本文演示如何在E-MapReduce上部署Storm集群和Kafka集群,并运行Storm作业消费Kafka数据。
环境准备
本文选择在杭州Region进行测试,版本选择EMR-3.8.0,本次测试需要的组件版本有:
- Kafka:2.11_1.0.0
- Storm: 1.0.1
本文使用阿里云EMR服务自动化搭建Kafka集群,详细过程请参考创建集群。
- 创建Hadoop集群
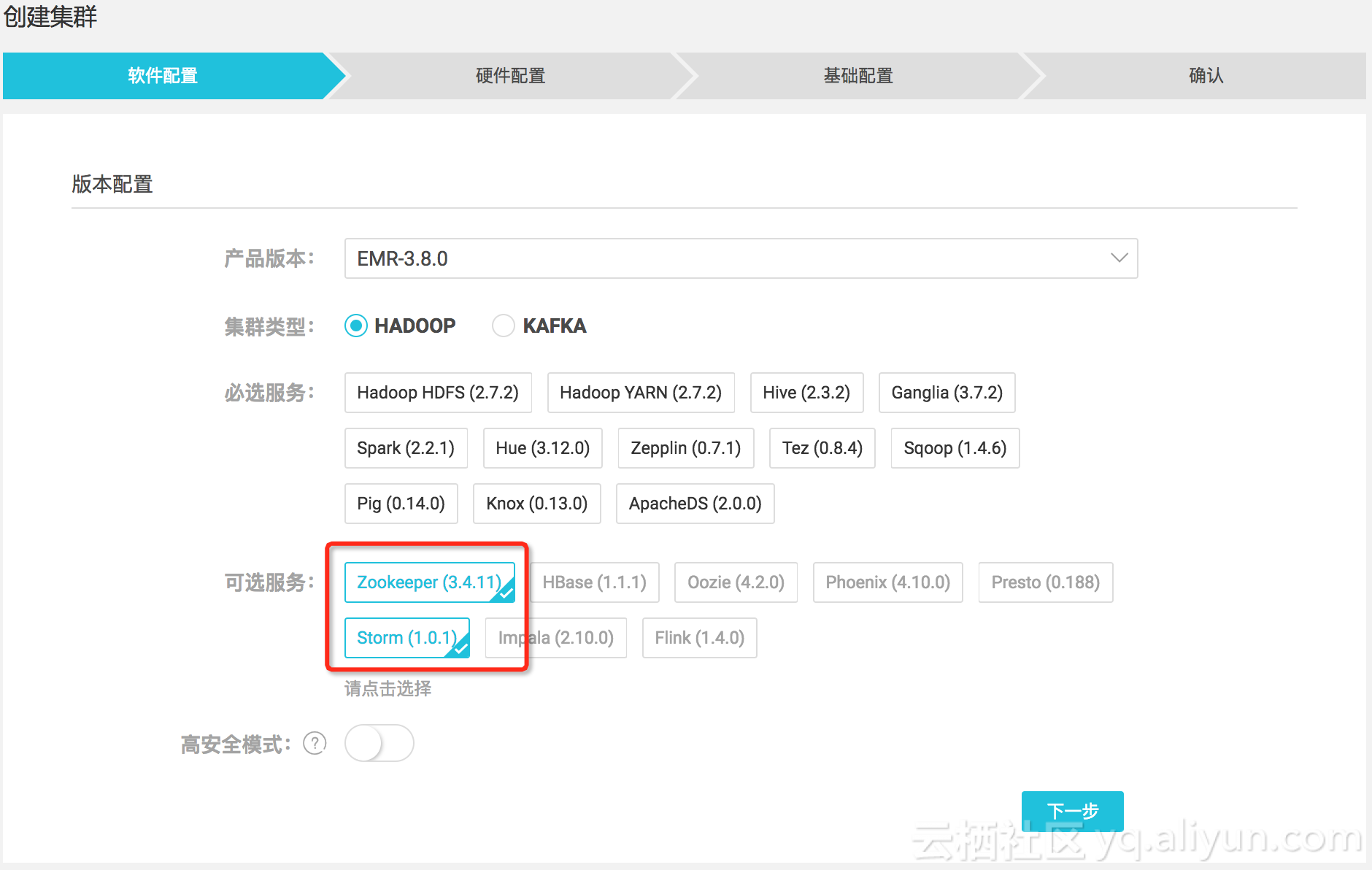
-
创建Kafka集群
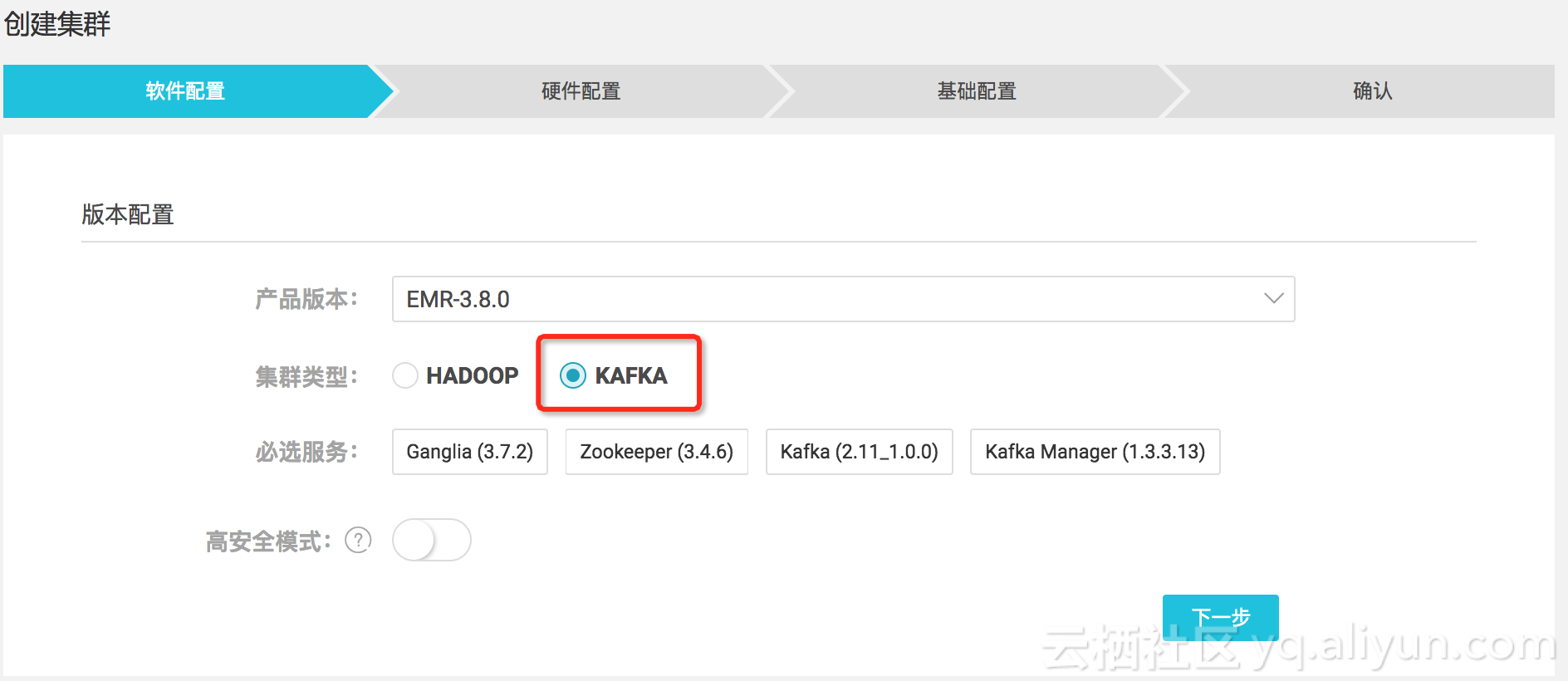
说明- 如果使用经典网络,请注意将Hadoop集群和Kafka集群放置在同一个安全组下面,这样可以省去配置安全组,避免网络不通的问题。
- 如果使用VPC网络,请注意将Hadoop集群和Kafka集群放置在同一个VPC/VSwitch以及安全组下面,这样同样省去配置网路和安全组,避免网络不通。
- 如果你熟悉ECS的网络和安全组,可以按需配置。
-
配置Storm环境
如果我们想在Storm上运行作业消费Kafka的话,集群初始环境下是会失败的,因为Storm运行环境缺少了不少必须的依赖包,如下:
以上版本依赖包经过测试可用,如果你再测试过程中引入了其他依赖,也一同添加在Storm lib中,具体操作如下: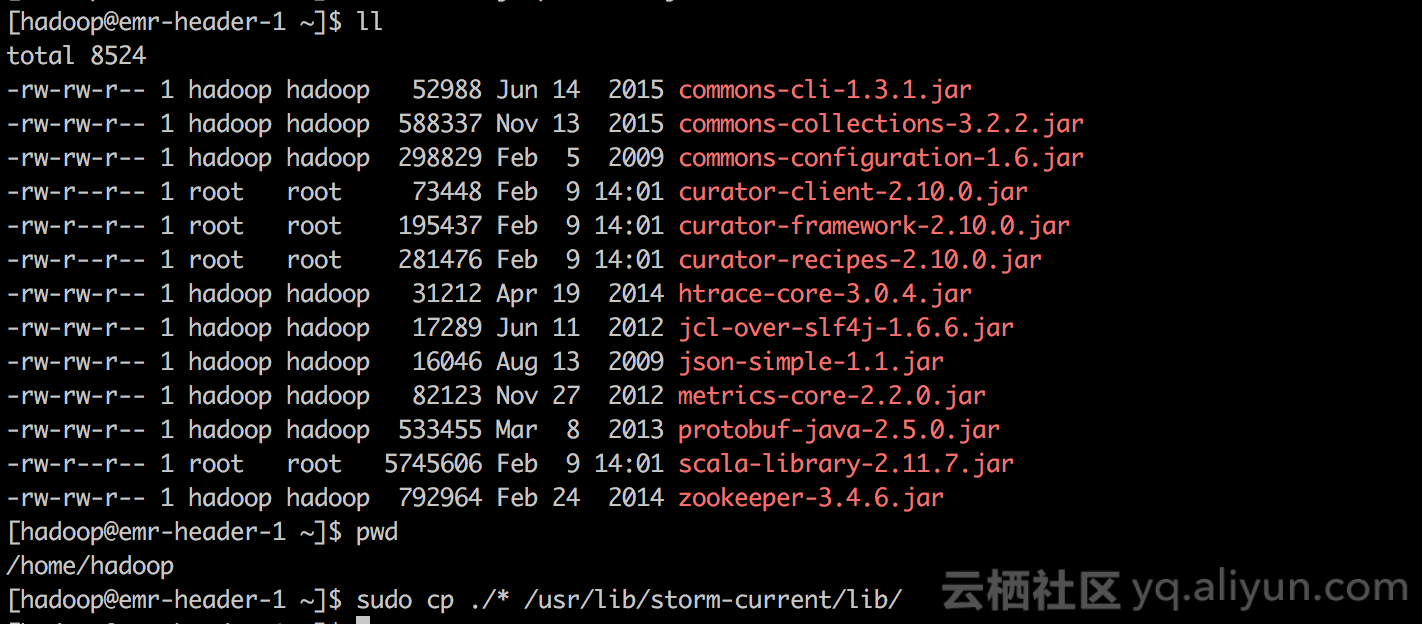
上述操作需要在Kafka集群的每台机器执行一遍。执行完在E-MapReduce控制台重启Storm服务,如下: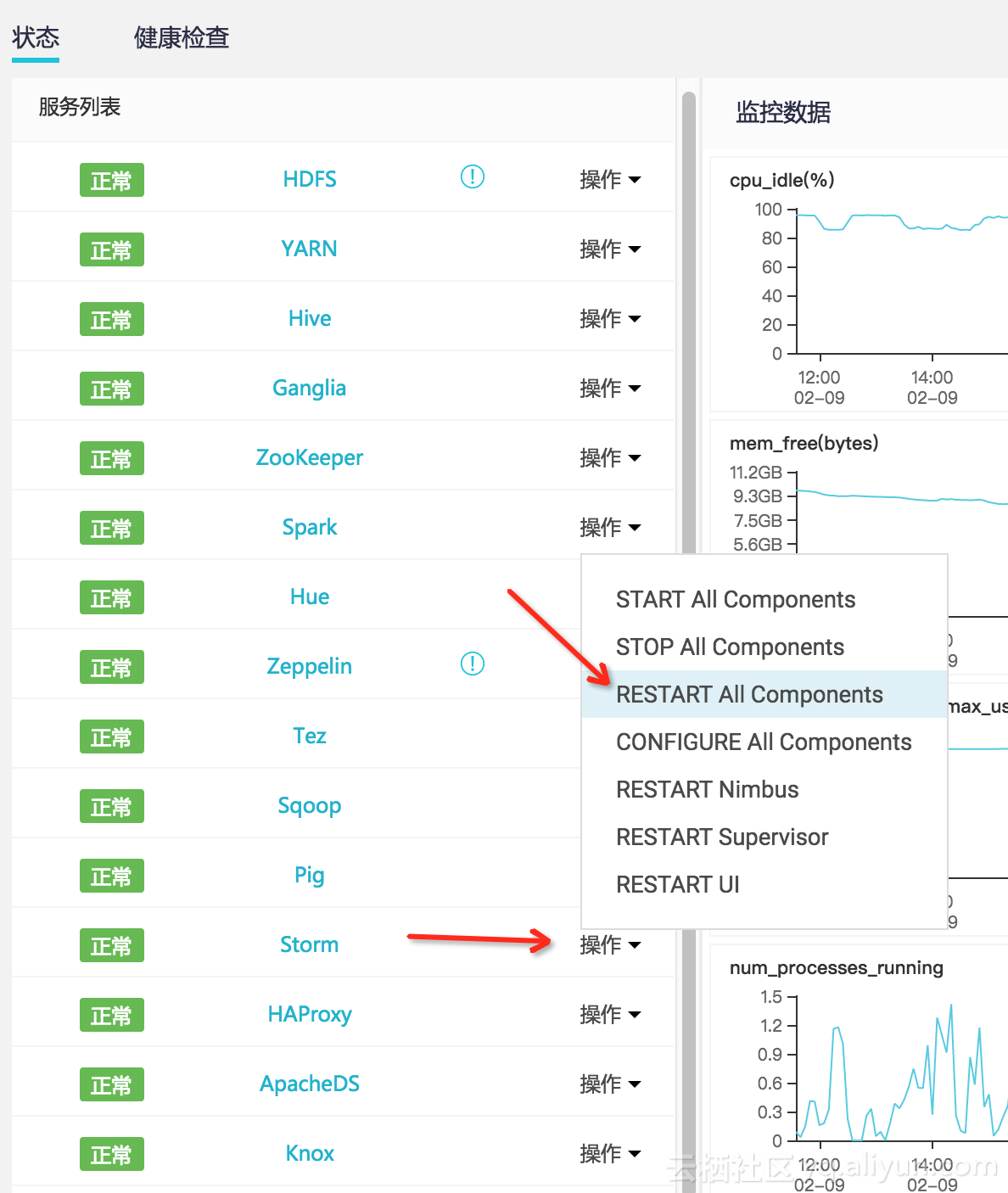
查看操作历史,待Storm重启完毕:
开发Storm和Kafka作业
E-MapReduce已经提供了现成的示例代码,直接使用即可,地址如下:
e-mapreduce-demo
e-mapreduce-sdk
Topic数据准备
登录到Kafka集群
创建一个test topic,分区数10,副本数2
/usr/lib/kafka-current/bin/kafka-topics.sh --partitions 10 --replication-factor 2 --zookeeper emr-header-1:/kafka-1.0.0 --topic test --create向test topic写入100条数据
/usr/lib/kafka-current/bin/kafka-producer-perf-test.sh --num-records 100 --throughput 10000 --record-size 1024 --producer-props bootstrap.servers=emr-worker-1:9092 --topic test说明 以上命令在kafka集群的emr-header-1节点执行,当然也可以客户端机器上执行。
运行Storm作业
登录到Hadoop集群,将第二步中编译得到的
examples-1.1-shaded.jar拷贝到集群emr-header-1上,这里我放在root根目录下面。提交作业:
/usr/lib/storm-current/bin/storm jar examples-1.1-shaded.jar com.aliyun.emr.example.storm.StormKafkaSample test aaa.bbb.ccc.ddd hdfs://emr-header-1:9000 sample- 查看Storm运行状态
查看集群上服务的WebUI有2种方式:本文选择使用SSH隧道方式,访问地址:
http://localhost:9999/index.html 。可以看到我们刚刚提交的Topology。点进去可以看到执行详情: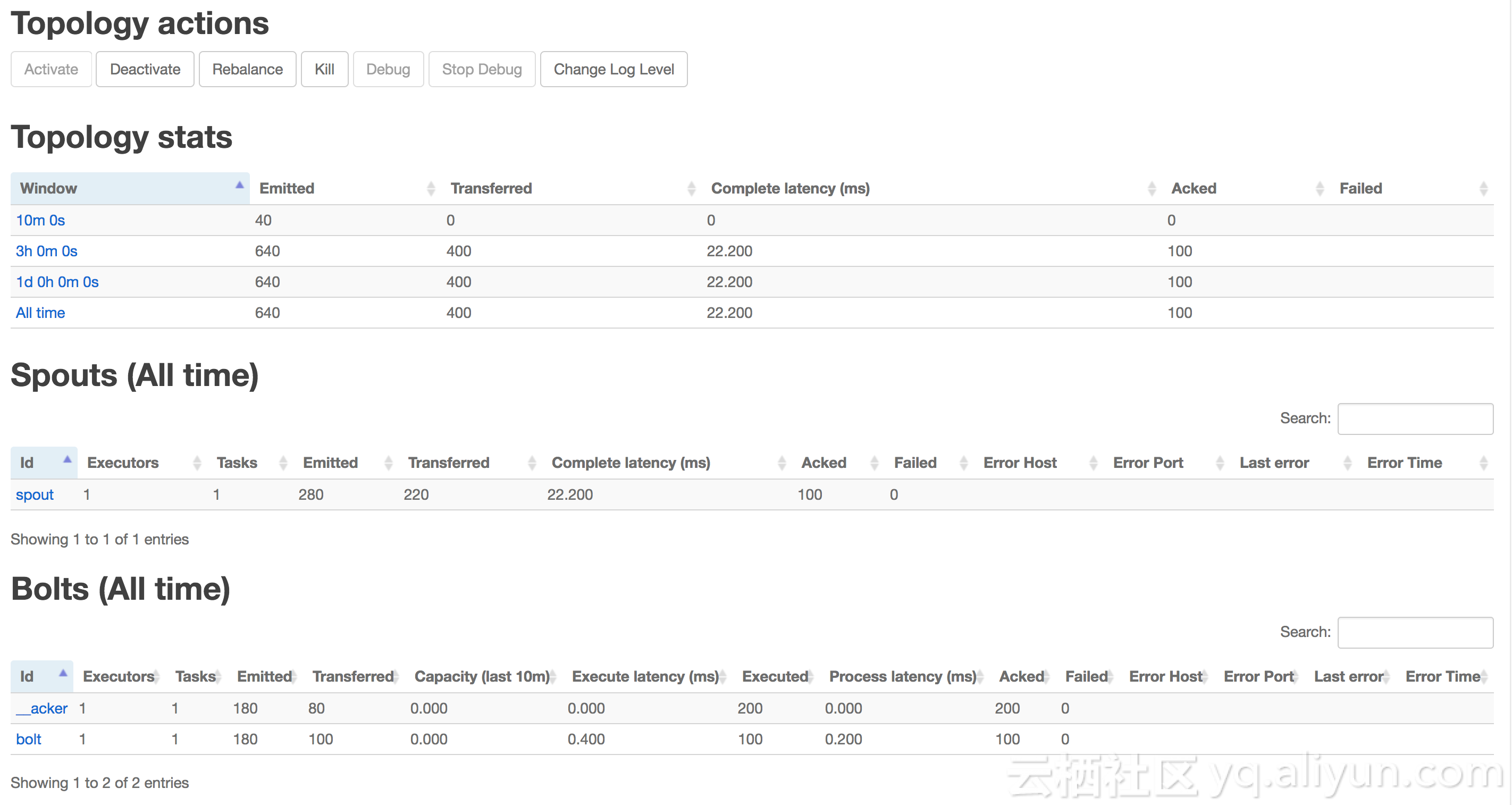
- 查看HDFS输出
- 查看HDFS文件输出
[root@emr-header-1 ~]# hadoop fs -ls /foo/ -rw-r--r-- 3 root hadoop 615000 2018-02-11 13:37 /foo/bolt-2-0-1518327393692.txt -rw-r--r-- 3 root hadoop 205000 2018-02-11 13:37 /foo/bolt-2-0-1518327441777.txt [root@emr-header-1 ~]# hadoop fs -cat /foo/bolt-2-0-1518327441777.txt | wc -l 200向kafka写120条数
[root@emr-header-1 ~]# /usr/lib/kafka-current/bin/kafka-producer-perf-test.sh --num-records 120 --throughput 10000 --record-size 1024 --producer-props bootstrap.servers=emr-worker-1:9092 --topic test 120 records sent, 816.326531 records/sec (0.80 MB/sec), 35.37 ms avg latency, 134.00 ms max latency, 35 ms 50th, 39 ms 95th, 41 ms 99th, 134 ms 99.9th查看HDFS文件输出
[root@emr-header-1 ~]# hadoop fs -cat /foo/bolt-2-0-1518327441777.txt | wc -l 320总结
至此,我们成功实现了在E-MapReduce上部署一套Storm集群和一套Kafka集群,并运行Storm作业消费Kafka数据。当然,E-MapReduce也支持Spark Streaming和Flink组件,同样可以方便在Hadoop集群上运行,处理Kafka数据。
说明
由于E-MapReduce没有单独的Storm集群类别,所以我们是创建的Hadoop集群,并安装了Storm组件。如果你在使用过程中用不到其他组件,可以很方便地在E-MapReduce管理控制台将那些组件停掉。这样,可以将Hadoop集群作为一个纯粹的Storm集群使用。
(本文作者为阿里云大数据产品文档工程师)




