自助审核、应用连接管理。
自动化部署主要包括数据库一键创建、账号一键赋权。这些功能主要是配合脚本实现的。脚本是DBA小哥哥写的,这里给他们点个赞。
访问权限控制包括表查询权限控制、数据库访问控制、工单流转权限控制等,这里就不多说了。
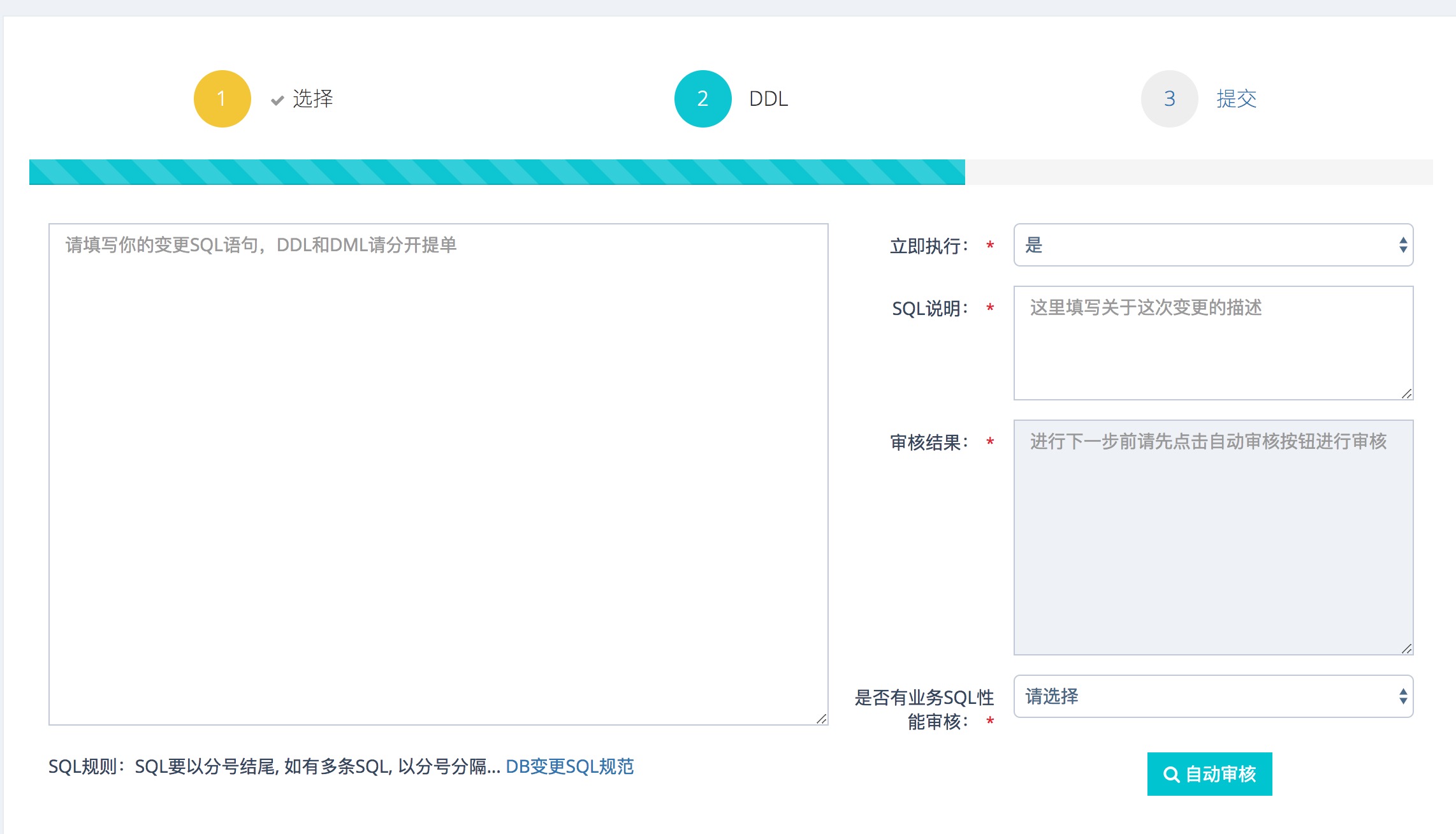
自助审核主要包括语法校验和影响行数评估。开发提交的sql往往存在问题,我们通过开源Inception组件实现了语法校验,让开发自己根据不通过的提示将sql修改正确再提交。为了拿到真实的影响行数,我们没有采用Inception的方案(Inception是基于Mysql执行计划的统计信息预估的,不是很准确)。我们通过将sql进行语法和此法解析,然后改成DQL去库中执行拿到真实的影响行数。
应用连接管理包括单库单表连接和分库分表连接。这些应用的数据源配置连接都是由动态连接组成。通过配管中心(我们内部配管中心应用叫gconfig)下发给应用。应用拿到连接,结合客户端jar包完成数据源的注入。
我们对外展示的是4个平台,数据查询平台、工单平台、数据库资源管理平台、和连接访问管理平台。这些平台不多介绍,直接上几个核心页面的图片:
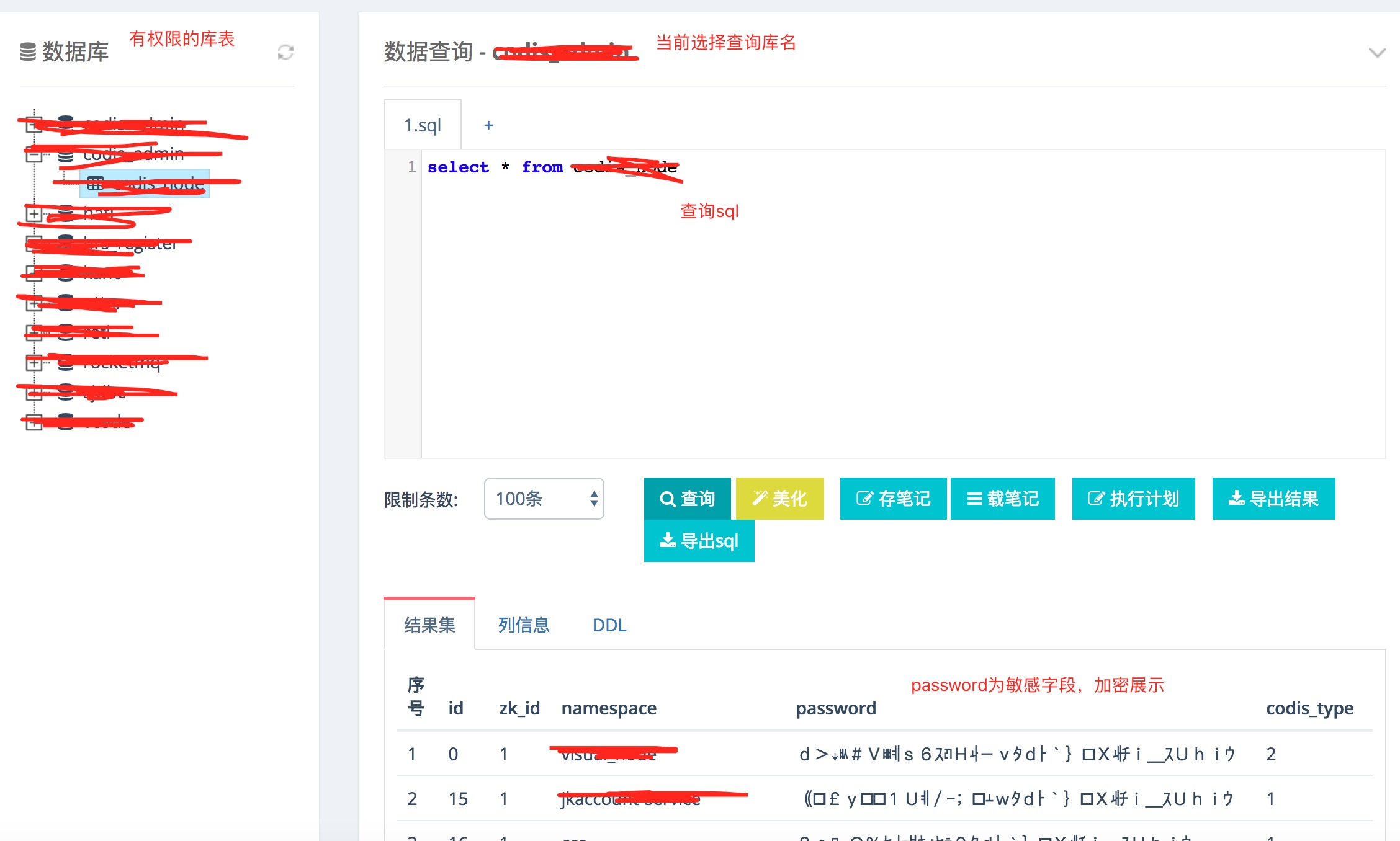
数据查询平台核心页面
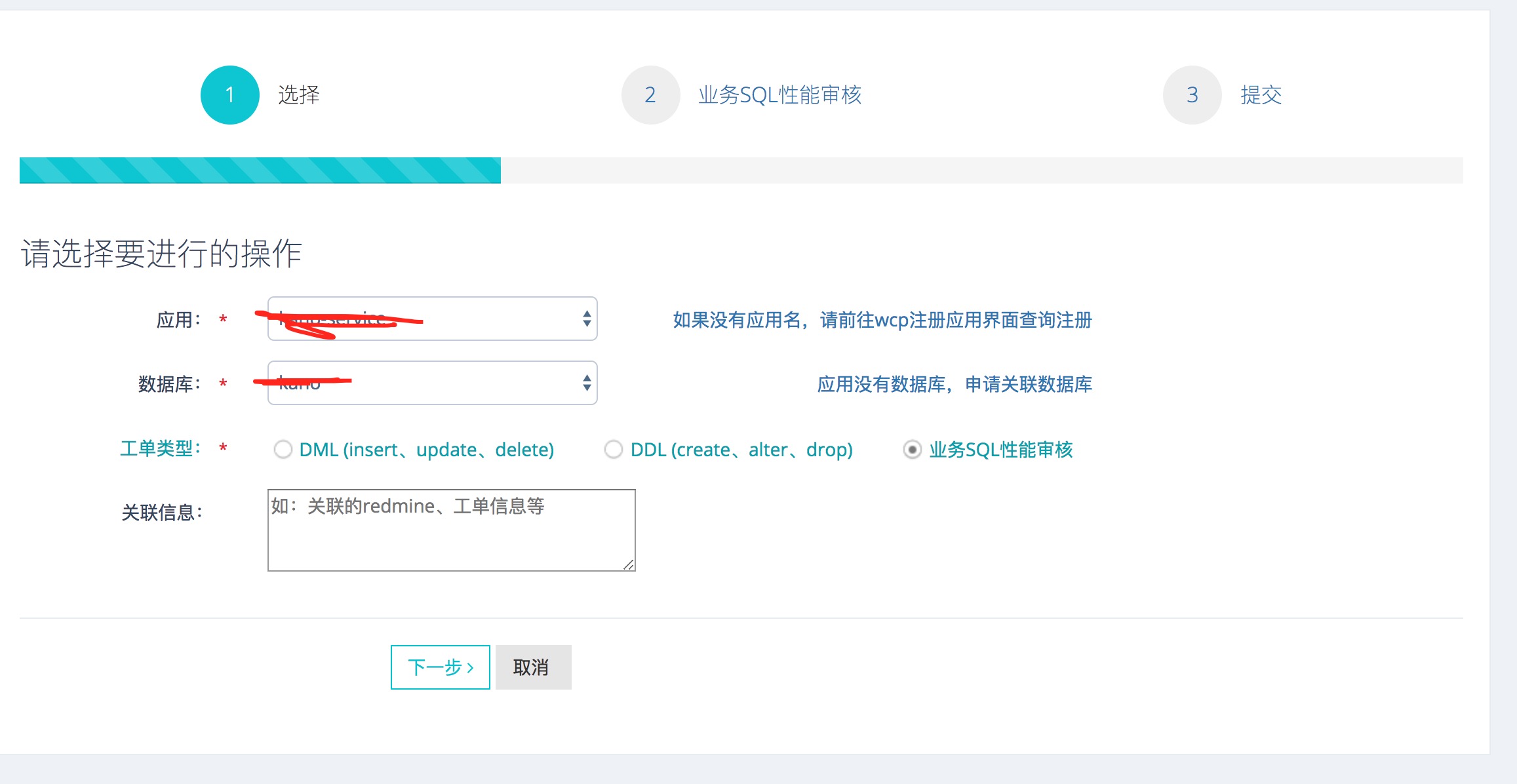
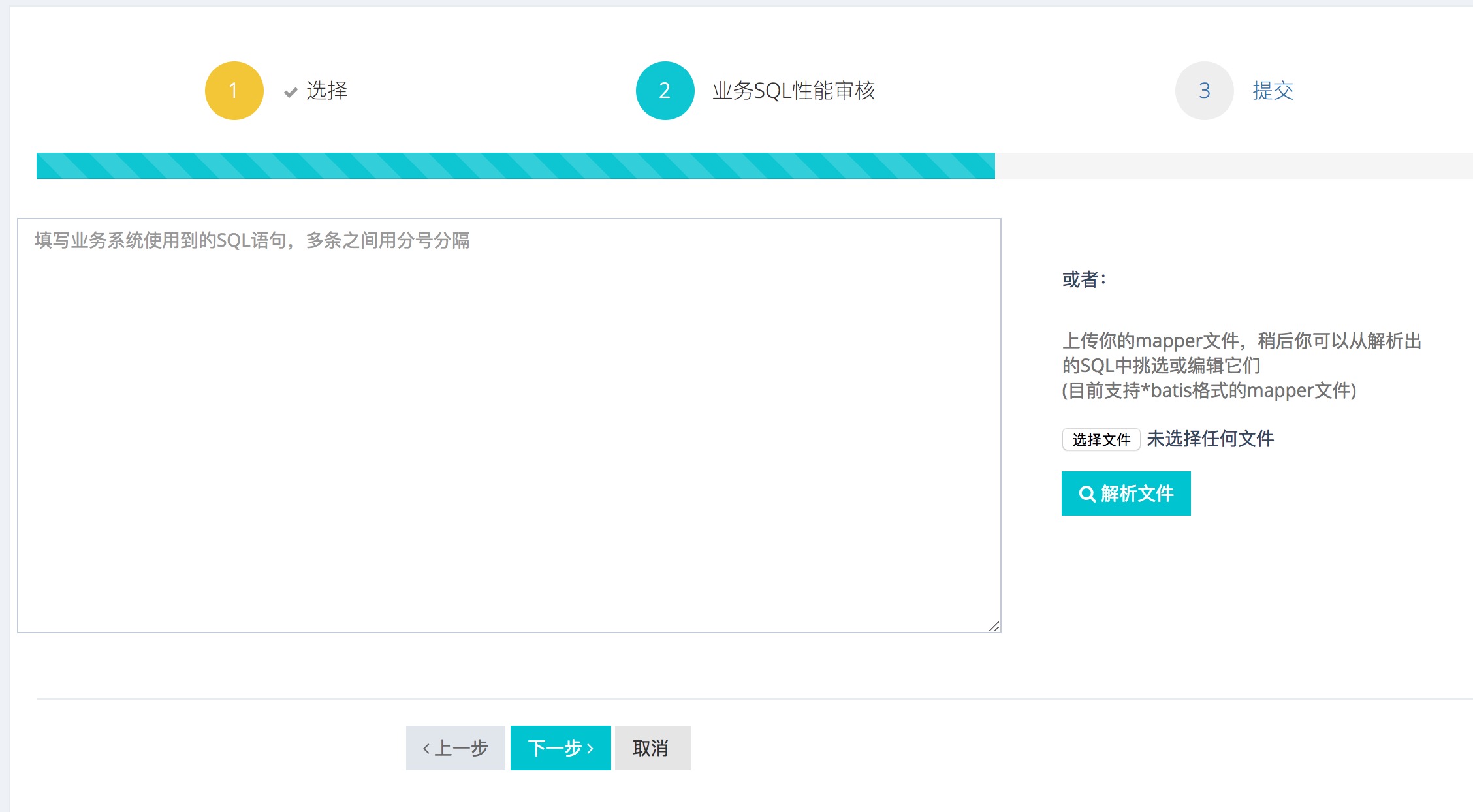
工单平台
应用数据库架构演进
随着业务量的增长,所有公司都不是直接选择分库分表设计方案的。很长一段时间内,会采用 库垂直拆分和分区表 来解决库表数据量比较大的问题,采用 读写分离 来解决访问压力比较大的问题。我们公司也是一样。目前绝大部分业务还是使用读写分离的方案。我相信很多公司和我们公司的架构一样,采用中间代理层做读写分离。结构如下:
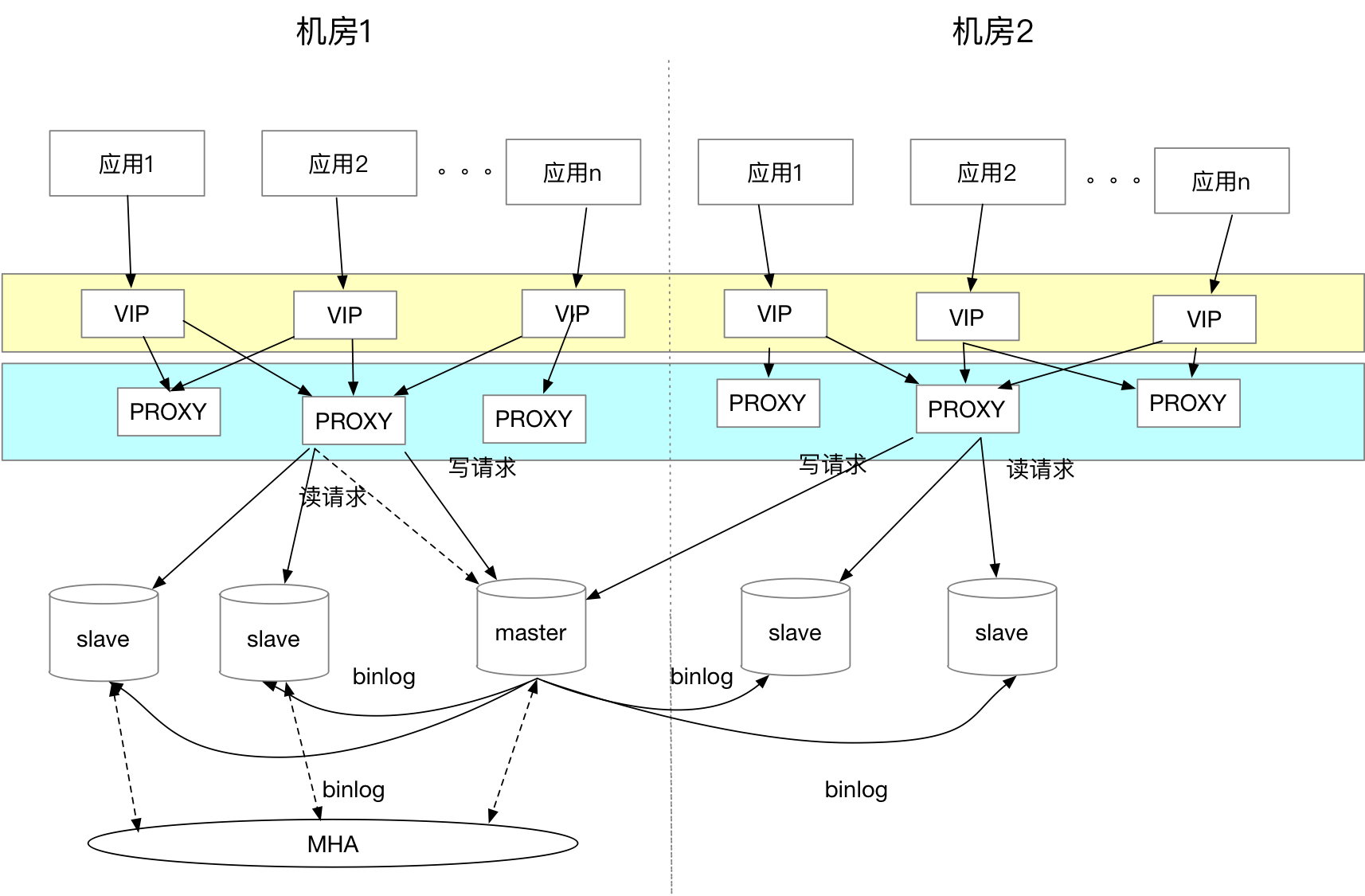
第一层是VIP,通过VIP做中间映射层,避免了应用绑定数据库的真实IP,这样在数据库故障时,可以通过VIP飘移来将流量打到另一个库。但是VIP无法跨机房,为未来的异地多活设计埋下绕不过去的坎。
VIP下面一层是读写分离代理,我们公司使用的是360的Atlas。Atlas通过将SQL解析为DML(Data Modify Language)和DQL(Data Query Language),DML的请求全部发到主库,DQL根据配置比例分发到读库(读库包括主库和从库)。
使用Atlas不足的地方如下:
1)Altas不再维护更新,现存一些bug,bug网上很多描述;
2) atlas中没有具体应用请求IP与具体数据库IP之间的映射数据,所以无法准确查到访问DB的请求是来自哪个应用
3)Altas控制的粒度是sql语句,只能指定某条查询sql语句走主库,不能根据场景指定。
4) DB在自动关闭某个与atlas之间的连接时,atlas不会刷新,它仍有可能把这个失效的连接给下次请求的应用使用。
5)使用atlas,对后期增加其他功能模会比较麻烦。
基于Atlas以上问题,以及我们需要将数据库账号和连接配置集中管控。我们设计了下面这套方案:
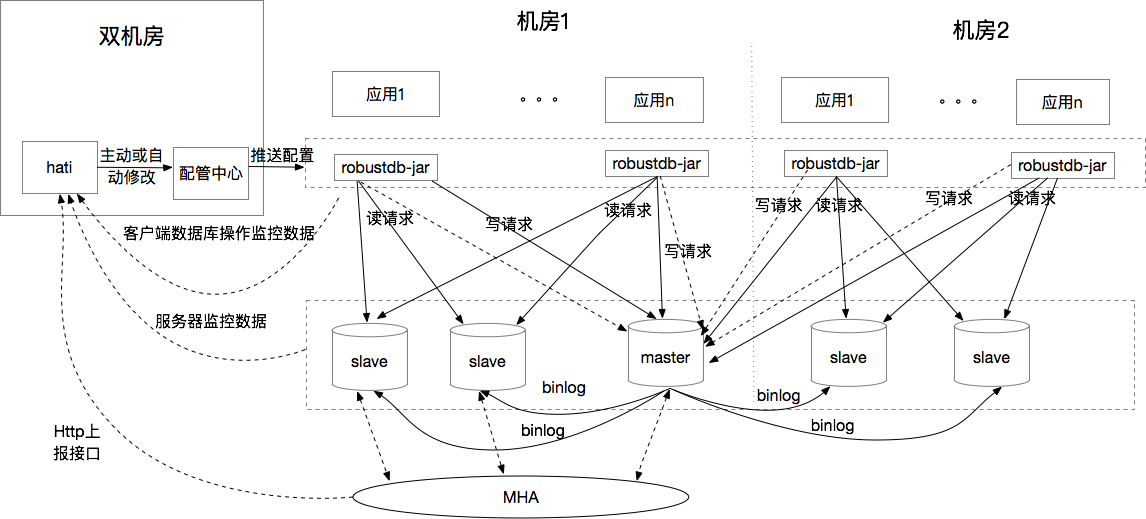
通过在客户端做读写分离可以解决Atlas上面存在的不足。robustdb的设计我会在另一篇文章中分析。
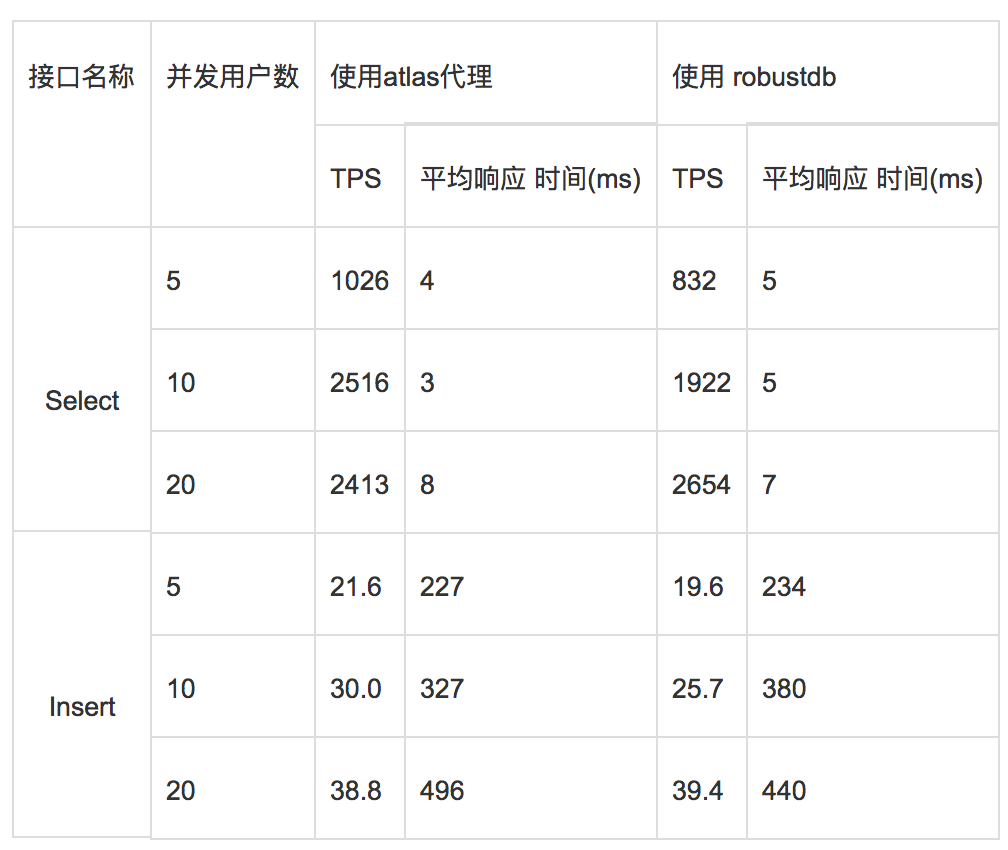
我们经过性能测试,发现Robustdb的性能在一定层度上比Atlas性能更好。压测结果如下:
Hati系统应用架构图
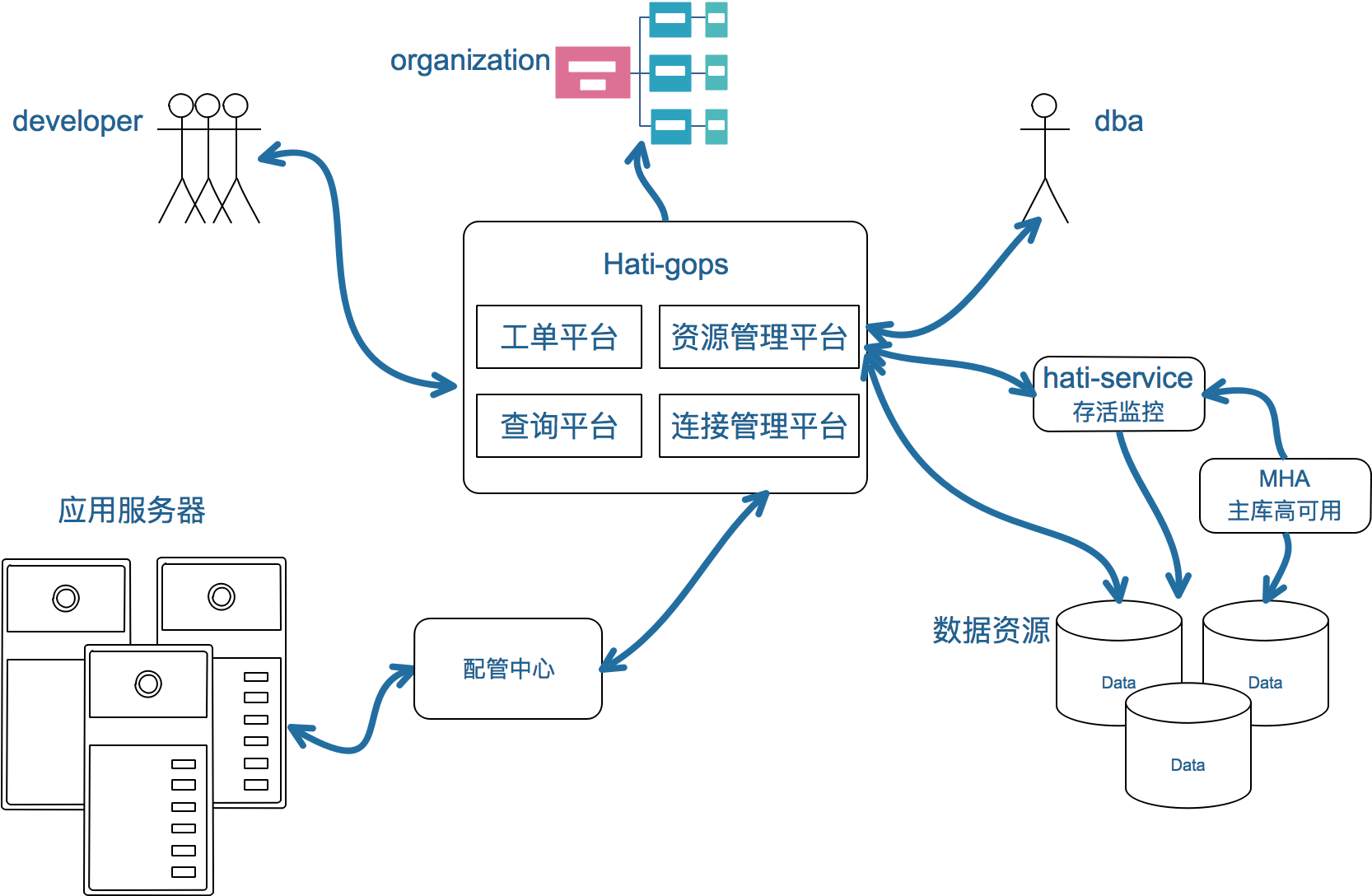
Hati作为一个平台将开发的需求转交DBA进行处理。Hati的工单平台、查询平台都涉及到权限控制,权限控制的基础是公司的人员架构组织关系。下面是工单审核和数据查询权限申请的流程。
同时Hati作为数据库资源的管理平台,依赖MHA的主从切换消息完成主库故障自修复,依赖Hati-service的从库存活检测完成从库故障自动摘除。Hati是通过公司的配管中心将指令下发给应用服务器的。
Hati数据库ER简图
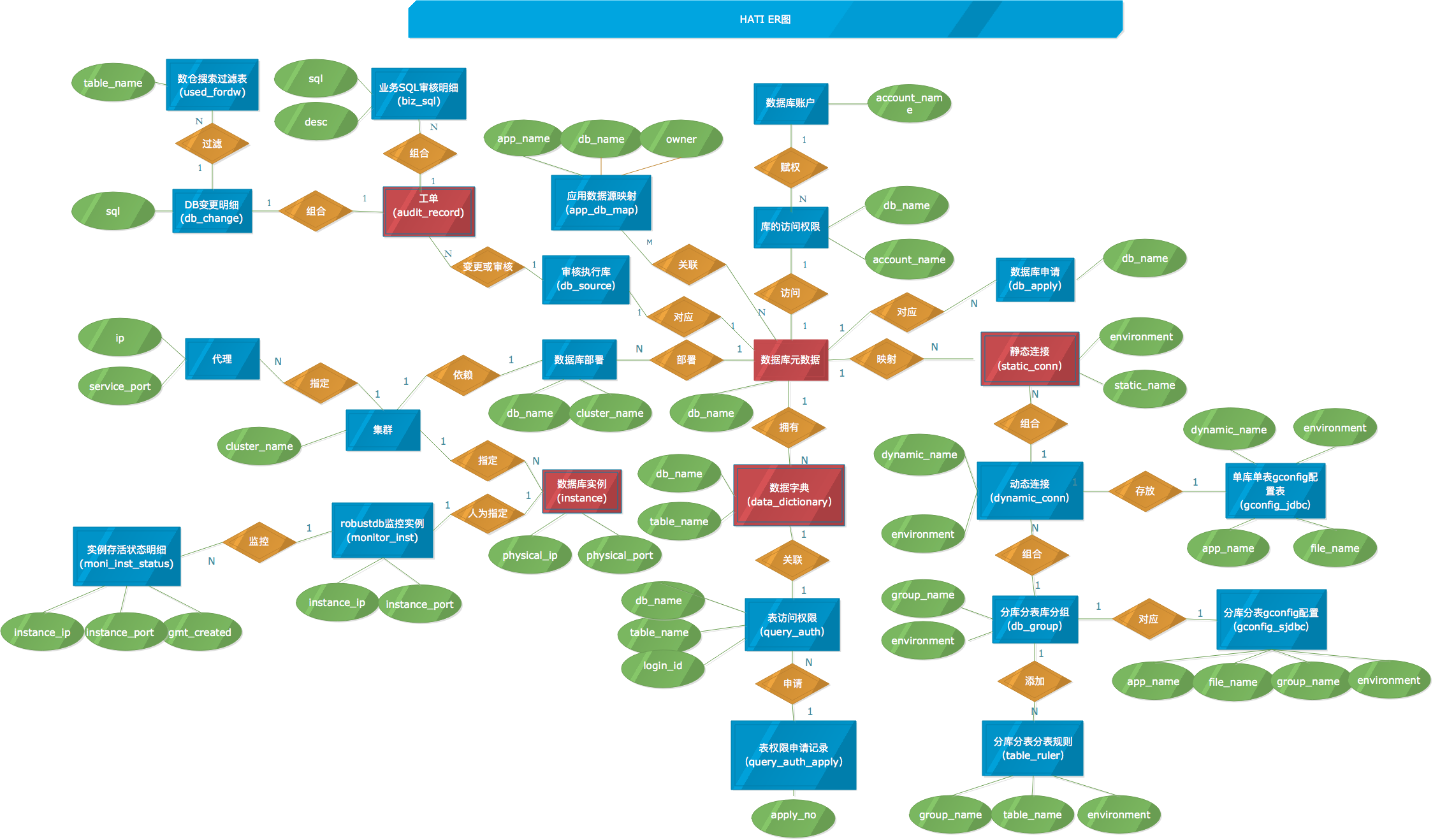
Hati数据表明细
库表的设计基本上按照数据库的三范式,通过对底层数据模型的梳理,可以最小成本的支撑Hati平台进行业务扩展。目前hati数据表根据hati的功能模块可以分为5大类。图中红色表是Hati的关键表,串联这Hati的核心功能。
1)Sql审核相关;对应的数据表有:业务SQL审核明细(biz_sql)、工单(audit_record)、DB变更明细(db_change)、应用数据源映射(app_db_map)、审核执行库(db_source)
2)数据查询相关;对应的数据表有:数据字典(data_dictionary)、表访问权限(query_auth)、表权限申请记录(query_auth_apply)
库账号管理相关;对应的数据表有:数据库元数据(db_meta)、数据库账号(db_account)、库的访问权限(db_authority)
数据库实例监控相关;对应的数据表有:数据库实例(instance)、robustdb监控实例(robustdb_monitor_instance)、实例存活状态明细(robustdb_status_detail)
5)动态代理相关;对应的数据表有:静态连接(robustdb_static_connection)、动态连接(robustdb_dynamic_connection)、gconfig单库单表配置(robustdb_gconfig_jdbc)
Hati的发展
根据公司目前的现状,下面三点可能是我们进一步完善Hati的方向。
- 慢sql的线上治理平台
- 数据库服务器的性能实时监控展示。让开发知道自己数据库的运行状况和优化验证
- 数据库的物理拓扑图展示,方便排查共实例或共机器引起的性能问题