开篇
这次的目标网站也是本人一直以来有在关注的科技平台:Zealer,爬取的信息包括全部的科技资讯以及相应的评论。默认配置下运行,大概跑了半个多小时,最终抓取了5000+的资讯以及10几万的评论。
Zealer Media
说明及准备
开发环境:Scrapy、Redis、PostgreSQL
数据库表:tb_zealer_series、tb_zealer_media、tb_zealer_comment
下面对上述每张表进行简要说明:
- tb_zealer_series,用于存放不同科技频道信息:
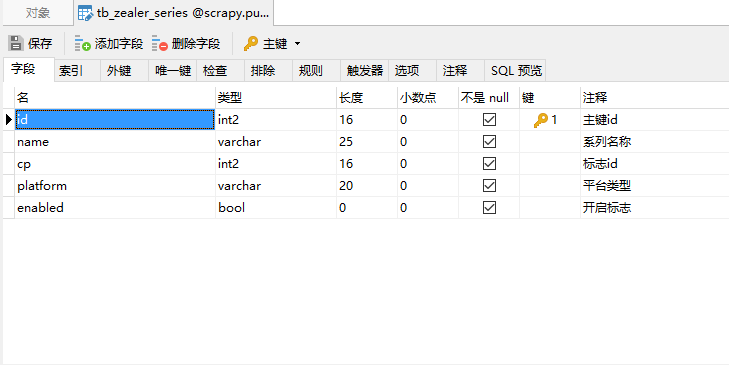
tb_zealer_series
-- ----------------------------
-- Table structure for tb_zealer_series
-- ----------------------------
DROP TABLE IF EXISTS "public"."tb_zealer_series";
CREATE TABLE "public"."tb_zealer_series" (
"id" serial2,
"name" varchar(25) COLLATE "pg_catalog"."default" NOT NULL,
"cp" int2 NOT NULL,
"platform" varchar(20) COLLATE "pg_catalog"."default" NOT NULL,
"enabled" bool NOT NULL
)
;
COMMENT ON COLUMN "public"."tb_zealer_series"."id" IS '主键id';
COMMENT ON COLUMN "public"."tb_zealer_series"."name" IS '系列名称';
COMMENT ON COLUMN "public"."tb_zealer_series"."cp" IS '标志id';
COMMENT ON COLUMN "public"."tb_zealer_series"."platform" IS '平台类型';
COMMENT ON COLUMN "public"."tb_zealer_series"."enabled" IS '开启标志';
-- ----------------------------
-- Indexes structure for table tb_zealer_series
-- ----------------------------
CREATE UNIQUE INDEX "uni_cp" ON "public"."tb_zealer_series" USING btree (
"cp" "pg_catalog"."int2_ops" ASC NULLS LAST
);
- tb_zealer_media,用于保存科技资讯的表:
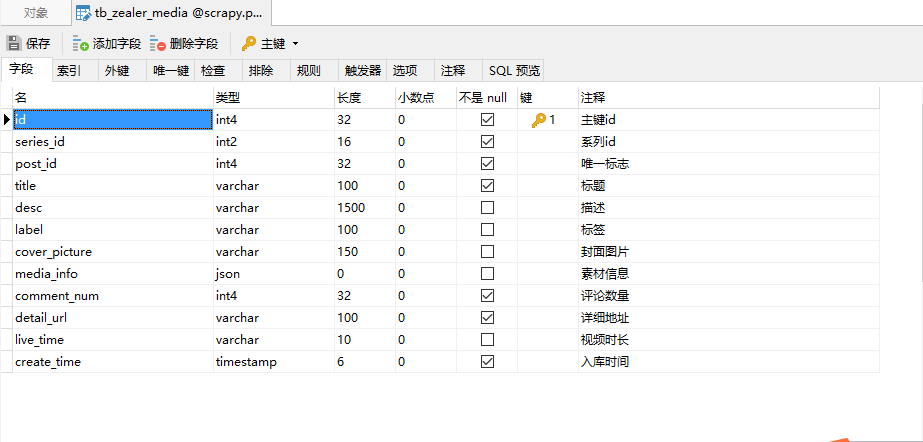
tb_zealer_media
-- ----------------------------
-- Table structure for tb_zealer_media
-- ----------------------------
DROP TABLE IF EXISTS "public"."tb_zealer_media";
CREATE TABLE "public"."tb_zealer_media" (
"id" serial4,
"series_id" int2 NOT NULL,
"post_id" int4 NOT NULL,
"title" varchar(100) COLLATE "pg_catalog"."default" NOT NULL,
"desc" varchar(1500) COLLATE "pg_catalog"."default",
"label" varchar(100) COLLATE "pg_catalog"."default",
"cover_picture" varchar(150) COLLATE "pg_catalog"."default",
"media_info" json,
"comment_num" int4 NOT NULL,
"detail_url" varchar(100) COLLATE "pg_catalog"."default" NOT NULL,
"live_time" varchar(10) COLLATE "pg_catalog"."default",
"create_time" timestamp(6) NOT NULL
)
;
COMMENT ON COLUMN "public"."tb_zealer_media"."id" IS '主键id';
COMMENT ON COLUMN "public"."tb_zealer_media"."series_id" IS '系列id';
COMMENT ON COLUMN "public"."tb_zealer_media"."post_id" IS '唯一标志';
COMMENT ON COLUMN "public"."tb_zealer_media"."title" IS '标题';
COMMENT ON COLUMN "public"."tb_zealer_media"."desc" IS '描述';
COMMENT ON COLUMN "public"."tb_zealer_media"."label" IS '标签';
COMMENT ON COLUMN "public"."tb_zealer_media"."cover_picture" IS '封面图片';
COMMENT ON COLUMN "public"."tb_zealer_media"."media_info" IS '素材信息';
COMMENT ON COLUMN "public"."tb_zealer_media"."comment_num" IS '评论数量';
COMMENT ON COLUMN "public"."tb_zealer_media"."detail_url" IS '详细地址';
COMMENT ON COLUMN "public"."tb_zealer_media"."live_time" IS '视频时长';
COMMENT ON COLUMN "public"."tb_zealer_media"."create_time" IS '入库时间';
-- ----------------------------
-- Indexes structure for table tb_zealer_media
-- ----------------------------
CREATE UNIQUE INDEX "uni_post_id" ON "public"."tb_zealer_media" USING btree (
"post_id" "pg_catalog"."int4_ops" ASC NULLS LAST
);
- tb_zealer_comment,保存每条资讯相应的评论信息:
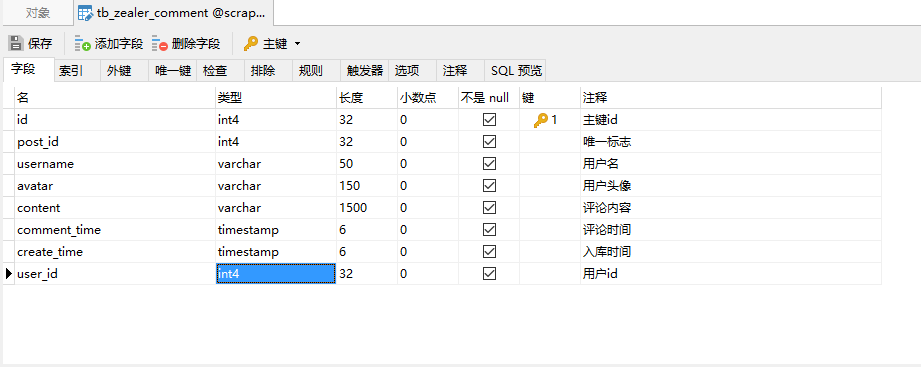
tb_zealer_comment
-- ----------------------------
-- Table structure for tb_zealer_comment
-- ----------------------------
DROP TABLE IF EXISTS "public"."tb_zealer_comment";
CREATE TABLE "public"."tb_zealer_comment" (
"id" serial4,
"post_id" int4 NOT NULL,
"username" varchar(50) COLLATE "pg_catalog"."default" NOT NULL,
"avatar" varchar(150) COLLATE "pg_catalog"."default" NOT NULL,
"content" varchar(1500) COLLATE "pg_catalog"."default" NOT NULL,
"comment_time" timestamp(6) NOT NULL,
"create_time" timestamp(6) NOT NULL,
"user_id" int4 NOT NULL
)
;
COMMENT ON COLUMN "public"."tb_zealer_comment"."id" IS '主键id';
COMMENT ON COLUMN "public"."tb_zealer_comment"."post_id" IS '唯一标志';
COMMENT ON COLUMN "public"."tb_zealer_comment"."username" IS '用户名';
COMMENT ON COLUMN "public"."tb_zealer_comment"."avatar" IS '用户头像';
COMMENT ON COLUMN "public"."tb_zealer_comment"."content" IS '评论内容';
COMMENT ON COLUMN "public"."tb_zealer_comment"."comment_time" IS '评论时间';
COMMENT ON COLUMN "public"."tb_zealer_comment"."create_time" IS '入库时间';
COMMENT ON COLUMN "public"."tb_zealer_comment"."user_id" IS '用户id';
-- ----------------------------
-- Indexes structure for table tb_zealer_comment
-- ----------------------------
CREATE UNIQUE INDEX "uni_uid_pid_ctime" ON "public"."tb_zealer_comment" USING btree (
"user_id" "pg_catalog"."int4_ops" ASC NULLS LAST,
"post_id" "pg_catalog"."int4_ops" ASC NULLS LAST,
"create_time" "pg_catalog"."timestamp_ops" ASC NULLS LAST
);
抓取"科技频道"信息
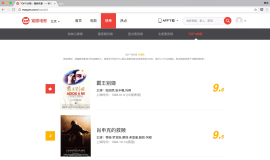
考虑到这块的信息比较少且固定(如下图红框所示),所以用Request+BeautifulSoup提前获取。
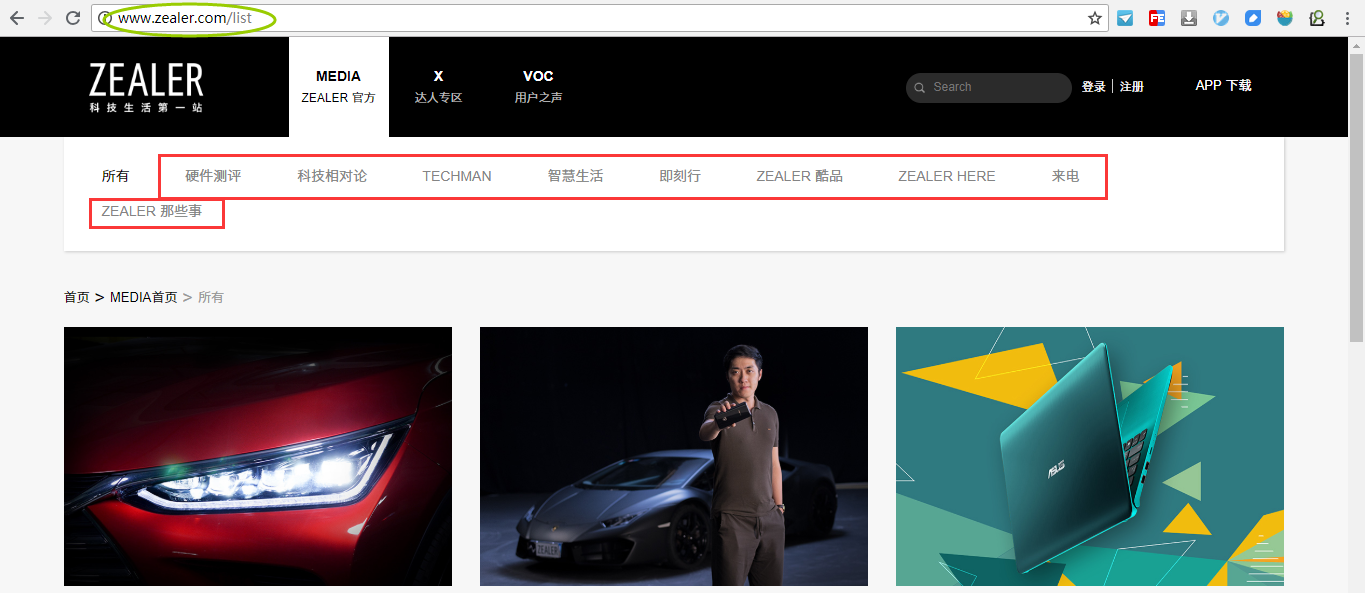
Zealer - Media
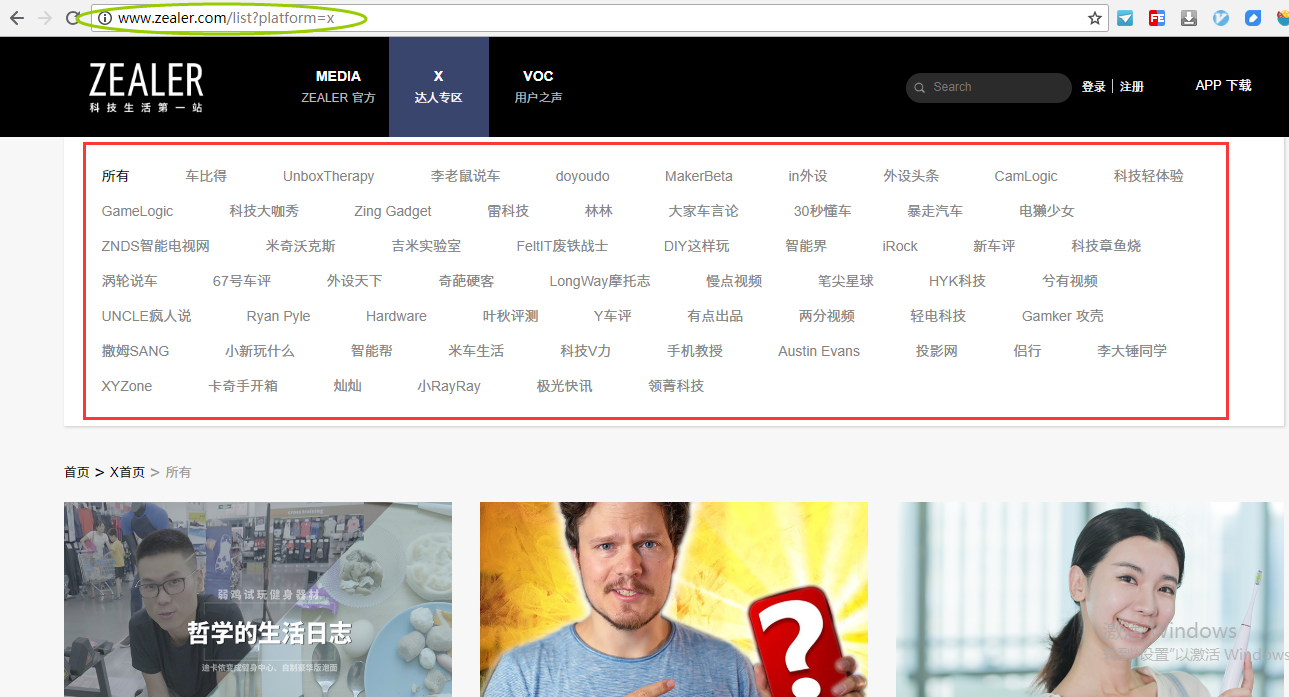
Zealer - X
import app
import requests
from bs4 import BeautifulSoup
from zealer.service import sql
# BeautifulSoup+Request获取所有系列
postgres = app.postgres()
index = 'http://www.zealer.com/list?platform={}'
platforms = ['media', 'x'] # 对应Zealer官方(MEDIA)和达人专区(X)
for platform in platforms:
resp = requests.get(index.format(platform))
bs = BeautifulSoup(resp.text, 'html.parser')
nav_list = bs.find('p', class_='nav_inner')
for nav in nav_list.find_all('a', class_=''):
name, nav_url = nav.text, nav.get('href')
cp = int(nav_url.split('cp=')[1])
postgres.handler(sql.save_series(), (name, cp, platform, True))
环境搭建
新建项目:scrapy startproject zealer
新建爬虫:scrapy genspider tech zealer.com
Item定义
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
from scrapy import Item, Field
class MediaItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
postId = Field()
seriesId = Field()
title = Field()
desc = Field()
label = Field()
coverPicture = Field()
mediaInfo = Field()
commentNum = Field()
detailUrl = Field()
liveTime = Field()
pass
class CommentItem(Item):
userId = Field()
postId = Field()
username = Field()
avatar = Field()
content = Field()
commentTime = Field()
pass
编写爬虫
先分析下页面数据的渲染形式,通过"开发者工具" -> "Network"查看,相应的资讯以及评论数据都是请求接口获得json后再进行展示的,因此直接请求这两个接口就可以了,参考资讯接口示例 && 评论接口示例,其中资讯接口中的cid表示不同的科技频道,上面已经获取到了保存在tb_zealer_series这个表中,page分页从1开始,评论接口的id参数通过资讯接口获得。
这里注释掉默认给出的start_urls = ['http://zealer.com/'],然后重写start_requests方法来定义起始爬取逻辑。由于上述两个接口中并没有返回任何终止的条件,所以这里用比较曲折的方法来自行加判断解决:
# -*- coding: utf-8 -*-
import sys
import json
import math
import scrapy
from utils import mytime
from scrapy import Request
from bs4 import BeautifulSoup
from zealer.service import app, sql
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst
from zealer.items import MediaItem, CommentItem
class TechSpider(scrapy.Spider):
name = 'tech'
allowed_domains = ['zealer.com']
# start_urls = ['http://zealer.com/']
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.postgres = app.postgres()
self.series_list = self.postgres.fetch_all(sql.get_series())
self.series_stop = set() # 用于判断Media抓取终止
self.max_page = sys.maxsize
self.post = 'http://www.zealer.com/post/{}'
self.sift = 'http://www.zealer.com/x/sift?cid={}&page={}&order=created_at'
self.comment = 'http://www.zealer.com/Post/comment?id={}&page={}'
def start_requests(self):
for series in self.series_list:
series_id, cp = series[0], series[1]
for page in range(1, self.max_page):
if series_id in self.series_stop:
self.logger.warning('Stop Media: {}'.format(series_id))
self.series_stop.discard(series_id)
break
else:
sift = self.sift.format(cp, page)
yield Request(sift, callback=self.parse, meta={'series_id': series_id})
def parse(self, response):
"""解析请求资讯接口返回的JSON数据"""
data = json.loads(response.body_as_unicode())
status, messages = data.get('status'), data.get('message')
self.logger.info('Media URL: {} , status: {} , messages: {}'.format(response.url, status, len(messages)))
series_id = response.meta['series_id']
if messages:
# 解析数据
for message in messages:
loader = ItemLoader(item=MediaItem())
loader.default_output_processor = TakeFirst()
post_id = message.get('id')
loader.add_value('postId', int(post_id))
loader.add_value('seriesId', series_id)
loader.add_value('title', message.get('title'))
loader.add_value('coverPicture', message.get('cover'))
comment_total = int(message.get('comment_total'))
loader.add_value('commentNum', comment_total)
loader.add_value('liveTime', message.get('live_time'))
detail_url = self.post.format(post_id)
loader.add_value('detailUrl', detail_url)
yield Request(detail_url, callback=self.parse_detail, meta={'loader': loader})
else:
# 终止条件
self.logger.warning('Judge Stop Media: {}'.format(series_id))
self.series_stop.add(series_id)
def parse_detail(self, response):
"""获取资讯详情页的数据"""
loader = response.meta['loader']
desc = response.xpath('//p[@class="des_content"]/text()').extract_first()
loader.add_value('desc', desc)
tag_list = response.xpath('//div[@class="right_tag"]/a/text()').extract()
loader.add_value('label', '; '.join(map(str.strip, tag_list)))
media_info = response.xpath('//script[@type="text/javascript"]/text()[contains(.,"option")]').extract_first()
media_info = media_info.split('=')[1].split(';')[0].replace(' ', '')
loader.add_value('mediaInfo', media_info)
item = loader.load_item()
comment_num = item.get('commentNum')
if comment_num:
"""抓取评论数据"""
post_id = item.get('postId')
comment_max_page = int(math.ceil(comment_num / 20))
for page in range(1, comment_max_page):
yield Request(self.comment.format(post_id, page),
callback=self.parse_comment, meta={'post_id': post_id})
yield item
def parse_comment(self, response):
"""解析获取评论数据"""
data = json.loads(response.body_as_unicode())
status, count = data.get('status'), int(data.get('count'))
self.logger.info('Comment URL: {} , status: {} , count: {}'.format(response.url, status, count))
if count:
content = data.get('content')
post_id = response.meta['post_id']
bs = BeautifulSoup(content, 'html.parser')
comment_list = bs.find_all('li')
for comment in comment_list:
item = CommentItem()
item['postId'] = post_id
item['userId'] = comment.find('div', class_='list_card')['card']
item['username'] = comment.find('span', class_='mb_name').text
item['avatar'] = comment.find('img')['src']
comment_text = comment.find('p') or comment.find('dd')
item['content'] = comment_text.text
comment_time = comment.find('span', class_='commentTime').text.strip()
item['commentTime'] = self.handleCommentTime(comment_time)
yield item
@staticmethod
def handleCommentTime(comment_time):
"""处理日期问题, 当年的评论返回格式为: x月x日 hh:mm"""
if comment_time.find('年') == -1:
comment_time = '{}年{}'.format(mytime.now_year(), comment_time)
return mytime.str_to_date_with_format(comment_time, '%Y年%m月%d日 %H:%M')
数据入库
在pipelines.py中操作数据入库,别忘了还要在settings.py中配置pipelines开启:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from utils import mytime
from zealer import items
from zealer.service import app, sql
class ZealerPipeline(object):
def __init__(self) -> None:
self.redis = app.redis()
self.postgres = app.postgres()
def process_item(self, item, spider):
if isinstance(item, items.MediaItem):
series_id, post_id = item.get('seriesId'), item.get('postId')
key = "zealer:seriesId:{}".format(series_id)
if not self.redis.sismember(key, post_id):
item_field = ['title', 'desc', 'label', 'coverPicture',
'mediaInfo', 'commentNum', 'detailUrl', 'liveTime']
data = [item.get(field) for field in item_field]
data.insert(0, series_id), data.insert(1, post_id), data.append(mytime.now_date())
effect_count = self.postgres.handler(sql.save_media(), tuple(data))
if effect_count:
self.redis.sadd(key, post_id)
elif isinstance(item, items.CommentItem):
post_id, user_id = item.get('postId'), item.get('userId')
key = "zealer:postId:{}".format(post_id)
if not self.redis.sismember(key, user_id):
item_field = ['username', 'avatar', 'content', 'commentTime']
data = [item.get(field) for field in item_field]
data.insert(0, post_id), data.append(user_id), data.append(mytime.now_date())
effect_count = self.postgres.handler(sql.save_comment(), tuple(data))
if effect_count:
self.redis.sadd(key, user_id)
return item
效果展示
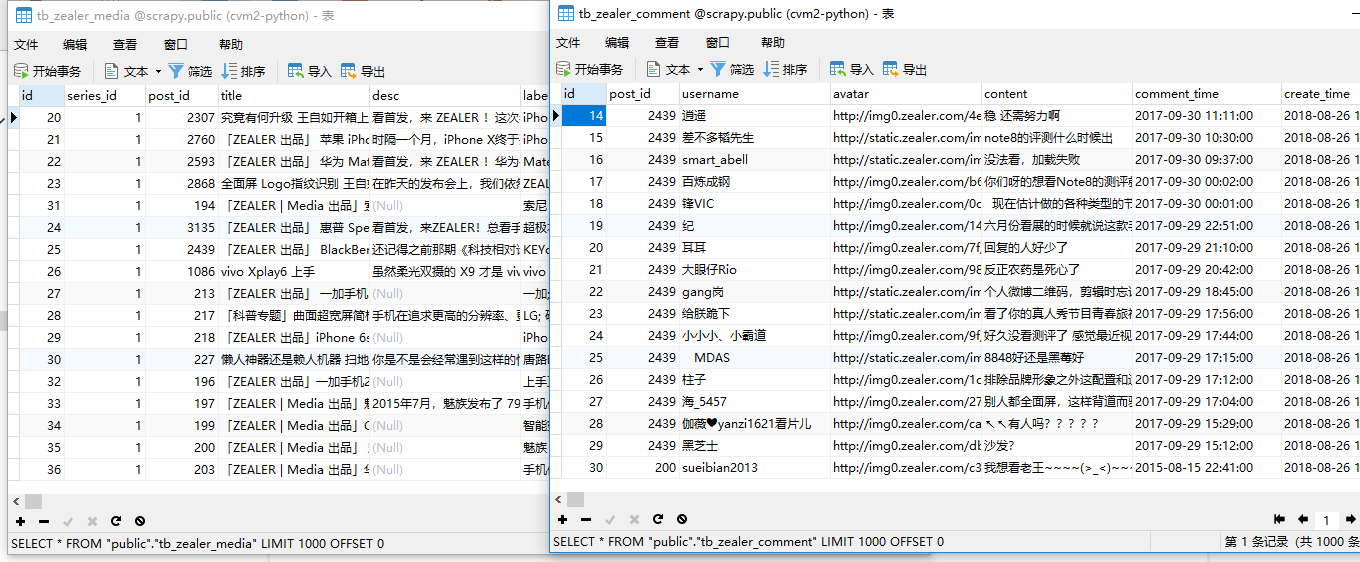
数据展示