
满血上阵,DeepSeek x 低代码创造专属知识空间
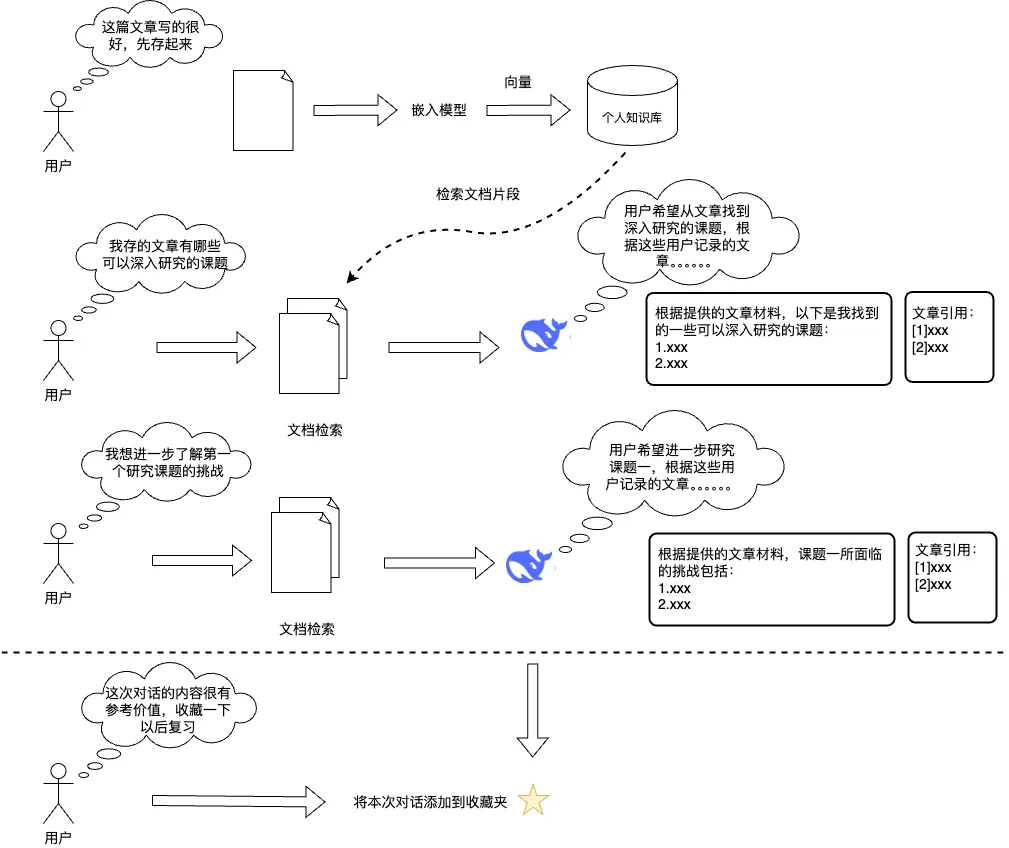


































你好,我是AI助理
可以解答问题、推荐解决方案等
