一、GIL介绍
GIL全称 Global Interpreter Lock ,中文解释为全局解释器锁。它并不是Python的特性,而是在实现python的主流Cpython解释器时所引入的一个概念,GIL本质上就是一把互斥锁,将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,从而保证数据的安全性。
注:每次执行python程序,都会产生一个独立的进程,进程里除了能看到的若干线程,还有看不见的解释器开启的垃圾回收等解释器级别的线程。
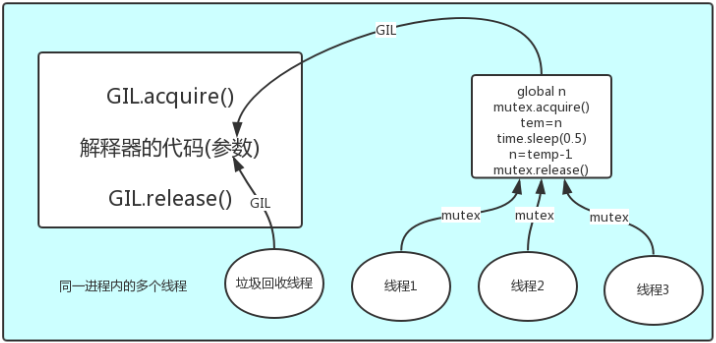
#1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码) 例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启四个线程然后target都指向该代码,能访问到意味着就是可以执行。 #2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
多个线程先访问到解释器的代码,去拿去执行权限,然后将自己target的代码拿给解释器去执行,解释器的代码是对所有线程都共享的,这个时候就存在一个问题,垃圾回收线程也可以去访问解释器代码,对于同一个数据,可能线程1去修改它的数据的同时 垃圾回收对他执行的是回收操作,这个时候就会导致很多无法预料的bug。GIL加锁处理,就是保证解释器同一时间内只能执行一个任务的代码。这就导致了同一个进程下的线程无法实现并行,不能很好的利用cpu的多核机制,但是还是可以实现并发的。(如果想实现并行只能开启多个进程)
二、GIL与Lock的区别
GIL保护的是解释器级别的数据,但是用户自己的数据需要自己加锁处理。


from threading import Thread,Lock import time mutex=Lock() n=100 def task(): global n with mutex: temp=n time.sleep(0.1) n=temp-1 if __name__ == '__main__': l=[] for i in range(100): t=Thread(target=task) l.append(t) t.start() for t in l: t.join() print(n)
通过自定义互斥锁,每个线程除了要抢到GIL锁之外还要抢到自定义的锁,否则即使抢到了GIL也没有用,这就充分保证了数据的安全性。
三、GIL与多线程
既然有了GIL的存在,一个进程中同一时刻只有一个线程能够被执行,无法利用cpu的多核机制,和多进程一比,是不是多进程反而更占优势了呢。
那多核机制有什么好处呢?
cpu是用来做计算的,多核,意味多个cpu去完成计算功能,提升计算性能,但是cpu一旦遇到 I/O操作,那么多核对I/O就没有什么帮助了。
#计算操作 from multiprocessing import Process import os,time from threading import Thread def work(): res=0 for i in range(100000000): res+=i if __name__ == '__main__': print(os.cpu_count()) p_l =[] start = time.time() for i in range(4): p = Process(target=work)#5.057471036911011 # p = Thread(target=work)#18.38089609146118 p.start() p_l.append(p) for j in p_l: j.join() print('time is %s'%(time.time()-start))
#io操作 from threading import Thread from multiprocessing import Process import time def work(): time.sleep(4) if __name__ == '__main__': p_l = [] start = time.time() for i in range(4): p = Process(target=work)#4.281008243560791 # p = Thread(target=work)#4.002274751663208 p_l.append(p) p.start() for j in p_l: j.join() print(p_l) print('time is %s' % (time.time() - start))
总结:
多线程用于I/O密集型,如socket,爬虫,web等
多进程用于计算密集型,如金融分析等。
四、死锁与递归锁
死锁:两个或两个以上的进程或者线程在执行过程中,因为争夺资源而造成的互相等待现象,若无外力的作用,都将一直处于阻塞状态,这些互相等待的进程或者线程就被称为死锁。
from threading import Thread,Lock import time mutexA=Lock() mutexB=Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print('\033[41m%s 拿到A锁\033[0m' %self.name) mutexB.acquire() print('\033[42m%s 拿到B锁\033[0m' %self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print('\033[43m%s 拿到B锁\033[0m' %self.name) time.sleep(2) mutexA.acquire() print('\033[44m%s 拿到A锁\033[0m' %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(10): t=MyThread() t.start() ''' Thread-1 拿到A锁 Thread-1 拿到B锁 Thread-1 拿到B锁 Thread-2 拿到A锁 然后就卡住,死锁了 '''
解决方法,使用递归锁(RLock)
这个RLock内部有一个Lock和一个counter变量,counter记录着acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
from threading import Thread,Lock,RLock import time mutexB=mutexA=RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止 class Mythead(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print('%s 抢到A锁' %self.name) mutexB.acquire() print('%s 抢到B锁' %self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print('%s 抢到了B锁' %self.name) time.sleep(2) mutexA.acquire() print('%s 抢到了A锁' %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(100): t=Mythead() t.start()
五、信号量Semaphore
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
from threading import Thread,Semaphore import time,random sm=Semaphore(5)#最大连接数为5 def task(name): sm.acquire() print('%s 正在上厕所' %name) time.sleep(random.randint(1,3)) sm.release() if __name__ == '__main__': for i in range(20): t=Thread(target=task,args=('路人%s' %i,)) t.start()
六、Event
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时就需要用到threading中的Event对象。对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
from threading import Thread,Event import time event=Event() def light(): print('红灯正亮着') time.sleep(3) event.set() #绿灯亮 def car(name): print('车%s正在等绿灯' %name) event.wait() #等灯绿 print('车%s通行' %name) if __name__ == '__main__': # 红绿灯 t1=Thread(target=light) t1.start() # 车 for i in range(10): t=Thread(target=car,args=(i,)) t.start()
七、queue补充
线程的queue和进程一样,这里补充一下queue.LifoQueue()和queue.PriorityQueue()优先级
queue.LifoQueue() 后进先出---->堆栈
q=queue.LifoQueue(3) q.put(1) q.put(2) q.put(3) print(q.get())#3 print(q.get())#2 print(q.get())#1
queue.PriorityQueue() 设置优先级别,数字越小,优先级别越高
q=queue.PriorityQueue(3) #优先级,优先级用数字表示,数字越小优先级越高 q.put((10,'a')) q.put((-1,'b')) q.put((100,'c')) print(q.get())#(-1, 'b') print(q.get())#(10, 'a') print(q.get())#(100, 'c')
焚膏油以继晷,恒兀兀以穷年。
