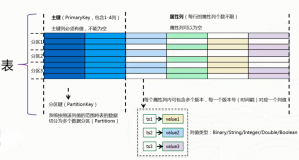
名词定义
- 索引表:对主表某些列数据的索引,只能读不能写。
- 预定义列:表格存储为Schema-free模型,原则上一行数据可以写入任意列,无需在schema中指定。但是也可以在建表时预先定义一些列,以及其类型。
- 单列索引:只为某一个列建立索引。
- 组合索引:多个列组合排序,组合索引中包含组合索引列1,列2。
- 索引表属性列:被映射到索引表非PK列中的主表预定义列。
- 索引列补齐:自动将没有出现在索列中的主表PK列补充到索引表PK中。
使用场景介绍
全局二级索引是表格存储提供的一个新特性。当用户创建一张表时,其所有PK列构成了该表的“一级索引”:即给定完整PK,可以迅速的查找到该PK所在行的数据。但是越来越多的业务场景中,需要对表的属性列,或者非首列PK进行条件上的查询,由于没有足够的索引信息,只能通过进行全表的扫描,配合条件过滤,来得到最终结果,特别是全表数据较多,但最终结果很少时,全表扫描将浪费极大的资源。TableStore提供的二级索引功能(与DynamoDB及HBase的Phoenix方案类似),支持在指定列上建立索引,生成的索引表中数据按用户指定的索引列进行排序,主表的每一笔写入都将自动异步同步到索引表。用户只向主表中写入数据,根据索引表进行查询,在许多场景下,将极大的提高查询的效率。
以我们常见的电话话单查询为例,有主表如下:
| CellNumber | StartTime(Unix时间戳) | CalledNumber | Duration | BaseStationNumber |
|---|---|---|---|---|
| 123456 | 1532574644 | 654321 | 60 | 1 |
| 234567 | 1532574714 | 765432 | 10 | 1 |
| 234567 | 1532574734 | 123456 | 20 | 3 |
| 345678 | 1532574795 | 123456 | 5 | 2 |
| 345678 | 1532574861 | 123456 | 100 | 2 |
| 456789 | 1532584054 | 345678 | 200 | 3 |
其中CellNumber、StartTime分别代表主叫号码与通话发生时间,作为表的联合主键,CalleNumber、Duration、BaseStationNumber三列为表的预定义列,分别代表被叫号码、通话时长、基站号码,每次用户通话结束后,都会将此次通话的信息记录到该表中。可以分别在被叫号码,基站号码列上建立二级索引,来满足不同角度的查询需求(具体建立索引的示例代码见本文附录)。
现在来看几种查询需求:
1.查询号码234567的所有主叫话单:由于表格存储为全局有序模型,所有行按主键进行排序,并且提供顺序扫描(getRange)接口,所以只需要在调用getRange接口时,将PK0列的最大及最小值均设置为234567,PK1列(通话发生时间)的最小值设置为0,最大值设置为INT_MAX,对主表进行扫描即可:
private static void getRangeFromMainTable(SyncClient client, long cellNumber)
{
RangeRowQueryCriteria rangeRowQueryCriteria = new RangeRowQueryCriteria(TABLE_NAME);
// 构造主键
PrimaryKeyBuilder startPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.fromLong(cellNumber));
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.fromLong(0));
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(startPrimaryKeyBuilder.build());
// 构造主键
PrimaryKeyBuilder endPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.fromLong(cellNumber));
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.INF_MAX);
rangeRowQueryCriteria.setExclusiveEndPrimaryKey(endPrimaryKeyBuilder.build());
rangeRowQueryCriteria.setMaxVersions(1);
String strNum = String.format("%d", cellNumber);
System.out.println("号码" + strNum + "的所有主叫话单:");
while (true) {
GetRangeResponse getRangeResponse = client.getRange(new GetRangeRequest(rangeRowQueryCriteria));
for (Row row : getRangeResponse.getRows()) {
System.out.println(row);
}
// 若nextStartPrimaryKey不为null, 则继续读取.
if (getRangeResponse.getNextStartPrimaryKey() != null) {
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(getRangeResponse.getNextStartPrimaryKey());
} else {
break;
}
}
}
AI 代码解读
2.查询号码123456的被叫话单:前面提到,表格存储的模型是对所有行按照主键进行排序,由于被叫号码存在于表的预定义列中,所以无法进行快速查询。因此可以在被叫号码索引表上进行查询:
索引表IndexOnBeCalledNumber:
| PK0 | PK1 | PK2 |
|---|---|---|
| CalledNumber | CellNumber | StartTime |
| 123456 | 234567 | 1532574734 |
| 123456 | 345678 | 1532574795 |
| 123456 | 345678 | 1532574861 |
| 654321 | 123456 | 1532574644 |
| 765432 | 234567 | 1532574714 |
| 345678 | 456789 | 1532584054 |
这里注意,系统会自动进行索引列补齐,即把主表的PK添加到索引列后面,共同作为索引表的PK。所以可以看到索引表有三列PK。
由于索引表IndexOnBeCalledNumber是按被叫号码作为主键,所以可以直接扫描索引表得到结果:
private static void getRangeFromIndexTable(SyncClient client, long cellNumber) {
RangeRowQueryCriteria rangeRowQueryCriteria = new RangeRowQueryCriteria(INDEX0_NAME);
// 构造主键
PrimaryKeyBuilder startPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
startPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_1, PrimaryKeyValue.fromLong(cellNumber));
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MIN);
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.INF_MAX);
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(startPrimaryKeyBuilder.build());
// 构造主键
PrimaryKeyBuilder endPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
endPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_1, PrimaryKeyValue.fromLong(cellNumber));
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MAX);
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.INF_MAX);
rangeRowQueryCriteria.setExclusiveEndPrimaryKey(endPrimaryKeyBuilder.build());
rangeRowQueryCriteria.setMaxVersions(1);
String strNum = String.format("%d", cellNumber);
System.out.println("号码" + strNum + "的所有被叫话单:");
while (true) {
GetRangeResponse getRangeResponse = client.getRange(new GetRangeRequest(rangeRowQueryCriteria));
for (Row row : getRangeResponse.getRows()) {
System.out.println(row);
}
// 若nextStartPrimaryKey不为null, 则继续读取.
if (getRangeResponse.getNextStartPrimaryKey() != null) {
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(getRangeResponse.getNextStartPrimaryKey());
} else {
break;
}
}
}
AI 代码解读
3.查询基站002从时间1532574740开始的所有话单:与上述示例类似,但是查询不仅把基站号码列作为条件,同时把通话发生时间列作为查询条件,因此我们可以在基站号码和通话发生时间列上建立组合索引,数据库中的记录将会如下所示:
索引表IndexOnBaseStation1:
| PK0 | PK1 | PK2 |
|---|---|---|
| BaseStationNumber | StartTime | CellNumber |
| 001 | 1532574644 | 123456 |
| 001 | 1532574714 | 234567 |
| 002 | 1532574795 | 345678 |
| 002 | 1532574861 | 345678 |
| 003 | 1532574734 | 234567 |
| 003 | 1532584054 | 456789 |
然后在IndexOnBaseStation1索引表上进行查询:
private static void getRangeFromIndexTable(SyncClient client,
long baseStationNumber,
long startTime) {
RangeRowQueryCriteria rangeRowQueryCriteria = new RangeRowQueryCriteria(INDEX1_NAME);
// 构造主键
PrimaryKeyBuilder startPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
startPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_3, PrimaryKeyValue.fromLong(baseStationNumber));
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.fromLong(startTime));
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MIN);
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(startPrimaryKeyBuilder.build());
// 构造主键
PrimaryKeyBuilder endPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
endPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_3, PrimaryKeyValue.fromLong(baseStationNumber));
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.INF_MAX);
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MAX);
rangeRowQueryCriteria.setExclusiveEndPrimaryKey(endPrimaryKeyBuilder.build());
rangeRowQueryCriteria.setMaxVersions(1);
String strBaseStationNum = String.format("%d", baseStationNumber);
String strStartTime = String.format("%d", startTime);
System.out.println("基站" + strBaseStationNum + "从时间" + strStartTime + "开始的所有被叫话单:");
while (true) {
GetRangeResponse getRangeResponse = client.getRange(new GetRangeRequest(rangeRowQueryCriteria));
for (Row row : getRangeResponse.getRows()) {
System.out.println(row);
}
// 若nextStartPrimaryKey不为null, 则继续读取.
if (getRangeResponse.getNextStartPrimaryKey() != null) {
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(getRangeResponse.getNextStartPrimaryKey());
} else {
break;
}
}
}
AI 代码解读
4.查询发生在基站003上时间从1532574861到1532584054的所有通话记录的通话时长:此查询相比前面变的更为复杂,不仅把基站号码列与通话发生时间列作为了查询条件,而且只把通话时长列作为返回结果,可以仍使用3中的索引,查索引表成功后反查主表得到通话时长:
private static void getRowFromIndexAndMainTable(SyncClient client,
long baseStationNumber,
long startTime,
long endTime,
String colName) {
RangeRowQueryCriteria rangeRowQueryCriteria = new RangeRowQueryCriteria(INDEX1_NAME);
// 构造主键
PrimaryKeyBuilder startPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
startPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_3, PrimaryKeyValue.fromLong(baseStationNumber));
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.fromLong(startTime));
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MIN);
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(startPrimaryKeyBuilder.build());
// 构造主键
PrimaryKeyBuilder endPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
endPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_3, PrimaryKeyValue.fromLong(baseStationNumber));
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.fromLong(endTime));
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MAX);
rangeRowQueryCriteria.setExclusiveEndPrimaryKey(endPrimaryKeyBuilder.build());
rangeRowQueryCriteria.setMaxVersions(1);
String strBaseStationNum = String.format("%d", baseStationNumber);
String strStartTime = String.format("%d", startTime);
String strEndTime = String.format("%d", endTime);
System.out.println("基站" + strBaseStationNum + "从时间" + strStartTime + "到" + strEndTime + "的所有话单通话时长:");
while (true) {
GetRangeResponse getRangeResponse = client.getRange(new GetRangeRequest(rangeRowQueryCriteria));
for (Row row : getRangeResponse.getRows()) {
PrimaryKey curIndexPrimaryKey = row.getPrimaryKey();
PrimaryKeyColumn mainCalledNumber = curIndexPrimaryKey.getPrimaryKeyColumn(PRIMARY_KEY_NAME_1);
PrimaryKeyColumn callStartTime = curIndexPrimaryKey.getPrimaryKeyColumn(PRIMARY_KEY_NAME_2);
PrimaryKeyBuilder mainTablePKBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
mainTablePKBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, mainCalledNumber.getValue());
mainTablePKBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, callStartTime.getValue());
PrimaryKey mainTablePK = mainTablePKBuilder.build(); // 构造主表PK
// 反查主表
SingleRowQueryCriteria criteria = new SingleRowQueryCriteria(TABLE_NAME, mainTablePK);
criteria.addColumnsToGet(colName); // 读取主表的"通话时长"列
// 设置读取最新版本
criteria.setMaxVersions(1);
GetRowResponse getRowResponse = client.getRow(new GetRowRequest(criteria));
Row mainTableRow = getRowResponse.getRow();
System.out.println(mainTableRow);
}
// 若nextStartPrimaryKey不为null, 则继续读取.
if (getRangeResponse.getNextStartPrimaryKey() != null) {
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(getRangeResponse.getNextStartPrimaryKey());
} else {
break;
}
}
}
AI 代码解读
为了提高查询效率,可以在基站号码列与通话发生时间列上建立组合索引,并把通话时长列作为索引表的属性列,数据库中的记录将会如下所示:
索引表IndexOnBaseStation2:
| PK0 | PK1 | PK2 | Defined0 |
|---|---|---|---|
| BaseStationNumber | StartTime | CellNumber | Duration |
| 001 | 1532574644 | 123456 | 60 |
| 001 | 1532574714 | 234567 | 10 |
| 002 | 1532574795 | 345678 | 5 |
| 002 | 1532574861 | 345678 | 100 |
| 003 | 1532574734 | 234567 | 20 |
| 003 | 1532584054 | 456789 | 200 |
然后在IndexOnBaseStation2索引表上进行查询:
private static void getRangeFromIndexTable(SyncClient client,
long baseStationNumber,
long startTime,
long endTime,
String colName) {
RangeRowQueryCriteria rangeRowQueryCriteria = new RangeRowQueryCriteria(INDEX2_NAME);
// 构造主键
PrimaryKeyBuilder startPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
startPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_3, PrimaryKeyValue.fromLong(baseStationNumber));
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.fromLong(startTime));
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MIN);
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(startPrimaryKeyBuilder.build());
// 构造主键
PrimaryKeyBuilder endPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
endPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_3, PrimaryKeyValue.fromLong(baseStationNumber));
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.fromLong(endTime));
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MAX);
rangeRowQueryCriteria.setExclusiveEndPrimaryKey(endPrimaryKeyBuilder.build());
// 设置读取列
rangeRowQueryCriteria.addColumnsToGet(colName);
rangeRowQueryCriteria.setMaxVersions(1);
String strBaseStationNum = String.format("%d", baseStationNumber);
String strStartTime = String.format("%d", startTime);
String strEndTime = String.format("%d", endTime);
System.out.println("基站" + strBaseStationNum + "从时间" + strStartTime + "到" + strEndTime + "的所有话单通话时长:");
while (true) {
GetRangeResponse getRangeResponse = client.getRange(new GetRangeRequest(rangeRowQueryCriteria));
for (Row row : getRangeResponse.getRows()) {
System.out.println(row);
}
// 若nextStartPrimaryKey不为null, 则继续读取.
if (getRangeResponse.getNextStartPrimaryKey() != null) {
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(getRangeResponse.getNextStartPrimaryKey());
} else {
break;
}
}
}
AI 代码解读
可见,如果不把通话时长列作为索引表的属性列,在每次查询时,都需先从索引表中解出主表的PK,然后对主表进行随机读。当然,把通话时长列作为索引表的属性列后,该列被同时存储在了主表及索引表中,增加了总的存储空间占用,这其实是性能与成本的一个平衡。
5.查询发生在基站003上时间从1532574861到1532584054的所有通话记录的总通话时长,平均通话时长,最大通话时长,最小通话时长:相对于上一条查询,这里不要求返回每一条通话记录的时长,只要求返回所有通话时长的统计信息,用户可以使用与上条查询同的的查询方式,然后自行对返回的每条通话时长做计算,得到最终结果,也可以使用SQL-on-OTS,省去客户端的计算,直接使用SQL语句返回最终统计结果,SQL-on-OTS的开通使用文档可见此处,其兼容绝大多数MySql语法,可以更方便的进行更复杂的,更贴近用户业务逻辑的计算。
功能介绍
- 支持全局二级索引,主表与索引表之间异步同步,正常情况下,同步延迟在毫秒级。
-
支持单列索引及组合索引,支持索引表带有属性列(Covered Indexes)。主表可以预先定义若干列(称为预定义列),可以对任意预定义列和主表PK列进行索引,可以指定主表的若干个预定义列作为索引表的属性列(索引表也可以不包含任何属性列)。当指定了主表的某些预定义列作为索引表的属性列时,读索引表可以直接得到主表中对应预定义列的值,无需反查主表,提高了查询性能(如上面示例4)。例如:主表有PK0, PK1, PK2三列主键,Defined0, Defined1, Defined2三列预定义列:
- 索引列可以是PK2,没有属性列。
- 索引列可以是PK2,属性列可以是Defined0。
- 索引列可以是PK3, PK2,没有属性列。
- 索引列可以是PK3, PK2,把Defined0作为属性列。
- 索引列可以是PK2, PK1, PK0,把Defined0, Defined1, Defined2作为属性列。
- 索引列可以是Defined0,没有属性列。
- 索引列可以是Define0, PK1, 把Defined1作为属性列。
- 索引列可以是Defined1, Defined0,没有属性列。
- 索引列可以是Defined1, Defined0,把Defined2作为属性列。
-
支持稀疏索引(Sparse Indexes):即如果主表的某个预定义列作为索引表的属性列,当主表某行中不存在该预定义列时,只要索引列全部存在,仍会为此行建立索引,但如果部分索引列缺失,则不会为此行建立索引。例如:主表有PK0, PK1, PK2三列主键,Defined0, Defined1, Defined2三列预定义列,设置索引表PK为Defined0, Defined1, 索引表属性列为Defined2
- 当主表某行中,只包含Defined0, Defined1这两列,不包含Defined2列时,会为此行建立索引。
- 当主表某行中,只包含Defined0,Defined2这两列,不包含Defined1列时,不会为此行建立索引。
- 支持在已经存在的主表上进行创建,删除索引的操作。 后续版本将支持新建的索引表中包含主表中的存量数据。
- 查索引表不会自动反查主表,用户需要自行反查。后续版本将支持自动根据索引表反查主表的功能。
接口说明(以Java SDK为例)
-
创建主表时同时创建索引表
private static void createTable(SyncClient client) { TableMeta tableMeta = new TableMeta(TABLE_NAME); tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema(PRIMARY_KEY_NAME_1, PrimaryKeyType.STRING)); // 为主表设置PK列 tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema(PRIMARY_KEY_NAME_2, PrimaryKeyType.INTEGER)); // 为主表设置PK列 tableMeta.addDefinedColumn(new DefinedColumnSchema(DEFINED_COL_NAME_1, DefinedColumnType.STRING)); // 为主表设置预定义列 tableMeta.addDefinedColumn(new DefinedColumnSchema(DEFINED_COL_NAME_2, DefinedColumnType.INTEGER)); // 为主表设置预定义列 tableMeta.addDefinedColumn(new DefinedColumnSchema(DEFINED_COL_NAME_3, DefinedColumnType.INTEGER)); // 为主表设置预定义列 int timeToLive = -1; // 数据过期时间设置为永不过期 int maxVersions = 1; // 最大版本数为1(带索引表的主表只支持版本数为1) TableOptions tableOptions = new TableOptions(timeToLive, maxVersions); ArrayList<IndexMeta> indexMetas = new ArrayList<IndexMeta>(); IndexMeta indexMeta = new IndexMeta(INDEX_NAME); // 新建索引表Meta indexMeta.addPrimaryKeyColumn(DEFINED_COL_NAME_1); // 指定主表的DEFINED_COL_NAME_1列作为索引表的PK indexMeta.addDefinedColumn(DEFINED_COL_NAME_2); // 指定主表的DEFINED_COL_NAME_2列作为索引表的属性列 indexMetas.add(indexMeta); // 添加索引表到主表 CreateTableRequest request = new CreateTableRequest(tableMeta, tableOptions, indexMetas); // 创建主表 client.createTable(request); }AI 代码解读 -
为已经存在的主表添加索引表
private static void createIndex(SyncClient client) { IndexMeta indexMeta = new IndexMeta(INDEX_NAME); // 新建索引Meta indexMeta.addPrimaryKeyColumn(DEFINED_COL_NAME_2); // 指定DEFINED_COL_NAME_2列为索引表的第一列PK indexMeta.addPrimaryKeyColumn(DEFINED_COL_NAME_1); // 指定DEFINED_COL_NAME_1列为索引表的第二列PK CreateIndexRequest request = new CreateIndexRequest(TABLE_NAME, indexMeta, false); // 将索引表添加到主表上 client.createIndex(request); // 创建索引表 }AI 代码解读注意:当前在添加索引表时,尚不支持索引表中包含主表中已经存在的数据,即新建索引表中将只包含主表从创建索引表开始时的增量数据。如果有对存量数据建索引的需求,请钉钉联系表格存储技术支持
-
删除索引表
private static void deleteIndex(SyncClient client) { DeleteIndexRequest request = new DeleteIndexRequest(TABLE_NAME, INDEX_NAME); // 指定主表名称及索引表名称 client.deleteIndex(request); // 删除索引表 }AI 代码解读 -
读取索引表中数据
需要返回的属性列在索引表中,直接读取索引表:
private static void scanFromIndex(SyncClient client) { RangeRowQueryCriteria rangeRowQueryCriteria = new RangeRowQueryCriteria(INDEX_NAME); // 设置索引表名 // 设置起始主键 PrimaryKeyBuilder startPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder(); startPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_1, PrimaryKeyValue.INF_MIN); // 设置需要读取的索引列最小值 startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MIN); // 主表PK最小值 startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.INF_MIN); // 主表PK最小值 rangeRowQueryCriteria.setInclusiveStartPrimaryKey(startPrimaryKeyBuilder.build()); // 设置结束主键 PrimaryKeyBuilder endPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder(); endPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_1, PrimaryKeyValue.INF_MAX); // 设置需要读取的索引列最大值 endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MAX); // 主表PK最大值 endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.INF_MAX); // 主表PK最大值 rangeRowQueryCriteria.setExclusiveEndPrimaryKey(endPrimaryKeyBuilder.build()); rangeRowQueryCriteria.setMaxVersions(1); System.out.println("扫描索引表的结果为:"); while (true) { GetRangeResponse getRangeResponse = client.getRange(new GetRangeRequest(rangeRowQueryCriteria)); for (Row row : getRangeResponse.getRows()) { System.out.println(row); } // 若nextStartPrimaryKey不为null, 则继续读取. if (getRangeResponse.getNextStartPrimaryKey() != null) { rangeRowQueryCriteria.setInclusiveStartPrimaryKey(getRangeResponse.getNextStartPrimaryKey()); } else { break; } } }AI 代码解读
需要返回的属性列不在索引表中,需要反查主表:
private static void scanFromIndex(SyncClient client) {
RangeRowQueryCriteria rangeRowQueryCriteria = new RangeRowQueryCriteria(INDEX_NAME); // 设置索引表名
// 设置起始主键
PrimaryKeyBuilder startPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
startPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_1, PrimaryKeyValue.INF_MIN); // 设置需要读取的索引列最小值
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MIN); // 主表PK最小值
startPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.INF_MIN); // 主表PK最小值
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(startPrimaryKeyBuilder.build());
// 设置结束主键
PrimaryKeyBuilder endPrimaryKeyBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
endPrimaryKeyBuilder.addPrimaryKeyColumn(DEFINED_COL_NAME_1, PrimaryKeyValue.INF_MAX); // 设置需要读取的索引列最大值
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_1, PrimaryKeyValue.INF_MAX); // 主表PK最大值
endPrimaryKeyBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2, PrimaryKeyValue.INF_MAX); // 主表PK最大值
rangeRowQueryCriteria.setExclusiveEndPrimaryKey(endPrimaryKeyBuilder.build());
rangeRowQueryCriteria.setMaxVersions(1);
while (true) {
GetRangeResponse getRangeResponse = client.getRange(new GetRangeRequest(rangeRowQueryCriteria));
for (Row row : getRangeResponse.getRows()) {
PrimaryKey curIndexPrimaryKey = row.getPrimaryKey();
PrimaryKeyColumn pk1 = curIndexPrimaryKey.getPrimaryKeyColumn(PRIMARY_KEY_NAME1);
PrimaryKeyColumn pk2 = curIndexPrimaryKey.getPrimaryKeyColumn(PRIMARY_KEY_NAME2);
PrimaryKeyBuilder mainTablePKBuilder = PrimaryKeyBuilder.createPrimaryKeyBuilder();
mainTablePKBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME1, pk1.getValue());
mainTablePKBuilder.addPrimaryKeyColumn(PRIMARY_KEY_NAME2, ke2.getValue());
PrimaryKey mainTablePK = mainTablePKBuilder.build(); // 根据索引表PK构造主表PK
// 反查主表
SingleRowQueryCriteria criteria = new SingleRowQueryCriteria(TABLE_NAME, mainTablePK);
criteria.addColumnsToGet(DEFINED_COL_NAME3); // 读取主表的DEFINED_COL_NAME3列
// 设置读取最新版本
criteria.setMaxVersions(1);
GetRowResponse getRowResponse = client.getRow(new GetRowRequest(criteria));
Row mainTableRow = getRowResponse.getRow();
System.out.println(row);
}
// 若nextStartPrimaryKey不为null, 则继续读取.
if (getRangeResponse.getNextStartPrimaryKey() != null) {
rangeRowQueryCriteria.setInclusiveStartPrimaryKey(getRangeResponse.getNextStartPrimaryKey());
} else {
break;
}
}
}
AI 代码解读
注意事项
-
对于每张索引表,系统会自动进行索引列补齐。在对索引表进行扫描时,用户需要注意填充对应PK列的范围(一般为负无穷到正无穷)。例如:主表有
PK0,PK1两列PK,Defined0一列预定义列,如果用户指定在Defined0列上建立索引,则系统会将索引表的PK生成为Defined0,PK0,PK1。用户可以指定在Defined0列及PK1列上建立索引,则生成索引表的PK为Defined0,PK1,PK0。用户还可以在PK列上建立索引,则生成索引表的PK为PK1,PK0。但是无论如果,用户在建立索引表时,只需要指定自己关心的索引列,其它列会由系统自动添加。例如主表有PK0, PK1两列PK,Defined0作为预定义列:- 如果在Defined0上建立索引,那么生成的索引表PK将会是Defined0, PK0, PK1三列。
- 如果在PK1上建立索引,那么生成的索引表PK将会是PK1, PK0两列。
- 选择主表的哪些预定义列作为主表的属性列,是成本和性能的平衡:将主表的一列预定义列作为索引表的属性列后,查询时不用反查主表即可得到该列的值,但是同时增加了相应的存储成本。反之则需要根据索引表反查主表。用户可以根据自己的查询模式以及成本的考虑,作出相应的选择。
- 不建议把时间相关列作为索引表PK的第一列,这样可能导致索引表更新速度变慢。建议将时间列进行哈希,然后在哈希后的列上建立索引,如果有类似需求可以钉钉联系表格存储技术支持一同讨论表结构。
- 不建议把区取值范围非常小,甚至可枚举的列作为索引表PK的第一列,例如
性别,这样将导致索引表水平扩展能力受限,从而影响索引表写入性能。
限制项
- 同一张主表下,最多建立16张索引表。
- 对于一张索引表,其索引列最多有四列(为主表PK以及主表预定义列的任意组合)。
- 索引列的类型为整型,字符串,二进制,布尔, 与主表PK列的约束相同。
- 类型为字符串以及二进制的索引列,大小限制与主表PK列相同。
- 类型为字符串以及二进制的列,作为索引表的属性列时,限制与主表相同。
- 暂不支持TTL表建立索引,有需求请钉钉联系表格存储技术支持。
- 不支持使用多版本功能的表上建立索引。
- 索引表上不允许使用Stream功能。
附录
创建主表及索引表
private static final String TABLE_NAME = "CallRecordTable";
private static final String INDEX0_NAME = "IndexOnBeCalledNumber";
private static final String INDEX1_NAME = "IndexOnBaseStation1";
private static final String INDEX2_NAME = "IndexOnBaseStation2";
private static final String PRIMARY_KEY_NAME_1 = "CellNumber";
private static final String PRIMARY_KEY_NAME_2 = "StartTime";
private static final String DEFINED_COL_NAME_1 = "CalledNumber";
private static final String DEFINED_COL_NAME_2 = "Duration";
private static final String DEFINED_COL_NAME_3 = "BaseStationNumber";
private static void createTable(SyncClient client) {
TableMeta tableMeta = new TableMeta(TABLE_NAME);
tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema(PRIMARY_KEY_NAME_1, PrimaryKeyType.INTEGER));
tableMeta.addPrimaryKeyColumn(new PrimaryKeySchema(PRIMARY_KEY_NAME_2, PrimaryKeyType.INTEGER));
tableMeta.addDefinedColumn(new DefinedColumnSchema(DEFINED_COL_NAME_1, DefinedColumnType.INTEGER));
tableMeta.addDefinedColumn(new DefinedColumnSchema(DEFINED_COL_NAME_2, DefinedColumnType.INTEGER));
tableMeta.addDefinedColumn(new DefinedColumnSchema(DEFINED_COL_NAME_3, DefinedColumnType.INTEGER));
int timeToLive = -1; // 数据的过期时间, 单位秒, -1代表永不过期. 带索引表的主表数据过期时间必须为-1
int maxVersions = 1; // 保存的最大版本数, 带索引表的请表最大版本数必须为1
TableOptions tableOptions = new TableOptions(timeToLive, maxVersions);
ArrayList<IndexMeta> indexMetas = new ArrayList<IndexMeta>();
IndexMeta indexMeta0 = new IndexMeta(INDEX0_NAME);
indexMeta0.addPrimaryKeyColumn(DEFINED_COL_NAME_1);
indexMetas.add(indexMeta0);
IndexMeta indexMeta1 = new IndexMeta(INDEX1_NAME);
indexMeta1.addPrimaryKeyColumn(DEFINED_COL_NAME_3);
indexMeta1.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2);
indexMetas.add(indexMeta1);
IndexMeta indexMeta2 = new IndexMeta(INDEX2_NAME);
indexMeta2.addPrimaryKeyColumn(DEFINED_COL_NAME_3);
indexMeta2.addPrimaryKeyColumn(PRIMARY_KEY_NAME_2);
indexMeta2.addDefinedColumn(DEFINED_COL_NAME_2);
indexMetas.add(indexMeta2);
CreateTableRequest request = new CreateTableRequest(tableMeta, tableOptions, indexMetas);
client.createTable(request);
}
AI 代码解读
Reference
试用
目前表格存储的全局二级索引功能已经在张北公共云集群预发邀测,想要试用可以直接钉钉联系 表格存储技术支持 或者加入钉钉群 111789671