网易云音乐
本文的总体思路如下:
找到正确的URL,获取源码;
利用bs4解析源码,获取歌曲名和歌曲ID;
调用网易云歌曲API,获取歌词;
将歌词写入文件,并存入本地。
本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
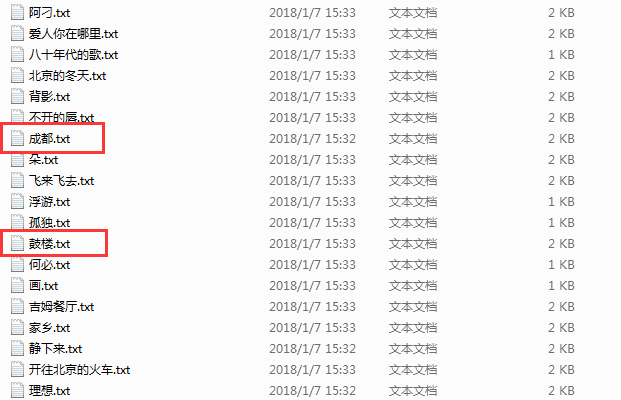
赵雷的歌曲
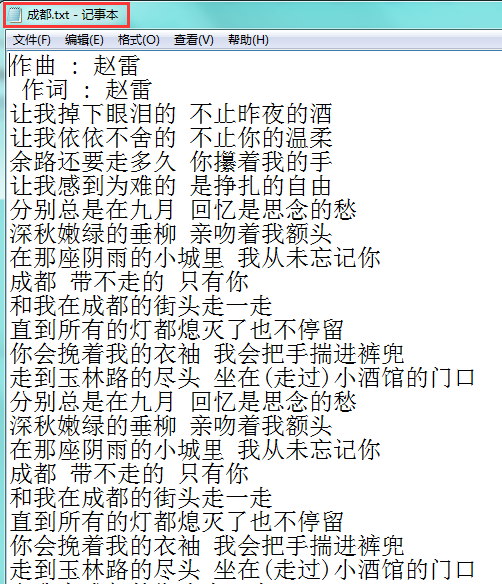
赵雷歌曲---《成都》
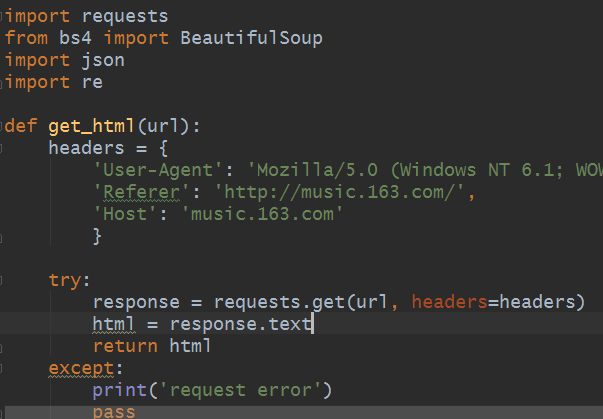
获取网页源码
获取到网页源码之后,分析源码,发现歌曲的名字和ID藏的很深,纵里寻她千百度,发现她在源码的294行,藏在<ul class="f-hide">标签下,如下图所示:

歌曲名和ID存在的位置
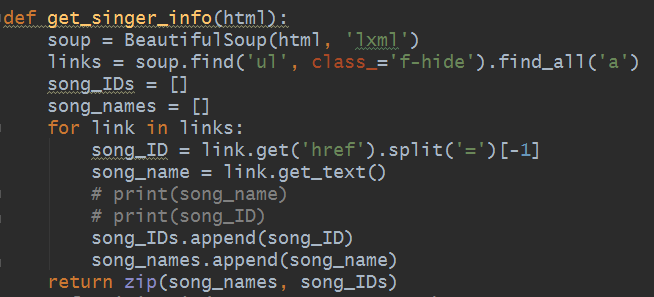
获取歌曲名和ID
得到ID之后便可以进入到内页获取歌词了,但是URL还是不给力,如下图:
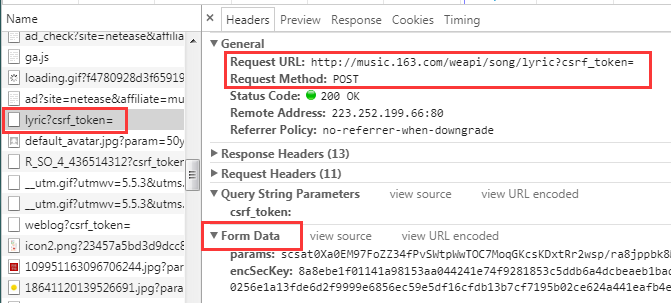
歌词的URL
莫慌,小编找到了网易云音乐的API,只要把歌曲的ID放在API链接上便可以获取到歌词了,代码如下:
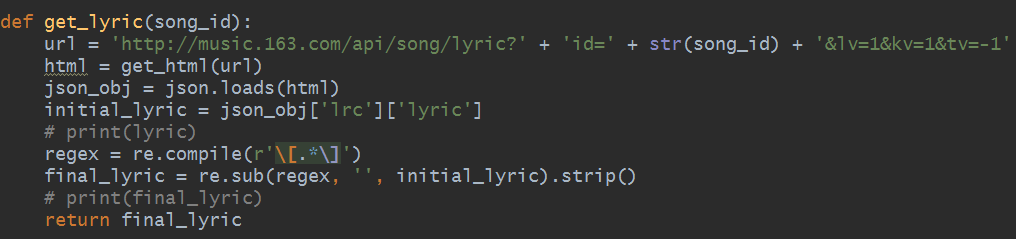
调用网易云API并解析歌词
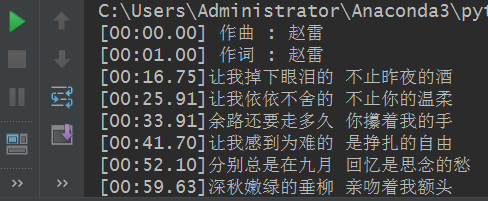
原始数据
得到歌词之后便将其写入到文件中去,并存入到本地文件中,代码如下:
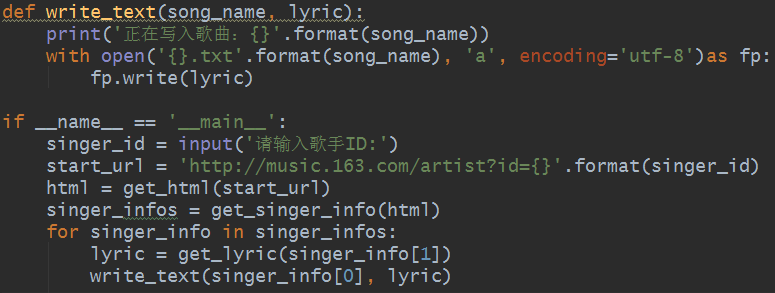
写入文件和程序主体部分
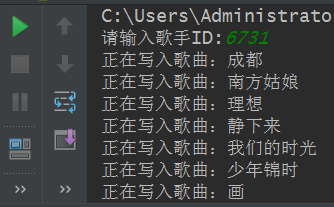
程序运行结果
相信大家对网易云歌词爬取已经有了一定的认识了,不过easier said than down,小编建议大家动手亲自敲一下代码,在实践中你会学的更快,学的更多的。
这篇文章教会大家如何采集网易云歌词,那网易云歌曲如何采集呢?且听小编下回分解~~~
为了给大家创建一个良好的Python学习环境,小编为大家创建了一个Python学习交流扣扣群,181125776,进群的验证码是:小王子,欢迎大家的加入~~
欢迎拍砖, _祝大家周末愉快 _