通用技巧
有些技巧对你来说可能就是明摆着的事,但在某些时候可能却并非如此,也可能存在不适用的情况,甚至对你的特定任务来说,可能不是一个好的技巧,所以使用时需要务必要谨慎!
使用 ADAM 优化器
确实很有效。与更传统的优化器相比,如 Vanilla 梯度下降法,我们更喜欢用ADAM优化器。用 TensorFlow 时要注意:如果保存和恢复模型权重,请记住在设置完AdamOptimizer 后设置 Saver,因为 ADAM 也有需要恢复的状态(即每个权重的学习率)。
ReLU 是最好的非线性(激活函数)
就好比 Sublime 是最好的文本编辑器一样。ReLU 快速、简单,而且,令人惊讶的是,它们工作时,不会发生梯度递减的情况。虽然 sigmoid 是常见的激活函数之一,但它并不能很好地在 DNN 进行传播梯度。
不要在输出层使用激活函数
这应该是显而易见的道理,但如果使用共享函数构建每个层,那就很容易犯这样的错误:所以请确保在输出层不要使用激活函数。
请在每一个层添加一个偏差
这是 ML 的入门知识了:偏差本质上就是将平面转换到最佳拟合位置。在 y=mx+b 中,b 是偏差,允许曲线上下移动到“最佳拟合”位置。
使用方差缩放(variance-scaled)初始化
在 Tensorflow 中,这看起来像tf.reemaner.variance_scaling_initializer()。根据我们的经验,这比常规的高斯函数、截尾正态分布(truncated normal)和 Xavier 能更好地泛化/缩放。
粗略地说,方差缩放初始化器根据每层的输入或输出数量(TensorFlow中的默认值是输入数量)调整初始随机权重的方差,从而有助于信号更深入地传播到网络中,而无须额外的裁剪或批量归一化(batch normalization)。Xavier 与此相似,只是各层的方差几乎相同;但是不同层形状变化很大的网络(在卷积网络中很常见)可能不能很好地处理每层中的相同方差。
归一化输入数据
对于训练,减去数据集的均值,然后除以它的标准差。在每个方向的权重越少,你的网络就越容易学习。保持输入数据以均值为中心且方差恒定有助于实现这一点。你还必须对每个测试输入执行相同的规范化,因此请确保你的训练集与真实数据相似。
以合理保留其动态范围的方式缩放输入数据。这与归一化有关,但应该在归一化之前就进行。例如,真实世界范围为 [0,140000000] 的数据 x 通常可以用 tanh(x) 或 tanh(x/C) 来控制,其中 C 是一些常数,它可以拉伸曲线,以适应 tanh 函数缓坡部分的动态范围内的更多输入范围。特别是在输入数据在一端或两端可能不受限制的情况下,神经网络将在(0,1)之间学习得更好。
一般不用学习率衰减
学习率衰减在 SGD 中更为常见,但 ADAM 很自然地处理了这个问题。如果你真的想把每一分表现都挤出去:在训练结束时短时间内降低学习率;你可能会看到突然的、非常小的误差下降,然后它会再次变平。
如果你的卷积层有 64 或 128 个过滤器,那就足够了。特别是一个对于深度网络而言。比如,128 个真的就已经很多了。如果你已经有了大量的过滤器,那么再添加更多的过滤器未必会进一步提高性能。
池化用于平移不变性
池化本质上就是让网络学习图像“那部分”的“总体思路”。例如,最大池化可以帮助卷积网络对图像中的特征的平移、旋转和缩放变得更加健壮。
调试神经网络
如果你的网络没能很好地进行学习(指在训练过程中损失/准确率没有收敛,或者没有得到预期的结果),那么可以试试以下的技巧:
过拟合
如果你的网络没有学习,那么首先要做的第一件事就是对训练点进行过拟合。准确率基本上应为 100% 或 99.99%,或误差接近 0。如果你的神经网络不能对单个数据点进行过拟合,那么体系架构就可能有严重的问题,但这可能是微妙的。如果你可以对一个数据点进行过拟合,但是对较大的集合进行训练仍然无法收敛,请尝试以下建议:
降低学习率
你的网络学习就会变得更慢一些,但是它可能会找到以前无法进入的最小化的方式,因为它的步长太大了。
提高学习率
这样做将会加快训练,有助于收紧反馈,这意味着无论你的网络是否正常工作,你都会很快地知道你的网络是否有效。虽然网络应该更快地收敛,但其结果可能不会很好,而且“收敛”实际上可能会跳来跳去。(对于 ADAM 优化器,我们发现在很多经历中,学习率大约为 0.001 时,表现很不错。)
减少批量处理规模
将批处理大小减小到 1,可以为你提供与权重更新相关的更细粒度的反馈,你应该使用TensorBoard(或其他一些调试/可视化工具)展示出来。
删除批归一化层
随着批处理大小减少到 1,这样做会暴露出梯度消失或梯度爆炸的问题。我们曾有过一个网络,在好几周都没有收敛,当我们删除了批归一化层之后,我们才意识到第二次迭代时输出都是 NaN。就像是创可贴上的吸水垫,它也有它可以发挥效果的地方,但前提是你知道网络没有 Bug。
增加批量处理的规模
一个更大的批处理规模,如果可以的话,整个训练集减少梯度更新中的方差,使每个迭代更准确。换句话说,权重更新将朝着正确的方向发展。但是!它的可用性和物理内存限制都有一个有效的上限。通常,我们发现这个建议不如上述两个建议有用,可以将批处理规模减少到1并删除批归一化层。
检查你的重构
大幅度的矩阵重构(如改变图像的X、Y 维度)会破坏空间局部性,使网络更难学习,因为它也必须学会重塑。(自然特征变得支离破碎。事实上,自然特征在空间上呈局部性,也是为什么卷积神经网络能如此有效的原因!)如果使用多个图像/通道进行重塑,请特别小心;使用 numpi.stack()进行适当的对齐操作。
仔细检查你的损失函数
如果使用一个复杂的函数,请尝试将其简化为 L1 或 L2。我们发现L1对异常值不那么敏感,在发出噪声的批或训练点时,不会做出太大的调整。
如果可以的话,仔细检查你的可视化。你的可视化库(matplotlib、OpenCV等)是调整值的比例呢,还是它们进行裁剪?可考虑使用一种视觉上均匀的配色方案。
实战分析
为了使上面所描述的过程更容易让读者理解,我们这儿有一些用于描述我们构建的卷积神经网络的真实回归实验的损失图(通过TesnorBoard)。
起初,这个网络根本没有学习:
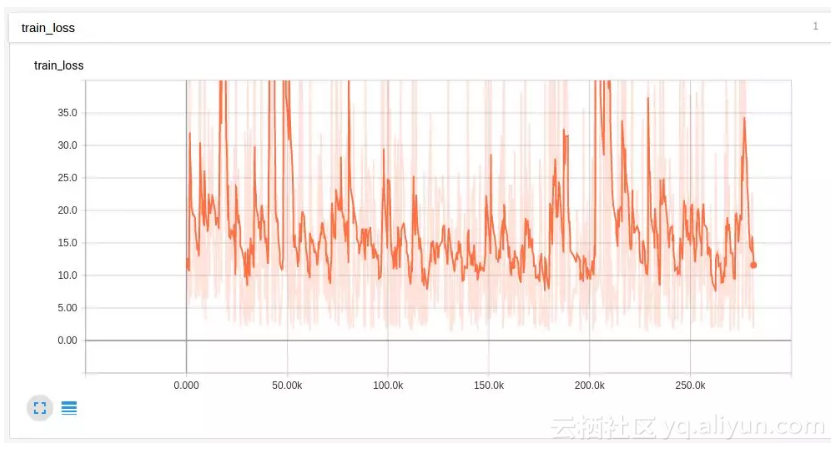
我们试图裁剪这些值,以防止它们超出界限:
嗯。看看不平滑的值有多疯狂啊!学习率是不是太高了?我们试着在一个输入数据上降低学习率并进行训练:
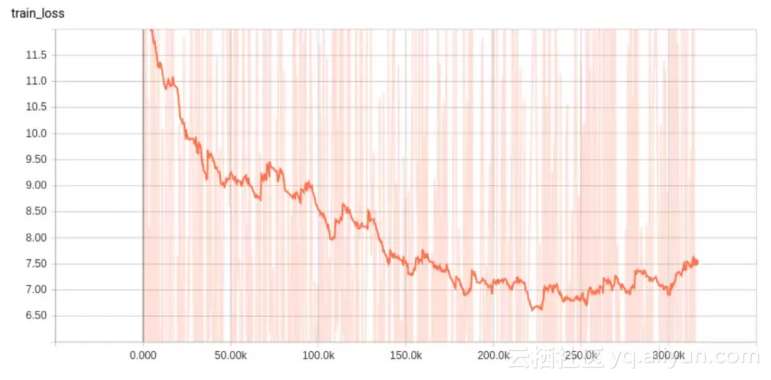
你可以看到学习率的前几个变化发生的位置(大约在 300 步和 3000 步)。显然,我们衰减得太快了。所以,给它更多的衰减时间,它表现得会更好:
你可以看到我们在 2000 步和 5000 步的时候衰减了。这样更好一些了,但还不够好,因为它没有趋于 0。
然后我们禁用了 LR 衰减,并尝试将值移动到更窄的范围内,而不是通过 tanh 输入。虽然这显然使误差值小于 1,但我们仍然不能对训练集进行过拟合:
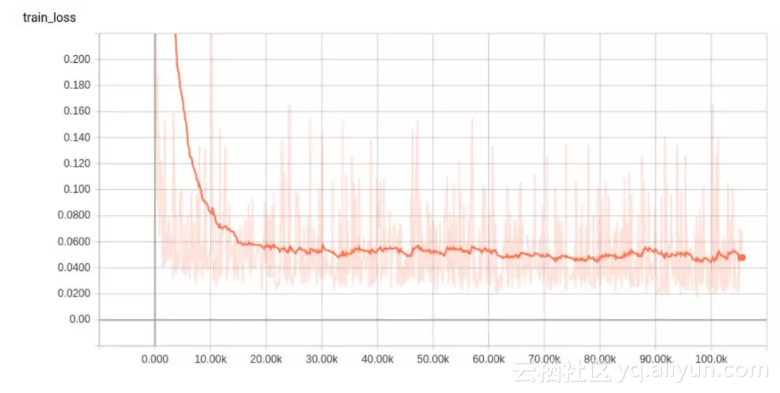
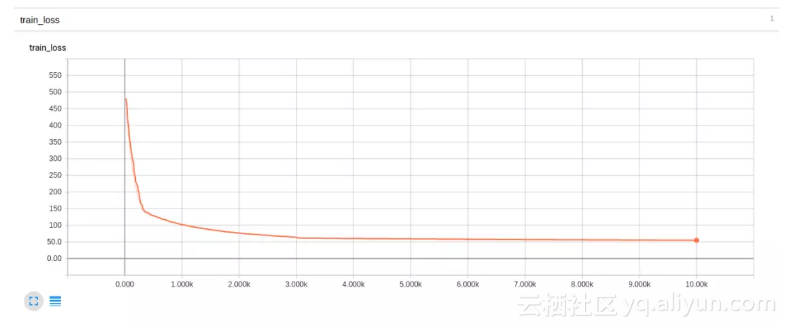
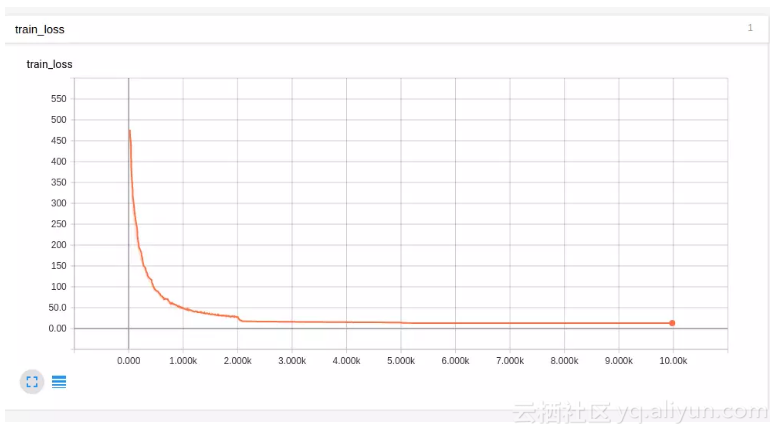
这里我们发现,通过删除批归一化层,网络在一到两次迭代之后迅速输出 NaN。我们禁用了批归一化,并将初始化更改为方差缩放。这些改变了一切!我们能够对只有一两个输入的测试集进行过拟合了。当底部的图标裁剪Y轴时,初始误差值远高于 5,表明误差减少了近 4 个数量级:
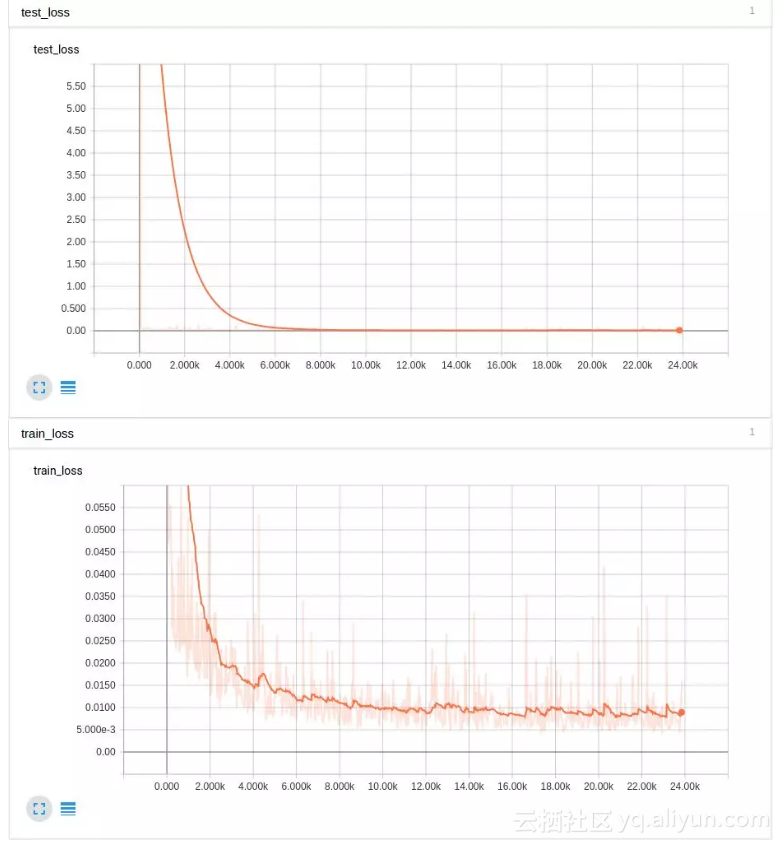
上面的图表是非常平滑的,但是你可以看到它非常快地拟合了测试输入,随着时间的推移,整个训练集的损失降低到了 0.01 以下。这没有降低学习速度。然后我们将学习速率降低一个数量级后继续训练,得到更好的结果:
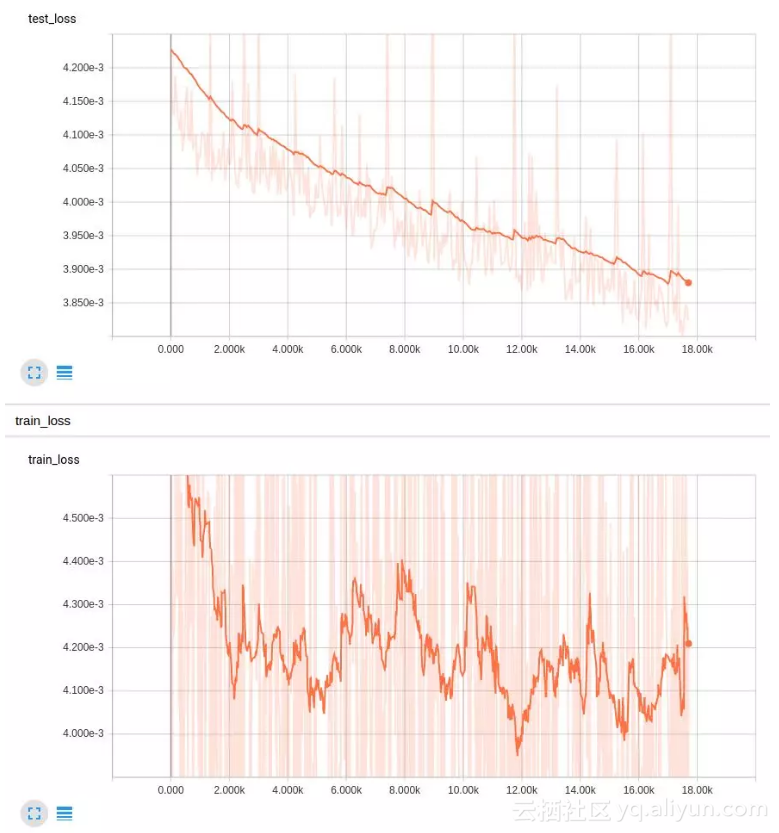
这些结果好得多了!但是,如果我们以几何方式降低学习率,而不是将训练分成两部分,会发生什么样的结果呢?
通过在每一步将学习率乘以 0.9995,结果就不那么好了:
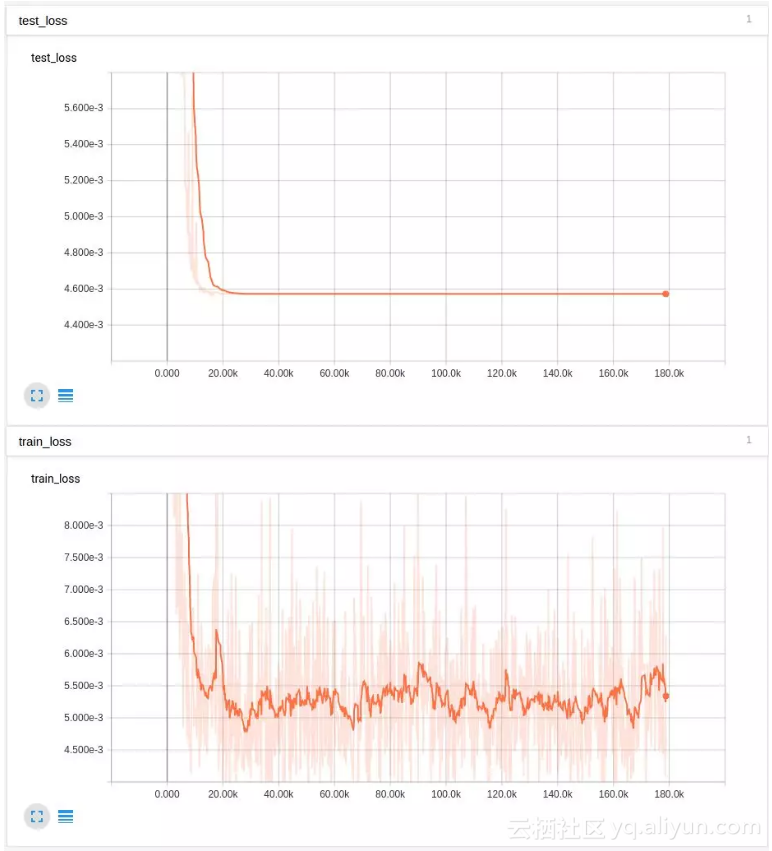
大概是因为学习率衰减太快了吧。乘数为 0.999995 会表现的更好,但结果几乎相当于完全没有衰减。我们从这个特定的实验序列中得出结论,批归一化隐藏了由槽糕的初始化引起的爆炸梯度,并且 ADAM 优化器对学习率的衰减并没有什么特别的帮助,与批归一化一样,裁剪值只是掩盖了真正的问题。我们还通过 tanh 来控制高方差输入值。
我们希望,本文提到的这些基本技巧能够在你构建深度神经网络时有所帮助。通常,正式因为简单的事情才改变了这一切。
原文发布时间为:2018-09-19
