基础知识储备
分布式跟踪的目标
一个分布式系统由若干分布式服务构成,每一个请求会经过多个业务系统并留下足迹,但是这些分散的数据对于问题排查,或是流程优化都很有限,要能做到追踪每个请求的完整链路调用,收集链路调用上每个服务的性能数据,计算性能数据和比对性能指标(SLA),甚至能够再反馈到服务治理中,那么这就是分布式跟踪的目标。
分布式跟踪的目的
zipkin分布式跟踪系统的目的:
- zipkin为分布式链路调用监控系统,聚合各业务系统调用延迟数据,达到链路调用监控跟踪;
- zipkin通过采集跟踪数据可以帮助开发者深入了解在分布式系统中某一个特定的请求时如何执行的;
- 假如我们现在有一个用户请求超时,我们就可以将这个超时的请求调用链展示在UI当中;我们可以很快度的定位到导致响应很慢的服务究竟是什么。如果对这个服务细节也很很清晰,那么我们还可以定位是服务中的哪个问题导致超时;
- zipkin系统让开发者可通过一个Web前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
ZipKin介绍
- Zipkin是一个致力于收集分布式服务的时间数据的分布式跟踪系统。
- Zipkin 主要涉及四个组件:collector(数据采集),storage(数据存储),search(数据查询),UI(数据展示)。
- github源码地址:https://github.com/openzipkin/zipkin。
- Zipkin提供了可插拔数据存储方式:In-Memory,MySql, Cassandra, Elasticsearch
brave 介绍
Brave 是用来装备 Java 程序的类库,提供了面向标准Servlet、Spring MVC、Http Client、JAX RS、Jersey、Resteasy 和 MySQL 等接口的装备能力,可以通过编写简单的配置和代码,让基于这些框架构建的应用可以向 Zipkin 报告数据。同时 Brave 也提供了非常简单且标准化的接口,在以上封装无法满足要求的时候可以方便扩展与定制。
本文主要介绍springmvc+dubbo下的brave使用。
dubbo项目下快速搭建zipkin、brave追踪系统
1、zipkin安装使用
此处主要介绍linux下的安装使用,zipkin官网地址 http://zipkin.io/pages/quickstart.html
wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
说明:zipkin是springboot项目,该jar包可直接通过java -jar zipkin.jar启动。启动完成后可访问 http://ip:9411查看。
2、zipkin存储与启动
详情参考官网: https://github.com/openzipkin/zipkin/tree/master/zipkin-server
(1)In-Memory方式
nohup java -jar zipkin.jar &
注意:内存存储,zipkin重启后数据会丢失,建议测试环境使用
(2)MySql方式
目前只与MySQL的5.6-7。它的设计是易于理解,使用简单。但是,当数据量大时,查询很慢。性能不是很好。
- 创建数据库zipkin
- 建表
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
- 启动zipkin命令
$ STORAGE_TYPE=mysql MYSQL_HOST=IP MYSQL_TCP_PORT=3306 MYSQL_DB=zipkin MYSQL_USER=username MYSQL_PASS=password nohup java -jar zipkin.jar &
(3)Elasticsearch方式
本文建议使用此方法。
- Elasticsearch官网
- 创建elasticsearch用户,安装启动Elasticsearch服务
- 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- zipkin启动命令
$ STORAGE_TYPE=elasticsearch ES_HOSTS=http://IP:9200 nohup java -jar zipkin.jar &
3、dubbo项目快速接入
(1)、项目pom中添加brave-dubbo.jar的依赖,brave-dubbo简化dubbo项目接入zipkin的步骤。
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-dubbo</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
(2)、在spring-application.xml中配置brave
<bean id="brave" class="com.github.kristofa.brave.dubbo.BraveFactoryBean" p:serviceName="serviceName" p:zipkinHost="http://zipkin-server-ip:9411/" p:rate="1.0" />
说明:
- zipkin-server-ip 是zipkin服务器ip地址。
- p:serviceName 项目名称。
- 只要是dubbo项目,无论是普通服务,还是web项目,都需要添加此包,并配置brave Bean。
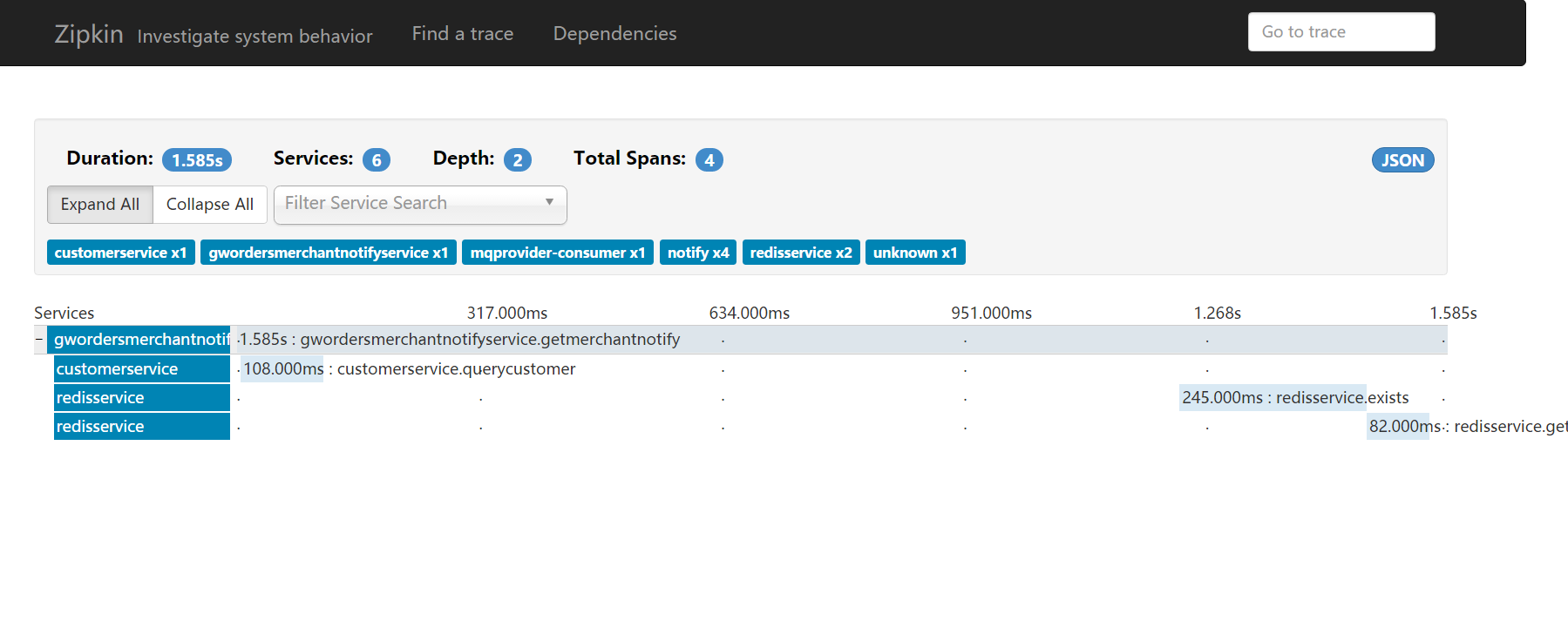
4、大功告成
此时,你可以看到如下效果。
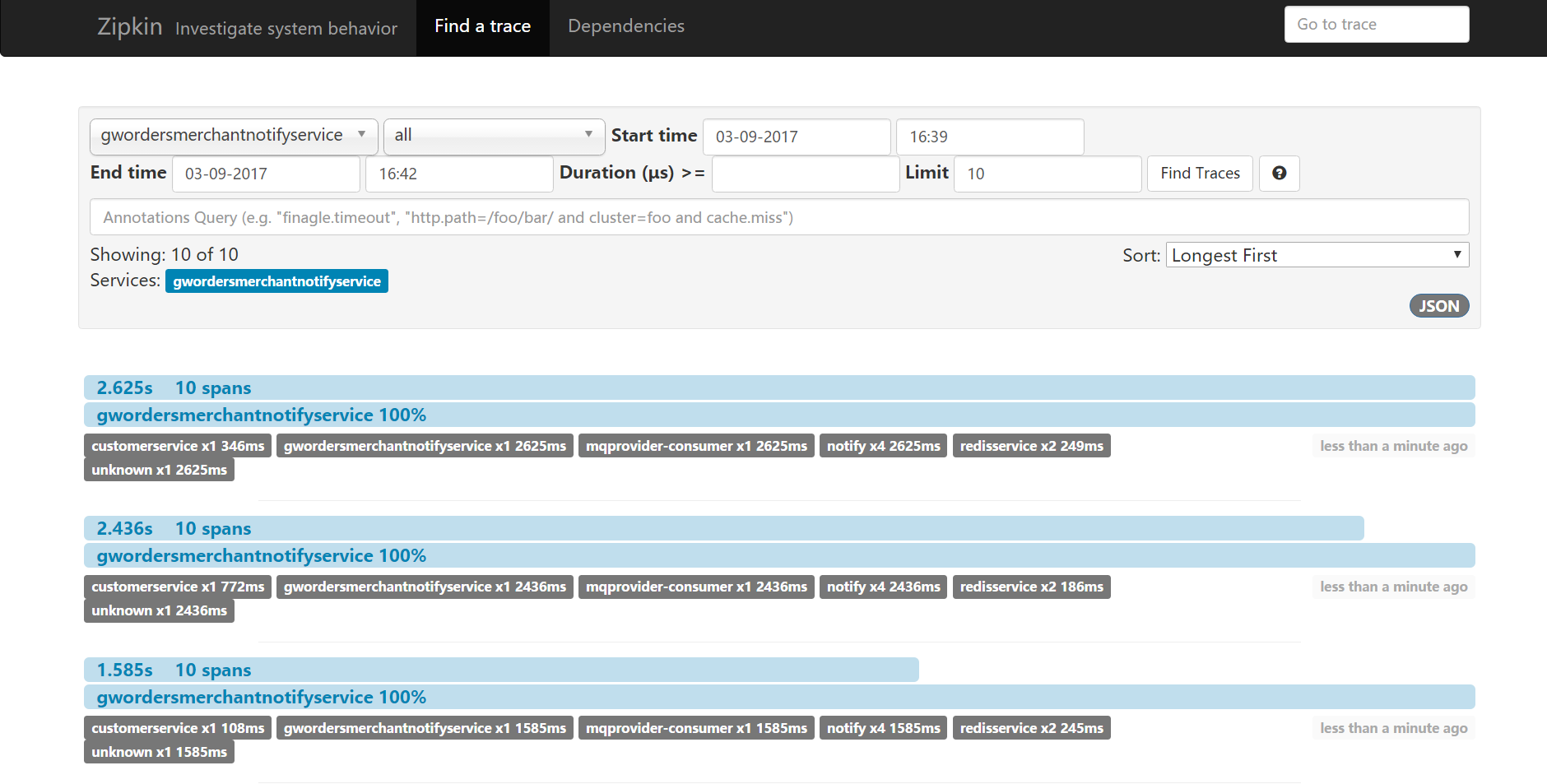
各个服务之间的调用关系及响应时间