Drill Storage Plugin介绍
Drill是一个交互式SQL查询引擎,官方默认支持的数据源有hive、hbase、kafka、kudu、mongo、opentsdb、jdbc等,其中jdbc storage plugin可以覆盖所有支持jdbc协议的数据源,如:mysql、oracle等关系型数据库。所有数据源的接入都是通过drill的storage plugin实现的,理论上Drill通过storage plugin机制可以支持对任何数据源进行异构查询。
Drill作为一个SQL查询引擎,它跟传统数据库有着很多相似之处,主要包括SQL Parser、SQL Validator、Query Optimizer、Data Flow Operators等几部分。如下图所示,SQL Parser阶段会把SQL语句解析为SQL查询语法树,这个阶段Storage Plugin没有介入。 从SQL Valiator阶段Storage Plugin开始介入,在这个阶段会通过Storage Plugin获取Schema信息对SQL进行校验,如判断表、字段是否存在等。Query Optimzer阶段会把SqlNode转换为PhysicalPlan,在这个过程中会通过Storage Plugin获取Planner Rule对SQL进行优化。Data Flow Operators阶段是对目标数据源进行数据读取,这部分操作是通过Storage Plugin的RecordReader实现的。
Drill Storage Plugin加载机制
DrillBit为drill的主类,drill启动时会自动加载所有有效的Storage Plugin,加载时序图如图2所示。

Plugin的注册主要是在类StoragePluginRegistryImpl中完成,插件注册主要分为以下几步。
第一步是加载classpath下所有drill-module.conf文件,这个文件配置了需要扫描的包路径,在这个包路径下接口StoragePlugin所有实现类都会被加载;第二步是校验,首先校验的是接口StoragePlugin的实现类的构造方法是否符合标准要求,构造方法参数必须为3个,且三个参数的类型必须分别为StoragePluginConfig,DrillbitContext、String。其次是校验plugin的配置是否有效,加载plugin配置,如果是首次启动,会读取classpath下bootstrap-storage-plugins.json文件,每个plugin都会对应一个这样的json文件。这个json文件最终会反序列为StoragePluginConfig实现类对象。非首次启动bootstrap-storage-plugins.json文件不会被加载。drill会以本地/tmp/drill/sys.storage_plugins目录下配置文件为准,集群模式配置信息保存在zookeeper /drill/sys.storage_plugins目录下。第三步是通过发射的方式进行插件实例化并注册。整个Plugin的注册流程如图 3所示

Drill查询流程分析
在正式介绍Drill Storage Plugin开发实战之前我们先了解下Drill的查询流程,这样有助于对Storage Plugin进行深入理解,而不是简单的依葫芦画瓢。Drill是分布式的,并且节点之间是对等的,所有drill节点都可以对外提供服务,当节点接收到sql查询请求之后,在UserWorker中会拉起一个Foreman线程来单独处理这个请求,Foreman会完成sql到物理执行计划的转换,并根据物理执行计划切分成可并行执行的Fragment,Foreman根据一定的算法把Fragment分发到本机或者其他drill节点进行执行,执行完之后会在接收初始请求的Drill节点中进行结果合并,然后返回给客户端。如图4 所示。

一条SQL到物理执行计划,会经过SqlNode(sql节点解析树)、RelNode(关系表达式)、DrillRel(drill关系表达式)、Prel(物理关系表达式)、PhysicalPlan(物理执行计划)几个步骤的转换。如图 5所示

SqlNode、RelNode、DrillRel、Prel都是树形结构,以一条简单查询druid数据源的SQL为例,SQL->SqlNode->RelNode这两个阶段只会存在节点之间的转换,不会考虑目标数据源之间的差异进行SQL优化和改写之类的动作。RelNode->DrilRel节点会进行逻辑执行计划的优化,示例中对filter进行了下推操作。DrillRel->Prel节点会进行物理执行计划的优化。 各阶段文本化之后如下所示。
原始SQL
select * from hbase.staff t1 where row_key='10000'RelNode(关系表达式节点树),有3个节点分别为LogicalProject、LogicalFilter、EnumerableTableScan
LogicalProject(row_key=[$0], f1=[$1])
LogicalFilter(condition=[=($0, '10000')])
EnumerableTableScan(table=[[hbase, staff]])DrillRel(Drill关系表达式节点树),转换为drill中关系表达式节点
DrillScreenRel
DrillFilterRel(condition=[=($0, '10000')])
DrillScanRel(table=[[hbase, staff]], groupscan=[HBaseGroupScan [HBaseScanSpec=HBaseScanSpec [
tableName=staff, startRow=null, stopRow=null, filter=null], columns=[`row_key`, `f1`, `**`]]])Prel(物理关系表达式节点树),这一步应用了物理优化规则,把filter下推到scan里面了
ScreenPrel
ProjectPrel(row_key=[$0], f1=[$1])
ScanPrel(groupscan=[HBaseGroupScan [HBaseScanSpec=HBaseScanSpec [
tableName=staff, startRow=10000, stopRow=10000\x00, filter=null], columns=[`row_key`, `f1`, `**`]]])Drill Storage Plugin开发实战
经过前面的介绍,大家对Drill Storage Plugin作用与原理应该已经有一个比较全面的了解。接下来以hbase为例详细介绍drill storage plugin开发流程。 Hbase是一个分布式列存数据库,默认是不支持SQL查询的。为了实现在Drill中用SQL对Hbase进行异构查询,需要实现一个Hbase的storage plugin。 下面以Hbase storage plugin为例介绍storage plugin的开发流程。
1、在目录contrib新建mvn模块,如: stroage-hbase
2、在新建的模块resource目录新建两个文件drill-module.conf和bootstrap-storage-plugins.json。drill-module.conf定义plugin所在的包路径,在plugin加载的时候会用到。bootstrap-storage-plugins.json文件是一些必要连接Hbase的配置。Drill首次启动时会用这个文件作为Plugin的初始配置。
{
"type": "hbase",
"config": {
"hbase.zookeeper.quorum": "172.168.1.100",
"hbase.zookeeper.property.clientPort": "2181"
},
"size.calculator.enabled": false,
"enabled": true
}3、修改UserBitShared.proto文件,在CoreOpertorType对象里面新增一行HBASE_SUB_SCAN = 33,33这个数字需根据自身实际情况进行递增。修改proto文件之后需要重新编译,具体参考protocol模块下的readme.txt
4、修改distribution模块下的bin.xml, 新增org.apache.drill.contrib:drill-hbase-storage
5、代码实现,部分代码剖析如下
HbaseStoragePlugin: 相当于plugin的总入口,对scheme进行注册,加载插件配置,指定优化规则等
public class HBaseStoragePlugin extends AbstractStoragePlugin {
private static final HBaseConnectionManager hbaseConnectionManager = HBaseConnectionManager.INSTANCE;
private final HBaseStoragePluginConfig storeConfig;
private final HBaseSchemaFactory schemaFactory;
private final HBaseConnectionKey connectionKey;
private final String name;
//构造方法,参数必须是3个,且类型需要匹配
public HBaseStoragePlugin(HBaseStoragePluginConfig storeConfig, DrillbitContext context, String name)
throws IOException {
super(context, name);
this.schemaFactory = new HBaseSchemaFactory(this, name);
this.storeConfig = storeConfig;
this.name = name;
this.connectionKey = new HBaseConnectionKey();
}
//注册schema
@Override
public void registerSchemas(SchemaConfig schemaConfig, SchemaPlus parent) throws IOException {
schemaFactory.registerSchemas(schemaConfig, parent);
}
//添加物理优化规则
@Override
public Set<StoragePluginOptimizerRule> getPhysicalOptimizerRules(OptimizerRulesContext optimizerRulesContext) {
return ImmutableSet.of(HBasePushFilterIntoScan.FILTER_ON_SCAN, HBasePushFilterIntoScan.FILTER_ON_PROJECT);
}
}HbaseStoragePluginConfig: Plugin配置,参数与bootstrap-storage-plugins.json对应
HBaseSchemaFactory: Schema工厂,Schema相当于一个表元数据,包括表名、字段、以及字段类型等信息
public class HBaseSchemaFactory extends AbstractSchemaFactory {
//注册schema,schema是有层级,查询时每层之间用.分隔
@Override
public void registerSchemas(SchemaConfig schemaConfig, SchemaPlus parent) throws IOException {
HBaseSchema schema = new HBaseSchema(getName());
SchemaPlus hPlus = parent.add(getName(), schema);
schema.setHolder(hPlus);
}
class HBaseSchema extends AbstractSchema {
HBaseSchema(String name) {
super(Collections.emptyList(), name);
}
// hbase schema只有一层
@Override
public AbstractSchema getSubSchema(String name) {
return null;
}
@Override
public Table getTable(String name) {
HBaseScanSpec scanSpec = new HBaseScanSpec(name);
try {
return new DrillHBaseTable(getName(), plugin, scanSpec);
} catch (Exception e) {
// Calcite firstly looks for a table in the default schema, if the table was not found,
// it looks in the root schema.
// If the table does not exist, a query will fail at validation stage,
// so the error should not be thrown here.
logger.warn("Failure while loading table '{}' for database '{}'.", name, getName(), e.getCause());
return null;
}
}
//调用hbase提供api,获取表信息
@Override
public Set<String> getTableNames() {
try(Admin admin = plugin.getConnection().getAdmin()) {
HTableDescriptor[] tables = admin.listTables();
Set<String> tableNames = Sets.newHashSet();
for (HTableDescriptor table : tables) {
tableNames.add(new String(table.getTableName().getNameAsString()));
}
return tableNames;
} catch (Exception e) {
logger.warn("Failure while loading table names for database '{}'.", getName(), e.getCause());
return Collections.emptySet();
}
}
@Override
public String getTypeName() {
return HBaseStoragePluginConfig.NAME;
}
}
}
public abstract class AbstractHBaseDrillTable extends DrillTable {
protected HTableDescriptor tableDesc;
public AbstractHBaseDrillTable(String storageEngineName, StoragePlugin plugin, Object selection) {
super(storageEngineName, plugin, selection);
}
//字段类型转换,把hbase中的字段类型映射为SQL类型
@Override
public RelDataType getRowType(RelDataTypeFactory typeFactory) {
ArrayList<RelDataType> typeList = new ArrayList<>();
ArrayList<String> fieldNameList = new ArrayList<>();
fieldNameList.add(ROW_KEY);
typeList.add(typeFactory.createSqlType(SqlTypeName.ANY));
Set<byte[]> families = tableDesc.getFamiliesKeys();
for (byte[] family : families) {
fieldNameList.add(Bytes.toString(family));
//family映射为map结构
typeList.add(typeFactory.createMapType(typeFactory.createSqlType(SqlTypeName.VARCHAR), typeFactory.createSqlType(SqlTypeName.ANY)));
}
return typeFactory.createStructType(typeList, fieldNameList);
}
}HbaseSubScan: 关系表达式的叶子节点,目标数据源能够识别的查询语言会在这里面定义
HbaseGroupScan: SubScan的一个超集
HbaseScanBatchCreator:根据节点泛型HbaseSubScan反射获取,获取HbaseSubScan参数并创建HbaseRecordReader对象
HbaseRecordReader:实现对目标数据源的进行记录读取,setup方法是在读取记录之前进行一些初始化工作, next方法中会调用hbase的api获取数据并放入OutputMutator对象中。
Rule: drill的优化规则,可用在逻辑计划、物理计划等优化阶段
实现一个Storage Plugin主要难点是在如何实现优化规则,where条件、聚合函数、分组、排序等是否可以下推都是由优化规则决定。下面以一个where条件下推为例介绍如何实现一个Rule。如图7所示,Filter经过下推转换为一颗 等价的查询树

Drill中优化规则很多,所有规则都是StoragePluginOptimizerRule类的子类,在进行逻辑计划和物理计划优化时并不是所有规则都会应用,只有匹配上的规则才会应用。匹配策略分两级,一级匹配比较粗略,只要查询节点树最小子树与规则类的构造放中操作类型class匹配就算匹配。如图7左边圈中部分和图8圈中部分所示。二级匹配是在matches方法,返回true才会执行onMatch方法进行关系表达式等价转换,这个方法默认是返回true,需要根据实际情况决定是否重写。在这个列子中我们进一步判断GroupScan是否是HbaseGroupScan实例,也就是说只有查询Hbase数据源的查询才会匹配这个规则。这里要说明一点的是,你在其中一个Storage Plugin中写的规则,对其他Storage Plugin来说都是可以使用的。
public abstract class HBasePushFilterIntoScan extends StoragePluginOptimizerRule {
private HBasePushFilterIntoScan(RelOptRuleOperand operand, String description) {
super(operand, description);
}
//FilterPrel.class、ScanPrel.class与图6圈中的部分匹配
public static final StoragePluginOptimizerRule FILTER_ON_SCAN =
new HBasePushFilterIntoScan(RelOptHelper.some(
FilterPrel.class, RelOptHelper.any(ScanPrel.class)), "HBasePushFilterIntoScan:Filter_On_Scan") {
@Override
public void onMatch(RelOptRuleCall call) {
final ScanPrel scan = (ScanPrel) call.rel(1);
final FilterPrel filter = (FilterPrel) call.rel(0);
final RexNode condition = filter.getCondition();
HBaseGroupScan groupScan = (HBaseGroupScan)scan.getGroupScan();
if (groupScan.isFilterPushedDown()) {
/*
* The rule can get triggered again due to the transformed "scan => filter" sequence
* created by the earlier execution of this rule when we could not do a complete
* conversion of Optiq Filter's condition to HBase Filter. In such cases, we rely upon
* this flag to not do a re-processing of the rule on the already transformed call.
*/
return;
}
doPushFilterToScan(call, filter, null, scan, groupScan, condition);
}
//二级匹配
@Override
public boolean matches(RelOptRuleCall call) {
final ScanPrel scan = (ScanPrel) call.rel(1);
//hbase数据源才会匹配
if (scan.getGroupScan() instanceof HBaseGroupScan) {
return super.matches(call);
}
return false;
}
};
protected void doPushFilterToScan(final RelOptRuleCall call, final FilterPrel filter, final ProjectPrel project, final ScanPrel scan, final HBaseGroupScan groupScan, final RexNode condition) {
final LogicalExpression conditionExp = DrillOptiq.toDrill(new DrillParseContext(PrelUtil.getPlannerSettings(call.getPlanner())), scan, condition);
final HBaseFilterBuilder hbaseFilterBuilder = new HBaseFilterBuilder(groupScan, conditionExp);
final HBaseScanSpec newScanSpec = hbaseFilterBuilder.parseTree();
if (newScanSpec == null) {
return; //no filter pushdown ==> No transformation.
}
final HBaseGroupScan newGroupsScan = new HBaseGroupScan(groupScan.getUserName(), groupScan.getStoragePlugin(),
newScanSpec, groupScan.getColumns());
newGroupsScan.setFilterPushedDown(true);
//filter下推至scan中
final ScanPrel newScanPrel = ScanPrel.create(scan, filter.getTraitSet(), newGroupsScan, scan.getRowType());
// Depending on whether is a project in the middle, assign either scan or copy of project to childRel.
final RelNode childRel = project == null ? newScanPrel : project.copy(project.getTraitSet(), ImmutableList.of(newScanPrel));
if (hbaseFilterBuilder.isAllExpressionsConverted()) {
/*
* Since we could convert the entire filter condition expression into an HBase filter,
* we can eliminate the filter operator altogether.
*/
call.transformTo(childRel);
} else {
call.transformTo(filter.copy(filter.getTraitSet(), ImmutableList.of(childRel)));
}
}
}
效果演示
演示数据准备,表staff包含一个列簇f1, 数据详细信息如下
| row_key | f1:name | f1:sex | f1:age |
|---|---|---|---|
| 10000 | 张三 | 男 | 18 |
| 10001 | 李四 | 男 | 28 |
| 10002 | 王五 | 男 | 38 |
演示SQL 1
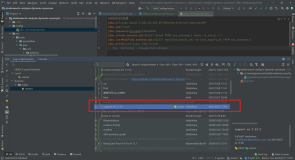
select * from hbase.staff t1 where row_key='10000'结果1

从上图结果可看出,同一个列簇f1是在同一个字段显示的,并且是一个json格式,列值都是经过编码的,这些结果的输出形式都是在HbaseRecordReader类中指定的,在类HbaseRecordReader中指定了row_key的输出类型为VarBinary, 列簇的输出类型为Map,Map中value为VarBinary类型。如果想要个列单独显示,SQL可以按以下方式书写。
演示SQL 2
select cast(row_key as varchar) row_key,
cast(t1.f1.name as varchar) name,
cast(t1.f1.sex as varchar) sex,
cast(t1.f1.age as varchar) age
from hbase.staff t1 limit 10结果2

演示SQL 3
按列条件查询
select cast(row_key as varchar) row_key,
cast(t1.f1.name as varchar) name,
cast(t1.f1.sex as varchar) sex,
cast(t1.f1.age as varchar) age
from hbase.staff t1 where t1.f1.name='张三'结果3

小结
本文对Drill SQL查询流程、Storage Plugin加载机制、以及Storage Plugin实现原理进行了分析。 希望对读者自己实现一个Storage Plugin有所帮助