


京东(http://JD.com)是中国最大的自营式电商企业,2015年第一季度在中国自营式B2C电商市场的占有率为56.3%。如此庞大的一个电商网站,上面的商品信息是海量的,小编今天就带小伙伴利用正则表达式,并且基于输入的关键词来实现主题爬虫。
首先进去京东网,输入自己想要查询的商品,小编在这里以关键词“狗粮”作为搜索对象,之后得到后面这一串网址:https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其实参数%E7%8B%97%E7%B2%AE解码之后就是“狗粮”的意思。那么非常明显,只要输入keyword这个参数之后,将其进行编码,就可以获取到我们的目标网址了,请求网页,得到响应,尔后利用选择器便可以进行下一步的精准采集了。
在京东网上,狗粮信息在京东官网上的网页源码如下图所示:

话不多说,直接撸代码,如下图所示。小编用的是py3,也建议大家以后多用py3版本。通常URL编码的方式是把需要编码的字符转化为%xx的形式,一般来说URL的编码是基于UTF-8的,当然也有的于浏览器平台有关。在Python的urllib库中提供了quote方法,可以实现对URL的字符串进行编码,从而可以进入到对应的网页中去。
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是一种可以用于模式匹配和替换的强有力的工具。找到目标网页之后,调用urllib中的urlopen函数打开网页并获取源码,之后利用正则表达式实现对目标信息的精准采集。
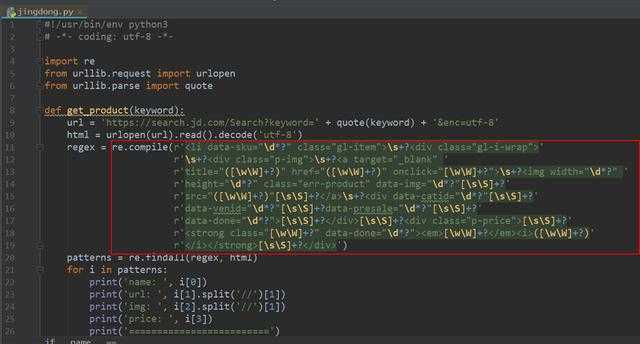
正则表达式写在这个程序中确实蛮复杂的,也占据了多行,但是主要用到的正则表达式是[wW]+?和[sS]+?。
[sS]或者[wW]是完全通配的意思,s是指空白,包括空格、换行、tab缩进等所有的空白,而S刚好相反。这样一正一反下来,就表示所有的字符,完全的,一字不漏的。另外,[]这个符号,表示在它里面包含的单个字符不限顺序的出现,比如下面的正则:[ace]*,这表示,只要出现a/c/e这三个任意的字母,都会被匹配。
此外,[s]表示,只要出现空白就匹配;[S]表示,非空白就匹配。那么它们的组合,表示所有的都匹配,与它相对应的,有[wW]等,意义完全相同。其实,[sS] 和 [wW]这样的用法,比"."所匹配的还要多,因为"."是不会匹配换行的,所有出现有换行匹配的时候,人们就习惯 使用[sS]或者[wW]这样的完全通配模式。
最后得到的输出效果图如下所示:
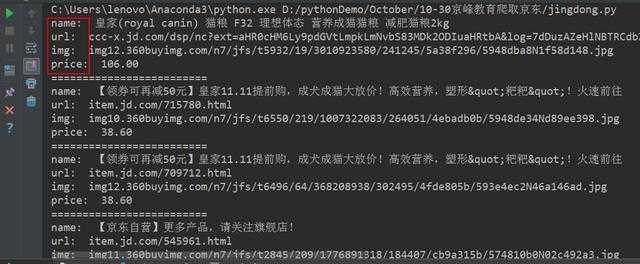
这样小伙伴们就可以获取到狗粮的商品信息了,当然,小编在这里只是抛砖引玉,只匹配了四个信息,而且只是做了个单页的获取。需要更多数据的小伙伴们可以自行去更改正则表达式和设置多页,达到你想要的效果。下篇文章小编将利用美丽的汤BeautifulSoup来进行匹配目标数据,实现目标信息的精准获取。
最后给大家简单介绍一下正则表达式。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
正则表达式对于初学者确实晦涩难懂,不过慢慢学习还是可以掌握的,并不一定要完全记下来,但是你要知道什么时候需要什么参数,能做到顺利使用它就可以了。




