我们在2017年统一了搜索和推荐场景下的HA3、iGraph、RTP和DII四大引擎的存储层(参见统一之战),帮助它们取得了的更迅速的迁移能力、更快速的数据恢复能力和更丰富的数据召回能力。 最近一年来,我们在统一的存储框架上又做了进一步的演进,下面将分别从架构、Build服务以及存储模型角度介绍我们的新进展和思考。
1.架构
在我们的传统架构(参见统一之战)中,Build 服务产出索引后,分发工具dp2将新产生的索引分发到各个searcher的本地磁盘上,同列多行的searcher之间采用链式分发。一个业务的数据量越大,它需要的索引分发时间越大。比如iGraph上的推荐业务和基于HA3的Open Search上的搜索业务,数据量经常是内存量的4-5倍,单个searcher容器需要的索引动辄在200G甚至300G以上,将索引分发到本地势必造成对ssd盘的大量写操作。ssd盘有一个缺点就是写操作会严重影响读操作的性能,如果正在写某个颗粒时,有请求要读取同一个颗粒上的数据,读操作的延迟会飙高到ms级。写ssd盘的速率越高,读受到的干扰越大。为此,我们对索引的分发还做了限速,比如300MB/s。如果300G索引在300MB/s限速下分发,分发时间需要1000秒。混布场景下,可能有多个容器的searcher集中在同一台机器上分发索引造成分发热点,实际每个容器的分发速度可能只有几十MB/s,分发时间可想而知是多么的漫长了。
为了解决这个问题,我们针对长尾场景(数据量远超内存)提出了“存储计算分离”架构,如下图所示。
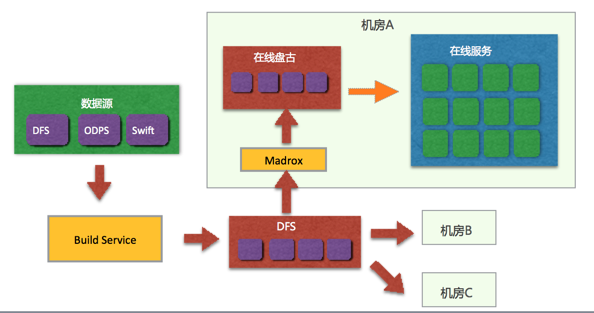
在这个架构中,在线盘古部署到存储集群上,在线服务运行在计算集群上。存储集群目前是用V51机型搭建的,每台V51有12块3.8T NVMe盘。Build Service产出的索引通过同步服务Madrox同步到在线盘古上,而不再需要同步到searcher的本地ssd。在线服务直接读取在线盘古的数据,而不再完全依赖于本地ssd。相对于传统架构,这个架构有如下优势:
(1)索引放到存储集群上,迁移服务不需要迁移数据,于是迁移时间大大缩短;
(2)分发索引可以充分调动存储集群的各块盘的写能力,不会出现因为传统架构中随机出现的分发热点带来的分发时间过长;
(3)计算和存储相分离,各自可以随需独立扩展;
(4)存储资源由存储集群统一管理,可有效避免碎片,避免各个磁盘间的不均衡,提高空间利用效率。
但是,要应用好这个架构,也需要解决不少问题:
(1)网络有最佳工作状态的出带宽和入带宽限制,NVMe盘有存储容量限制,也有可接受延迟的情况下读能力和写能力的限制,CPU有计算能力的限制。这些硬件的限制之间是一个什么关系,谁是水桶中最短的木板需要准确的估算和测试。哪个合理的成为瓶颈,哪个才是估算所需资源量的依据。
(2)软件层面的原因可能会让不合理的瓶颈提前到达,这时候要分析清楚去优化软件,而不是简单的以为某方面到达了瓶颈而去购买更多设备浪费预算。
(3)跨网络读取远端数据和读取本地盘相比,开销势必要高不少,应尽可能降低网络带来的开销。几千台计算节点的场景下,我们无法使用RDMA等高性能的网络协议,但在pangu chunk server上使用用户态TCP是个选择。
(4)索引数据中仍然会存在热点,热点数据的特点是数据量较小但是访问量很大,有可能会使存储集群的随机读取能力首先称为瓶颈。对热点数据的一个有效应对办法是利用本地cache以减少对盘古的访问,但cache预热期间仍然对存储集群有着高随机读取压力。静态cache是另外一个解决办法,然而不是所有业务场景都存在将数据有效划分到静态cache的规则。
目前,上述问题都在努力解决中。已经有两个业务正在上线过程中,我们也计划在接下来将更多的业务迁移到这个架构上,让更多的业务受益。
2.Build Service的进展
一年以来,我们在改进Build Service这个方向上,把精力主要放在提升Build和Merge性能和用户干预索引过程等方面,并取得了不少进展。
2.1 提升Build和Merge性能
Build Service本质上是负责索引生成和优化的服务,其执行过程包括全量索引和增量索引过程。在离线混布的大环境下,我们认为可用的计算资源是相对充裕的,应该充分利用这些充裕的资源来提速索引的产出和优化,也就是通过提高索引过程的并发度来提升性能。当然也可以通过优化代码和数据结构的效率来提高build和merge性能,但不在这篇文章的讨论范围之内。
(1)全量索引速度越快,则业务数据在线上生效的延迟越短。Build Service提高全量Build性能的有效手段是通过全量并行Build,即每个partition由多个instance同时build,这一feature是很久之前就支持的功能。提升全量Merge性能的方法也是充分并行,即每个倒排和正排都可以并行起来。如果有大的倒排成为merge长尾,可以将该倒排索引中的term拆分成多组来获取更大的并行。当merge的instance数目确定后,每个正排和倒排的merge任务将被分配到这些instance上,各个instance负责调度分配给它的merge任务。在混布的背景下,merge instance随时有可能因为某种原因被杀死。此时,merge instance会被调度到其他机器上执行。Build Service 1.4保证了已经完成的merge任务不会再被执行,以此来降低merge instance被杀死重启带来的损失。
(2)增量索引一般来说和实时索引处理的数据一样,多数情况下起到的是对实时索引甚至整体索引(包括全量)的优化作用。在少数的应用场景里,增量索引处理的数据要多于实时索引处理的数据。某些需要大批量导入或刷新数据的场景下,增量索引处理的数据要远远多于实时索引的数据。此时,提升增量索引性能变得至关重要。提升增量索引的性能包括提升增量build和增量merge的性能,其中后者和前面讨论的一样不再赘述。在Build Service 1.4 中,我们提供了通过增量并行Build来提升增量build性能的方式,这打破了Build Service之前对一个Partition只能由一个instance 用了进行增量build的限制,可以说极大地解放了生产力。
2.2 用户干预索引过程
在原有的Build Service管理下,索引内容随着时间的推进在不断做增量。这里的增量并不意味着doc数一直增长,因为增量中的doc有可能是delete doc或者与历史doc重复pk的add doc。增量的含义为每次的增量build过程都是在上一个时间点版本索引的基础上执行add、update和delete doc的操作。在实际的应用中,这一索引管理理念碰到了一些问题,例如:
(1) 执行某次增量build时,当时版本的bs binary存在bug,产出了错误的索引,导致之后的merge不能进行,新的增量build也无法开始,只能从全量索引开始做,成本巨大;
(2) 执行某次增量build时,buider控制内存出现疏漏,导致worker不断因为OOM被杀死,本次增量总是执行不成功。
Build Service 1.4允许用户可以指定索引内容回滚到之前的某个版本,然后重新执行这个时间点之后的索引过程。对于上述的问题(1),用户可以将索引回退到出现问题之前的版本,然后利用新的binary build索引。 1.4也允许暂停某次build或merge,然后修改hippo的某些配置,再恢复起相应的任务。对于上述的问题(2),用户可以暂停增量build任务,调大向hippo申请的内存资源,然后再恢复增量build任务。
2.3 一点思考
在Build Service演化过程中,我们也发现了很多需要对索引进行加工和整理的可能的操作,这些操作不再是传统的Builder和Merger能表达的了,我们将重新定义索引的演化过程。
3.存储模型
在普通表、kv表和kkv表等数据模型上,我们都做了一些迭代改进。
3.1 普通表支持schema动态变化
用户使用普通表模型时,典型的使用过程是需要首先定义好schema,指定有哪些字段,建立哪些正排、倒排以及摘要,然后基于该schema产出全量索引、实时索引和增量索引,提供查询服务。在服务过程中,如果用户需要修改schema,比如添加新的倒排或正排,无论这个倒排或正排来自于新字段还是已经存在的字段,用户都需要重新build全量索引。这意味着数据量越大,添加正排或倒排的成本越高。某些应用场景下,动态添加正排和倒排的需求是比较强烈的,比如:
(1)用户希望对已经存在的字段建立倒排,原因可能是用户希望该字段可快速检索或者indexlib提供了新的索引类型,用户想在此字段上尝试。
(2)用户希望添加一个新字段,并在此上建立正排或倒排,用户要求可以指定每个doc的新字段的值,包括已经存在的doc和新的doc。最典型的应用来自于RTP的Offline2Online项目,新字段的值来自于算法同学可能刚刚上线的一个新模型。
为了大幅降低用户添加正排和倒排的成本,Indexlib 3.5提供了动态添加正排和倒排功能,打破了之前schema必须一成不变的限制。
3.2 kv表和kkv表支持多schema
在Indexlib 3.5之前,Build Service仅允许一个kv表或kkv表拥有一个schema。如果要存储多个schema的数据,则需要创建多个kv表或kkv表。如果schema个数过多(比如上千个),管理这么多的kv表和kkv表也会成为一个复杂的问题。在很多应用场景中,一组不同schema的数据实际上是需要全量一起生效的,也就是说它们本来就应当做一个整体去管理。Indexlib 3.5允许用户在一个kv表和kkv表中定义多个region,每个region可以有自己的schema,kv表或kkv表仍是build、merge和索引切换的基本单位,查询时需要指定region,通过这种方式Indexlib支持了一个kv表或kkv表拥有多个schema。
4.小结
在搜索和推荐统一存储平台的建设过程中,我们在架构、Build服务和数据模型方面都取得了一些突破,本文介绍了几项主要的改进。另外,我们在索引功能和性能优化方面也做了不少增强,将在以后撰文介绍。在这里感谢团队和合作团队的每位同学,也欢迎有志在索引和存储方向上深耕的同学加入我们,和我们一起成长。



