了解过HashMap都应该知道,HashMap内部会创建一个Entry<K, V> table数组来存放元素,而且这个数组的长度永远都是2的指数次方。那么问题来了,为什么选择2的指数次方呢?
首先,思考一下计算出hash值后,应该存放在数组的哪个位置?显然用求余(模)最简单。然而模的效率并不高,看看JDK是怎么做的,indexFor方法:
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
其中h就是hash值,length是table的长度。对2的指数次方求模运算(h % length)和h & (length-1)结果是一样的,这点从代码注释也可以知道,不明白可以看最后的备注。
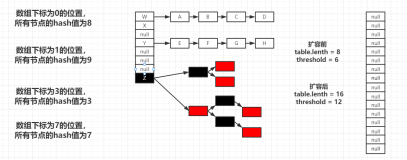
接着看看为什么容量是2的指数次方的问题,假如容量分别是16和15两种情况,对应的length-1的二进制分别是1111和1110,然后我们思考hash值分别是8和9这两种情况,8 & 1111 = 8,9 & 1111 = 9,存放在table[8]和table[9]对应的位置,没有发生碰撞;然后8 & 1110 = 8,9 & 1110 = 8,两个hash值都被存放在了table的同一位置,显然发生了碰撞。放大来看,如果容量是15的话,length - 1对应的二进制是1110,进行与运算后,最后一位永远是0,即xxx0,这将会导致table中0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费不说,碰撞概率也增大。而我们2的指数次方对应的数length-1后二进制全是1,进行与运算显然不会干扰到原hash值,不会导致table中哪个位置不能存放元素。
解释一下“对2的指数次方求模运算(
h % length)和h & (length-1)结果是一样的”,以4(二进制为11)为例:
0 % 4 = 0 同 4 % 4 = 0 ……
1 % 4 = 1 同 5 % 4 = 1 ……
2 % 4 = 2 同 6 % 4 = 2 ……
3 % 4 = 3 同 7 % 4 = 3 ……
00 & 11 = 0 同 100 && 11 = 0 ……
01 & 11 = 1 同 101 && 11 = 1 ……
10 & 11 = 2 同 110 && 11 = 2 ……
11 & 11 = 3 同 111 && 11 = 3 ……
明显,求余运算每4个一循环,对应二进制大于4之后,高位的数字与0进行与运算,始终为0,效果等同于每4个一循环。
总结一下:使用2的指数次方作为HashMap中存放元素数组的大小,可以避免求余操作,效率较高,同时,减少了碰撞次数。