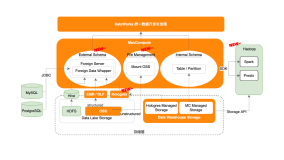
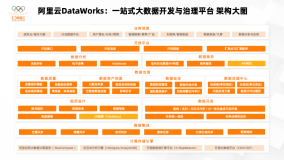
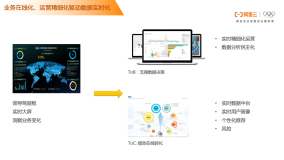
什么是大数据平台有三个疑问:
1.使用Cloudera或Hortonworks之类的Hadoop发行版本公司的提供的Hadoop套件,配置些参数,找几台服务器部署起来就算是一套大数据平台吗?
2.数据开发人员平时的工作是不是写些MR或者SQL任务,使用原生的命令行提交任务就可以了吗?
3.平台开发人员日常的工作是不是处理下集群的故障,给业务方扫盲,纠正各种框架组件使用姿势呢?
大数据平台个人理解:
是基于开源或自研组件的基础上创造更多的附件价值,提供给用户一个
完整的大数据业务解决方案,而不仅仅是做一个集群的维护者
大数据平台的价值
1.数据开发角度
一.降低数据开发门槛
二.提升数据开发人员效率
2.运维角度
一.降低运维门槛
二.提升运维效率
3.公司角度
一.数据统一管理(OneData理念),降低成本
大数据平台架构选型

离线计算:
1.Spark+SparkSQL
2.MR(Hadoop)+HiveSQL
离线数据同步:
1.DataX(Alibaba,开源支持单机版本)
- FlinkX(Dtstack,开源支持单机,standalone,yarn 模式)
- Sqoop(只能做Hadoop和关系型数据库之间的数据同步)
- Kettle
实时计算:
1.Flink
2.SparkStreaming
- Storm
- JStorm(Alibaba)
- StreamCQL(华为)
实时数据同步:
1.Flume
- Logstash(Elastic)
- JLogstash(Dtstack)
多维分析(即席查询):
1.Kylin
- SparkSQL+CarbonData
- Impala+Kudu 或Parquet
机器学习:
1.Spark MLib
- Flink MLib
- XGBoost
深度学习:
1.TensorFlow
- Caffe
- Keras
- Keras
资源管理器:
1.Yarn
- Mesos
- Kubernetes+Docker
集群管理:
1.Cloudera
2.星环
- Hortonworks
- Ambari