简介
当您在阿里云容器服务中使用GPU ECS主机构建Kubernetes集群进行AI训练时,经常需要知道每个Pod使用的GPU的使用情况,比如每块显存使用情况、GPU利用率,GPU卡温度等监控信息,本文介绍如何快速在阿里云上构建基于Prometheus + Grafana的GPU监控方案。
Prometheus
Prometheus 是一个开源的服务监控系统和时间序列数据库。从 2012 年开始编写代码,再到 2015 年 github 上开源以来,已经吸引了 20k+ 关注,2016 年 Prometheus 成为继 k8s 后,第二名 CNCF(Cloud Native Computing Foundation) 成员。2018年8月 于CNCF毕业。
作为新一代开源解决方案,很多理念与 Google SRE 运维之道不谋而合。

操作
前提
您已经通过阿里云容器服务创建了拥有GPU ECS的Kubernetes集群,并部署prometheus监控,具体步骤请参考:
部署Prometheus 的GPU 采集器
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: monitoring
name: ack-prometheus-gpu-exporter
spec:
selector:
matchLabels:
k8s-app: ack-prometheus-gpu-exporter
template:
metadata:
labels:
k8s-app: ack-prometheus-gpu-exporter
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: aliyun.accelerator/nvidia_name
operator: Exists
hostPID: true
containers:
- name: node-gpu-exporter
image: registry.cn-hangzhou.aliyuncs.com/acs/gpu-prometheus-exporter:0.1-5cc5f27
imagePullPolicy: Always
ports:
- name: http-metrics
containerPort: 9445
env:
- name: MY_NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
resources:
requests:
memory: 50Mi
cpu: 200m
limits:
memory: 100Mi
cpu: 300m
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock
volumes:
- hostPath:
path: /var/run/docker.sock
type: File
name: docker-sock
---
apiVersion: v1
kind: Service
metadata:
name: node-gpu-exporter
namespace: monitoring
labels:
k8s-app: ack-prometheus-gpu-exporter
spec:
type: ClusterIP
ports:
- name: http-metrics
port: 9445
protocol: TCP
selector:
k8s-app: ack-prometheus-gpu-exporter
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: ack-prometheus-gpu-exporter
labels:
release: ack-prometheus-operator
app: ack-prometheus-gpu-exporter
namespace: monitoring
spec:
selector:
matchLabels:
k8s-app: ack-prometheus-gpu-exporter
namespaceSelector:
matchNames:
- monitoring
endpoints:
- port: http-metrics
interval: 30s
配置Grafana
访问Grafana监控面板
执行以下命令,将集群中的Grafana映射到本地3000端口。
kubectl -n monitoring port-forward svc/ack-prometheus-operator-grafana 3000:80
在浏览器中访问localhost:3000,即可访问Grafana。 默认账号密码为 admin/admin
导入GPU监控配置
- 下载文件并解压,得到两个json文件:
GPU 监控 Grafana配置 - 进入Grafana页面,点击Import dashboard:

- 第一步下载的json文件上传,选择数据源为Prometheus

导入完成后查看结果确认监控正常。
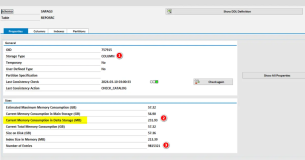
查看监控信息
节点GPU监控

Pod GPU监控

部署应用
如果您已经使用了Arena Arena - 打开KubeFlow的正确姿势) ,可以直接使用arena提交一个训练任务。
arena submit tf --name=style-transfer \
--gpus=1 \
--workers=1 \
--workerImage=registry.cn-hangzhou.aliyuncs.com/tensorflow-samples/neural-style:gpu \
--workingDir=/neural-style \
--ps=1 \
--psImage=registry.cn-hangzhou.aliyuncs.com/tensorflow-samples/style-transfer:ps \
"python neural_style.py --styles /neural-style/examples/1-style.jpg --iterations 1000000"
NAME: style-transfer
LAST DEPLOYED: Thu Sep 20 14:34:55 2018
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1alpha2/TFJob
NAME AGE
style-transfer-tfjob 0s提交任务成功后在监控页面里可以看到Pod的GPU相关指标, 能够看到我们通过Arena部署的Pod,以及pod里GPU 的资源消耗

节点维度也可以看到对应的GPU卡和节点的负载, 在GPU节点监控页面可以选择对应的节点和GPU卡