////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
hadoop 自学系列
hadoop hive hbase 入门学习 (一) hadoop安装、hdfs学习及mapreduce学习
hadoop 软件下载 (hadoop-1.2.1.tar.gz) 点击下载
hadoop hive hbase 入门学习 (二) hbase 安装、hbase语句学习
hbase 软件下载 (hbase-0.94.26.tar.gz) 点击下载
hadoop hive hbase 入门学习 (三) hive安装、及hive语句学习
hive软件下载 (hive-0.9.0.tar.gz)点击下载
mysql 客户端软件下载 (MySQL-client-5.5.23-1.linux2.6.i386.rpm)点击下载
mysql 服务端软件下载 (MySQL-server-5.5.23-1.linux2.6.i386.rpm)点击下载
mysql connector软件下载 (mysql-connector-java-5.1.16-bin.jar)点击下载
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
1.hadoop的伪分布安装步骤
1.1 先安装VMWare/VirtualBox,打开镜像文件,使用root用户登录。
1.2 设置静态ip地址
在windows上设置的VMNet1的ip是192.168.80.1
在linux上设置的ip是192.168.80.100,掩码是255.255.255.0,网关是192.168.80.1
设置ip后,执行命令service network restart重启虚拟网卡设置
验证:ifconfig
1.3 设置主机名
(1)执行命令hostname hadoop0 该操作只对当前会话有效
(2)编辑文件vi /etc/sysconfig/network 修改为hadoop0
验证:重启linux,查看是否生效
reboot -h now(重启)
1.4 把ip和hostname绑定
编辑文件vi /etc/hosts 增加一行记录 192.168.80.100 hadoop0
验证:ping hadoop0
1.5 关闭防火墙
执行命令service iptables stop
验证:service iptables status
1.6 关闭防护墙的自动运行
执行命令chkconfig iptables off
验证:chkconfig --list | grep iptables
1.7 使用SSH(Secure Shell)进行免密码登陆
(1)执行命令ssh-keygen -t rsa 产生秘钥,秘钥文件位于~/.ssh
(2)执行命令 cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys 把公钥放到文件authorized_keys.
(3)执行命令ssh-copy-id -i ~/.ssh/authorized_keys Master
验证:ssh hadoop0
1.8 安装oracle的jdk
(1)复制jdk到/usr/local目录,然后转到该目录 cd /usr/local
(2)执行命令 chmod u+x jdk-6u24-linux-i586.bin 赋予执行权限
(3)解压缩./jdk-6u24-linux-i586.bin
(4)重命名 mv jdk-1.6.0_24 jdk
(5)编辑文件vi /etc/profile 设置环境变量
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
保持退出
(6)source /etc/profile
验证:java -version
1.9 安装hadoop
(1)复制jdk到/usr/local目录,然后转到该目录
(2)执行命令 tar -zxvf hadoop-1.1.2.tar.gz 进行解压缩
(3)重命名 mv hadoop-1.1.2 hadoop
(4)编辑文件 vi /etc/profile 设置环境变量
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
保持退出
(5)source /etc/profile
(6)修改4个配置文件
<1>修改hadoop-env.sh,内容如下
export JAVA_HOME=/usr/local/jdk/
<2>修改core-site.xml,内容如下
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
<description>change your own hostname</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
<3>修改hdfs-site.xml,内容如下
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
<4>修改mapred-site.xml,内容如下
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop0:9001</value>
<description>change your own hostname</description>
</property>
</configuration>
(7)格式化文件系统,执行命令hadoop namenode -format
(8)启动,执行命令start-all.sh
验证:<1>执行命令jps,可以看到5个新增的java进程,分别是NameNode、DataNode、SecondaryNameNode、JobTracker、TaskTracker
<2>通过浏览器,访问http://hadoop0:50070和http://hadoop0:50030
注意:格式化操作不能多次执行。删除文件夹/usr/local/hadoop/tmp之后再执行格式化。
注意:可以在windows下配置hosts文件,位于C:\Windows\System32\drivers\etc路径下的。
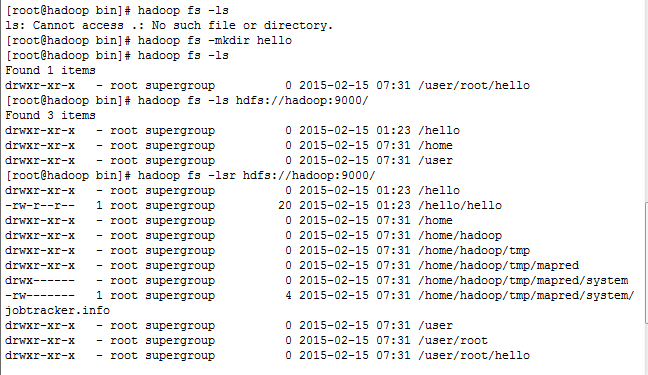
2.hadoop fs Shell操作(格式hadoop fs -XXXX)
2.1 查看列表
hadoop fs -ls hdfs://hadoop0:9000/ 查看hadoop0上的hdfs的根目录
hadoop fs -lsr hdfs://hadoop0:9000/ 递归查看hadoop0上的hdfs的根目录
hadoop fs -ls / 查看hadoop0上的hdfs的根目录
hadoop fs -ls 查看hadoop0上的hdfs的/user/<user>目录
2.2 hadoop fs -mkdir <path> 创建文件夹
2.3 hadoop fs -rmr <path> 删除文件夹
2.4 hadoop fs -put <linux src> <hdfs des> 上传文件
2.5 hadoop fs -get <hdfs src> <linux des> 下载文件
2.6 hadoop fs -rm <path> 删除文件
页面查看:
http://192.168.32.128:50075/browseDirectory.jsp?namenodeInfoPort=50070&dir=/
3.RPC(remote procedure call)
3.1 指的是2个java进程之间的调用。进一步讲,是一个java进程(client)调用另一个java进程(server)的对象中的方法。
3.2 RPC是hadoop体系构建的基础,各个进程之间(如NameNode与DataNode之间、DataNode之间、JobTracker与TaskTracker之间)的通信是通过RPC实现的。
4.通过例子获得认识
4.1 RPC指的是2个java进程之间的调用
4.2 client调用server中的对象的方法,要求对象implements VersionedProtocol,要求对象具有接口,对象中的方法位于接口中。
4.3 client拿到的是接口。
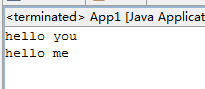
public interface MyBizable extends VersionedProtocol{
public abstract String hello(String name);
}
public class MyBiz implements MyBizable{
public static final String SERVER_ADDRESS = "localhost";
public static final int SERVER_PORT = 1234;
public static long VERSION = 1112332323L;
public MyBiz(){
try{
/**
* 构造一个 RPC服务端.
* @param instance 实例中的方法会被客户端调用
* @param bindAddress 绑定的地址用来监听连接的到来
* @param port 绑定的端口用来监听连接的到来
* @param conf the configuration to use
*/
final Server server = RPC.getServer(this, SERVER_ADDRESS, SERVER_PORT, new Configuration());
server.start();
}catch (Exception e) {
e.printStackTrace();
}
}
/* (non-Javadoc)
* @see rpc.MyBizable#hello(java.lang.String)
*/
@Override
public String hello(String name){
System.out.println("我被调用了");
return "hello "+name;
}
@Override
public long getProtocolVersion(String arg0, long arg1) throws IOException {
return MyBiz.VERSION;
}
public static void main(String[] args) throws Exception{
final MyBiz myBiz = new MyBiz();
}
}
public class MyClient {
public static void main(String[] args) throws Exception {
/** 构造一个实现了命名的协议的客户端的代理对象 ,可以和服务端的指定地址通信*/
MyBizable proxy = (MyBizable)RPC.waitForProxy(MyBizable.class,
MyBiz.VERSION,
new InetSocketAddress(MyBiz.SERVER_ADDRESS, MyBiz.SERVER_PORT),
new Configuration()
);
final String result = proxy.hello("world");
System.out.println(result);
RPC.stopProxy(proxy);
}
}
5.分析用户代码如何与NameNode通信
5.1 以App2中的上传代码为例;
5.2 App2中通过调用fileSystem.create(...)获得的FsDataOutputStream对象,
来自于DistributedFileSystem的create(...),见P188.
public static final String PATH = "hdfs://192.168.60.128:9000/hello/hello";
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); final URL url = new URL(PATH); final InputStream in = url.openStream(); IOUtils.copyBytes(in, System.out, 1024, true);
createDir
if(!fileSystem.exists(new Path(DIR1))){
fileSystem.mkdirs(new Path(DIR1));
}
deleteDir
if(fileSystem.exists(new Path(DIR1))){
fileSystem.delete(new Path(DIR1), true);
}
getData
final FSDataInputStream in = fileSystem.open(new Path(F1)); IOUtils.copyBytes(in, System.out, 1024, true);
putdata
final FSDataOutputStream out = fileSystem.create(new Path(F1));
final FileInputStream in = new FileInputStream("C:/Windows/System32/drivers/etc/hosts");
IOUtils.copyBytes(in, out, 1024, true);
liststatus
final FileSystem fileSystem = FileSystem.get(new URI(PATH), new Configuration());
final FileStatus[] listStatus = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
String isDir = fileStatus.isDir()?"d":"-";
final String permission = fileStatus.getPermission().toString();
final short replication = fileStatus.getReplication();
final String owner = fileStatus.getOwner();
final String group = fileStatus.getGroup();
final long len = fileStatus.getLen();
final long modificationTime = fileStatus.getModificationTime();
final String path = fileStatus.getPath().toString();
System.out.println(isDir+permission+"\t"+replication+"\t"+owner+"\t"+group+"\t"+len+"\t"+modificationTime+"\t"+path);
}

connection exception: java.net.ConnectException: Connection refused: no further information
捐助开发者
在兴趣的驱动下,写一个免费的东西,有欣喜,也还有汗水,希望你喜欢我的作品,同时也能支持一下。 当然,有钱捧个钱场(右上角的爱心标志,支持支付宝和PayPal捐助),没钱捧个人场,谢谢各位。
谢谢您的赞助,我会做的更好!




