项目背景
大数据时代的到来让数据在公司决策上发挥了越来越大的作用,数据分析师也成为了各大企业的标配,那么各大企业又会愿意花多少代价来为数据买单呢?本文将通过从拉勾网爬取到的职位信息来展现「数据分析」职位究竟「钱」景如何:
- 哪些城市更需要数据分析人才,除了北上广深还有没有其他城市给我们惊喜;
- 哪些行业更需要数据分析人才,薪资如何;
- 目前数据分析职位要求的工作经验和学历是怎样:
- 我工作%n年了,该拿到多少工资才不至于拖后腿了。
使用工具
Python/Tableau
- 数据获取主要使用urllib/json包,具体可参见文章Python爬虫拉勾网 ;
- 数据清洗处理使用了pandas包,可视化使用了seaborn包。
数据来源
本文使用数据全部来自于拉勾网,职位搜索关键词「数据分析」,获取时间2018/3/8,字段解释如下:
| 字段 | 内容 |
|---|---|
| city | 城市 |
| indusryField | 行业 |
| workYear | 工作经验 |
| education | 学历要求 |
| companySize | 公司规模 |
| salary | 薪资 |
| positionId | 职位编号 |
项目内容
导入所需包
import pandas as pd
import seaborn as sns
主题/字体设置
- 设置图表主题;
- 指定字体解决图表中文显示为方块的问题。
sns.set_style('ticks',{'font.sans-serif':['simhei','Arial']})
数据清洗
- 根据职位编号(positionId)进行去重,去重之后共计2298条招聘记录;
- 薪资(salary)字段格式为10K-20K,替换掉「k」然后根据「-」进行分列获得薪资上限与下限,最后取平均值作为职位参考薪资;
- 行业分类(industryField)包含大类和小类部分,根据「,」,「、」和空格分列取大类用于后期分析。
sns.set_style('ticks',{'font.sans-serif':['simhei','Arial']})
#中文显示问题
df = pd.read_excel('~\LagouSpider.xls',encoding='utf-8')
#加载数据
df = df.drop_duplicates(['positionId'])
#根据positionId进行去重
df = df.reset_index(drop=True)
#重置索引
df['salary'] = df['salary'].str.replace('k','')
df['salary'] = df['salary'].str.replace('K','')
#去掉大小写k
df['salary'] = df['salary'].str.split('-')
#通过'-'完成分列
df['salary'] = (df['salary'].str[1].astype(int)+df['salary'].str[0].astype(int))/2
#取平均值作为参考薪资
df['industryField'] = df['industryField'].str.split(',| ',1).str[0]
df['industryField'] = df['industryField'].str.split(u'、',1).str[0]
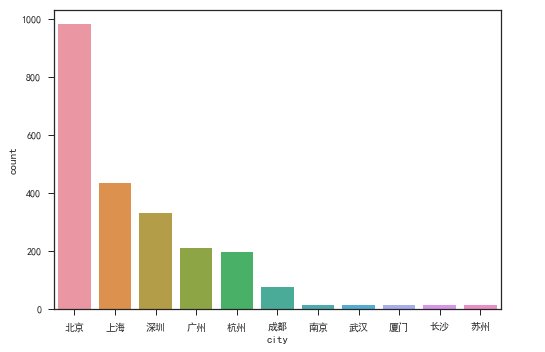
哪个城市最需要数据分析师?
根据城市分类来看,北上广深四城毫无意外念的领先,北京更是优势巨大,这与很多互联网以及金融企业选择在北京作为总部相关,当然也可能与拉勾网本身就是北京的一家企业,在北京业务开展更广有关系。
在二线城市中,杭州优势明显,「阿里巴巴」,「网易」加分不少,与广州已经差距很小了。
成都目前在招岗位60个,与其他城市拉开差距,在常年以来「成都与武汉谁是中西部最强城市?」似乎可以加上1分。
sns.countplot(x = 'city' , data = df)
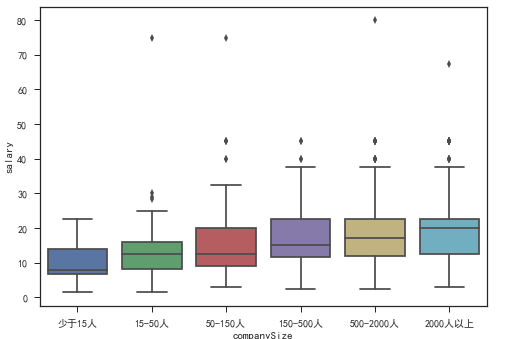
大公司OR小公司?
这个问题也是大多少求职者所考虑的问题,大公司更加稳定、制度健全,但是相比小公司可能晋升困难一些,从薪资整体水平来看,也可以看出,大公司更愿意给出高工资,但同时我们也能看到,小公司同样也能给出50K-100K这样的薪资。
所以你是愿意去大公司拧螺丝,还是去小公司造飞机,当然大部分时候拧螺丝还能赚的更多。
sns.boxplot(x = df['companySize'],y = df['salary'],
order = [u'少于15人',u'15-50人',u'50-150人',u'150-500人',u'500-2000人',u'2000人以上'])
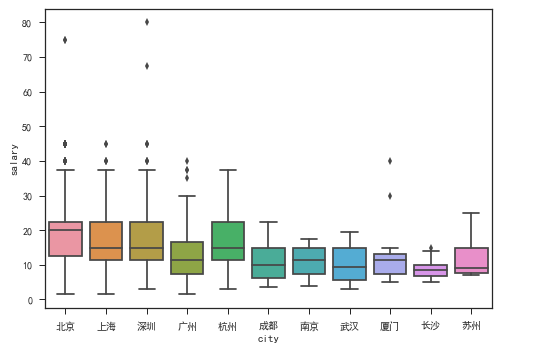
哪个城市薪资最高?
从各个城市薪资来看,北京依然遥遥领先,薪资中位数已逾20K,上海/深圳/杭州相差不大,都是15K左右的水平,当然如果对比一下上海/深圳的房价,杭州对于数据分析师来说似乎是个不错的落户选择。广州在薪资这阶段掉队明显,与其他二线城市相当。
sns.boxplot(x = 'city',y = 'salary',data = df)
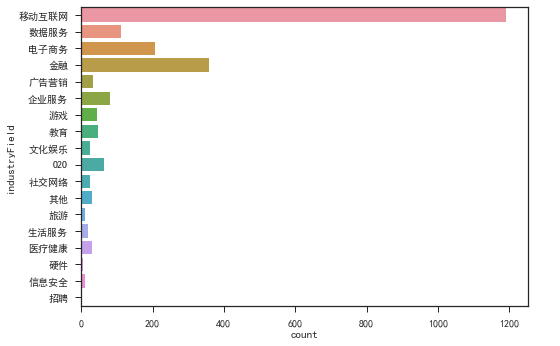
哪个行业最需要数据分析师?
从行业分布来看,移动互联网占据了半壁江山,招聘职位数是金融行业3倍,电子商务行业的5倍,另外由于拉勾网本身就是一家专注于互联网招聘的企业,这也让移动互联网在这份榜单上的优势愈加明显。
除了我们熟知的电子商务/金融行业,数据服务类公司也有较大的需求,数据服务会不会成为以后行业的一块大饼呢?最近几年大火的O2O也有较大的需求,去送个外卖也不错~
sns.boxplot(x = 'salary',y = 'industryField',data = df)
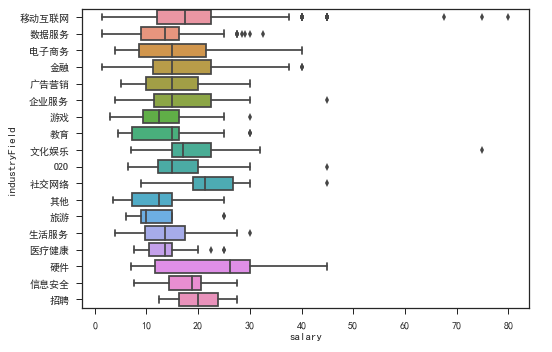
数据分析在各行薪资是个什么水平?
各个行业薪资水平来看,金融和电子商务行业薪资中位数相差无几,不过金融行业薪资整体薪资来看要高于电子商务,去金融行业求个职似乎还是门槛要高点。
移动互联网行业整体薪资维持在11K-22K之间,中位数16K,要高于金融行业。其他行业的由于样本量偏少,就不展开讨论了。
sns.countplot(y = 'industryField',data = df)
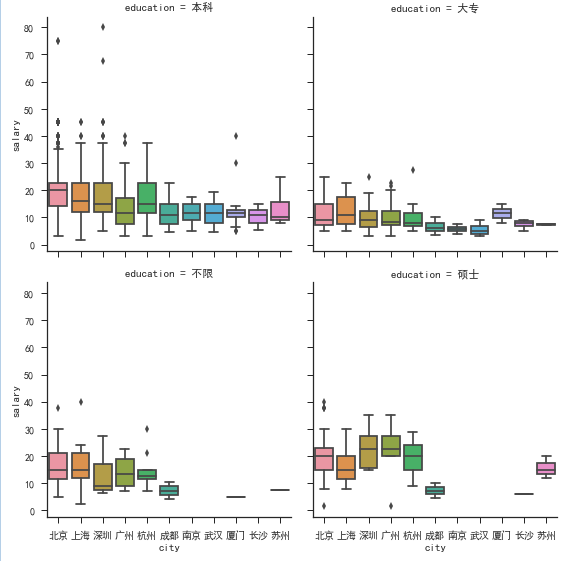
如果我是本科/硕士学历,我该去哪个城市?
在对各个学历的需求上来看,要求为本科的基本符合整体趋势,在2298个招聘职位中要求为本科的达到了1969个,看来本科已经成为了数据分析师的一个基本门槛。
在遍地211/985的北京,大专似乎很不值钱,在四个一线城市中,薪资为最低。
但我们看要求为硕士的,薪资领先的是广州/深圳,我们都知道,相比北京/上海,广州/深圳的高校资源相对匮乏,尤其是深圳,这样的薪资也体现了广州/深圳对于高学历人才的需求,所以,如果你硕士毕业,想要更高的工资,广州/深圳应该是不错的选择。
sns.factorplot(x="city", y = 'salary' , col="education",col_wrap=2,
data=df[df['education']!=u'博士'], kind="box",
size=4, aspect=1);
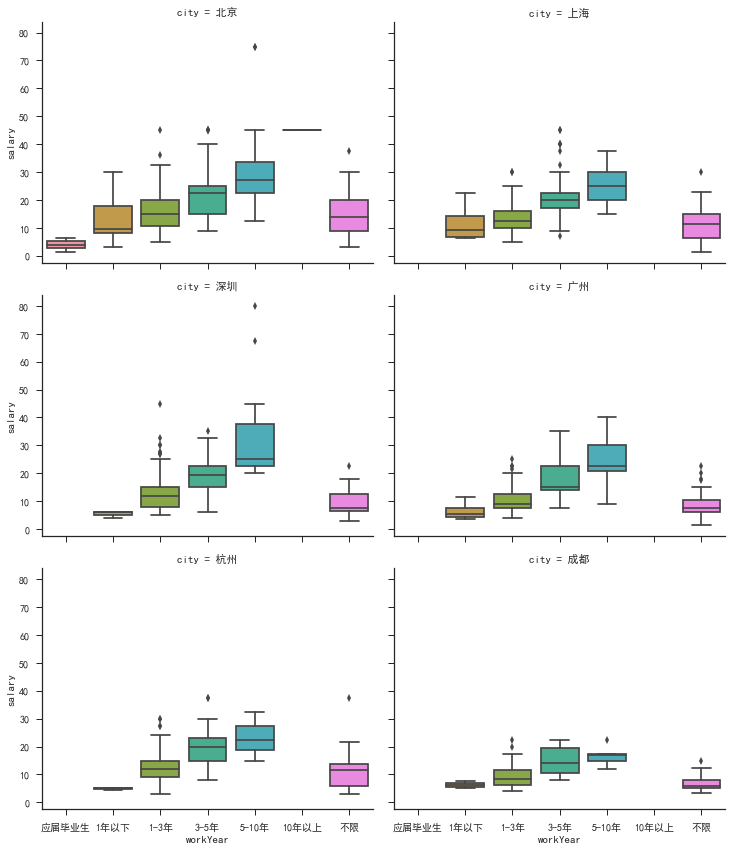
我工作%n年了,应该拿到多少薪资才不至于拖后腿了?
从工作年限来看,都是一个整体上升趋势,3-5年会有一个较大的涨幅,5-10年工作经验的工资基本维持在20K-30K之间,深圳一家公司开出了60K-100K的工资,羡慕不已,传送门 。
sns.factorplot(x="workYear", y = 'salary' , col="city",col_wrap=2,
data=df.loc[df['city'].isin([u'北京',u'上海',u'广州',u'深圳',u'杭州',u'成都'])],
order = [u'应届毕业生',u'1年以下',u'1-3年',u'3-5年',u'5-10年',u'10年以上',u'不限'],
kind="box",size=4, aspect=1.3)
总结
- 数据分析整个行业薪资普遍不低,而且上升空间也是足够的,年入百万也不是痴人说梦;
- 城市分部来看,北上深优势明显,无论是从薪资还是机会都优于其他城市, 由于「阿里」、「网易」的存在,杭州也有不错表现,然后广州掉队明显;
- 公司规模大小与薪资成正比,越大的公司给出的工资也更高;
- 学历要求来看,本科学历是基本,硕士学历在广州/深圳更容易拿到高工资;
- 工作年限上,从业3年之后会有一个较大涨幅。
写在最后
这篇文章算是对数据分析行业的一次简单的概述,也算是自己第一次完成了「数据获取-清洗-分析」的一整套流程,对于求职者或者想踏入数据分析行业的人来说,可以当作参考,希望能有一点帮助。
当然还有很多需要完善和改进的地方:
- 样本量偏少而且偏向严重,少了点说服力;
- 只进行了简单的描述性分析,没有更深入的探索;
- 少了职位描述及职位要求,本来想做的词云也夭折了。
继续努力~
最后也祝各位早日拿到高工资~