在上一篇文章中,我们讨论了单变量和多变量线性回归的Python实现方法。现在我们讲逻辑回归。大家要注意,如何克服过度拟合的问题,这将是讨论的重点。
基础知识
强烈建议你先看第3周的视频讲座,首先应该对Python系统有个基本的了解。在这里,我们将研究一个在业界最广泛应用的机器学习算法。
逻辑回归
在这部分练习中,你将建立一个逻辑回归模型来预测一个学生是否能被大学录取。
场景描述:
假设你是一个大学某系的招生负责人,想根据两门考试的成绩来确定每个申请者的录取概率。你有以前的历史数据,可以用它作为逻辑回归的训练数据集。对于每一个训练的例子,你有申请人两门考试的分数和相应的录取决策。你的工作是建立一个分类模型,然后根据这两门考试的成绩来预测申请者的录取概率。
首先要加载必需的库:
importnumpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt # more on this later
下一步,读入数据 (在第3周里找到)
data = pd.read_csv('ex2data1.txt', header = None)
X = data.iloc[:,:-1]
y = data.iloc[:,2]
data.head()
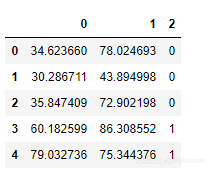
因此,我们有两个独立的特征和一个因变量。这里的“0”表示申请人不能被录取,而“1”则表示能被录取。
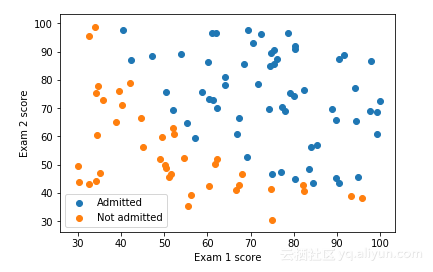
数据可视化
在开始执行任何学习算法之前,如果可能的话,最好一直进行数据的可视化工作。
mask = y == 1
adm = plt.scatter(X[mask][0].values, X[mask][1].values)
not_adm = plt.scatter(X[~mask][0].values, X[~mask][1].values)
plt.xlabel('Exam 1 score')
plt.ylabel('Exam 2 score')
plt.legend((adm, not_adm), ('Admitted', 'Not admitted'))
plt.show()
执行
在开始调用实际成本函数之前,请回想一下,逻辑回归的假设是利用了S形函数。让我们首先定义S形函数:
S型函数
def sigmoid(x):
return 1/(1+np.exp(-x))
请注意,我们在这里写的是向量化的代码。因此,x是个标量,也是个向量,还是个张量,其实并不重要。当然,编写和理解向量化的代码需要花费一些心思。不过,在去掉了循环部分之后,这会使代码更加的高效和通用。
成本函数
以下是我们实现逻辑回归成本函数的代码:
defcostFunction(theta, X, y):
J = (-1/m) * np.sum(np.multiply(y, np.log(sigmoid(X @ theta)))
+ np.multiply((1-y), np.log(1 - sigmoid(X @ theta))))
return J
请注意,我们在上面的成本函数中使用了S形函数。
有多种编程方法来实现成本函数,不过更重要的是底层的数学思想,还有我们把它转化成代码的能力。
梯度函数
def gradient(theta, X, y):
return ((1/m) * X.T @ (sigmoid(X @ theta) - y))
我们一定要注意,虽然这个梯度看起来与线性回归的梯度相同,然而实际上公式是不一样的,因为线性回归和逻辑回归有不同的假设函数定义。
以下是通过初始的参数来进行函数调用的代码。
(m, n) = X.shape
X = np.hstack((np.ones((m,1)), X))
y = y[:, np.newaxis]
theta = np.zeros((n+1,1)) # intializing theta with all zeros
J = costFunction(theta, X, y)
print(J)
上面的代码运行之后,会给我们J的输出值是0.693。
使用fmin_tnc来学习参数
在前面的任务中,我们通过执行梯度下降的算法来找到线性回归模型的最优参数,然后写了一个成本函数,并且计算了它的梯度,最后执行了梯度下降的操作步骤。这一次,我们不执行梯度下降步骤,而是从scipy库中调用了一个内置的函数fmin_tnc。
fmin_tnc是一个寻找非约束函数的最小值的优化求解函数。对于逻辑回归,你希望用参数theta来优化成本函数。优化中的约束经常是指对参数的约束。例如, theta可能取值的约束范围theta≤ 1。然而逻辑回归就没有这样的限制,因为theta是允许采取任何实际值的。
具体来说,在给定固定的数据集(X和y的值)的情况下,你将使用fmin_tnc来找到逻辑回归的成本函数的最佳或者最优的参数theta。将把以下的输入传递给fmin_tnc:
· 我们想要优化的参数初始值;
· 当给定训练集和特定theta值时,用来给数据集(X,y)计算theta值的逻辑回归成本和梯度的函数。
temp = opt.fmin_tnc(func = costFunction,
x0 = theta.flatten(),fprime = gradient,
args = (X, y.flatten()))
#the output of above function is a tuple whose first element #contains the optimized values of theta
theta_optimized = temp[0]
print(theta_optimized)
关于函数flatten()的注解:
不幸的是,SciPy的sfmin_tnc不能很好地使用行向量或者列向量,它期望的参数是数组形式的。flatten()函数将行向量或者列向量缩小到数组形式。
上面代码的运行结果应该是[-25.16131862, 0.20623159, 0.20147149]。
如果你正确地执行了costFunction函数,fmin_tnc将在正确的优化参数上进行收敛,并返回最终的theta值。值得注意的是,通过使用fmin_tnc,你不必自己编写任何循环程序,也不必像梯度下降那样设置一个学习率。这都是由fmin_tnc来完成的,你只需要提供一个函数来计算成本和梯度。
让我们使用这些优化了的theta值来计算成本。
J = costFunction(theta_optimized[:,np.newaxis], X, y)
print(J)
你会看到上面代码运行之后的输出值是0.203,这可以与使用初始的theta值获得的成本值0.693对比一下。
绘制决策边界
然后,这个最终的theta值将被用来绘制训练数据的决策边界,从而会得到一个类似于下面的图。
plot_x = [np.min(X[:,1]-2), np.max(X[:,2]+2)]
plot_y = -1/theta_optimized[2]*(theta_optimized[0]
+ np.dot(theta_optimized[1],plot_x))
mask = y.flatten() == 1
adm = plt.scatter(X[mask][:,1], X[mask][:,2])
not_adm = plt.scatter(X[~mask][:,1], X[~mask][:,2])
decision_boun = plt.plot(plot_x, plot_y)
plt.xlabel('Exam 1 score')
plt.ylabel('Exam 2 score')
plt.legend((adm, not_adm), ('Admitted', 'Not admitted'))
plt.show()
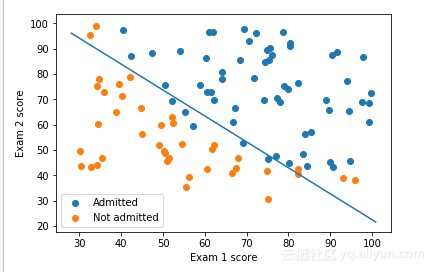
通过上面的结果,看起来我们的模型在区分那些被录取的和没有被录取的学生的方面做得非常好。接下来要量化模型的精度,我们将为这个模型编写一个称为accuracy的函数。
def accuracy(X, y, theta, cutoff):
pred = [sigmoid(np.dot(X, theta)) >= cutoff]
acc = np.mean(pred == y)
print(acc * 100)
accuracy(X, y.flatten(), theta_ans[0], 0.5)
运行之后,应该会输出一个结果为89%的精度值。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Python Implementation of Andrew Ng’s Machine Learning Course (Part 2.1)》
作者:Srikar
译者:奥特曼,审校:袁虎。
文章为简译,更为详细的内容,请查看原文
