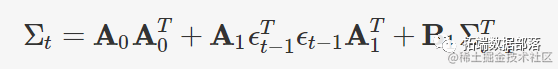热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
【软件工程】融通未来的工艺:深度解析统一过程在软件开发中的角色
IBM SPSS Modeler分类决策树C5.0模型分析空气污染物数据
【软件工程】走进瀑布模型:传统软件开发的经典之路
数据分享|R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据(下)
【软件工程】走近演化过程模型:软件开发的不断进化之路
【Mybatis】深入学习MyBatis:概述、主要特性以及配置与映射
【MySQL】数据库规范化的三大法则 — 一探范式设计原则
r语言中对LASSO回归,Ridge岭回归和弹性网络Elastic Net模型实现(下)
【MySQL】数据库中为什么使用B+树不用B树
【MySQL】SQL优化
使用R语言进行时间序列(arima,指数平滑)分析(下)
【MySQL】脏读、不可重复读、幻读介绍及代码解释
【MySQL】多表连接查询
R语言缺失数据变量选择LASSO回归:Bootstrap重(再)抽样插补和推算
【MySQL】数据库索引(简单明了)
电子好书发您分享《从零开始玩转AIGC》
电子好书发您分享《2023龙蜥操作系统大会全面推进运维智能化分论坛》
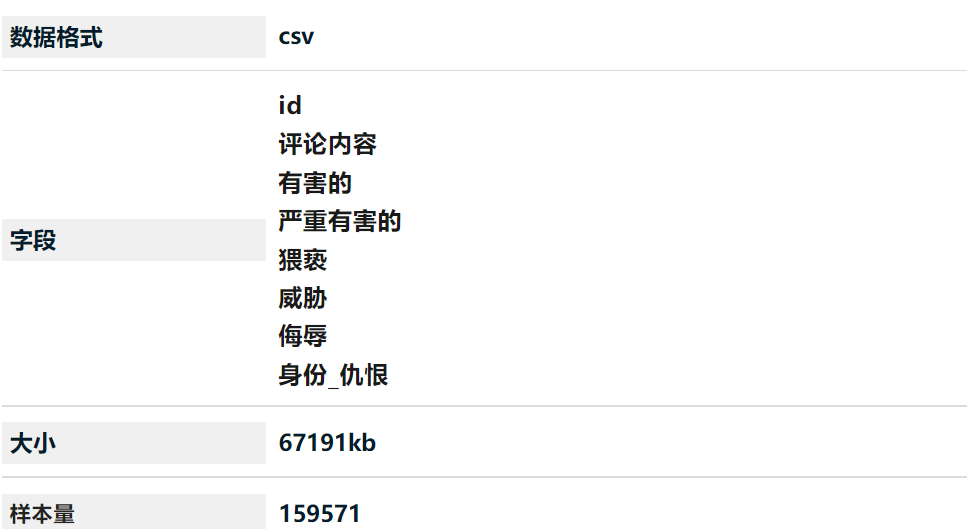
【数据分享】维基百科Wiki负面有害评论(网络暴力)文本数据多标签分类挖掘可视化
SpringCloud和Dubbo有哪些区别
电子好书发您分享《阿里云产品手册2024版》
【JAVA面试题】static的作用是什么?详细介绍
【JAVA面试题】final关键字的作用有哪些
数据分享|R语言逐步回归、方差分析anova电影市场调查问卷数据可视化
【JAVA面试题】什么是引用传递?什么是值传递?
【JAVA面试题】什么是对象锁?什么是类锁?
Julia 语言环境安装
【JAVA面试题】什么是代码单元?什么是码点?
【JAVA面试题】基本类型的强制类型转换是否会丢失精度?引用类型的强制类型转换需要注意什么?
【JAVA面试题】什么是深拷贝?什么是浅拷贝?
【Linux笔记】文件查看和编辑
【Linux笔记】文件和目录操作
【Linux笔记】系统信息
AI百模大战:引领行业变革与开启人才黄金时代
【Linux笔记】网络操作命令详细介绍
R语言多元(多变量)GARCH :GO-GARCH、BEKK、DCC-GARCH和CCC-GARCH模型和可视化
【Linux笔记】用户和权限管理基本命令介绍
CCNA 200-301系列:思科命令行界面(CLI) 简介用户模式和特权模式
创世纪:AIGC引领人工智能时代的崭新篇章
CCNA 200-301系列:DNS简介
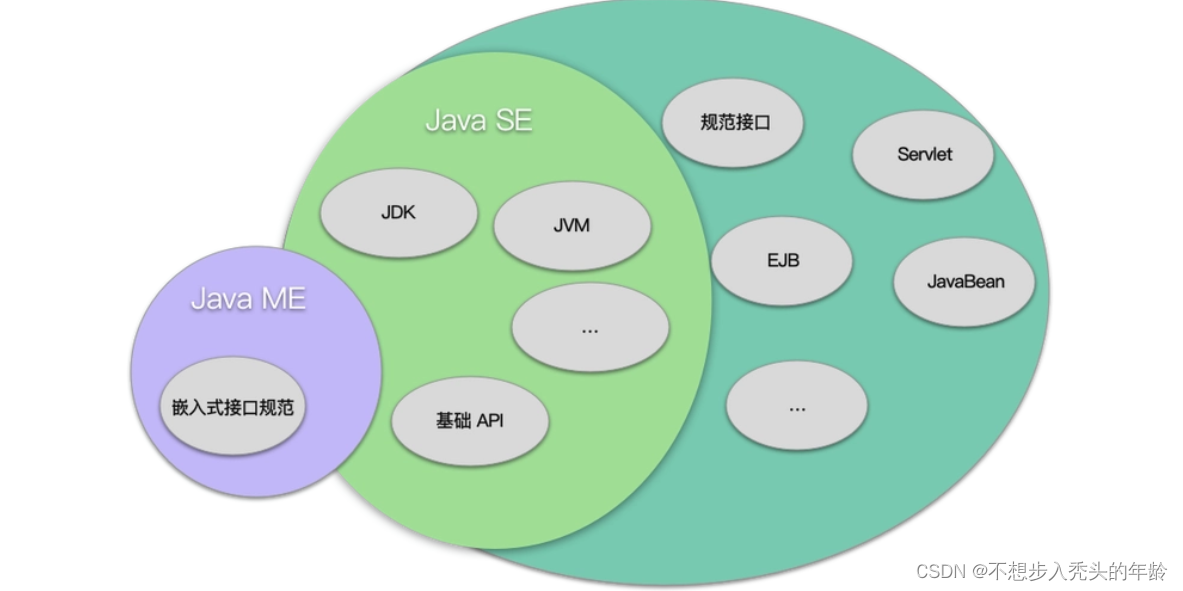
JAVA的三大版本
CCNA 200-301系列:ICMP简介
力扣---最长回文子串(动态规划)
CCNA 200-301系列:TCP 窗口
命名之美:探索Java的标识符与命名规范
CCNA 200-301系列:TCP头
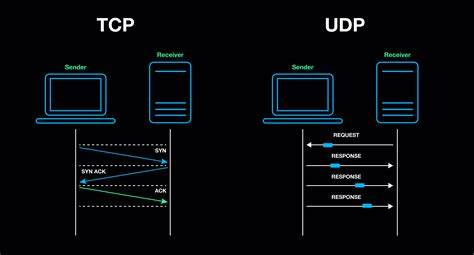
CCNA 200-301系列:TCP和UDP简介