多维数据的形象表示
import
numpy
as
np
# 一维数据不用赘言
data_1d = np.array([
0
,
1
,
2
,
3
])
# 二维数据作为 m 行 n 列的表格,例如 2 行 3 列
data_2d = np.arange(
6
).reshape(
2
,
3
)
# 三维数据作为 k 层 m 行 n 列 的积木块, 例如 2 层 3 行 4 列
data_3d = np.arange(
24
).reshape(
2
,
3
,
4
)
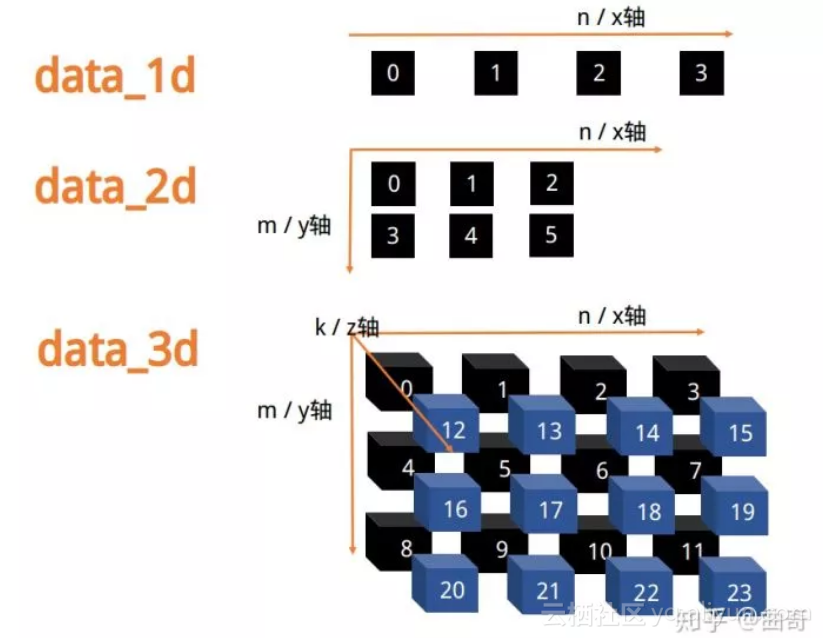
检查一个 ndarray 数据的维度和大小,分别用 ndim 和 shape 属性。
>>>
print
(data_3d.ndim)
3
>>>
print
(data_3d.shape)
(
2
,
3
,
4
)
shape 是一个很关键的属性,我是这样把它和各个轴对应的:
shape: (
2
,
3
,
4
)
k
,
m
,
n
z
,
y
,
x
心法1: x, y, z 对应的shape元组是从右往左数的。
这是我的个人习惯,也符合主流的用法。
图像数据的小误会
打开一幅 640 x 480 的图像:
import
numpy
as
np
import
matplotlib.pylab
as
plt
image = plt.imread(
"lena.jpg"
)
print
(image.shape)
# --- 结果 ---
# (480, 640, 3)
# (y, x, c)
不是 640 x 480 吗, 怎么倒过来了?我写代码的时候在这里总是犯迷糊。
在口头表达中,我们先说宽640,再说高480,而在计算机中是先高(y) 后宽(x),注意了!
每个像素有三个颜色分量(color),所以这个维度放在了最右边,可以理解,顺序就是 (y, x, c)
抽象轴上的操作
对于4维及更高维度的数据,无法在3维空间图示。这个时候,就不要考虑形象思维了,直接按照规则做处理。
用 shape 属性返回的元组,从左到右,座标轴分别命名为 axis 0, axis 1, ...,请注意,现在是从左向右数,正好是这个元组的 index,在以后的运算中,都按此规定。
>>>
print
(data.shape)
(
3
,
3
,
2
,
5
)
# axis 0: 3
# axis 1: 3
# axis 2: 2
# axis 3: 5
心法2: 抽象座标轴顺序从左向右。指定哪个轴,就只在哪个轴向操作,其他轴不受影响。
排序(sorting)
data = np.array(np.arange(
12
))
np.random.shuffle(data)
data = data.reshape(
3
,
4
)
print
(data)
# [[10 8 3 2]
# [ 5 6 0 7]
# [11 4 9 1]]
print
(np.sort(data
,
axis
=
0
))
# [[ 5 4 0 1] | 小
# [10 6 3 2] | 到
# [11 8 9 7]] | 大
print
(np.sort(data
,
axis
=
1
))
# 小 到 大
# --------->
# [[ 2 3 8 10]
# [ 0 5 6 7]
# [ 1 4 9 11]]
如果你在心中能把抽象轴和 x, y, z 对应起来,则理解轴向排序很容易。
shape: (
3
,
4
)
axis:
0
,
1
AXIS: y
,
x
2. 求和、均值、方差、最大、最小、累加、累乘
这几个函数调用,一般会指定轴向,注意心法2
sum,mean,std,var,min,max 会导致这个轴被压扁,缩减为一个数值
data = np.arange(
24
).reshape(
2
,
3
,
4
)
print
(data)
# [[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
#
# [[12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]]
print
( np.sum(data
,
axis
=
0
) )
# 0轴被sum压扁,1轴2轴不变
# [[12 14 16 18]
# [20 22 24 26]
# [28 30 32 34]]
print
( np.sum(data
,
axis
=
1
) )
# 1轴被sum压扁,0轴2轴不变
# [[12 15 18 21]
# [48 51 54 57]]
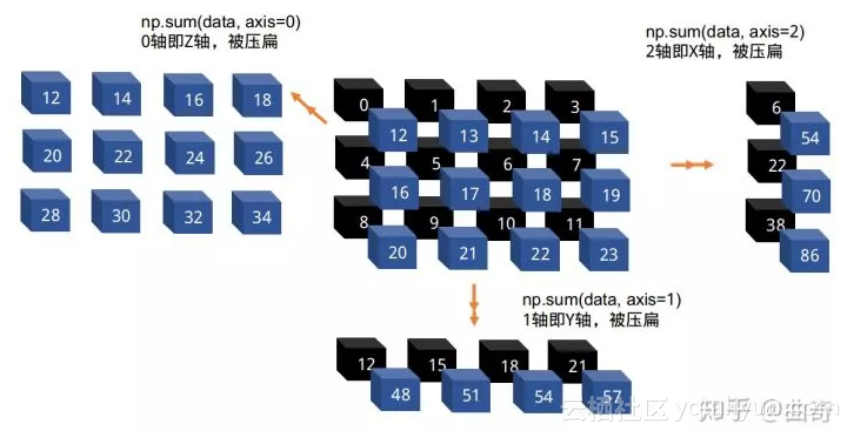
cumsum,cumprod 不缩减轴向,只在指定轴向操作,请读者自己试验。
3. 索引和切片(indexing and slicing)
心法3: 在索引中出现冒号(:),则本轴继续存在,如果只是一个数值,则本轴消失。
例如,像 :, :1, 1: 这样的索引,保留此轴, data[:, :1, 2:] 中,三个轴都保留。 data[1, 4, 2] 三个轴都消失,只返回一个数值。
data[1:2, 0:1, 0:1] 中,三个轴都保留,但只有一个数据元素,很神奇吧。
data = np.arange(
24
).reshape(
2
,
3
,
4
)
print
( data )
# [[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
#
# [[12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]]
print
( data[
0
,
:
,
:] )
# axis 0,即 z 轴,是数值,则 z 轴消失,切了一片 x-y
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print
( data[
0
,
1
,
2
] )
# 所有轴都消失,只返回一个标量数据
# 6
print
( data[
0
:
1
,
1
:
2
,
2
:
3
] )
# 返回三维数据,虽然只有一个元素
# [[[6]]]
如何查看 ndarray 的维度呢?可以访问 shape 属性;如果打印出来了,那么就数一数起始的中括号个数,比如 [[[6]]], 有三个 [,那么就是三维数组。你记住了吗?
4. 拼接(concatenating)
同样遵循心法2,指定哪个轴,就在哪个轴向拼接:
data = np.arange(
4
).reshape(
2
,
2
)
print
( np.concatenate([data
,
data]
,
axis
=
0
) )
# 在轴向 0 拼接,即 y 方向
# [[0 1]
# [2 3]
# [0 1]
# [2 3]]
print
( np.concatenate([data
,
data]
,
axis
=
1
) )
# 在轴向 1 拼接,即 x 方向
# [[0 1 0 1]
# [2 3 2 3]]
reshape 之迷乱
你有没有这个困惑:在 reshape 之后,数据在各个轴上是如何重新分配的?
搞清楚 ndarray 的数据在内存里的存放方式,以及各个维度的访问方式,reshape 困惑就迎刃而解了。
心法4: ndarray 的数据在内存里以一维线性存放,reshape 前后,数据没有变化,只是访问方式变了而已。
数据优先填充 X 轴向,其次 Y 轴,其次 Z 轴 。。。
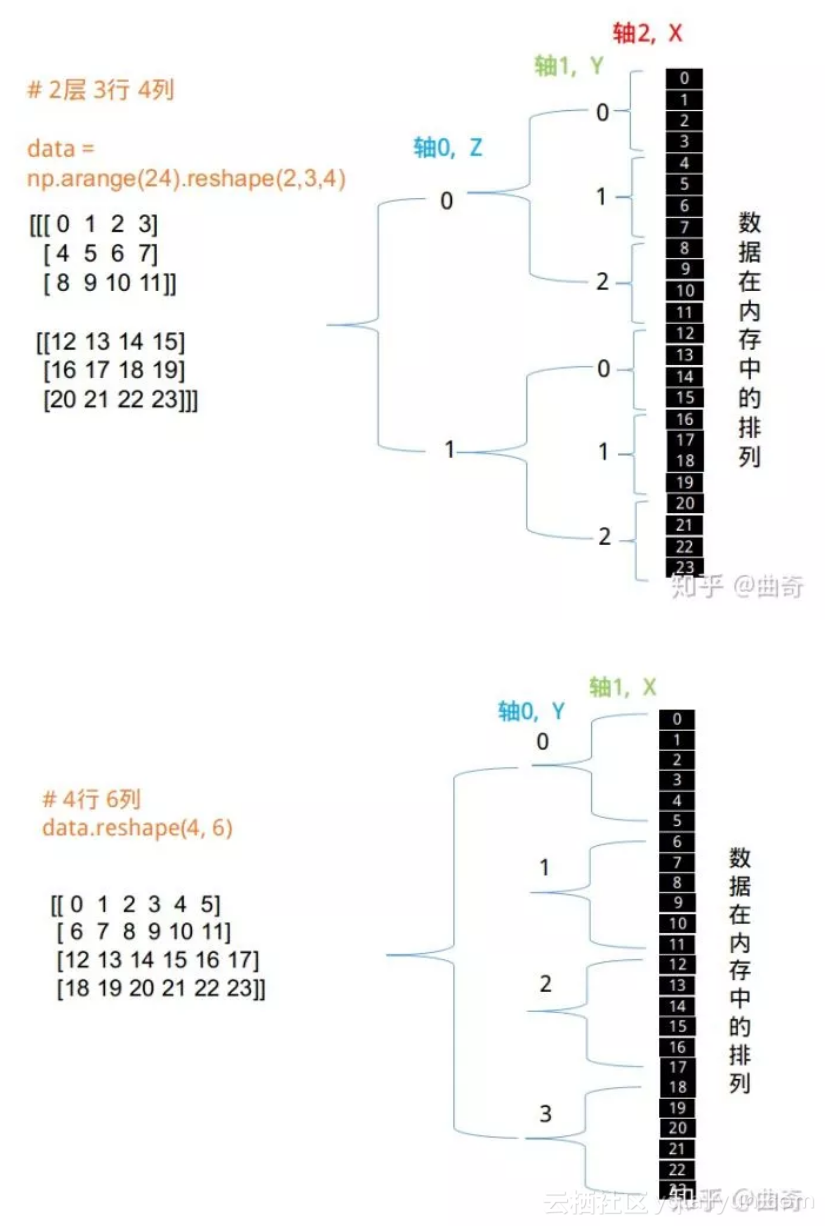
有 C 语言基础的,很容易理解 ndarray 的实现,就是 C 中的多维数组而已。
int
data[
2
][
3
][
4
];
int
data[
4
][
6
];
总结
就说这么多,看了本文请亲自动手写代码体验一下。掌握此心法,可以纵横 numpy 世界而无大碍。
心法1: x, y, z 对应的shape元组是从右往左数的。
心法2: 抽象座标轴顺序从左向右。指定哪个轴,就只在哪个轴向操作,其他轴不受影响。
心法3: 在索引中出现冒号(:),则结果中本轴继续存在,如果只是一个数值,则本轴消失。
心法4: ndarray 的数据在内存里以一维线性存放,reshape 前后,数据没有变化,只是访问方式变了而已。
原文发布时间为:2018-09-20
本文作者:曲奇
本文来自云栖社区合作伙伴“磐创AI”,了解相关信息可以关注“磐创AI”。





