项目介绍

通过NBA近三十年的数据来看:
- 各项统计数据之间的相关性
- 整体风格上的变化
- 三分球的作用
数据介绍
关于数据源的介绍以及字段解释各位可以移步科赛网 查看,使用的数据源是 team_season.csv。
项目内容
导入所需包
# -*- coding: utf-8 -*-
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import numpy as np
import matplotlib as mpl
import warnings
import re
warnings.filterwarnings('ignore')
plt.rcParams['font.family'] = ['Microsoft YaHei']
导入数据
导入数据并生根据比赛比分生成一列分差:
data_team = pd.read_csv('/home/kesci/input/NBAdata/team_season.csv',encoding ='utf-8')
# 根据比分生成一列分差
data_team[u'分差'] = (data_team[u'比分'].str.extract(r"(\d+\.?\d*)-(\d+\.?\d*)", expand=False)[0].astype('int')
- data_team[u'比分'].str.extract(r"(\d+\.?\d*)-(\d+\.?\d*)", expand=False)[1].astype('int'))
data_team.head()

数据相关性
解析来我们看下各项统计数据之间有何相关性,使用的是pandas的内置函数dataframe.corr()来计算数据之间的皮尔逊相关系数,绝对值越接近1表明相关性越强。
data_corr = data_team.corr()
plt.figure(figsize = (15,12))
sns.heatmap(data = data_corr,cmap = 'Blues',linewidths=0.25,annot=True)
plt.show()
我们通过seaborn的heatmap来展示:
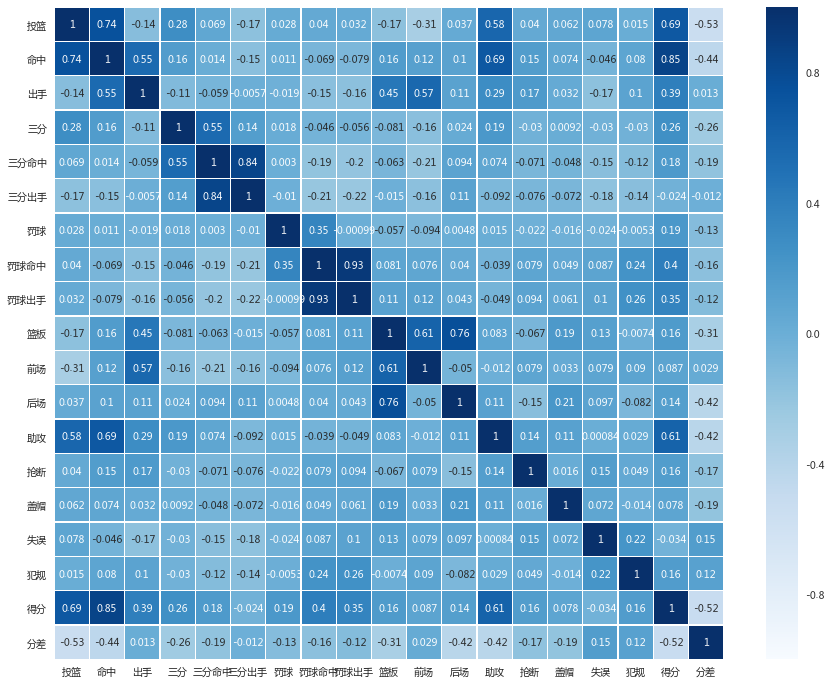
我们能看到什么:
- 整体来看,各项数据之间其实相关性不大,当然除了命中数和得分这类傻子都知道的关系;
- 前场篮板与出手数的相关系数是0.57,这个也很好解释,篮板抢的越多,自然就会有更多的出手机会,但后场篮板与出手的相关系数就只有0.11了,看过多年球的应该都明白,后场篮板其实是由对手的命中率来决定的,只有前场篮板才能反映一个球队在拼抢篮板上是不是积极;
- 得分与助攻的相关系数是0.61,助攻越多,得分自然越多,当然这个并不能直接说明传球在球队进攻中发挥的作用,因为助攻统计的仅仅只是直接转化为得分的传球,但有一点可以肯定但是,得分多的球队,助攻肯定不会少。
- 得分与三分出手竟然是负相关,这点可能是我们大多数球迷会感到意外的,现在联盟都在拼了命的扔三分,结果居然是负相关。其实这点才反映了NBA这三十年的变化,在80/90年代,没那么多球队会选择三分球的,需要三分的时候可能是球队恰恰越到困难的时候,这也导致了与得分呈现负相关,当然现在这么多球队开始选择三分,肯定是有他的原因的,这个我们后面再看。
三十年,风格变了吗
可能看了很多年的球迷都在感叹:
- 以前是一个人扛起一支球队,每个球队都有那么一两个球星,现在都是球星扎堆;
- 以前是中锋的时代,内线肉搏是主流,现在都是飘在外线扔三分。
但事实真的是这样的吗或者说这些变化又是怎么体现到数据之中的,我们接下来看一看。
# 对比赛时间处理,取年份用于分组
data_team[u'年份'] = data_team[u'时间'].str.split('-').str[0]
data_team[u'月份'] = data_team[u'时间'].str.split('-').str[1]
data_grouped_years = data_team.groupby(data_team[u'年份']).mean().reset_index()
plt.figure(figsize=(15, 12))
for i, column in enumerate(data_grouped_years.iloc[:, 1:19].columns, 1):
plt.subplot(6, 3, i)
plt.plot(data_grouped_years[u'年份'], data_grouped_years[column], 'r')
my_x_ticks = ['1985', '1990', '1995', '2000', '2005', '2010', '2016']
plt.xticks(my_x_ticks)
plt.ylabel(column)
plt.show()
通过绘制折线图我们看下各项数据在三十年间的变化:
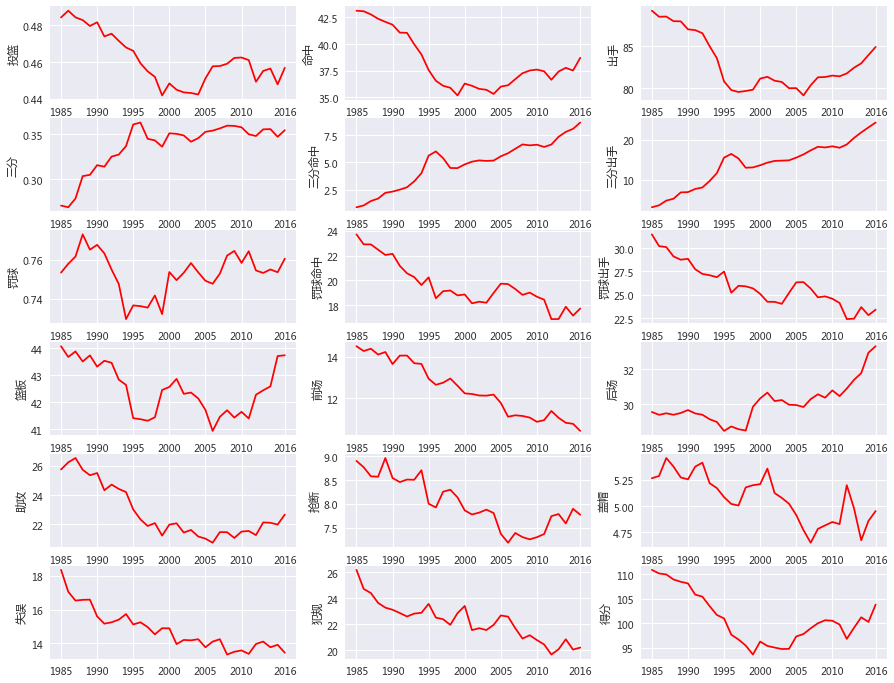
我们能看到什么:
- 不论是投篮命中率还是出手,都有了下降,不过在近十年有所上升;
- 三分不论是命中率还是出手都有一个大幅度提升,三分出手数从85年的2个飙升到了24个左右;
- 罚球方面,命中率有波动,但罚球数一直是下降但趋势,这也不难理解,毕竟犯规更集中在内线,外线三分投的多了,内线肉搏自然少了,犯规数自然就下降了,罚球也就少了。
- 篮板有下降,但近十年也一直上涨,为什么上涨,后场篮板多了,前场篮板这三十年可是一直在下降,前文也说过了,前场篮板才是反映一个球队篮板拼抢的积极性,这也说明了,篮板是越来越不被重视了,现在是一个没有中锋的时代。
- 助攻,抢断,盖帽,失误,犯规,得分都在下降,真的是不看不知道,一看吓一跳。
总体来说,防守型的数据都是在下降,无论是篮板,抢断还是盖帽,外线出手暴涨。以前是内线的时代,现在是小球时代,中锋作用被弱化。毕竟NBA是一个商业联盟,更多的是迎合市场,一个更能得分的球员总是会比一个更能抢篮板的球员更受欢迎。
三分的变化
前文中我们也看到了,三分球这些年越来越被重视,我们接下来更加直观来展现下这些年三分选择的变化:
data_team[u'三分占比'] = data_team[u'三分命中']*3/data_team[u'得分']
data_team_3ps_grouped = data_team[u'三分占比'].groupby(
[data_team[u'年份'], data_team[u'月份']]).mean().reset_index()
data_team_pivot = data_team_3ps_grouped.pivot(u'月份', u'年份', u'三分占比')
plt.figure(figsize=(20, 5))
with sns.axes_style("white"):
sns.heatmap(data=data_team_pivot, annot=True, linewidths=.5, cmap='Reds')
plt.ylabel(u'月份')
plt.show()
我们统计来这些年来三分球占比的情况,通过seaborn的heatmap做如下展示:
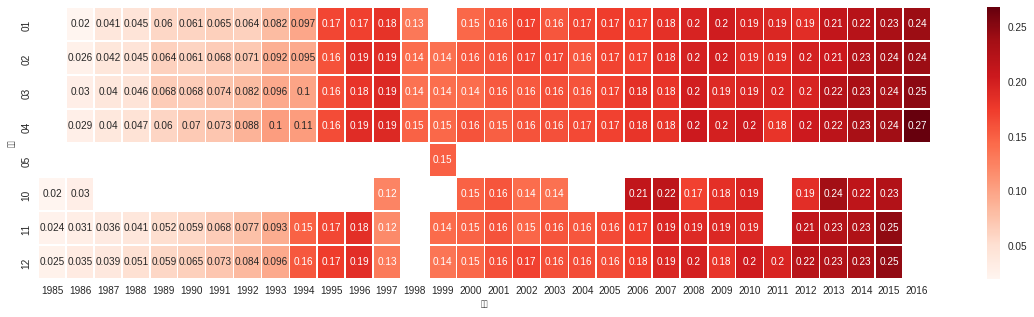
我们能看到什么:
- 85年的时候三分球得分占比不到2%,什么概念,平均下来一场得分100的球,三分只能占到2分,一个球不到,但到了2016年,这个比重以及上升到27%;
- 95-97年之间三分球有个较大幅度上涨,到97-98赛季又下降了。
三分合理吗
现在都这么拼命的扔三分,真的就很合理吗?
在讨论三分合理性之前,我们先引入一个概念——有效命中率
eFG%(effective Field Goal percentage)通常翻译为“有效命中率”,该数据优化了三分球对于球员命中率的影响。 考虑到每一个三分球实际上相当于命中了1.5个两分球,因此,eFG%的计算公式为:eFG% = ( FG + 0.5 * 3P ) / FGA,其中: FG:投篮命中数; 3P:三分命中数 FGA:投篮出手总数
其实简单来说,投中一个三分,算1.5个投篮命中数,下面我们来看下近三十年来,有效命中率是怎么在变化。
data_team[u'有效命中率'] = (data_team[u'命中']+0.5 *
data_team[u'三分命中'])/data_team[u'出手']
data_team_efg_grouped = data_team.groupby(
[u'年份'])[u'有效命中率', u'投篮'].mean().reset_index()
plt.figure(figsize=(15, 5))
plt.plot(data_team_efg_grouped[u'年份'], data_team_efg_grouped[u'有效命中率'], 'r')
plt.plot(data_team_efg_grouped[u'年份'], data_team_efg_grouped[u'投篮'], 'g')
my_x_ticks = ['1985', '1990', '1995', '2000', '2005', '2010', '2016']
plt.xticks(my_x_ticks)
plt.legend(loc='best')
plt.show()
我们使用折线图来看这些年真实命中率的变化:
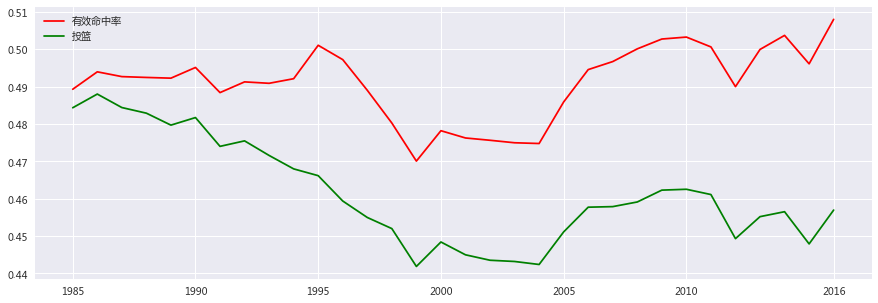
我们可以看到,这些年整体命中率虽然是在下降,不过真实命中率反而要高于以前了,可能对于很多老球迷来说,这样的NBA少了很多对抗,观赏性不如以前,不过我们还是可以看到,进攻效率却更高了,当然这样的变化是好是坏,就因人而异了。
最后
结论性的东西就不说了,前文都已经说了很多了。
NBA这么多年变化不少,作为一个球迷的我来说,变化其实也不小,想着以前高中大学的时候,为了自己喜欢的球星,跟同学争的面红耳赤也争不出个好歹,大学的时候只要上午有比赛,铁定是逃课去看比赛的,渐渐的参加工作之后,看NBA的时间没那么多了,搞得现在好多新生辈的球员都不认识了,关注的永远只有老詹,有时候看到一些说老詹不好的话,也没那么生气了,现在希望的就是老詹还能多打几年,等老詹退役了,我也应该就不再年轻了。
之前一直在科赛网-NBA这些年 上更新这个项目的,不过一直没怎么整理,特别是文字部分,很多也是在一边摸索一边统计,后期发现有意义的会再更新到简书的。
peace~
