热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
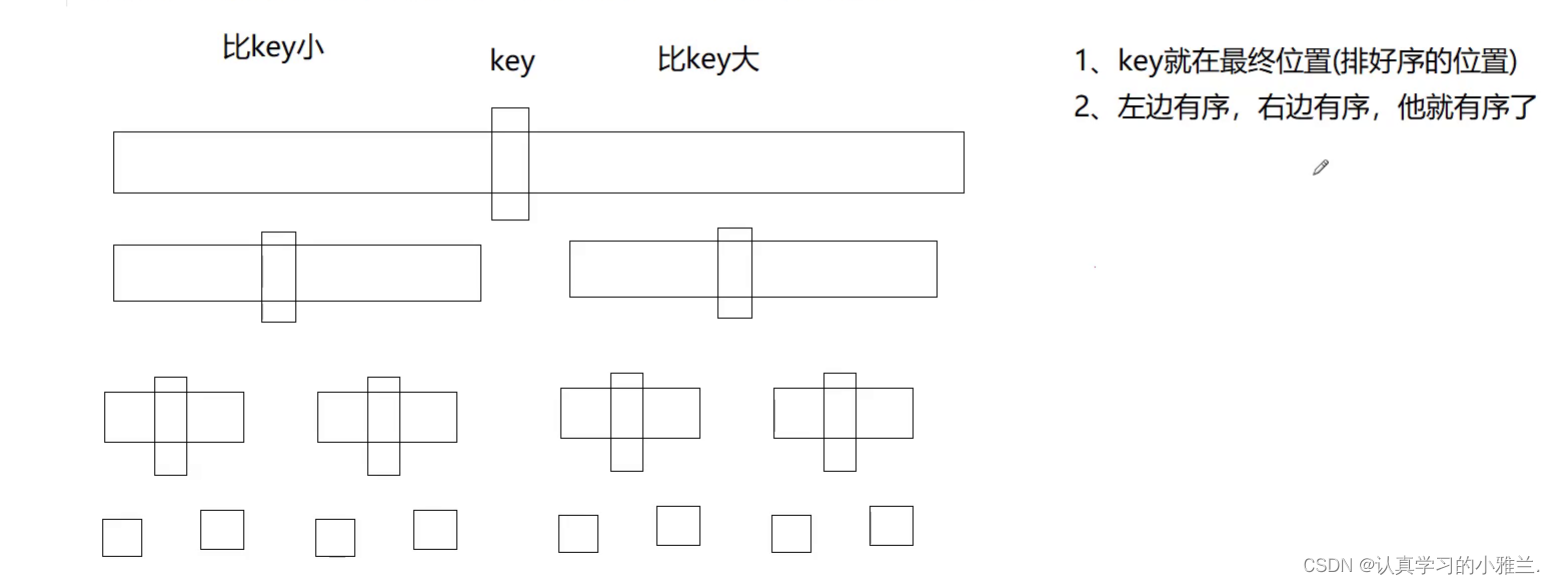
快速排序——“数据结构与算法”
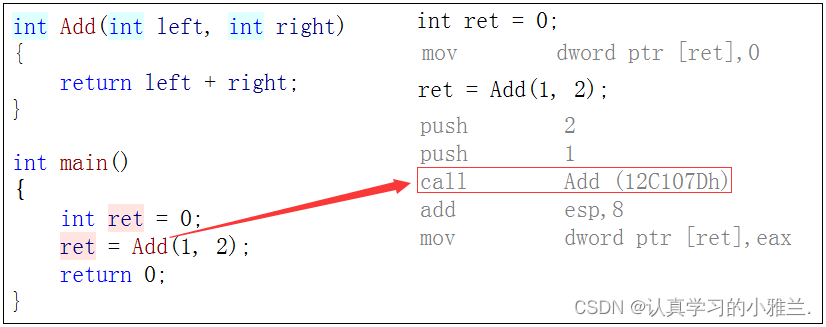
开发语言漫谈-C语言
初识C++(下)——“C++”
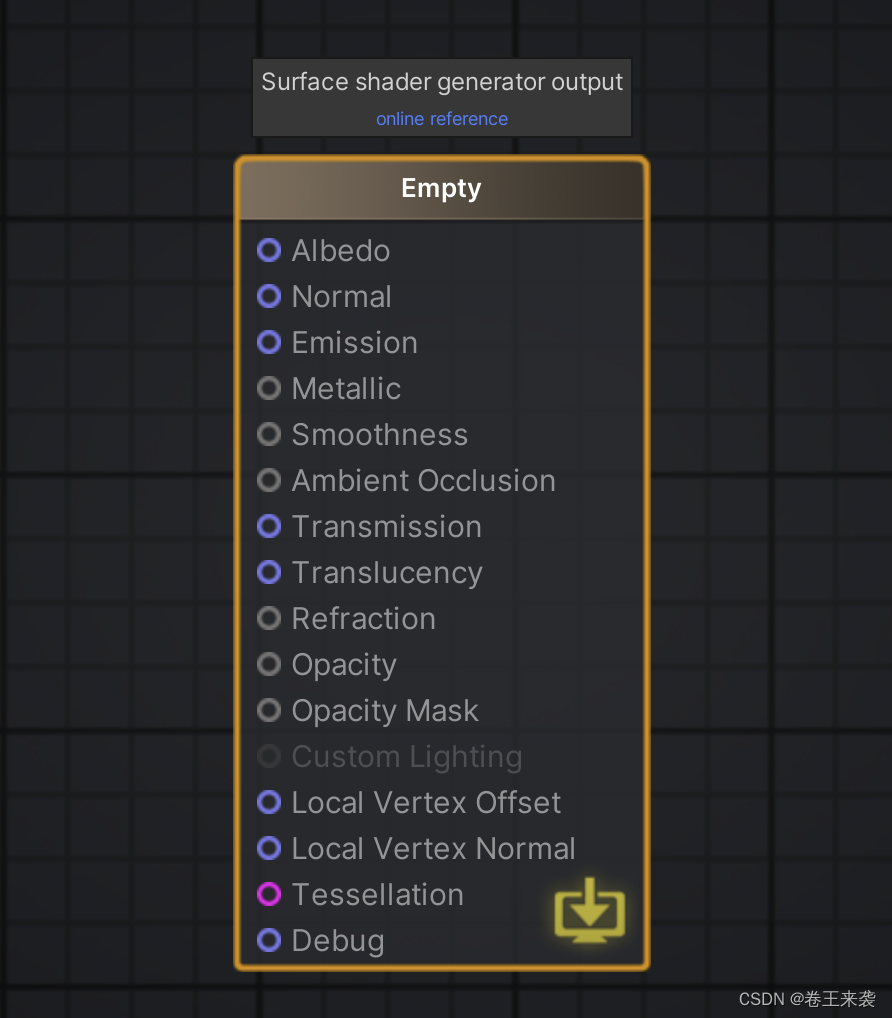
【Unity Shader#自定义材质面板_第一篇】
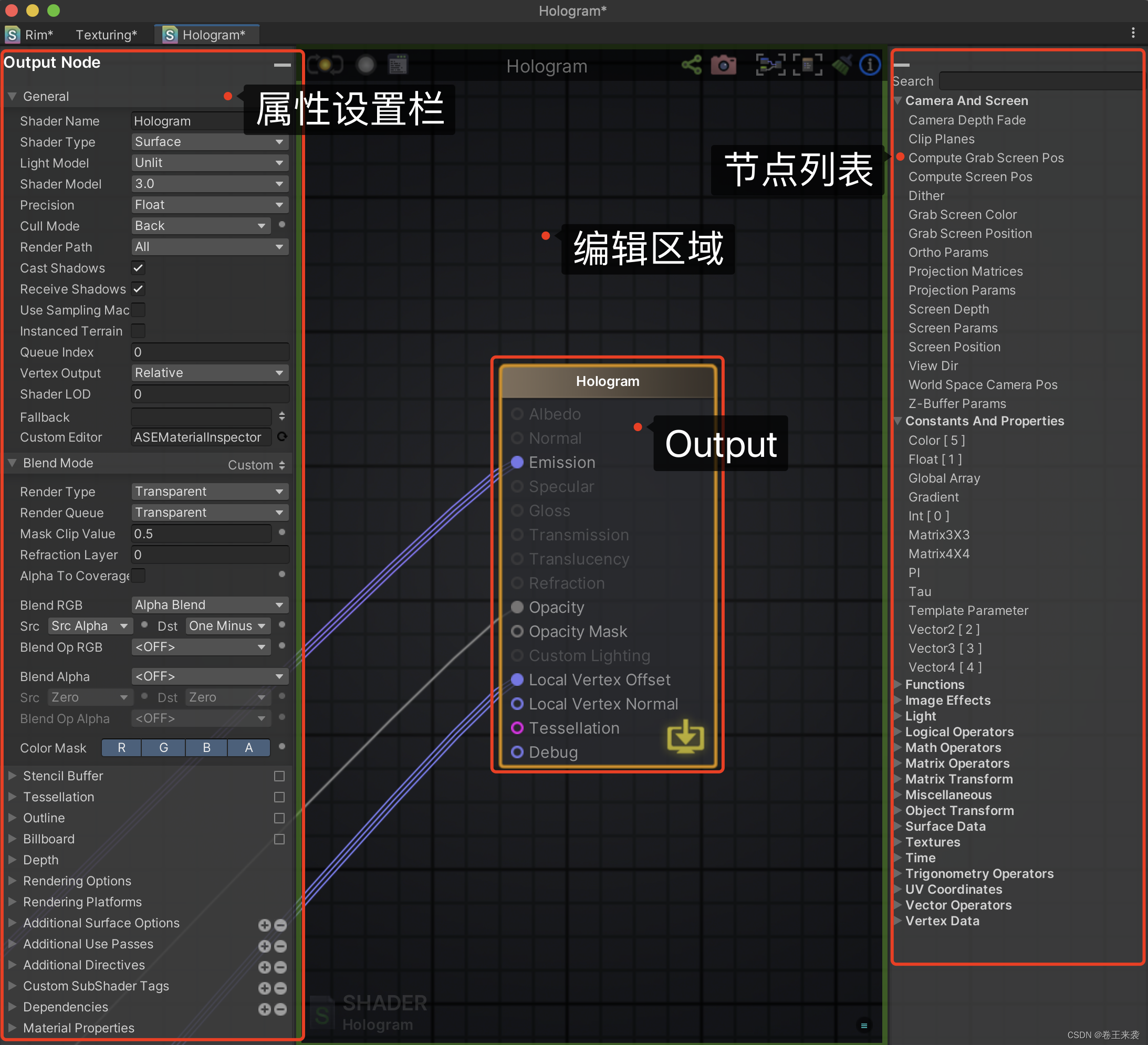
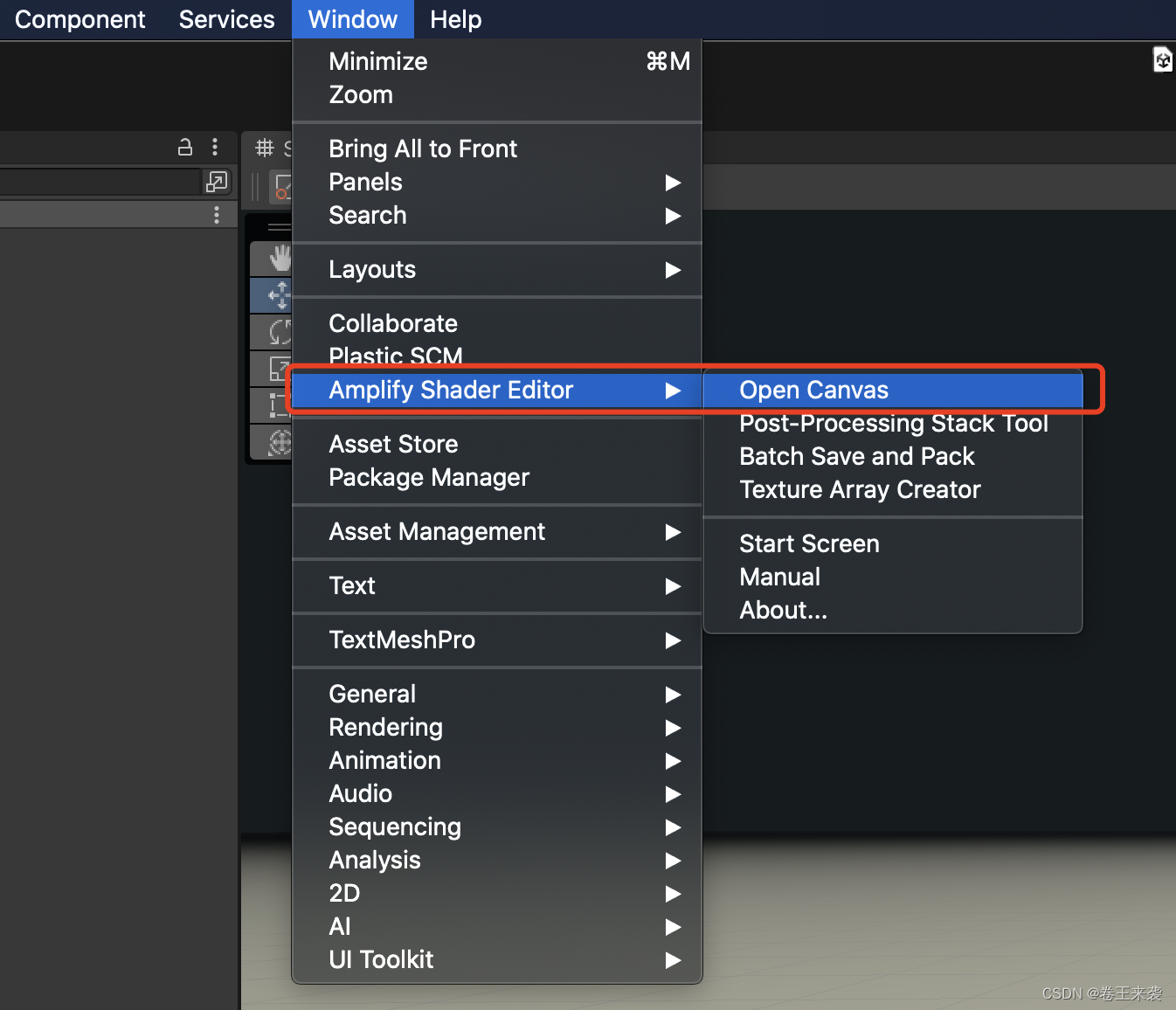
【#Unity Shader#Amplify Shader Editor(ASE)_第七篇】
阿里云服务器搭建部署宝塔详细流程
【#Unity Shader#Amplify Shader Editor(ASE)_第六篇】
Python并发编程模型:面试中的重点考察点
直接插入排序、希尔排序、直接选择排序、堆排序、冒泡排序——“数据结构与算法”
初识C++(上)——“C++”
【#Unity Shader#Amplify Shader Editor(ASE)_第五篇】
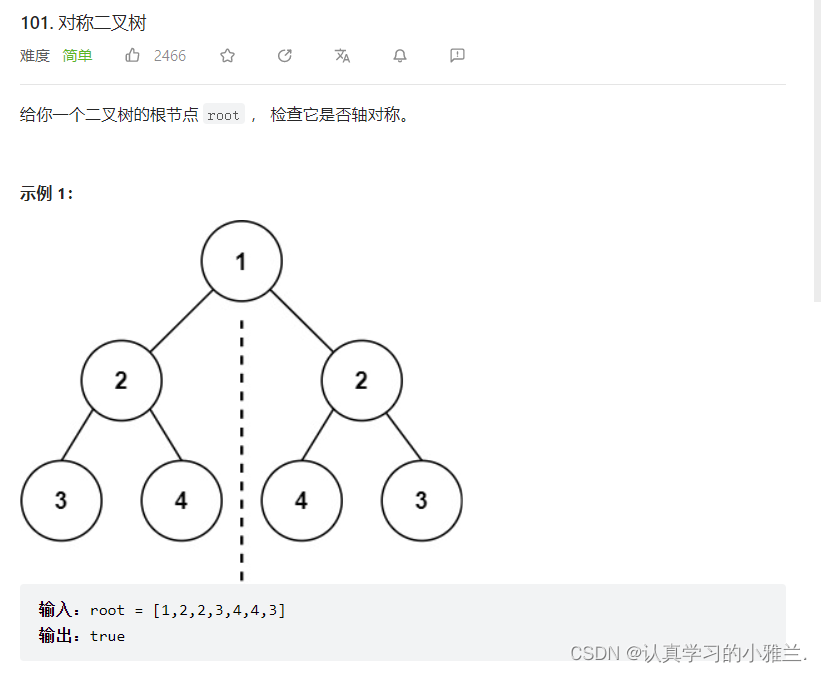
二叉树(下)+Leetcode每日一题——“数据结构与算法”“对称二叉树”“另一棵树的子树”“二叉树的前中后序遍历”
Python多线程、多进程与协程面试题解析
【#Unity Shader#Amplify Shader Editor(ASE)_第四篇】
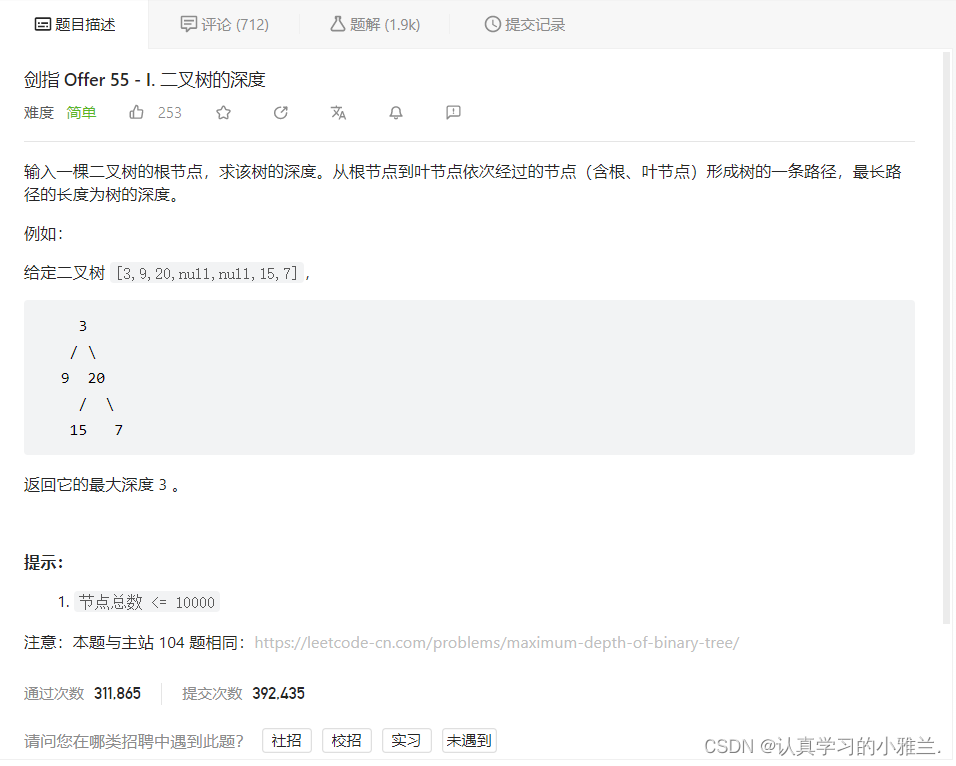
二叉树(中)+Leetcode每日一题——“数据结构与算法”“剑指Offer55-I. 二叉树的深度”“100.相同的树”“965.单值二叉树”
内存
默认值不一样【重点】
Linux权限管理
局部变量和成员变量
【#Unity Shader#Amplify Shader Editor(ASE)_第三篇】
Python装饰器与上下文管理器:面试详解
【#Unity Shader#Amplify Shader Editor(ASE)_第二篇】
Python函数式编程思想与面试实战
【#Unity Shader#Amplify Shader Editor(ASE)_第一篇】
二叉树(上)——“数据结构与算法”
Python模块化编程:面试题深度解析
有哪些数据结构与算法是程序员必须要掌握的?——“数据结构与算法”
掌握Python异常处理:面试中的关键考点
Python标准库知识问答:面试必备
堆排序+TopK问题——“数据结构与算法”
堆——“数据结构与算法”
在我掉入计算机的大坑并深陷其中时,一门名为“C语言”的编程语言让我沉迷
那年我头脑发热,选择了自动化,后来我掉入计算机的世界无法自拔
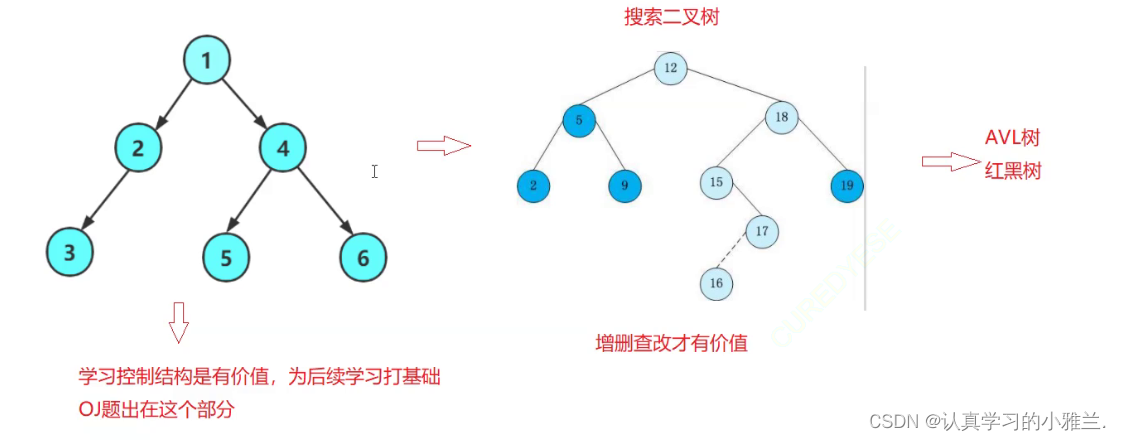
树——“数据结构与算法”
Python期末复习题库(下)——“Python”
Python高级特性解析与面试应对策略2
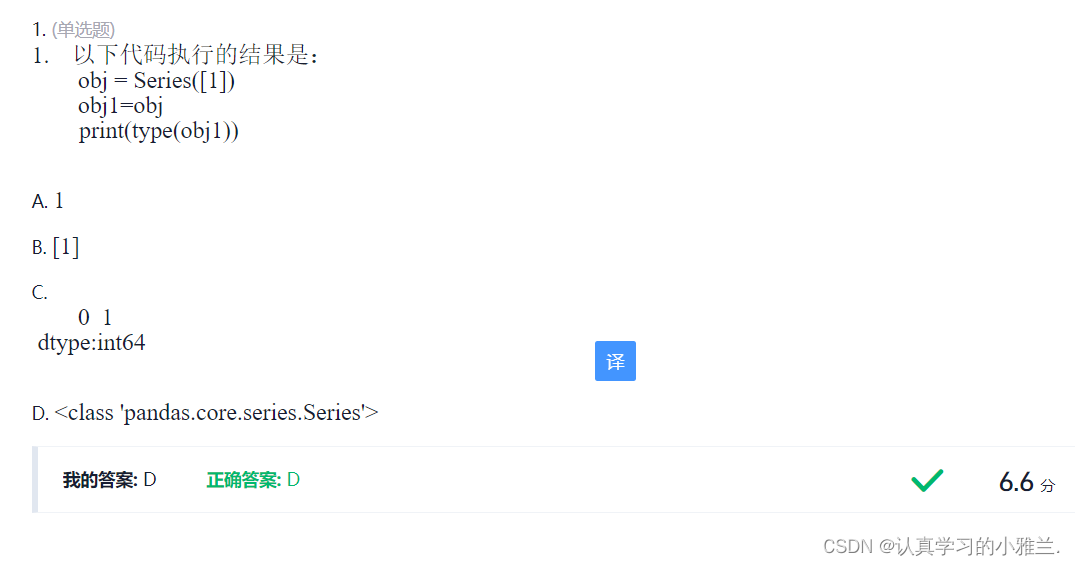
Python期末复习题库(上)——“Python”
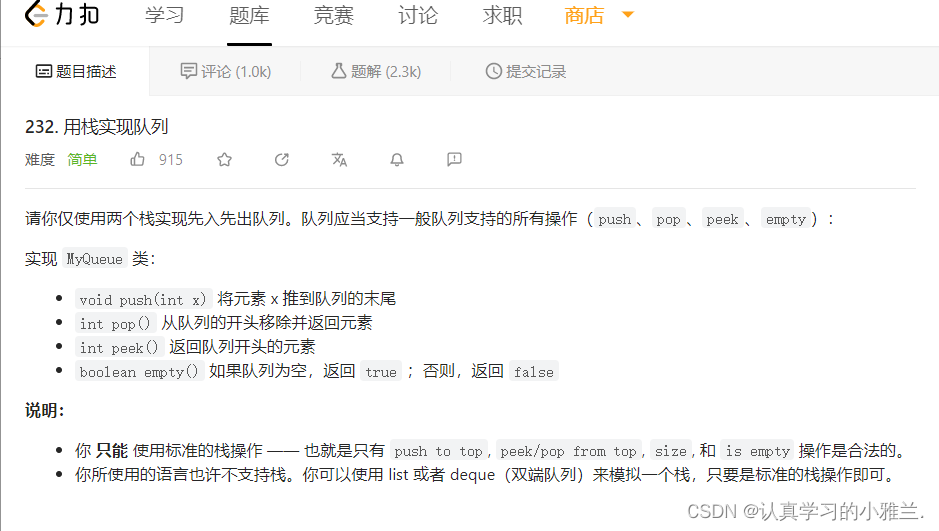
Leetcode每日一题——“用栈实现队列”
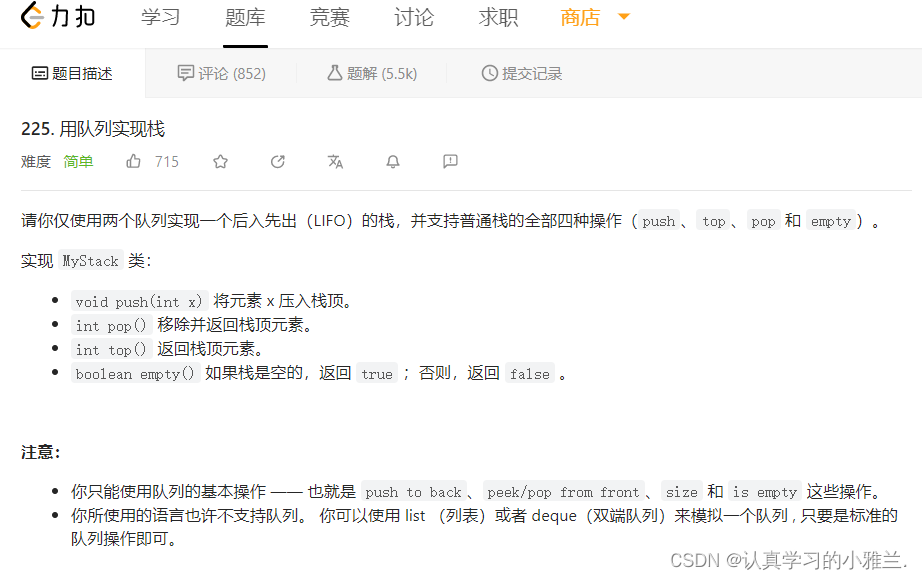
Leetcode每日一题——“用队列实现栈”
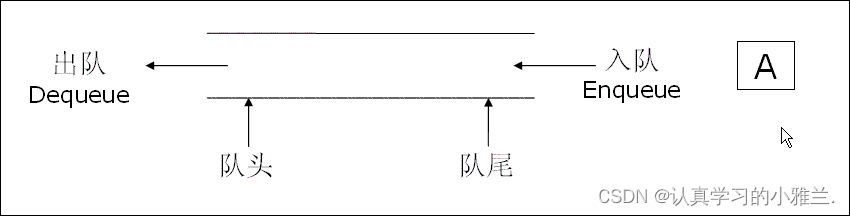
队列——“数据结构与算法”
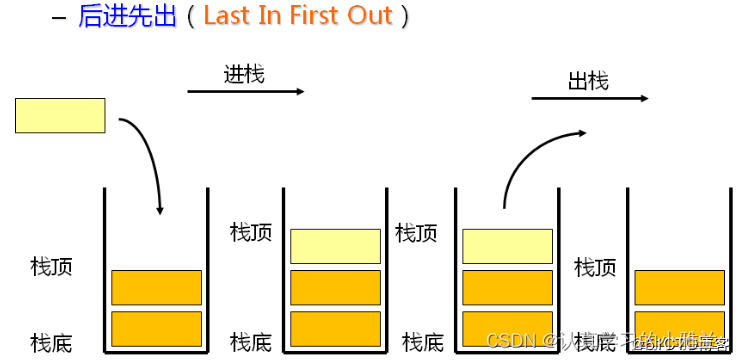
栈——“数据结构与算法”
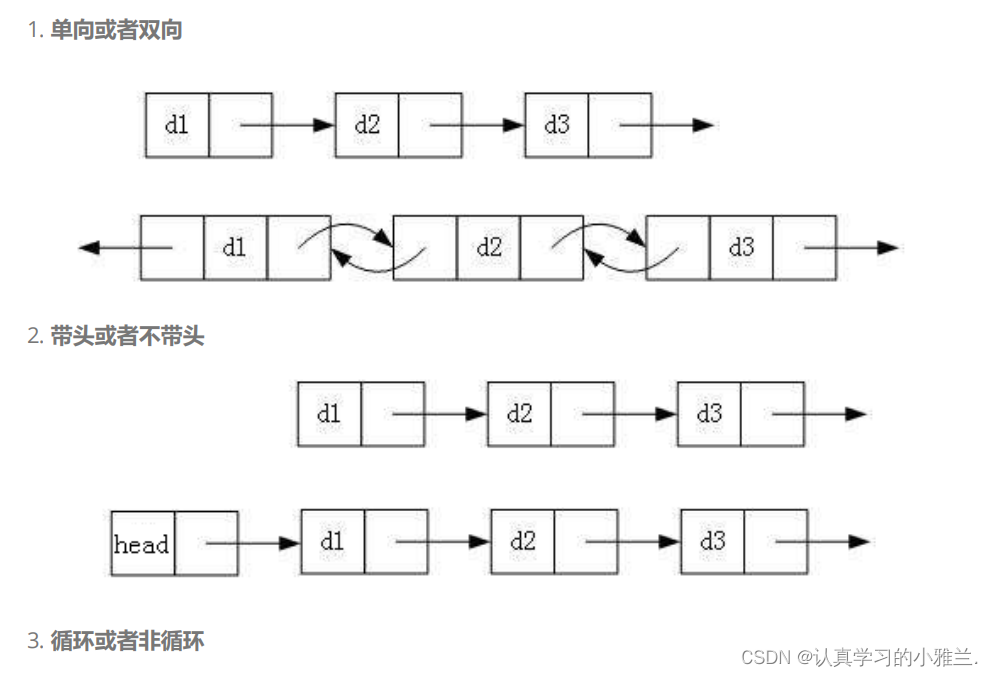
双链表——“数据结构与算法”
MySQL环境搭建——“MySQL数据库”
Spring IOC的源码解析
初识MySQL数据库——“MySQL数据库”
单链表——“数据结构与算法”
【微服务系列笔记】MQ消息可靠性
< 知识拓展:前端代码规范 >