热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
超级实用的python代码片段汇总和详细解析(16个)(上)
【牛客网算法】NP16 发送offer
代码之美:从功能实现到艺术创作
Spring Cloud 常用各个组件详解及实现原理(附加源码+实现逻辑图)
vue 动态改变css样式
css flex布局两个元素水平居中垂直居中
uniapp读取(获取)缓存中的对象值(微信小程序)
css 设置无背景色
vue element ui 打开弹窗出现黑框问题
数据分享|逻辑回归、随机森林、SVM支持向量机预测心脏病风险数据和模型诊断可视化(下)
数据分享|逻辑回归、随机森林、SVM支持向量机预测心脏病风险数据和模型诊断可视化(上)
数据分享|R语言逻辑回归(Logistic Regression)、回归决策树、随机森林信用卡违约分析信贷数据集
python常用pandas函数nlargest / nsmallest及其手动实现
掌握Spring Boot中的@Validated注解
Python正则表达式Regular Expression初探
python tkinter 最简洁的计算器按钮排列
教你用通义千问只要五步让千年的兵马俑跳上现代的科目三?
异步计算斐波那契数列大数值项(千万数级)的值
Rust 最新版1.75.0升级记
使用Reds实例搭建网上商城的商品相关性分析程序
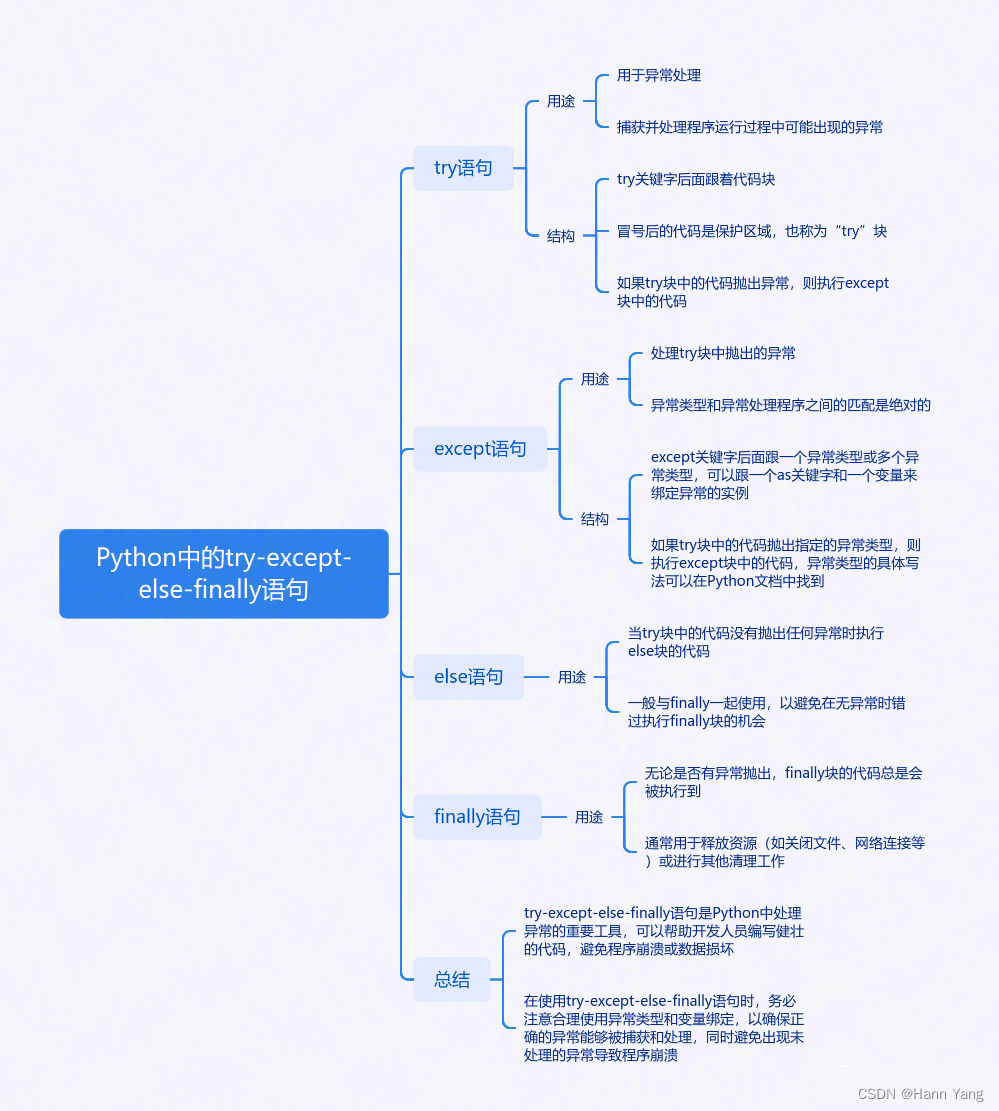
Python异常捕获和处理语句 try-except-else-finally
Python异步编程|PySimpleGUI界面读取PDF转换Excel
Tiktok养号为什么要用静态IP代理?有什么优势?
Kali系统基于qemu虚拟化运行img镜像文件
探索深度学习在图像识别领域的创新应用
数字堡垒的构建者:深入网络安全与信息保护
实现iOS平台的高效图片缓存策略
通过视图函数index添加表数据
深度学习赋能智能监控:图像识别技术的革新与应用
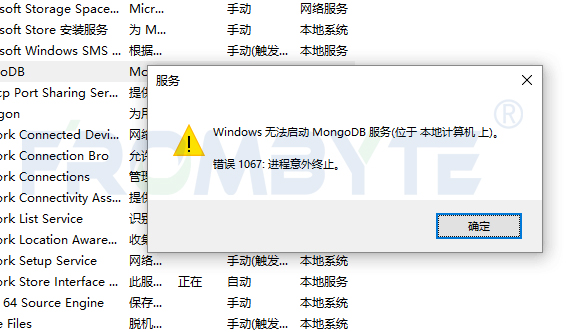
MongoDB数据恢复—MongoDB数据库文件被破坏的数据恢复案例
深入白盒测试:静态分析与动态覆盖的协同策略
构建高效机器学习模型的最佳实践
基于深度学习的图像识别技术在自动驾驶系统中的应用
深入理解PHP的命名空间和自动加载机制
Rust vs Go:解析两者的独特特性和适用场景
数字堡垒的构筑者:网络安全与信息安全的深层探索
网络安全与信息安全:保护你的数据,保护你的未来
深入理解操作系统内存管理:原理与实践
QT环境搭建详解及实例展示
EDA设计与开发:原理、实例与代码详解
Linux挂载硬盘的详细步骤与实例
性能工具之linux常见日志统计分析命令
Linux中grep命令详解与实战应用
STM32采集正弦幅值的研究与实践
面试官:索引失效场景有哪些?
STM32中断详解及其编程实践