实现目标:
- 输入斗鱼房间号实时获取弹幕信息,实现效果如下:
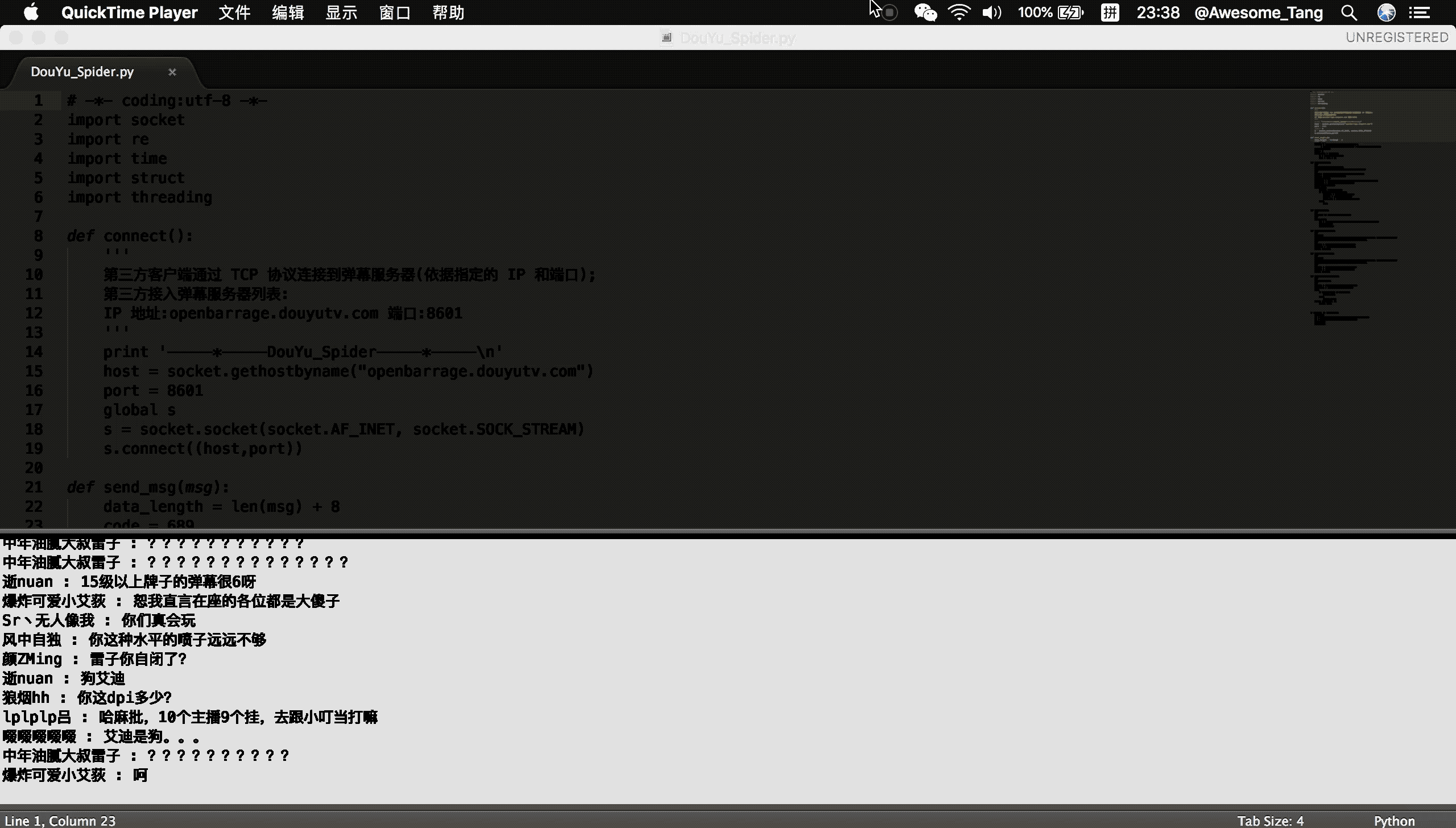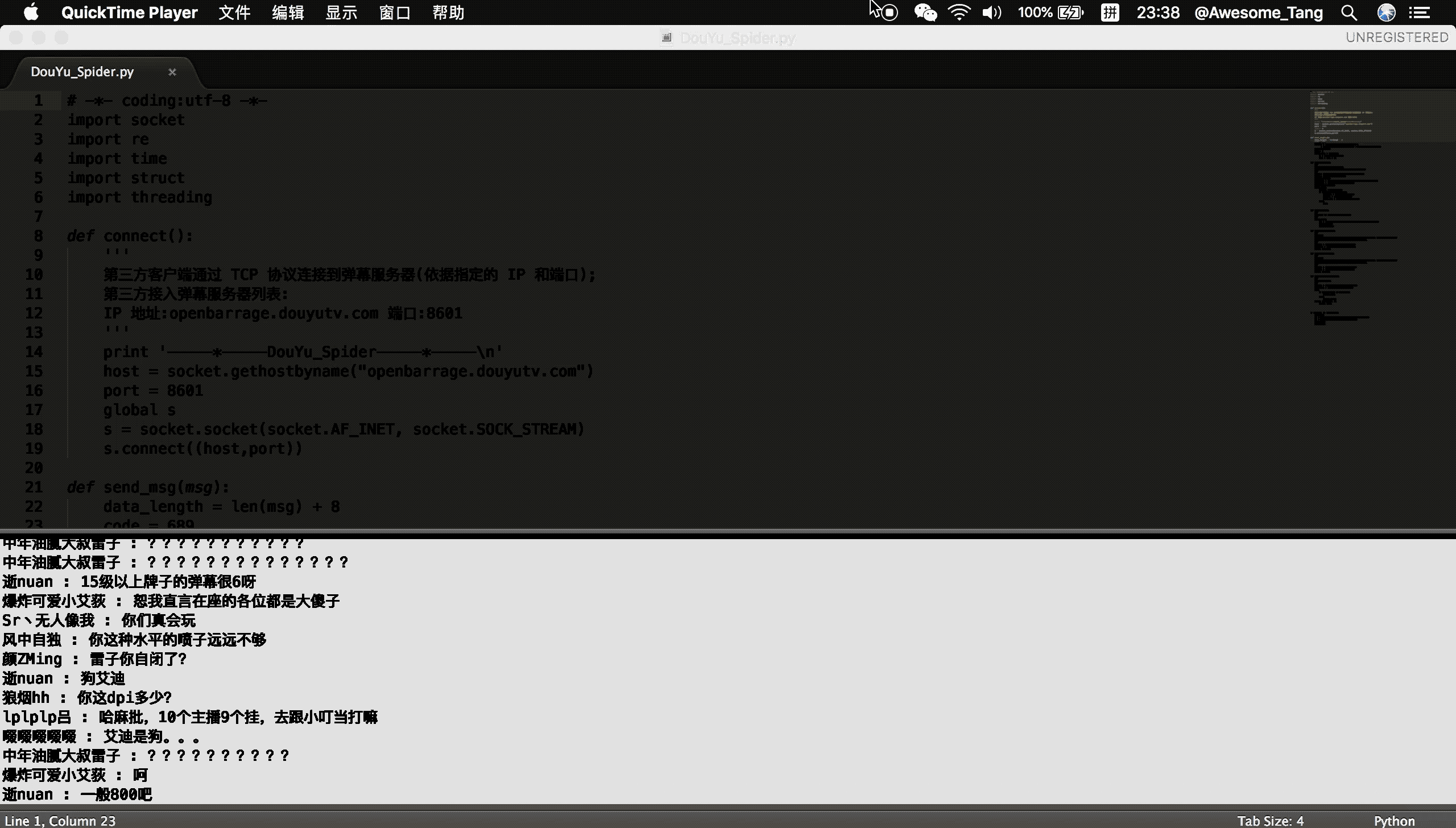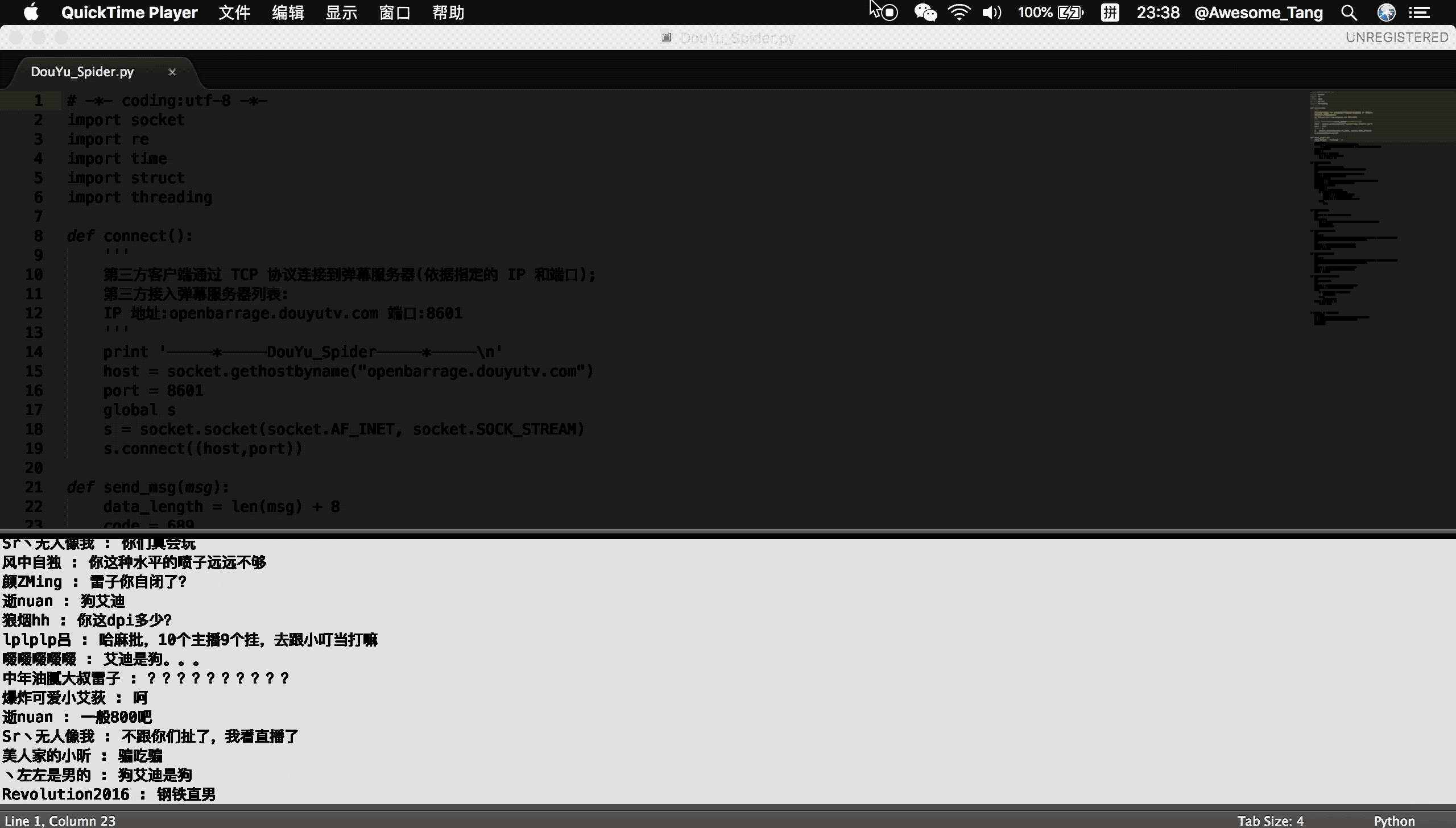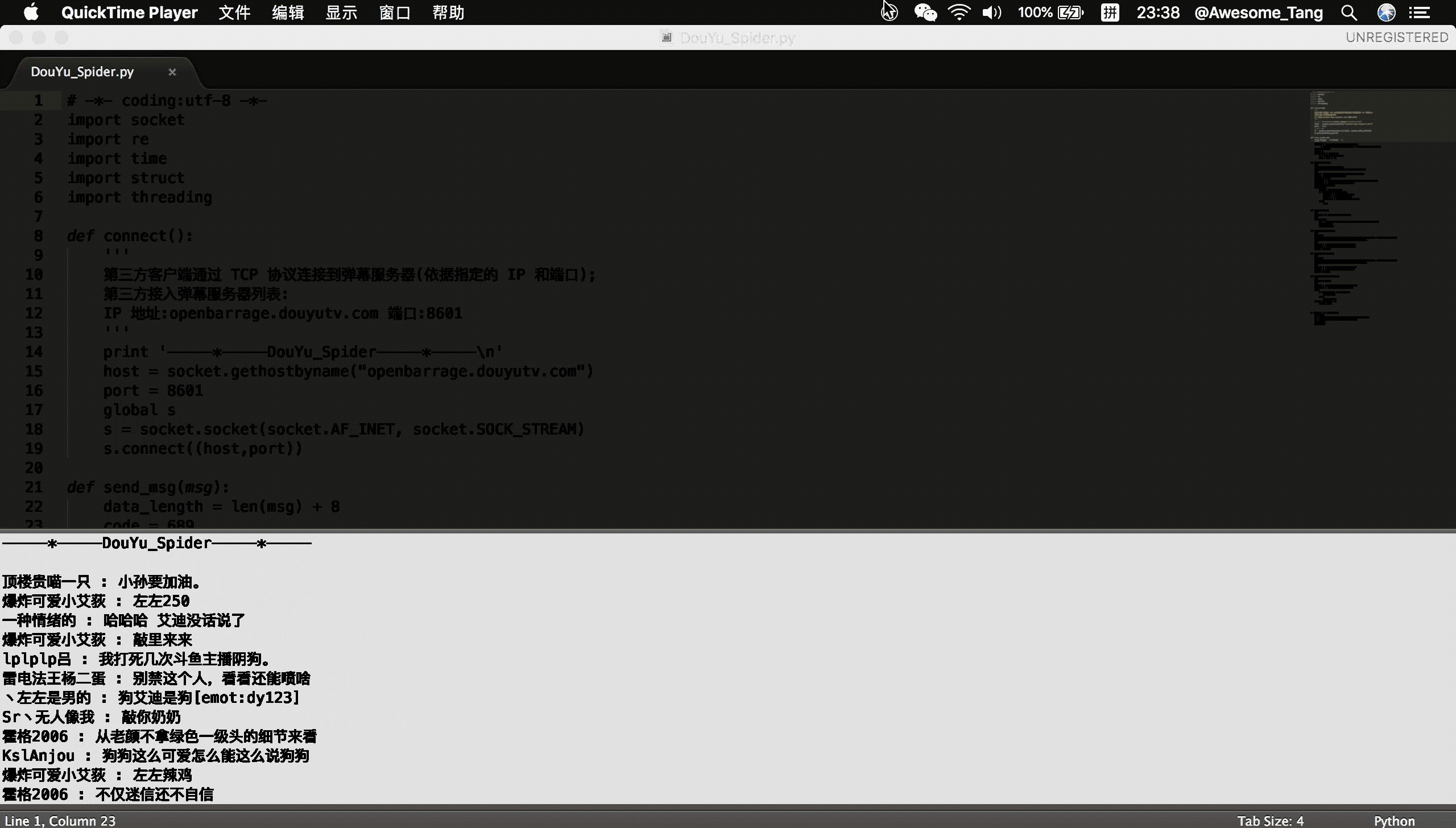 douyu.gif
douyu.gif
逻辑梳理
- 首先说明下斗鱼是开放了弹幕API的,可以直接去他们开发者论坛查看文档,按照文档中要求一步一步的来就好了,我这边就简单梳理下:
- 建立两个线程:一个与弹幕服务器建立连接然后获取数据,一个定时发送心跳信息给弹幕服务器保持连接。
建立连接
- 通过TCP协议连接到弹幕服务器;
IP 地址:openbarrage.douyutv.com 端口:8601
- 向弹幕服务器发送登录请求,登录弹幕服务器,消息格式
type@=loginreq/roomid@=房间号/,不需要账号密码; - 登陆成功之后服务器会给你返回一个登录成功信息,这部分不用管,继续向服务器发送一个进入弹幕分组请求,格式
type@=joingroup/rid@=房间号/gid@=-9999/,gid使用-9999就好,表示海量弹幕模式; - 接下来接收消息就好了,当然服务器返回的不止弹幕信息,还包括礼物/特殊人物进入房间等消息,这部分可以通过返回消息的type进行判断,选择自己需要的就好,详细的参见文档;
心跳消息
- 为保持连接需要每隔段时间向弹幕服务器发送心跳消息,长时间未收到心跳消息服务器就会断开连接了,心跳消息格式:
type@=keeplive/tick@=1439802131/,其中tick为当前秒级时间戳。
代码部分
# -*- coding:utf-8 -*-
import socket
import re
import time
import struct
import threading
def connect():
'''
第三方客户端通过 TCP 协议连接到弹幕服务器(依据指定的 IP 和端口);
第三方接入弹幕服务器列表:
IP 地址:openbarrage.douyutv.com 端口:8601
'''
print '-----*-----DouYu_Spider-----*-----\n'
host = socket.gethostbyname("openbarrage.douyutv.com")
port = 8601
global s
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host,port))
def send_msg(msg):
data_length = len(msg) + 8
code = 689
msgHead = struct.pack('<i',data_length) \
+ struct.pack('<i',data_length) + struct.pack('<i',code)
s.send(msgHead)
sent = 0
while sent < len(msg):
tn = s.send(msg[sent:])
sent = sent + tn
def danmu(room_id):
'''
1.客户端向弹幕服务器发送登录请求
2.客户端收到登录成功消息后发送进入弹幕分组请求给弹幕服务器
'''
login = 'type@=loginreq/roomid@=%s/\0'%room_id
login = login.encode('utf-8')
send_msg(login)
joingroup = 'type@=joingroup/rid@=%s/gid@=-9999/\0'%room_id
joingroup = joingroup.encode('utf-8')
send_msg(joingroup)
while True:
content = s.recv(1024)
if judge_chatmsg(content):
nickname = nick_name(content)
chatmsg = chat_msg(content)
print '%s : %s'%(nickname,chatmsg)
else:
pass
def keep_alive():
'''
客户端每隔 45 秒发送心跳信息给弹幕服务器
'''
while True:
msg = 'type@=keeplive/tick@=%s/\0'%str(int(time.time()))
send_msg(msg)
time.sleep(45)
def nick_name(content):
'''
弹幕消息:
type@=chatmsg/rid@=301712/gid@=-9999/uid@=123456/nn@=test /txt@=666/level@=1/
判断type,弹幕消息为chatmsg,txt为弹幕内容,nn为用户昵称
'''
pattern = re.compile(r'nn@=(.*)/txt@')
nickname = pattern.findall(content)[0]
return nickname
def chat_msg(content):
'''
弹幕消息:
type@=chatmsg/rid@=301712/gid@=-9999/uid@=123456/nn@=test /txt@=666/level@=1/
判断type,弹幕消息为chatmsg,txt为弹幕内容,nn为用户昵称
'''
pattern = re.compile(r'txt@=(.*)/cid@')
chatmsg = pattern.findall(content)[0]
return chatmsg
def judge_chatmsg(content):
'''
判断是否为弹幕消息
'''
pattern = re.compile(r'type@=(.*)/rid@')
data_type = pattern.findall(content)
try:
if data_type[0] == 'chatmsg':
return True
else:
return False
except Exception, e:
return False
if __name__ == '__main__':
connect()
t1 = threading.Thread(target=danmu,args=(2947432,))
t2 = threading.Thread(target=keep_alive)
t1.start()
t2.start()
最后
斗鱼提供的文档已经是一年前的了,里面传回的消息内容增加了不少,但整体逻辑还是没变,我这边只取了弹幕里面的昵称和文本内容,其他的消息各位可以先打印出来看了再写正则表达式去匹配就好。
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=4smxcktb7utn