前言
为什么MySQL InnoDB需要Purge操作?明确这个问题的答案,首先还得从InnoDB的并发机制开始。为了更好的支持并发,InnoDB的多版本一致性读是采用了基于回滚段的的方式。另外,对于更新和删除操作,InnoDB并不是真正的删除原来的记录,而是设置记录的delete mark为1。因此为了解决数据Page和Undo Log膨胀的问题,需要引入purge机制进行回收。下面我们来描述下purge整个过程。(代码分析基于MySQL 5.7)
Purge数据产生的背景
- Undo log和Undo history list
- Mark deleted数据
Undo log
Undo log保存了记录修改前的镜像。在InnoDB存储引擎中,undo log分为:
- insert undo log
- update undo log
insert undo log是指在insert操作中产生的undo log。由于insert操作的记录,只是对本事务可见,其他事务不可见,所以undo log可以在事务提交后直接删除,而不需要purge操作。
update undo log是指在delete和update操作中产生的undo log。该undo log会被后续用于MVCC当中,因此不能提交的时候删除。提交后会放入undo log的链表,等待purge线程进行最后的删除。
下面列出了undo log类型,后续在purge工作线程的时候会针对性的讲述不同的处理方式:
- 从表中删除一行记录
TRX_UNDO_DEL_MARK_REC (将主键记入日志),在删除一条记录时,并不是真正的将数据从数据库中删除,只是标记为已删除。 - 向表中插入一行记录
TRX_UNDO_INSERT_REC (仅将主键记入日志)
TRX_UNDO_UPD_DEL_REC (将主键记入日志) 当表中有一条被标记为删除的记录和要插入的数据主键相同时, 实际的操作是更新这个被标记为删除的记录。 - 更新表中的一条记录
TRX_UNDO_UPD_EXIST_REC (将主键和被更新了的字段内容记入日志)
TRX_UNDO_DEL_MARK_REC和TRX_UNDO_INSERT_REC,当更新主键字段时,实际执行的过程是删除旧的记录然后,再插入一条新的记录。
Undo history list
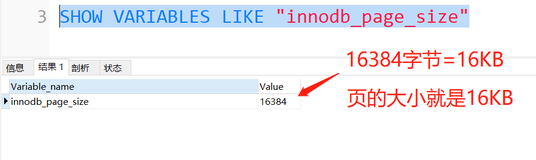
事务提交后,对于有update_undo的事务,首先会调用trx_serialisation_number_get函数生成一个当前最大的事务号,并且把该事务加到全局trx_serial_list链表中。接下来会根据该事务所在的回滚段信息
last_page_no == FIL_NULL,来决定是否讲该回滚段加入到purge_sys->ib_bh全局队列当中。其次,会调用trx_undo_update_cleanup->trx_purge_add_update_undo_to_history函数,将undo log加入到history list上,同时记录这个回滚段上第一个需要purge的undo log信息,防止rseg再次被添加到purge队列中,然后唤醒purge线程。
/* Add the log as the first in the history list */
flst_add_first(rseg_header + TRX_RSEG_HISTORY,
undo_header + TRX_UNDO_HISTORY_NODE, mtr);
......
if (rseg->last_page_no == FIL_NULL) {
rseg->last_page_no = undo->hdr_page_no;
rseg->last_offset = undo->hdr_offset;
rseg->last_trx_no = trx->no;
rseg->last_del_marks = undo->del_marks;
}注意insert_undo并不会放到History list上。
Mark deleted数据
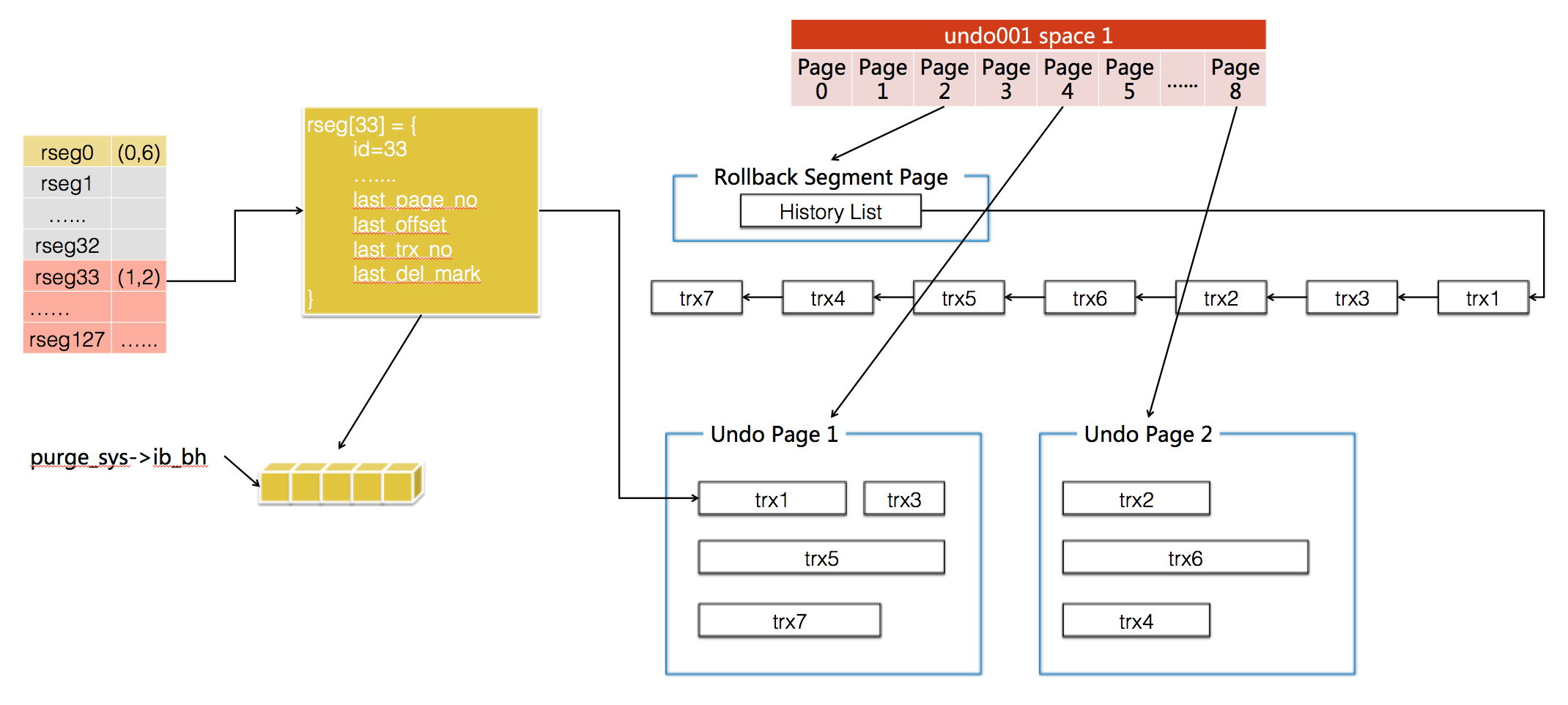
Mark deleted的数据可能会是由于一次delete操作或者一次update操作,InnoDB会调用btr_rec_set_deleted_flag->rec_set_deleted_flag_old/rec_set_deleted_flag_new设置record的delete标志位。
那么可以标记为mark delete的数据都有哪些类型呢?包括主键记录、二级索引记录:
btr_cur_del_mark_set_clust_rec
btr_cur_del_mark_set_sec_rec
更新主键索引的情况
ha_innobase::update_row -> row_update_for_mysql -> row_upd_step -> row_upd -> row_upd_clust_step -> row_upd_clust_rec_by_insert -> btr_cur_del_mark_set_clust_rec -> row_ins_index_entry
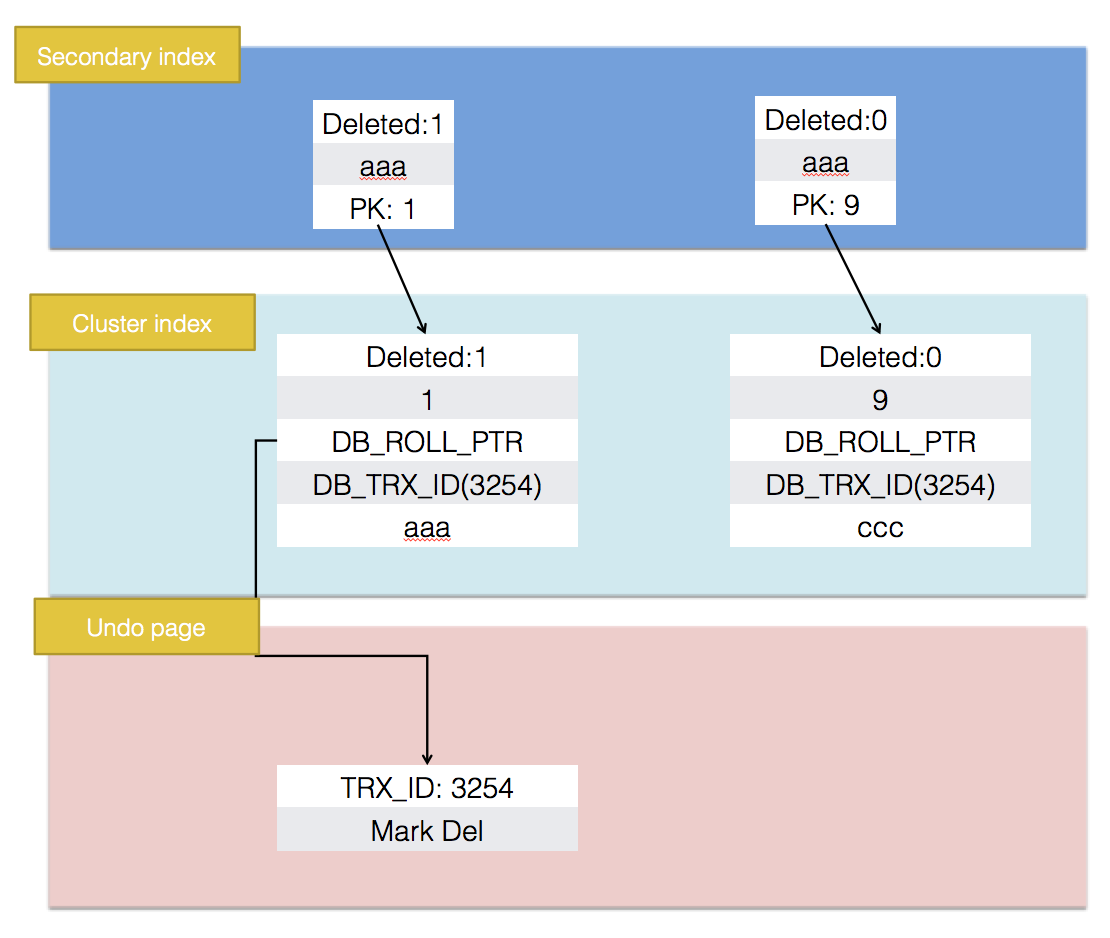
更新非主键值,但是影响二级索引的情况
ha_innobase::update_row -> row_update_for_mysql -> row_upd_step -> row_upd -> row_upd_sec_step -> row_upd_sec_index_entry -> btr_cur_del_mark_set_sec_rec -> row_ins_sec_index_entry
Purge操作流程
- 创建srv_purge_coordinator_thread协调线程和srv_worker_thread工作线程
- 启动purge流程
- 初始化purge
- purge工作线程流程
- 清理回滚段undo数据
创建srv_purge_coordinator_thread协调线程和srv_worker_thread工作线程
/* Create the master thread which does purge and other utility
operations */
if (!srv_read_only_mode) {
os_thread_create(
srv_master_thread,
NULL, thread_ids + (1 + SRV_MAX_N_IO_THREADS));
}
if (!(srv_read_only_mode)
&& srv_force_recovery < SRV_FORCE_NO_BACKGROUND) {
os_thread_create(
srv_purge_coordinator_thread,
NULL, thread_ids + 5 + SRV_MAX_N_IO_THREADS);
ut_a(UT_ARR_SIZE(thread_ids)
> 5 + srv_n_purge_threads + SRV_MAX_N_IO_THREADS);
/* We've already created the purge coordinator thread above. */
for (i = 1; i < srv_n_purge_threads; ++i) {
os_thread_create(
srv_worker_thread, NULL,
thread_ids + 5 + i + SRV_MAX_N_IO_THREADS);
}
srv_start_wait_for_purge_to_start();
} else {
purge_sys->state = PURGE_STATE_DISABLED;
}启动purge流程
purge的主要任务是将数据库中已经mark del的数据删除,另外也会批量回收undo pages。数据库的数据页很多,要清除被删除的数据,不可能遍历所有的数据页。由于所有的变更都有undo log, 因此,从undo作为切入点,在清理过期的undo的同时,也将数据页中的被删除的记录一并清除。 整个purge操作的入口函数是srv_do_purge->trx_purge。
-
初始化Purge的记录:
Purge操作会克隆最老旧的read_view:purge_sys->view->open_purge(),这个purge view包括了重要的两个信息:
m_low_limit_no:trx_sys->trx_serial_list最小的提交事务号no,不是事务id。
m_up_limit_id:当前最老read_view中,最小的活跃事务id。
然后,开始获取那些可以被purge掉的undo records(trx_purge_attach_undo_recs->trx_purge_fetch_next_rec),然后转化为purge_rec, 轮流放在purge thread的上下文purge_node_t *node->undo_recs中。
那么从什么位置开始purge还需要关心purge_sys的两个变量:
purge_iter_t iter; /* Limit up to which we have read and
parsed the UNDO log records. Not
necessarily purged from the indexes.
Note that this can never be less than
the limit below, we check for this
invariant in trx0purge.cc */
purge_iter_t limit; /* The 'purge pointer' which advances
during a purge, and which is used in
history list truncation */
下面看看如何获取更新这两个变量:
首先,先需要确定purge_sys->iter是不能大于purge_sys->limit的,原因是由于purge->limit是用来truncate对应的undo log并且更新history list,而iter用于找到对应del的data record进行purge,我们一定要保证purge del的data后才能purge对应的undo log。
/* Track the max {trx_id, undo_no} for truncating the
UNDO logs once we have purged the records. */
if (purge_sys->iter.trx_no > limit->trx_no
|| (purge_sys->iter.trx_no == limit->trx_no
&& purge_sys->iter.undo_no >= limit->undo_no)) {
*limit = purge_sys->iter;
}其次,需要根据purge_sys->next_stored判断是否当前purge系统中有保存的purge record,如果没有就要通过purge queue中保存的需要purge的回滚段rseg来进行purge record的生成,详细见函数trx_purge_choose_next_log。在函数trx_purge_get_rseg_with_min_trx_id会更新purge_sys->iter.trx_no成为purge rseg的last_trx_no,也就是指定回滚段上最早提交的事务号。
最后,通过调用trx_purge_get_next_rec找到真正需要purge的undo log,并且更新purge_sys->iter。如果该rseg指向的last_page_no的page上并没有其他可以需要purge的mark del的undo log,那会继续调用trx_purge_rseg_get_next_history_log来获取下一个history list下的undo page。
在获取undo log的过程中,还有一个重要的判断:
if (purge_sys->iter.trx_no >= purge_sys->view->low_limit_no()) {
return(NULL);
}这意味着,如果purge_sys->iter的trx_no已经大于等于最老读事务的事务提交号,就放弃该undo log的purge过程,只处理目前已经可以purge的undo log。
目前purge一次处理的undo log为默认300个,可通过参数innodb_purge_batch_size参数调整。
-
Purge工作线程流程:
Purge工作线程启动,是借助于MySQL中的查询计划图(que0que.cc)来调度的,也就是借助了MySQL Innodb的执行Process Model。简单可以通过代码中的注释理解:
举例说明
X := 1;
WHILE X < 5 LOOP
X := X + 1;
X := X + 1;
X := 5
将会生成下面的架构,x轴代表下一个执行关系,Y轴代表父子关系
A - W - A
|
|
A - A
A = assign_node_t, W = while_node_t.
启动并行purge的代码流程如下:
que_run_threads->que_run_threads_low-> que_thr_step-> row_purge_step-> row_purge
每个work thread需要处理的流程如下:
row_purge->row_purge_record
case TRX_UNDO_DEL_MARK_REC:
->row_purge_del_mark->row_purge_remove_sec_if_poss
->row_purge_remove_clust_if_poss
case TRX_UNDO_UPD_EXIST_REC:
->row_purge_upd_exist_or_extern->row_purge_remove_clust_if_poss
可以看出work thread要只需要处理两种情况,一种是由于删除或者更新导致的mark delete的数据能够删除老版本,包括可能的二级索引和一级索引,另一种是处理由于更新非mark delete的数据导致的可能的二级索引老版本。
另外还需要介绍两个函数row_purge_parse_undo_rec,也就是从undo log里解析出行引用信息和其他信息,返回值为true表明需要执行purge操作。通过函数trx_undo_rec_get_pars获得undo记录的类型,主要包括以下几个类型:
#define TRX_UNDO_INSERT_REC 11 /* fresh insert into clustered index */
#define TRX_UNDO_UPD_EXIST_REC \
12 /* update of a non-delete-marked \
record */
#define TRX_UNDO_UPD_DEL_REC \
13 /* update of a delete marked record to \
a not delete marked record; also the \
fields of the record can change */
#define TRX_UNDO_DEL_MARK_REC \
14 /* delete marking of a record; fields \
do not change */
#define TRX_UNDO_CMPL_INFO_MULT \
16 /* compilation info is multiplied by \
this and ORed to the type above */
#define TRX_UNDO_MODIFY_BLOB \
64 /* If this bit is set in type_cmpl, \
then the undo log record has support \
for partial update of BLOBs. Also to \
make the undo log format extensible, \
introducing a new flag next to the \
type_cmpl flag. */
#define TRX_UNDO_UPD_EXTERN \
128 /* This bit can be ORed to type_cmpl \
to denote that we updated external \
storage fields: used by purge to \
free the external storage */通过trx_undo_update_rec_get_sys_cols函数获取对应的table_id,trx_id,和roll_ptr。另外,为了防止所有对表的DROP操作,还会对dict_operation_lock加S全局锁。
-
Purge一级索引(row_purge_remove_clust_if_poss):
Purge一级索引首先会尝试乐观删除,即直接删除leaf
row_purge_remove_clust_if_poss_low(BTR_MODIFY_LEAF)->btr_cur_optimistic_delete
失败后,会不断尝试(最多100次)悲观删除,即修改tree本身
row_purge_remove_clust_if_poss_low(BTR_MODIFY_TREE)->btr_cur_pessimistic_delete
-
Purge二级索引(row_purge_remove_sec_if_poss):
二级索引purge时,同样先乐观删除(row_purge_remove_sec_if_poss_leaf),失败再进行悲观删除(row_purge_remove_sec_if_poss_tree)。不同的是,需要通过row_purge_poss_sec判断该二级索引记录是否可以被Purge,当该二级索引记录对应的聚集索引记录没有delete mark并且其trx id比当前的purge view还旧时,不可以做Purge操作。
参考资料
- MySQL · 引擎特性 · InnoDB undo log 漫游
- InnoDB Rollback Segment & Undo Page Deallocation实现源码分析
- InnoDB多版本(MVCC)实现简要分析