写在前面
Mycat作为独立的数据库中间件,我们只需要进行相关的配置,就可以非常方便的帮我们实现水平切分、垂直切分、读写分离等功能,但PostgreSQL的主从复制需要我们通过其它方式实现。这里假设我们已经搭建好相关的环境,下面就开始我们的实践吧!
准备环境
- PostgreSQL(Version : 10.1)主从环境搭建
- 对应数据库建立(以下例子中使用的都是默认存在的postgres数据库,可以不用额外添加)
配置server.xml
<user name="postgresmycat">
<property name="password">postgresmycat</property>
<property name="schemas">postgresmycats</property>
</user>
配置schema.xml
<schema name="postgresmycats" checkSQLschema="false" sqlMaxLimit="100">
<table name="tb_user" dataNode="mydn3,mydn4" rule="user-mod-long" />
<table name="tb_student" dataNode="mydn3,mydn4" rule="student-mod-long" />
</schema>
<dataNode name="mydn3" dataHost="myhost3" database="postgres" />
<dataNode name="mydn4" dataHost="myhost4" database="postgres" />
<!-- 这里的dbDriver使用jdbc的方式来连接,用native方式似乎目前还不太兼容,试过了好像不可以 -->
<dataHost name="myhost3" maxCon="100" minCon="10" balance="3" writeType="0" dbType="postgresql" dbDriver="jdbc">
<heartbeat>select user</heartbeat><!-- 注意这里的心跳检测命令跟mysql的有点不同 -->
<writeHost host="hostM3" url="jdbc:postgresql://localhost:5432/postgres" user="postgres" password="xxx">
<readHost host="hostS3" url="jdbc:postgresql://localhost:5433/postgres" user="postgres" password="xxx"/>
</writeHost>
</dataHost>
<dataHost name="myhost4" maxCon="100" minCon="10" balance="3" writeType="0" dbType="postgresql" dbDriver="jdbc">
<heartbeat>select user</heartbeat>
<writeHost host="hostM4" url="jdbc:postgresql://localhost:5434/postgres" user="postgres" password="xxx" >
<readHost host="hostS4" url="jdbc:postgresql://localhost:5435/postgres" user="postgres" password="xxx"/>
</writeHost>
</dataHost>
dbDriver 属性
指定连接后端数据库使用的 Driver,目前可选的值有 native 和 jdbc。使用 native 的话,因为这个值执行的
是二进制的 mysql 协议,所以可以使用 mysql 和 maridb。其他类型的数据库则需要使用 JDBC 驱动来支持
引述《Mycat权威指南》里面的原话:
从 1.6 版本开始支持 postgresql 的 native 原始协议。
如果使用 JDBC 的话需要将符合 JDBC4 标准的驱动 JAR 包放到 MYCAT\lib 目录下,并检查驱动 JAR 包中
包括如下目录结构的文件:META-INF\services\java.sql.Driver。在这个文件内写上具体的 Driver 类名,例如:
com.mysql.jdbc.Driver。
所以,具体的解决方案就是找一个postgresql的jar包,然后丢到mycat的lib目录下,不然就会出现启动失败或者连接不到postgre数据库的异常情况。本例中用到的jar包是:postgresql-42.1.4.jar
配置rule.xml
<tableRule name="user-mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="student-mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">2</property>
</function>
修改了配置文件后,别忘了重启Mycat,如果有异常出现,请通过查看logs目录下的日志文件进行排查。
项目搭建(SpringBoot + JPA)
准备:首次建表,设置application.yml中的spring.jpa.hibernate.ddl-auto属性为:create(JPA自动建表解决方案,使用update的话在连接mycat的时候会报找不到表的错误)。之后似乎必须更改为:none,否则使用其它属性都会报错(这里Mysql与PostgreSQL不同,似乎是一个未解决的bug,这也就意味着以后新增字段都要手动连上数据库进行添加了...)
添加application.yml(注意了,这里都是用连mysql的方式去配置,Mycat会在后端做好对其它数据库的连接):
spring:
jpa:
show-sql: true
hibernate:
ddl-auto: update
naming:
strategy: org.hibernate.cfg.ImprovedNamingStrategy
properties:
hibernate:
dialect: org.hibernate.dialect.MySQL5Dialect
datasource:
url: jdbc:mysql://localhost:8066/postgresmycats?characterEncoding=UTF-8&useSSL=false&autoReconnect=true&rewriteBatchedStatements=true
username: postgresmycat
password: postgresmycat
- 添加User Entity
@Entity
@Table(name = "tb_user")
@Data
public class User {
@Id
private Long id;
private String name;
private Integer gender;
}
- 添加Student Entity
@Entity
@Table(name = "tb_student")
@Data
public class Student {
@Id
private Long id;
private String name;
@Column(unique = true)
private Long userId;
}
- 添加UserDao
public interface UserDao extends JpaRepository<User, Long> {
Page<User> findByNameLike(String name, Pageable pageable);
}
- 添加StudentDao
public interface StudentDao extends JpaRepository<Student, Long> {
Page<User> findByNameLike(String name, Pageable pageable);
}
项目测试
- 测试添加
@Test
public void testAdd() {
for (long i = 0; i < 30; i++) {
User user = new User();
user.setId(i);
user.setName("李四" + i);
user.setGender(i % 2 == 0 ? 1 : 0);
userDao.save(user);
Student student = new Student();
student.setId(System.currentTimeMillis() + i);
student.setName("李四学生" + i);
student.setUserId(i);
studentDao.save(student);
}
}
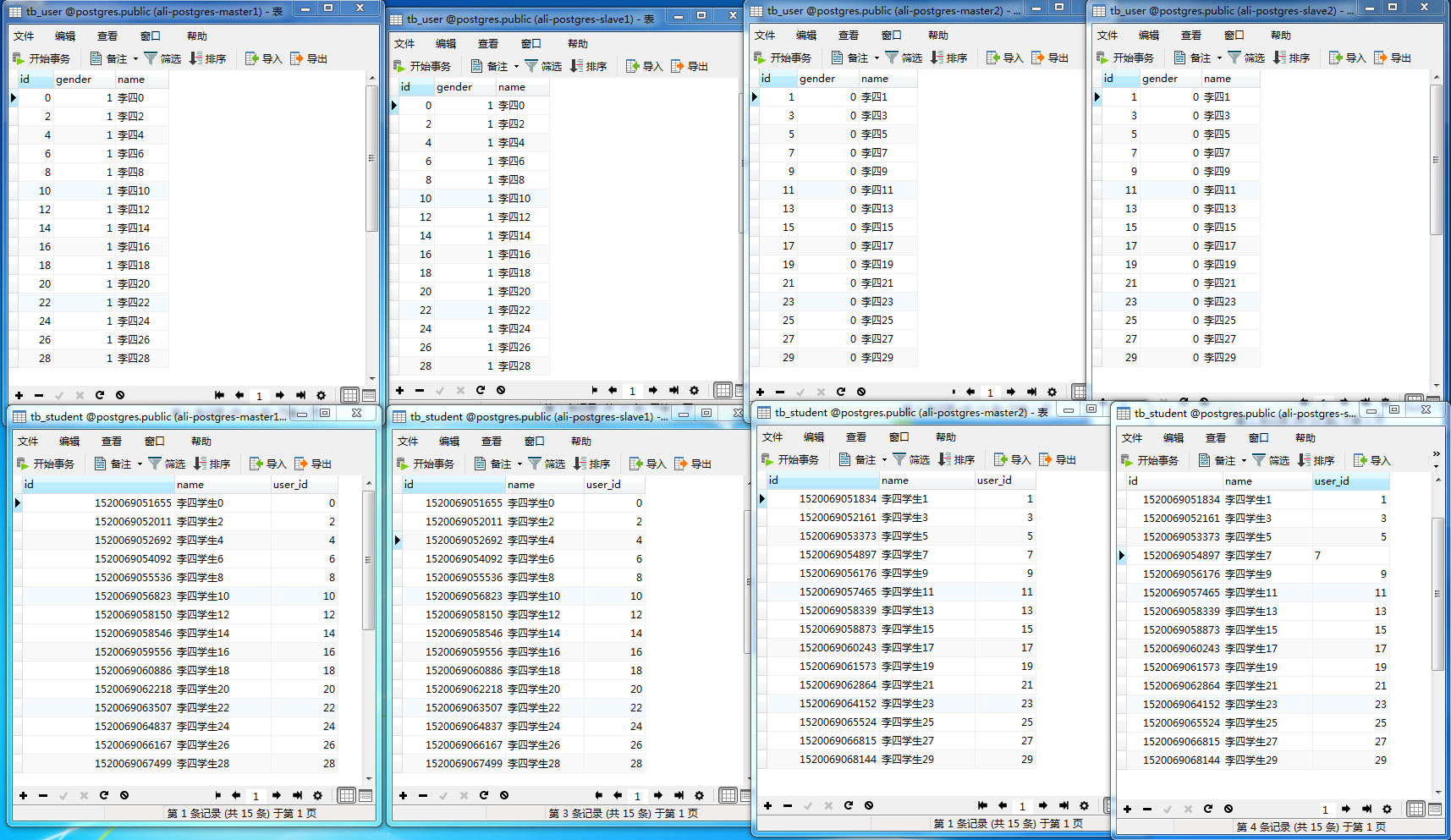
测试结果:数据按id取模的方式划分到了两个数据库中,同时从库同步了主库的数据
- 测试模糊查询+分页
@Test
public void testFind() {
Pageable pageable = new PageRequest(0, 10, Sort.Direction.ASC, "id");
List<User> userList = userDao.findByNameLike("%李四1%", pageable).getContent();
userList.forEach(System.out::println);
Pageable pageable2 = new PageRequest(0, 10, Sort.Direction.ASC, "userId");
List<Student> studentList = studentDao.findByNameLike("%李四学生2%", pageable2).getContent();
studentList.forEach(System.out::println);
}
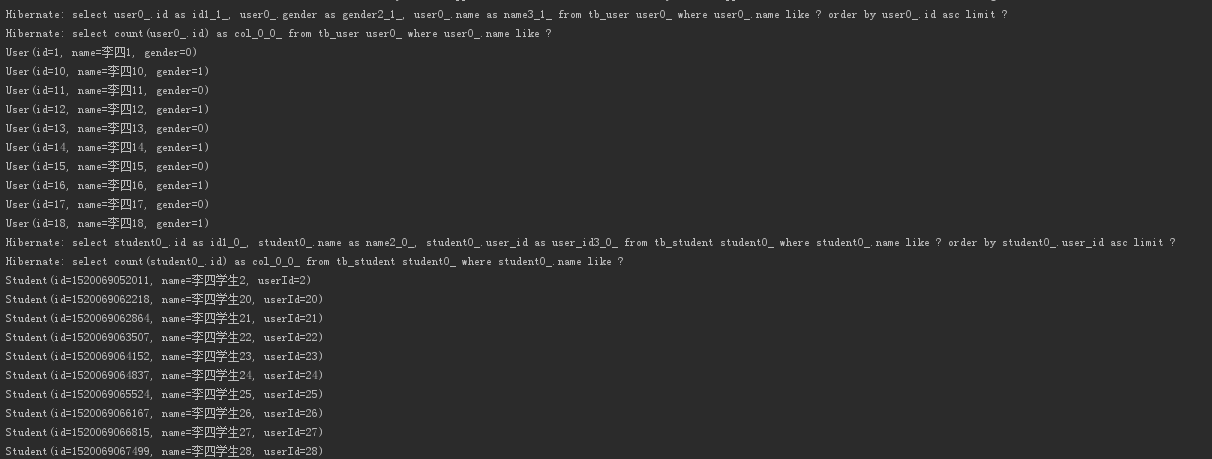
测试结果:按照模糊匹配及id升序的方式输出结果
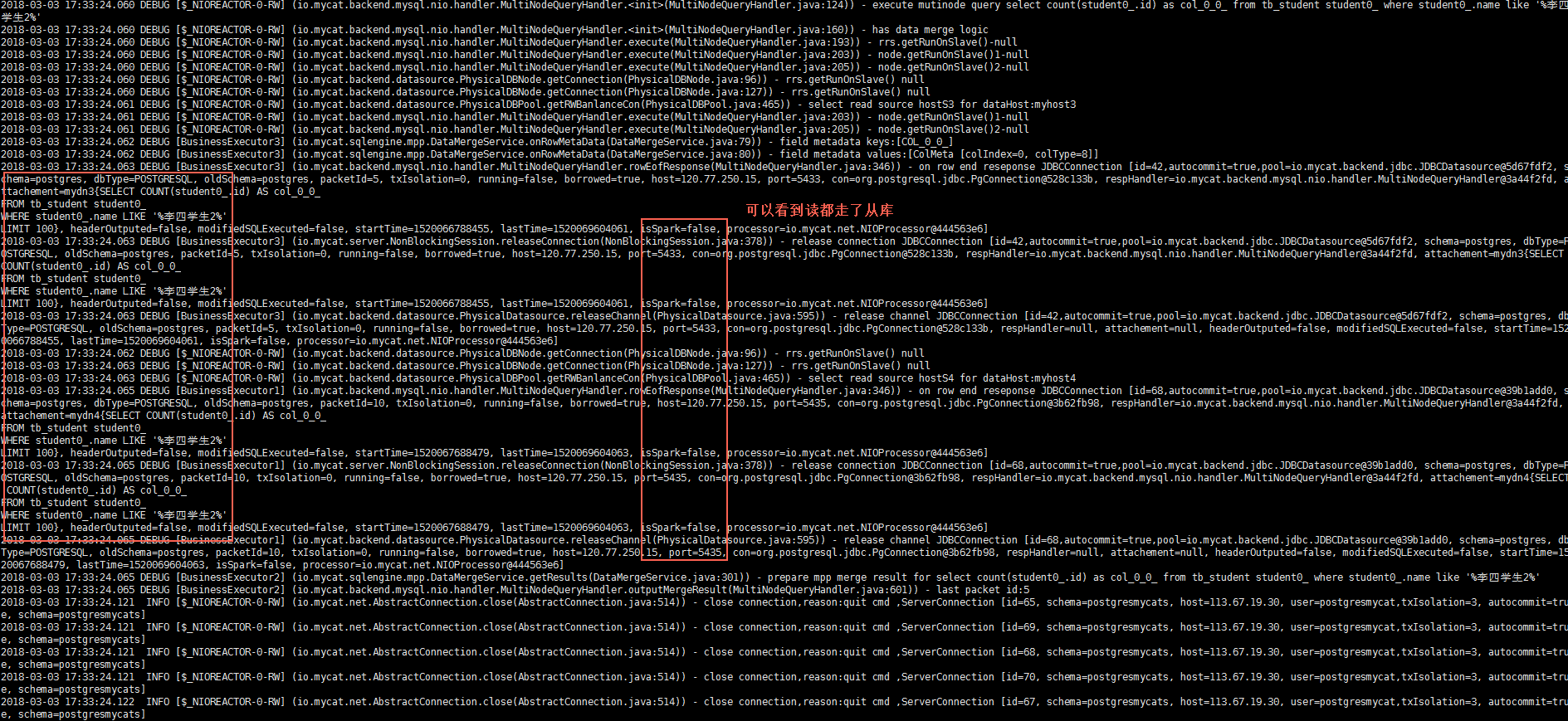
测试结果:读操作都走了从库
- 删除及修改请自行测试
Mycat系列
Mycat(入门篇)
Mycat(配置篇)
Mycat(实践篇 - 基于Mysql的水平切分、主从复制、读写分离)
Mycat(实践篇 - 基于PostgreSQL的水平切分、主从复制、读写分离)
参考链接
Mycat官网
Mycat从零开始
Mycat权威指南
GitHub:Mycat-Server
Wiki:Mycat-Server
Issues:Mycat-Server
mysql中间件研究(Atlas,Cobar,TDDL)
mysql中间件研究(Atlas,Cobar,TDDL,Mycat,Heisenberg,Oceanus,Vitess,OneProxy)