回归模型
1 基本知识介绍
1.1回归模型的引入
由于客观事物内部规律的复杂性及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型。所以在遇到有些无法用机理分析建立数学模型的时候,通常采取搜集大量数据的办法,基于对数据的统计分析去建立模型,其中用途最为广泛的一类随即模型就是统计回归模型。
回归模型确定的变量之间是相关关系,在大量的观察下,会表现出一定的规律性,可以借助函数关系式来表达,这种函数就称为回归函数或回归方程。
1.2回归模型的分类

2 用回归模型解题的步骤
回归模型解题步骤主要包括两部分:
一:确定回归模型属于那种基本类型,然后通过计算得到回归方程的表达式;
①根据试验数据画出散点图;
②确定经验公式的函数类型;
③通过最小二乘法得到正规方程组;
④求解方程组,得到回归方程的表达式。
二:是对回归模型进行显著性检验;
①相关系数检验,检验线性相关程度的大小;
②F检验法(这两种检验方法可以任意选);
③残差分析;
④对于多元回归分析还要进行因素的主次排序;
如果检验结果表示此模型的显著性很差,那么应当另选回归模型了。
3模型的转化
非线性的回归模型可以通过线性变换转变为线性的方程来进行求解:例如
函数关系式:可以通过线性变换:转化为一元线性方程组来求解,对于多元的也可以进行类似的转换。
4举例
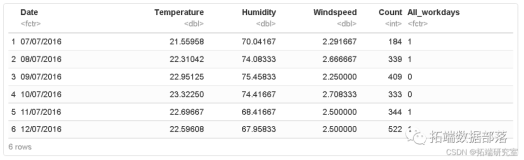
例1(多元线性回归模型):已知某湖八年来湖水中COD浓度实测值(y)与影响因素湖区工业产值(x1)、总人口数(x2)、捕鱼量(x3)、降水量(x4)资料,建立污染物y的水质分析模型。
(1)输入数据
x1=[1.376, 1.375, 1.387, 1.401, 1.412, 1.428, 1.445, 1.477] x2=[0.450, 0.475, 0.485, 0.500, 0.535, 0.545, 0.550, 0.575] x3=[2.170 ,2.554, 2.676, 2.713, 2.823, 3.088, 3.122, 3.262] x4=[0.8922, 1.1610 ,0.5346, 0.9589, 1.0239, 1.0499, 1.1065, 1.1387] y=[5.19, 5.30, 5.60,5.82,6.00, 6.06,6.45, 6.95]
(2)保存数据(以数据文件.mat形式保存,便于以后调用)
save data x1 x2 x3 x4 y
load data (取出数据)
(3)执行回归命令
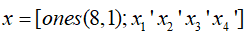
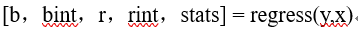
得结果:
b = (-16.5283,15.7206,2.0327,-0.2106,-0.1991)’
stats = (0.9908,80.9530,0.0022)
即:
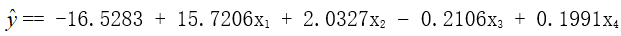
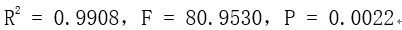
通过查表可知,R2代表决定系数(R代表相关系数),它的值很接近与1,说明此方程是高度线性相关的;
F检验值为80.9530远大于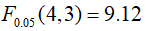 ,可见,检验结果是显著的。
,可见,检验结果是显著的。
例2(非线性回归模型)非线性回归模型可由命令nlinfit来实现,调用格式为:
[beta,r,j] = nlinfit(x,y,'model’,beta0)
其中,输人数据x,y分别为n×m矩阵和n维列向量,对一元非线性回归,x为n维列向量model是事先用 m-文件定义的非线性函数,beta0是回归系数的初值, beta是估计出的回归系数,r是残差,j是Jacobian矩阵,它们是估计预测误差需要的数据。
预测和预测误差估计用命令
[y,delta] = nlpredci(’model’,x,beta,r,j)
如:对实例1中COD浓度实测值(y),建立时序预测模型,这里选用logistic模型。即
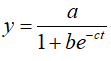
(1)对所要拟合的非线性模型建立的m-文件mode1.m如下:
function yhat=model(beta,t)
yhat=beta(1)./(1+beta(2)*exp(-beta(3)*t))
(2)输入数据
t=1:8
load data y(在data.mat中取出数据y)
beta0=[50,10,1]’
(3)求回归系数
[beta,r,j]=nlinfit(t’,y’,’model’,beta0)
得结果:
beta=(56.1157,10.4006,0.0445)’
即
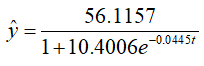
(4)预测及作图
[yy,delta] = nlprodei(’model’,t’,beta,r,j);
plot(t,y,’k+’,t,yy,’r’)
3.逐步回归
逐步回归的命令是stepwise,它提供了一个交互式画面,通过此工具可以自由地选择变量,进行统计分析。调用格式为:
stepwise(x,y,inmodel,alpha)
其中x是自变量数据,y是因变量数据,分别为n×m和n×l矩阵,inmodel是矩阵的列数指标(缺省时为全部自变量),alpha,为显著性水平(缺省时为0.5)
结果产生三个图形窗口,在stepwise plot窗口,虚线表示该变量的拟合系数与0无显著差异,实线表示有显著差异,红色线表示从模型中移去的变量;绿色线表明存在模型中的变量,点击一条会改变其状态。在stepwise Table窗口中列出一个统计表,包括回归系数及其置信区间,以及模型的统计量剩余标准差(RMSE),相关系数 (R-square),F值和P值。
例3、主成份分析
主成份分析主要求解特征值和特征向量,使用命令 eig(),调用格式为
[V,D] = eig(R)
其中R为X的相关系数矩阵,D为R的特征值矩阵,V为特征向量矩阵
实例3:对实例1中变量进行主成份成析
(1)调用数据
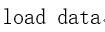
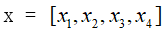
(2)计算相关系数矩阵
R = corrcoef(x)
(3)求特征根、特征向量
[V,D] = eig(R)
得结果:
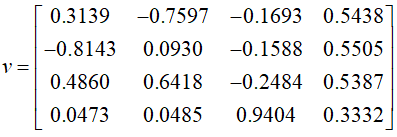

按特征根由大到小写出各主成份
第一主成份
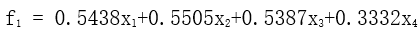
方差贡献率为3.1863/4 = 79.66%
第二主成份
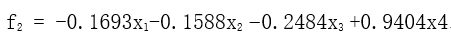
方差贡献率为0.7606/4 = 19.12%
第三主成份
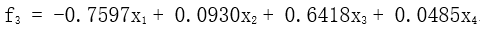
方差贡献率为0.0601/4=1.5%
您可以考虑给博主来个小小的打赏以资鼓励,您的肯定将是我最大的动力。thx.
微信打赏

支付宝打赏

作 者: Angel_Kitty
出 处:http://www.cnblogs.com/ECJTUACM-873284962/
关于作者:潜心机器学习以及信息安全的综合研究。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击右下角【推荐】推荐一下该博文。您的鼓励是作者坚持原创和持续写作的最大动力!