热门
万字长文:一文彻底搞懂Elasticsearch中Geo数据类型查询、聚合、排序
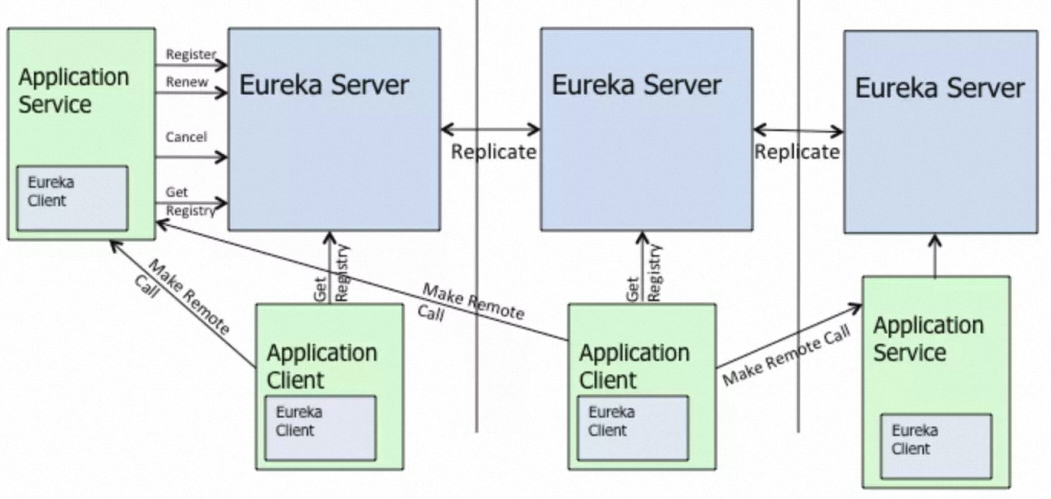
上一任留下的 Eureka,我该如何提升她的性能和稳定性(含数据比对)?
蚂蚁流场景状态演进和优化
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
数据加载与保存:Pandas中的数据输入输出操作
python面型对象编程进阶(继承、多态、私有化、异常捕获、类属性和类方法)(上)
python 格式化、set类型和class类基础知识练习(下)
python 格式化、set类型和class类基础知识练习(上)
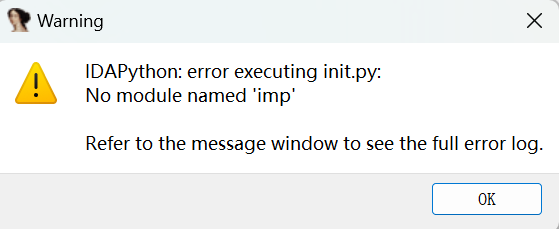
IDA3.12版本的python,依旧报错IDAPython: error executing init.py.No module named ‘impRefer to the message win
ubuntu更换国内镜像源,下载增速
Pandas数据结构详解:Series与DataFrame的奥秘
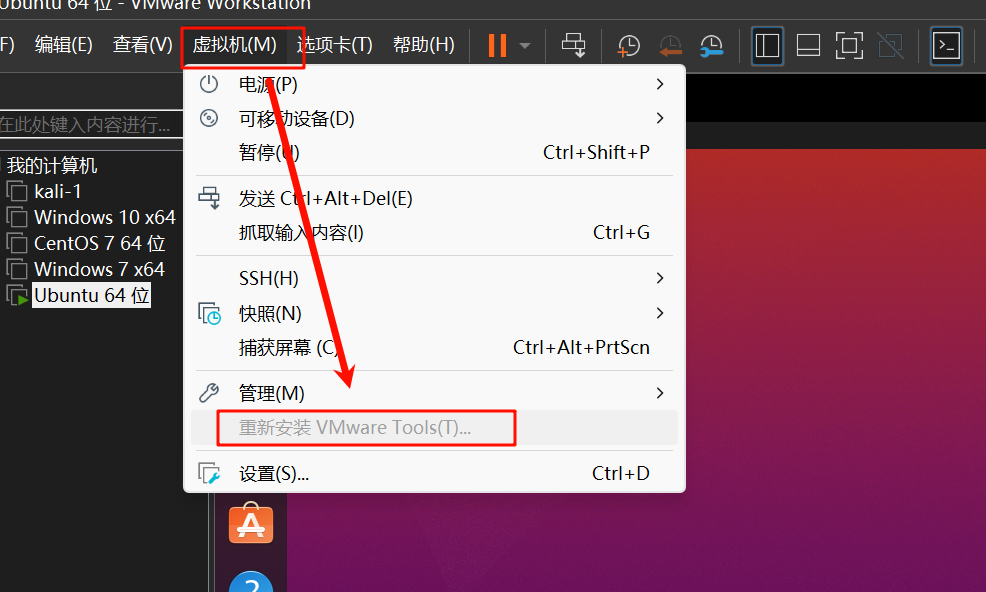
ubuntu无法粘贴复制windows中的内容,分辨率无法自适应电脑自带系统
解决新装好的ubuntu没有root权限
如何利用CRM业务流程管理实现双赢?探索成功案例!
Pandas入门指南:开启数据处理之旅
python 文件操作和学生管理系统练习
0基础安装激活版本office2016
vue项目实战:实战技巧总结(下)
关闭windows11(10)自动更新工具
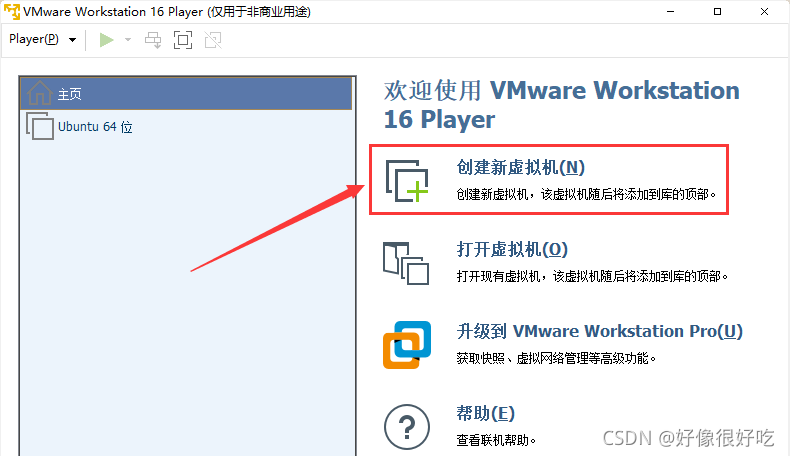
0基础教你安装VM 17PRO-直接就是专业许可证版
windows11物理机和VM中windows10虚拟机共享文件解决办法问题
Typora的使用说明
vue项目实战:实战技巧总结(中)
VX防撤回以及多开
GE通用电气 IC698PSA350 PACSystem RX7i 高容量电源模块
0基础安装Burpsuit专业版
0-hackbar最新版本(2.3.1)工具安装(超详细)
0-零基础安装ubuntu(超详细安装步骤)
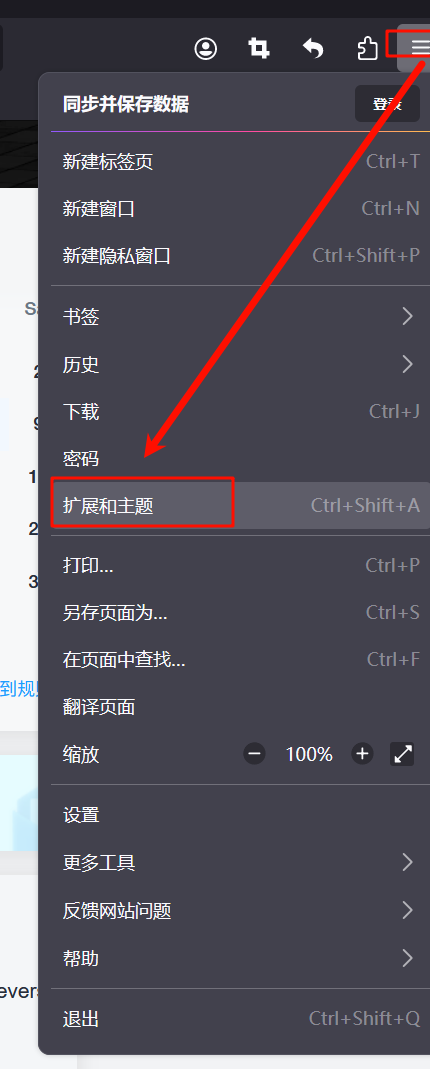
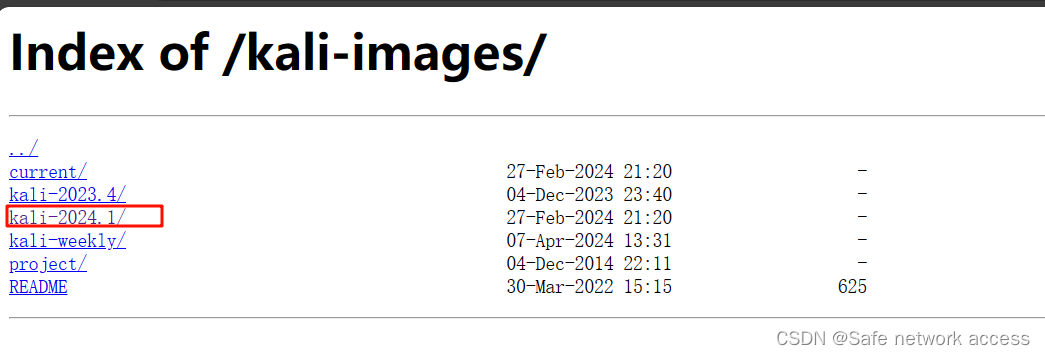
0-超详细基础安装linux系统-kali
08-python的文件操作-读写
vue项目实战:实战技巧总结(上)
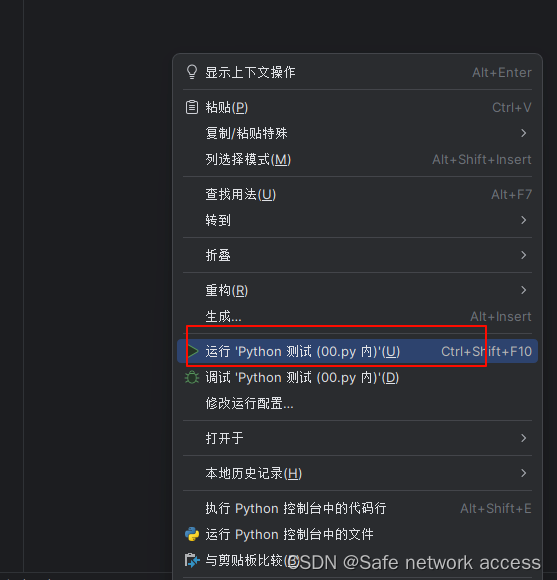
Pycharm运行提示(运行‘Python测试(00.py内)‘(u)
1688商品详情API接口获取商品信息
07-python函数的进阶-函数的多返回值/函数的多种传参方式/匿名函数/lambda函数
信息量&信息熵
06-数据容器拓展-字符串之间的比较
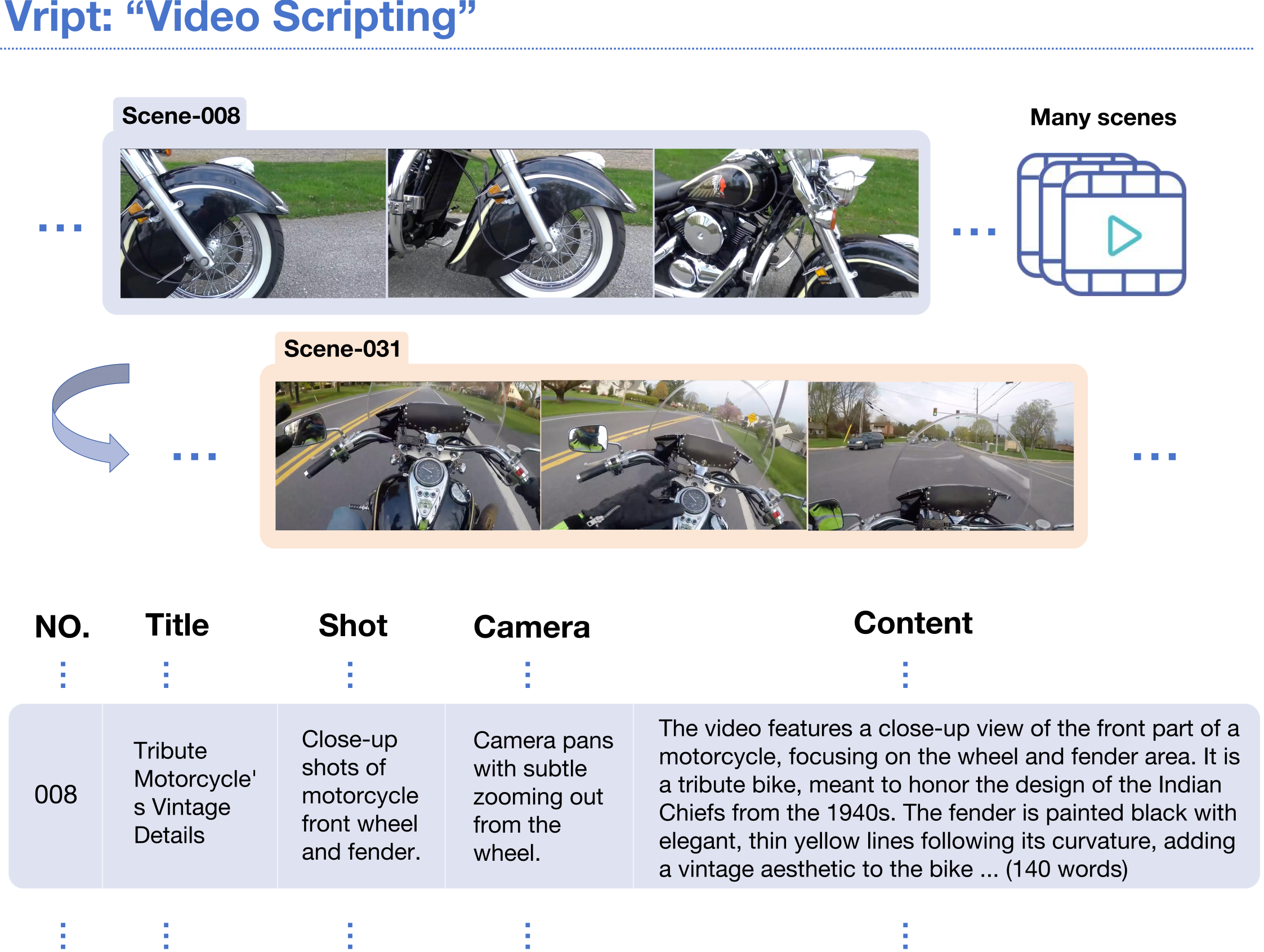
Vript:最为详细的视频文本数据集,每个视频片段平均超过140词标注 | 多模态大模型,文生视频
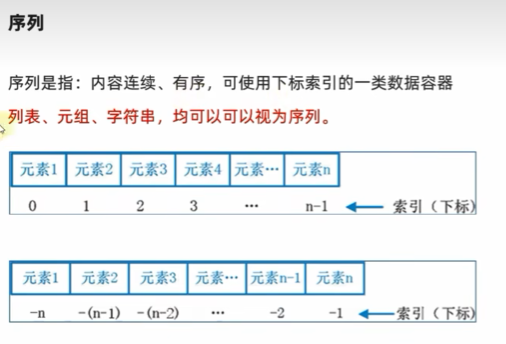
06-数据容器总结,多种类型容器对比
Flask监控与日志记录:掌握应用运行状况
python学习-函数模块,数据结构,字符串和列表(下)
python学习-函数模块,数据结构,字符串和列表(上)
[AFCTF2018]BASE解题思路
Flask性能优化:打造高性能Web应用
06-数据容器(字典)基础知识0基础来学
06-python数据容器-set(集合)入门基础操作
Flask应用部署指南:从开发到生产环境
06-数据容器(序列列表-元组-字符串)的切片操作
06-数据容器str(字符串)-字符串的下标索引/字符串无法修改/查找字符串下标初始值/字符串的替换/字符串的分割/字符串去除前后空格/统计字符串的数量/字符串的循环遍历/对字符串进行分割
编写自己的Flask扩展:扩展框架的无限可能