(第一次写博客,好激动的说.......)
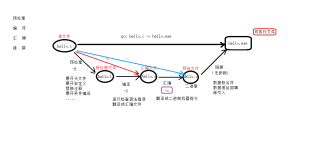
我们知道,一个程序由源代码到可执行文件往往由这几步构成:
预处理(Prepressing)-> 编译(Compilation)-> 汇编(Assembly)-> 链接(Linking)。
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生产相应的汇编代码文件,这个过程往往是我们所说的整个程序构建的核心部分。那么,这个核心部分究竟做了什么呢。
各位看官容我挽起袖子,且听我娓娓道来。
编译器做了什么?
从最直观的角度来说,编译器就是将高级语言翻译成机器语言的一个工具。
以 C语言为例,解释一下 ***.c -> ***.o 的过程。 假设test.c有下面一段代码
array[index] = (index + 4) * (2 + 6);
下面就来谈谈这个表达式是如何翻译成机器语言的过程。
这个过程主要有如下五步,看起来好长的样子,看官需静下心来慢慢看。。。。
1.词法分析 -- 将源代码字符序列分割成一系列的记号
源代码程序被输入到扫描器(Scanner)。
扫描器的任务就是:运用一种有限状态机(Finite State Machine)的算法,将源代码字符序列分割成一系列的记号(Token)。还有一些其他工作(将标识符放到符号表,将数字、字符串放到文字表中)
如下图(因为表格换页了,所以拍出来是这个样子,望海涵)


词法分析产生的记号可以分为如下几类:关键字、标识符、字面量(包括数字、字符串等)和特殊符号(+ - * /)。
需要注意的是:C语言的宏替换和文件包含等工作一般不是编译器做的,而是交给一个独立的预处理器。
有一个叫做lex的程序可以实现词法扫描。
2.语法分析 -- 产生语法树(以表达式为节点的树)
语法分析器(Grammar Parser)将对上面产生的记号进行语法分析,产生语法树(Syntax Tree)-- 采用的是上下文无关语法的分析手段。
简单的说,语法分析器生成的语法树就是以表达式(Expression)为节点的树。
如图
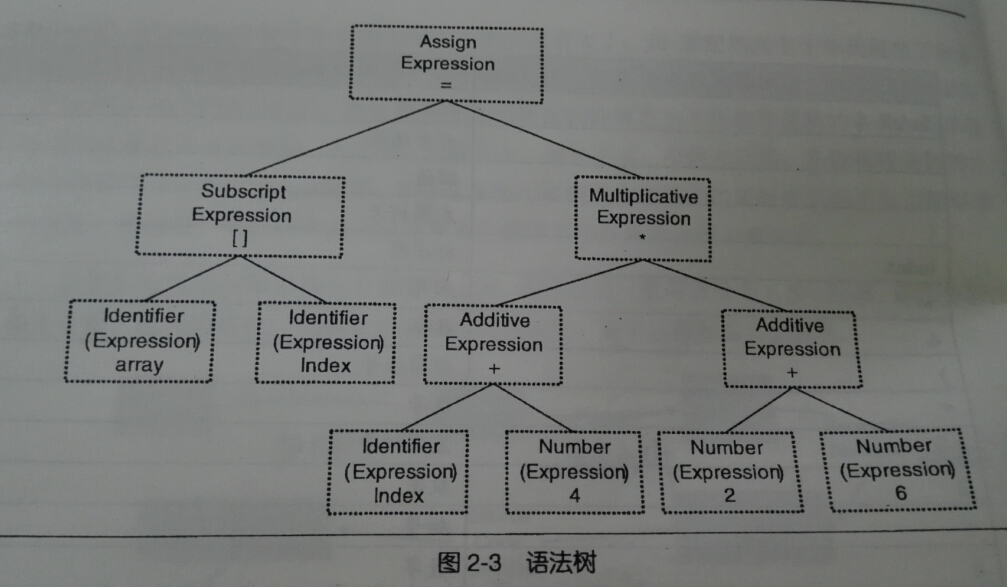
语法分析阶段必须对好多东西(符号的含义和优先级)进行区分,若出现了不合法(如括号不匹配,表达式缺少操作符等),编译器就会报告语法分析阶段的错误。
仅仅是完成了对表达式语法层面的分析,并不了解这个语句是否真正有意义。
语法分析也有一个现成的工具叫yacc(Yet Another Compiler Compiler)。
3.语义分析 -- 将语法树中节点标明含义
接下来就是,由语义分析器(Semantic Analyzer)来完成。
任务就是:为语法树的表达式标识类型。就是下面这个样子,多了类型
如图
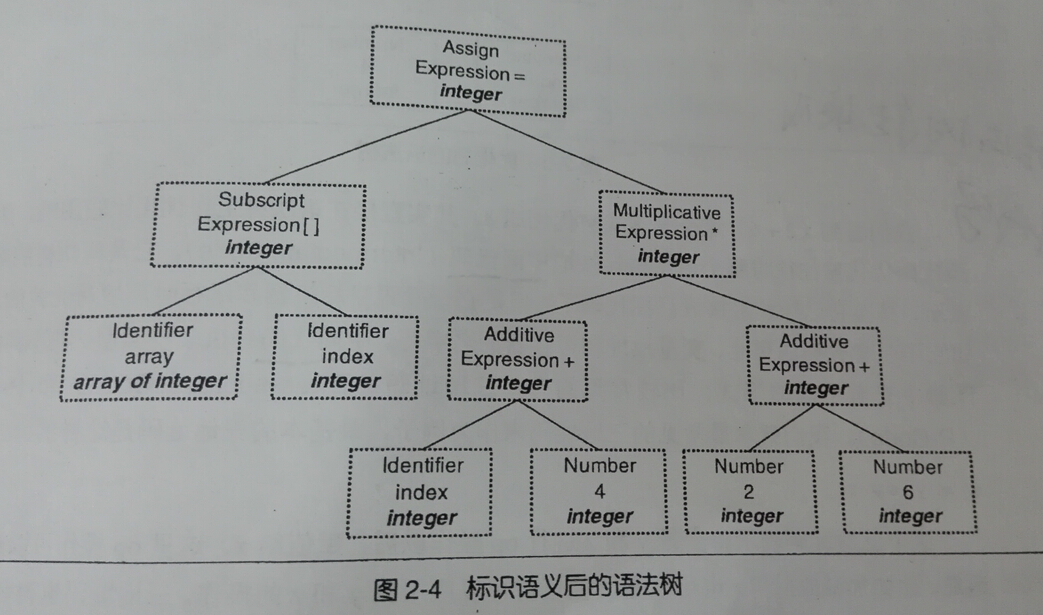
符号和数字是最小的表达式。
编译器所能分析的语义是静态语义。(动态语义不能被分析)
静态语义:在编译阶段可以确定的语义,通常包括声明和类型的匹配,类型的转换。
动态语义:在运行期才能确定的语义,比如将0作为除数是一个运行期语义错误。
4.中间语言生成 -- 一个优化过程
现代的编译器有着很多层次的优化,这里介绍的是一个源码级优化器(Source Code Optimizer),会在源码级别进行优化。比如例子中的(2 + 6),因为在编译阶段可以确定为8,所以这个表达式被优化掉了。
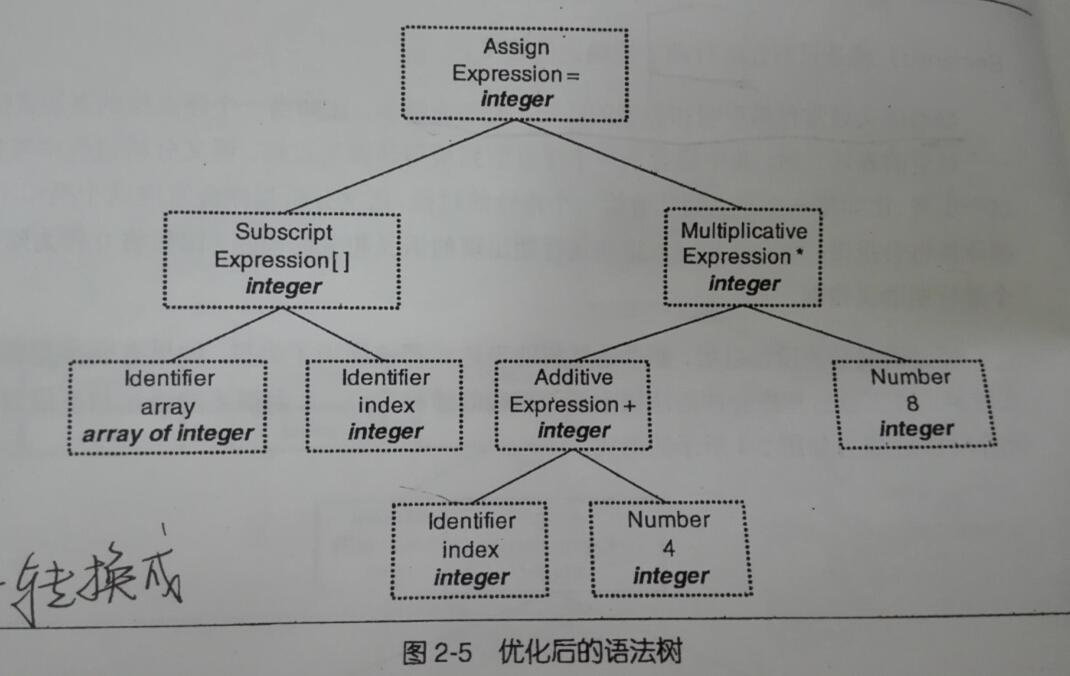
因为直接在语法树上做优化是比较困难的,所以源代码优化器往往将整个语法树转换成中间代码(Intermediate Code),就是语法树的顺序表示(已经非常接近目标代码了)。
中间代码有很多类型,在不同的编译器有着不同的表现形式,常见的有:三地址码(Three-address Code)、P代码(p-Code)。
中间代码使得编译器可以分成前端和后端。
前端:负责产生机器无关的中间代码
后端:将中间代码转换成目标代码
5.目标代码生成与优化(这里开始就是后端了,前面都是前端)
编译器后端主要包括:代码生成器(Code Generator)和目标代码优化器(Target Code Optimizer)。
代码生成器:将中间代码转换成目标机器代码。这个过程非常依赖于机器,因为不同的机器有不同的字长,寄存器,整数数据类型和浮点数数据类型等。
对于我们的例子,可能会生成下面的代码序列(用x86的汇编来表示),如图
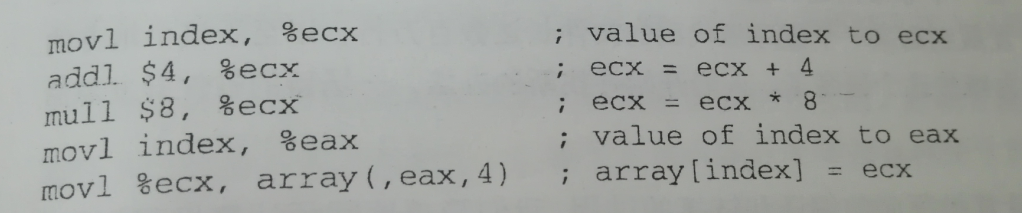
目标代码优化器:对上述的目标代码进行优化。比如:选择合适的寻址方式,使用位移来代替乘法运算,删除多余的指令等。
对于我们的例子,有可能会优化成这个样子。
如图。

------ 我是分割线 ------
好了,忙活了这么久,源代码终于变成了目标代码。
这时候问题来了,index和array的地址还没有确定。若用把目标代码用汇编器编译成真正能在机器上执行的指令,这两个地址从何而来呢。
若index和array定义在跟上面的源代码同一个编译单元里,那么编译器可以为它们分配空间,确定它们的地址。
若定义在其他模块呢?说来就话长了。。。。。。
附在那本书的一些话:(助于理解)
(1).现代的编译器可以将一个源代码文件编译成一个未链接的目标文件,然后由链接器最终将这些目标文件链接起来形成可执行文件。
(2).汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。
(3).所以汇编器的汇编过程相对于编译器来讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译就可以了。
(4).经过预编译、编译和汇编直接输出目标文件(Object File)。
参考文献《程序员的自我修养--链接、装载与库》 P41-P48 (其实就是摘抄整理了一下,哈哈)