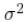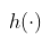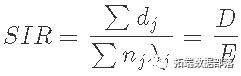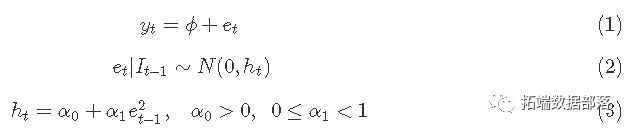热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
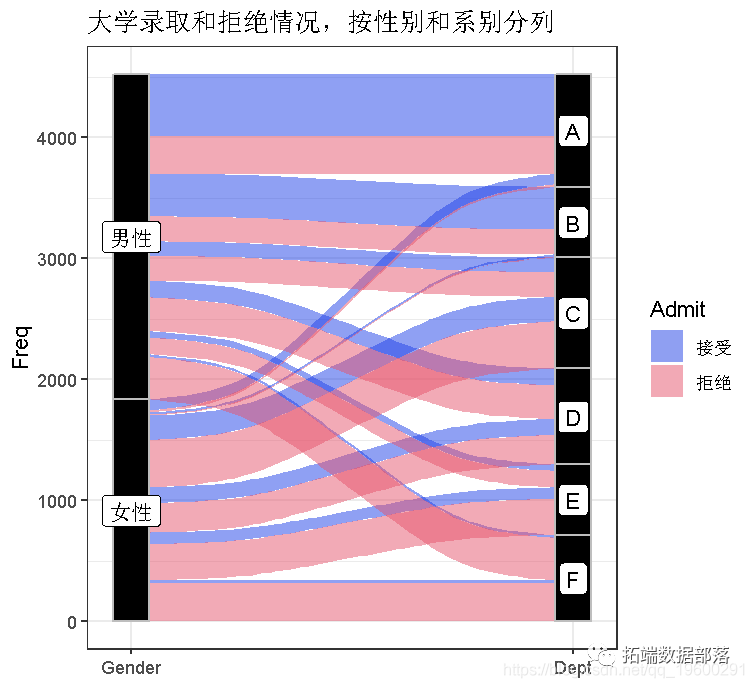
R语言可视化:ggplot2冲积/桑基图sankey分析大学录取情况、泰坦尼克幸存者数据
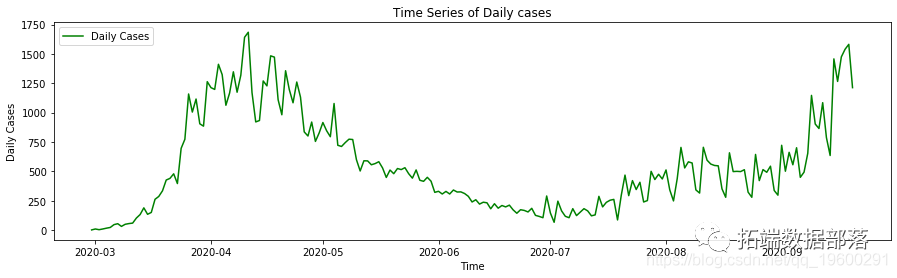
SARIMA,神经网络,RNN-LSTM,SARIMA和RNN组合方法预测COVID-19每日新增病例
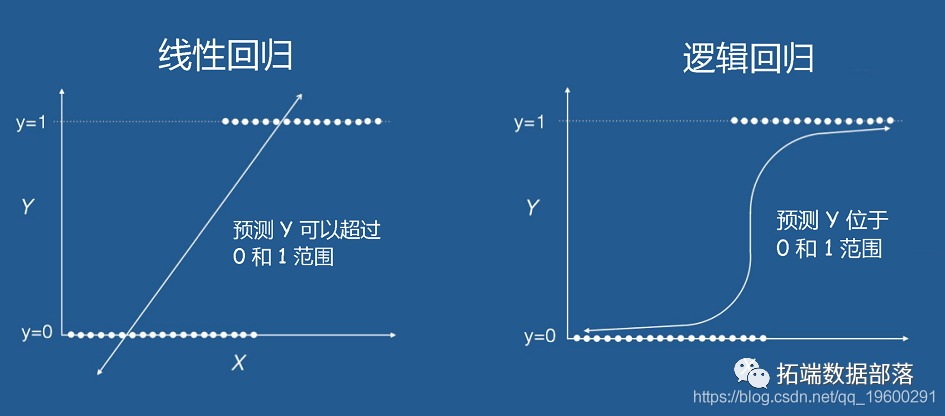
R语言逻辑回归Logistic回归分析预测股票涨跌
构建自定义机器学习模型:Scikit-learn的高级应用
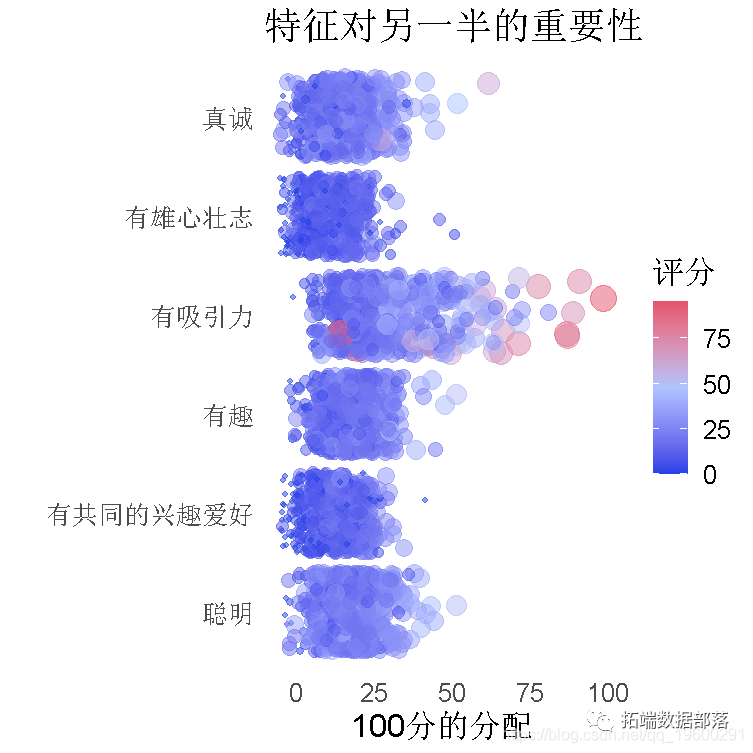
约会数据动态可视化分析:R语言使用GGPLOT和GGANIMATE制作动画图
scikit-learn在文本分类中的应用
Scikit-Learn与深度学习:融合与比较
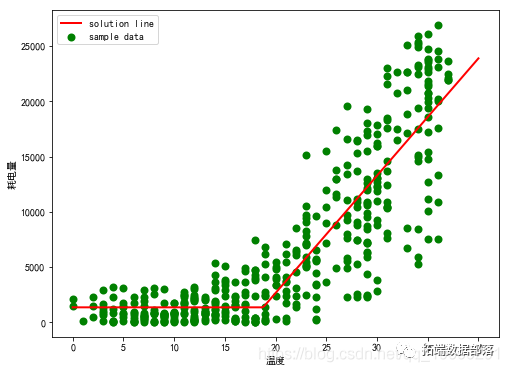
电力消耗模型构建、分析和预测
维度降维与特征选择:scikit-learn的实用技巧
R语言逻辑回归(Logistic Regression)、回归决策树、随机森林信用卡违约分析信贷数据集
模型选择与调优:scikit-learn中的交叉验证与网格搜索
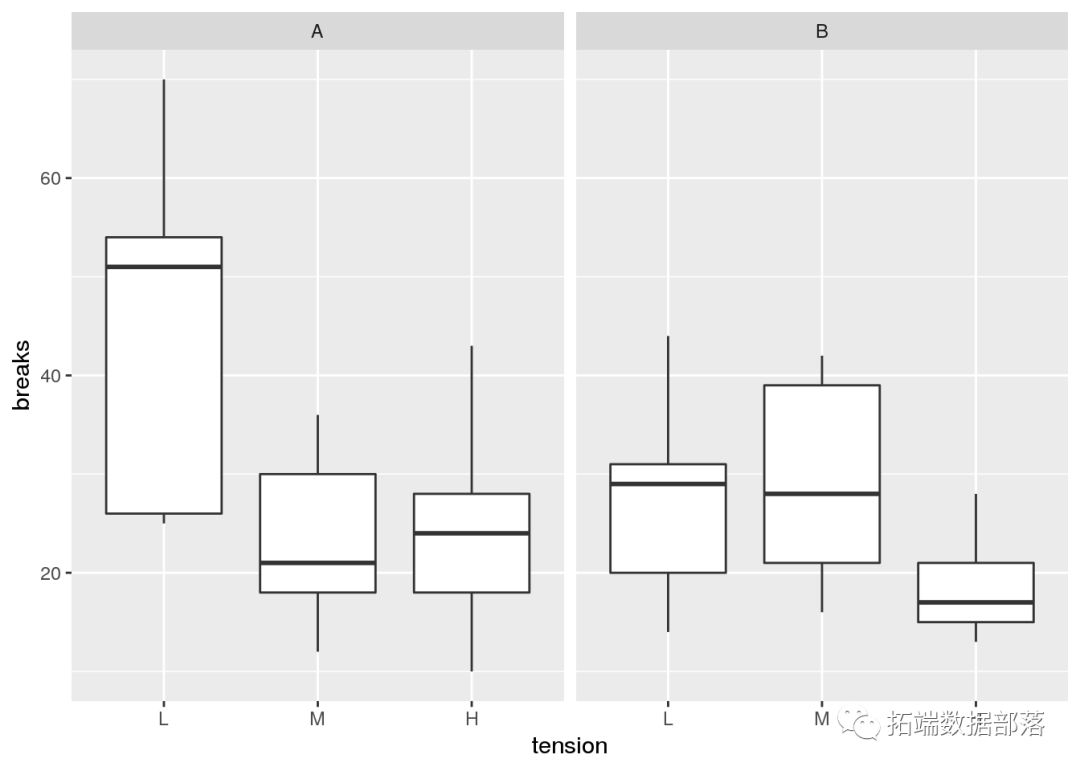
R语言多重比较方法
聚类分析实战:scikit-learn助你轻松上手
使用scikit-learn进行分类:模型选择与评估
scikit-learn在回归问题中的应用与优化
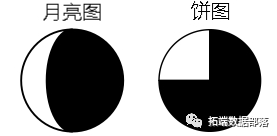
R语言在地图上绘制月亮图、饼状图数据可视化果蝇基因种群
探秘scikit-learn:机器学习库的核心功能详解
scikit-learn中的数据预处理:从清洗到转换
scikit-learn入门指南:从基础到实践
R语言进行支持向量机回归SVR和网格搜索超参数优化
R语言多元动态条件相关DCC-MVGARCH、常相关CCC-MVGARCH模型进行多变量波动率预测
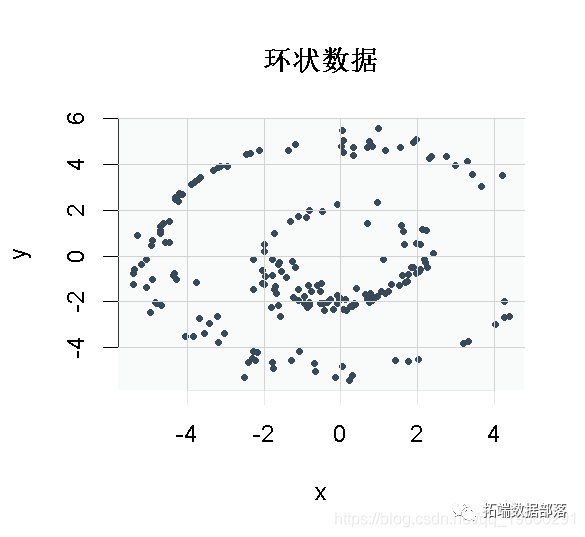
R语言谱聚类、K-MEANS聚类分析非线性环状数据比较
使用R语言做极大似然估计实例
R语言贝叶斯MCMC:用rstan建立线性回归模型分析汽车数据和可视化诊断
R语言检验独立性:卡方检验(Chi-square test)和费舍尔Fisher精确检验分析案例报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
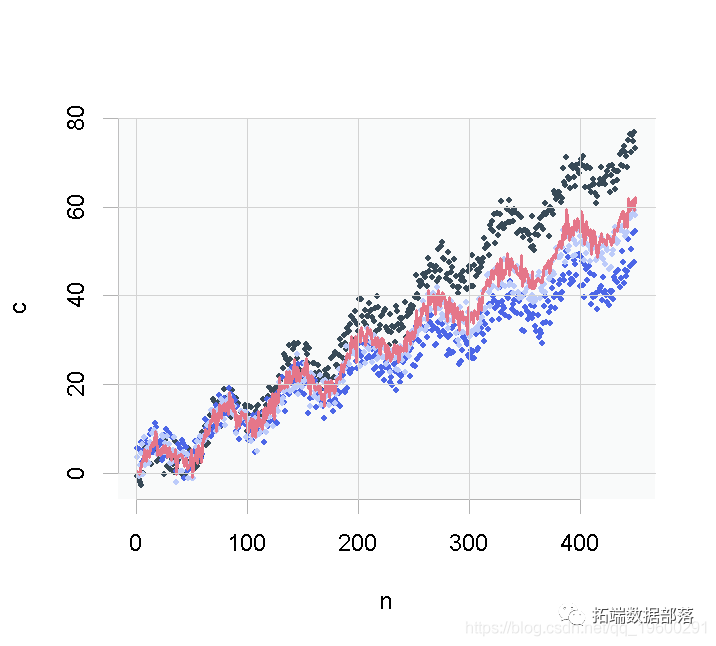
R语言样条曲线、泊松回归模型估计女性直肠癌患者标准化发病率(SIR)、死亡率(SMR)
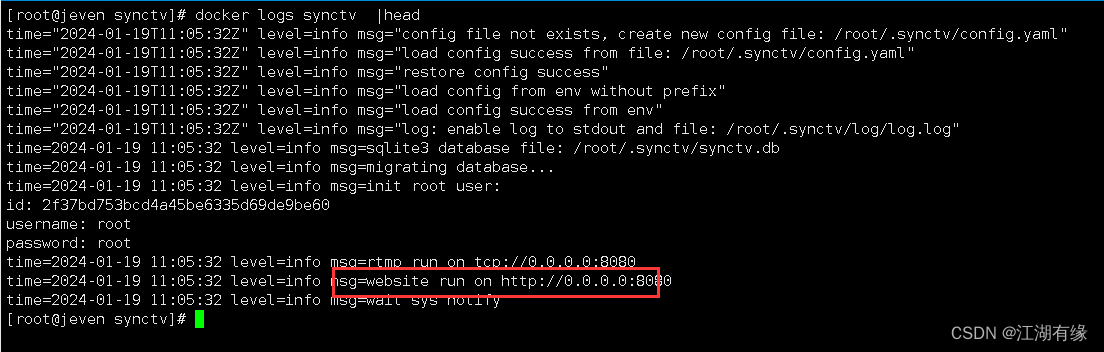
【好玩的开源项目】使用Docker部署SyncTV视频同步和共享平台
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
SciPy中的插值与拟合:实现数据平滑与曲线构建
SciPy高级特性:稀疏矩阵与并行计算
Python中LARS和Lasso回归之最小角算法Lars分析波士顿住房数据实例
SciPy线性代数库详解:矩阵运算与方程求解
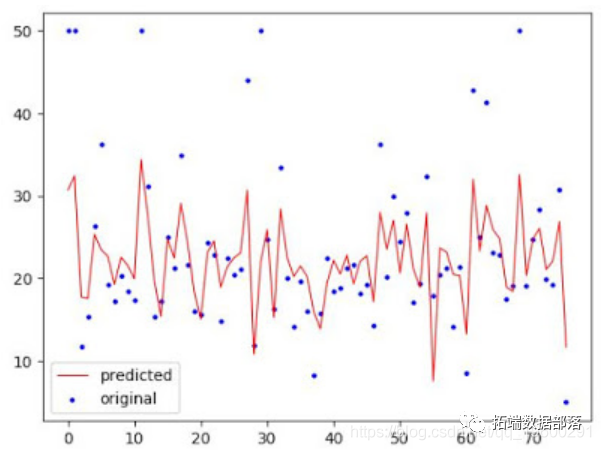
R语言时变波动率和ARCH,GARCH,GARCH-in-mean模型分析股市收益率时间序列
SciPy信号处理实战:从滤波到频谱分析
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
SciPy图像处理技巧:图像增强与特征提取
【MySQL系列笔记】MVCC
利用SciPy进行统计建模与预测分析
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
SciPy与机器学习:融合科学计算与智能算法
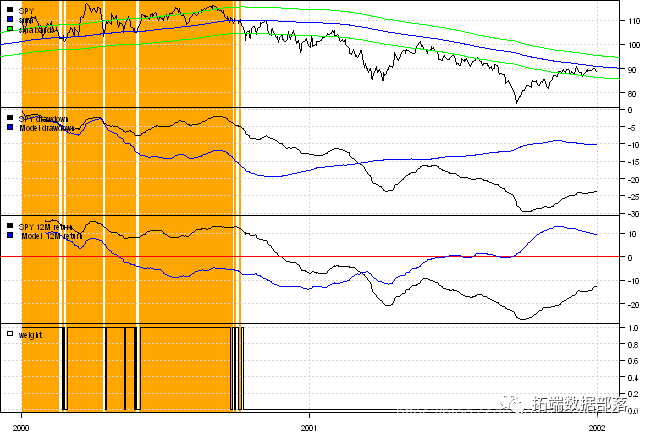
R语言资产配置策略量化模型:改进的移动平均线策略动态回测
深入探索SciPy:优化算法与数值分析
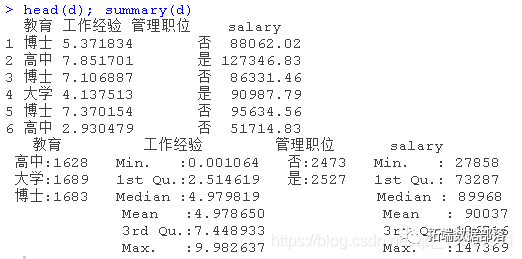
R语言使用虚拟变量(Dummy Variables) 回归分析工资影响因素
流畅的 Python 第二版(GPT 重译)(九)(4)
流畅的 Python 第二版(GPT 重译)(九)(3)
SciPy在数据分析中的应用:从数据清洗到可视化
流畅的 Python 第二版(GPT 重译)(九)(2)