热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
Java微服务架构设计与实现
vue面试
生物神经元与人工神经元
什么是Shell
7DGroup性能实施项目日记8
ZeptoMail邮箱API发送邮件的方法
element组件问题
【webpack】弄清楚webpack 与vite的区别
Python数据分析工具Seaborn
js字符串截取
BOSHIDA DC电源模块的发展趋势及前景展望
构建高效的Java缓存策略
光学雨量计雨量传感器技术的优势与应用范围
语言模型的历史和发展
ECS使用体验
光学雨量计技术的优势与应用范围
从零开始构建Java消息队列系统
阿里云ECS的使用心得
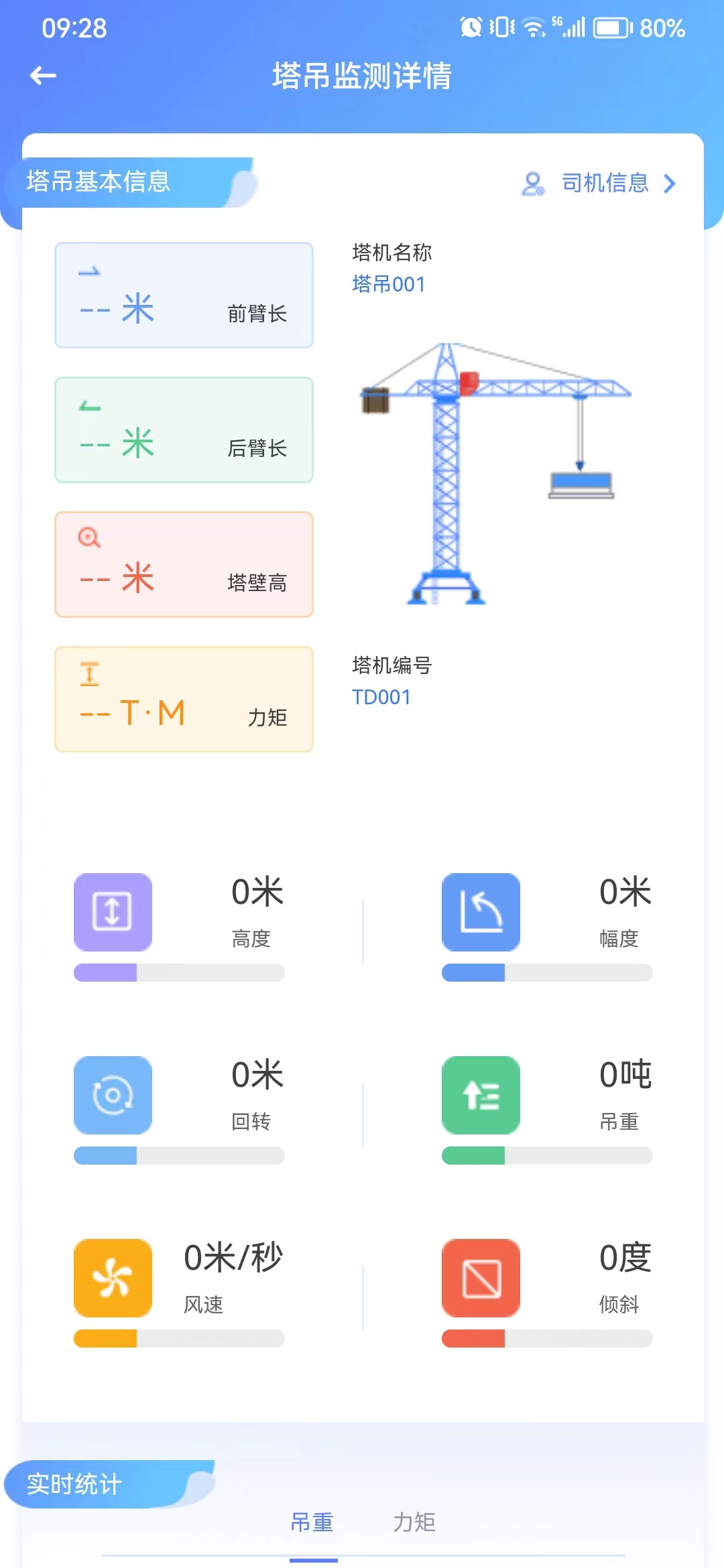
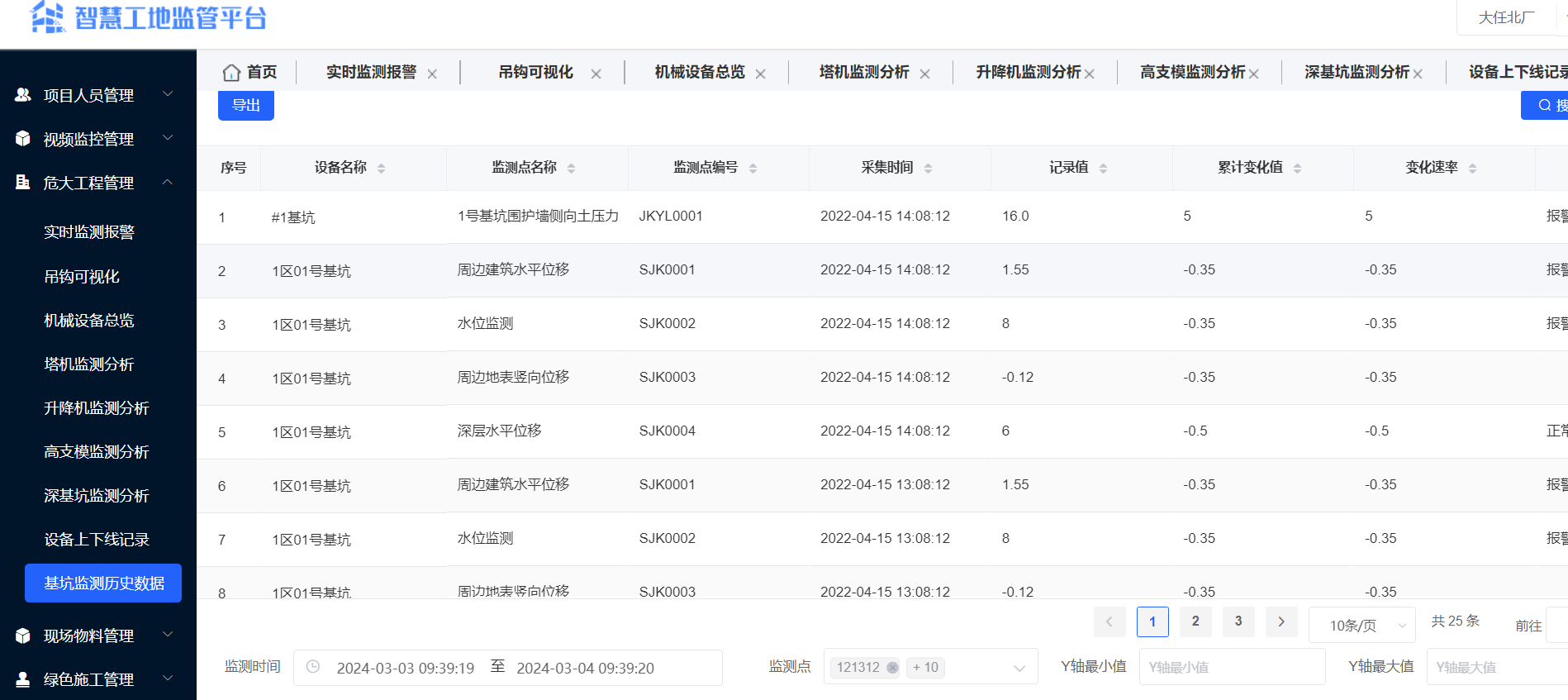
智慧工地管理云平台可视化AI大数据建造工地源码
阿里云ECS使用体验
什么是EL表达式
async、await
关系型数据库ALTER语句
await
git常用操作+常见问题汇总
探索并发编程中的死锁问题及解决方法
Java+Spring Cloud +Vue+UniApp微服务智慧工地云平台源码
iStack详解(三)——iStack多主检测方式
iStack详解(二)——堆叠连接方式堆叠拓扑变动处理
iStack详解(一)——iStack基本原理
关系型数据库CREATE语句
优化前端性能的六大技巧
关系型数据库删除数据
提升前端性能的7个技巧
Java安全编码:防范常见漏洞和攻击
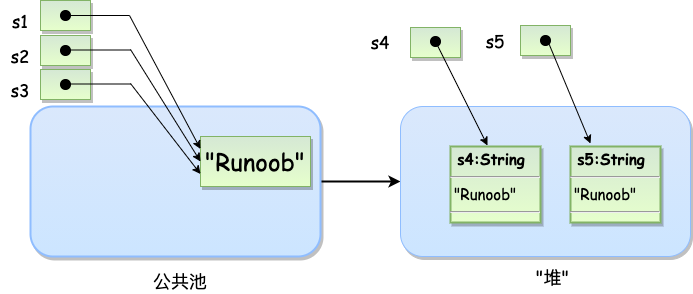
Java String 类
如何做代码Review?
探究 $nextTick 的实现原理
vue知识点
Java基础教程(9)-Java中的面向对象和类(三)
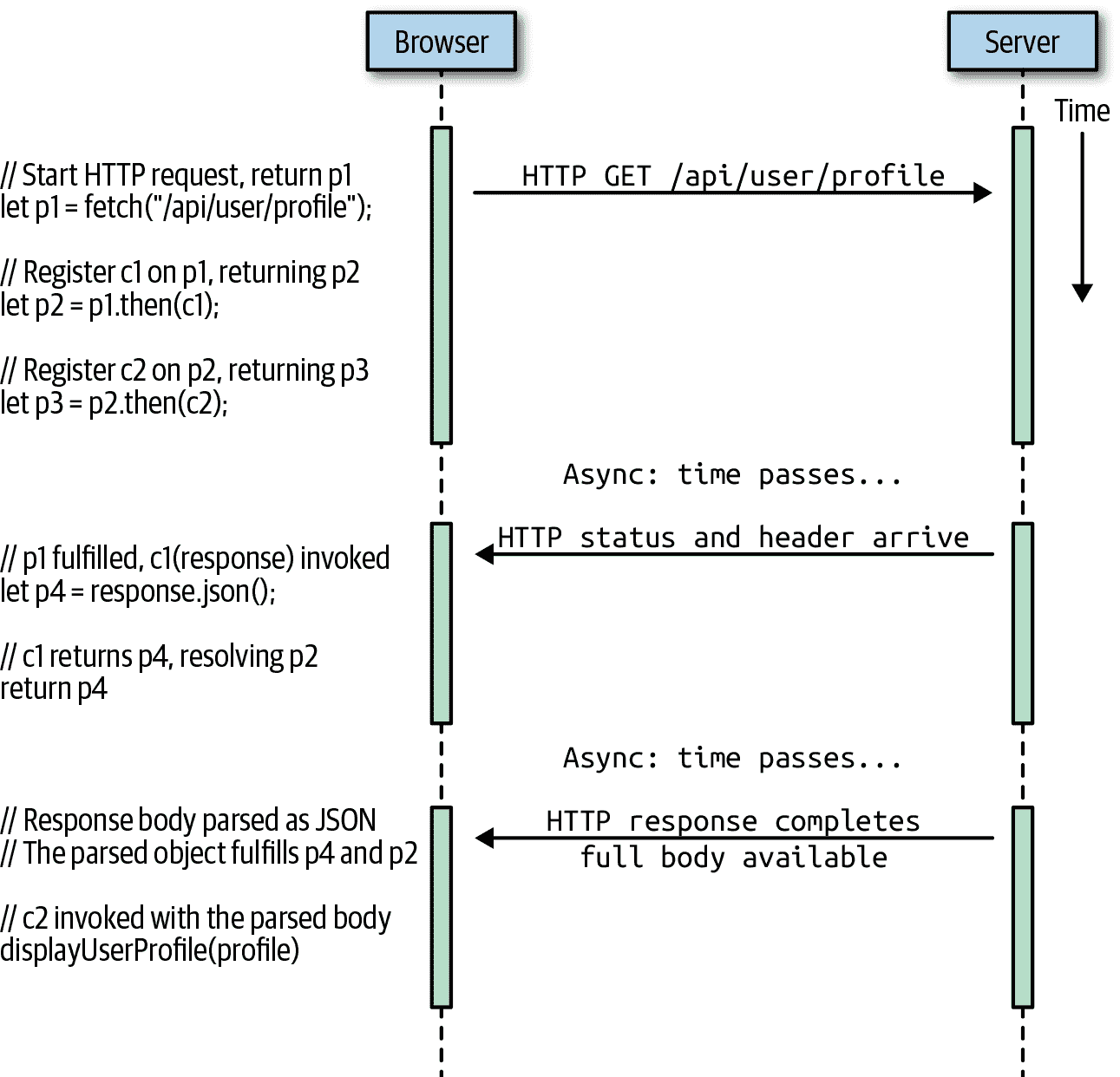
JavaScript 权威指南第七版(GPT 重译)(五)(4)
JavaScript 权威指南第七版(GPT 重译)(五)(3)
JavaScript 权威指南第七版(GPT 重译)(五)(2)
JavaScript 权威指南第七版(GPT 重译)(五)(1)
foreach 跳不出循环
优化前端性能的10个实用技巧
常见的前端加密方法
Vue的缓存组件 | 详解KeepAlive