爬虫用线程提速吧,用斗图网来做个对比。
普通爬虫,没用线程的例子:
import re,os,requests,time
from urllib import request
from lxml import etree
from fake_useragent import UserAgent
def get_url(url):
ua = UserAgent().random
headers = {'User-Agent':ua}
r = requests.get(url,headers=headers)
if r.status_code == 200:
print('请求成功')
return r.text
def parse(html):
html_data = etree.HTML(html)
# 这里获取的图片不包括 GIF 动图的形式,注意这种写法
imgs = html_data.xpath('//div[@class="page-content text-center"]//img[@class!="gif"]')
for img in imgs:
image_url = img.get('data-backup')
# 获取图片链接的后缀 单词是后缀的意思
suffixs = os.path.splitext(image_url)[1]
suffix = suffixs.replace(suffixs,'.jpg')
# 获取图片标题及剔除标题特殊字符
img_title = img.get('alt')
img_title = re.sub('[?\?。,\.!!]','',img_title)
filenamre = img_title + suffix
request.urlretrieve(image_url,'images/'+filenamre) # 保存图片到文件夹 images 下
print('保存图片成功')
def main():
for i in range(1,2):
print('第 %d 页' % i)
url = 'https://www.doutula.com/photo/list/?page={}'.format(i)
html = get_url(url)
parse(html)
if __name__ == '__main__':
start = time.time()
main()
end = time.time()
print('共运行了%s秒' % (end - start))
这里获取一页68图片,看一下运行速度:
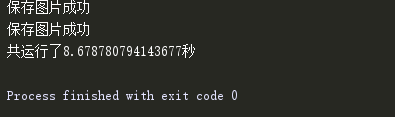
运行速度
生产者消费者模型
在这个例子中,定义两个队列,一个是获取页面的队列,一个是获取图片链接的队列。那么生产者就是这两个队列,消费者完成的任务就是下载图片到本地。
上述代码改造一下:
在main() 函数中,定义这两个队列:
def main():
page_queue = Queue(100) # 创建下载页面的队列
image_queue = Queue(1000) # 创建获取具体表情 url 的队列
for i in range(1,10):
print('第 %d 页' % i)
url = 'https://www.doutula.com/photo/list/?page={}'.format(i)
page_queue.put(url)
下载页面的队列的容量是100,put 方法将获取页面的url传入获取页面的队列中。
创建生产者模型:
# 创建生产者队列
class Procuder(threading.Thread):
# 重写父类构造函数,继承父类所有方法,同时添加两个参数
def __init__(self,page_queue,image_queue,*args,**kwargs):
super(Procuder,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.image_queue = image_queue
def run(self):
while True:
if self.page_queue.empty(): # 如果下载页面的队列为空,就结束循环
break
url = self.page_queue.get() # 获取页面url,交由解析图片url的方法解析图片url
self.parse(url)
def parse(self,url):
ua = UserAgent().random
headers = {'User-Agent':ua}
r = requests.get(url,headers=headers)
html_data = etree.HTML(r.text)
# 这里获取的图片不包括 GIF 动图的形式,注意这种写法
imgs = html_data.xpath('//div[@class="page-content text-center"]//img[@class!="gif"]')
for img in imgs:
image_url = img.get('data-backup')
# 获取图片链接的后缀 单词是后缀的意思
suffixs = os.path.splitext(image_url)[1]
suffix = suffixs.replace(suffixs,'.jpg')
# 获取图片标题及剔除标题特殊字符
img_title = img.get('alt')
img_title = re.sub('[?\?。,\.!!\*]','',img_title)
filenamre = img_title + suffix
self.image_queue.put((image_url,filenamre)) # 把图片的url传递给获取图片的队列
创建消费者模型
class Consumer(threading.Thread):
# 重写父类构造函数,继承父类所有方法,同时添加两个参数
def __init__(self,page_queue,image_queue,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.image_queue = image_queue
def run(self):
while True:
# 判断两个队列是否都为空,是就结束循环,不要让队列一直在等待操作
if self.page_queue.empty() and self.image_queue.empty():
break
image_url,filename = self.image_queue.get() # 获取具体表情的url队列中的图片url和文件名
request.urlretrieve(image_url,'images/'+ filename) # 保存图片到文件夹 images 下
print(filename + '保存图片成功')
主程序
def main():
page_queue = Queue(100) # 创建下载页面的队列
image_queue = Queue(1000) # 创建获取具体表情 url 的队列
for i in range(1,10):
print('第 %d 页' % i)
url = 'https://www.doutula.com/photo/list/?page={}'.format(i)
page_queue.put(url)
# 分别创建五个生产者,五个消费者,开启线程
for i in range(5):
t = Procuder(page_queue,image_queue)
t.start()
for i in range(5):
t = Consumer(page_queue,image_queue)
t.start()
if __name__ == '__main__':
main()
几百张图片几乎在两三秒就下载完成了。