引言
作为Java程序员,Spirng我们再熟悉不过,可以说比自己的女朋友还要亲密,每天都会和他在一起,然而我们真的了解spring吗?
我们都知道,Spring的核心是IOC和AOP,但楼主认为,如果从这两个核心中挑选一个更重要的,那非IOC莫属。AOP也是依赖于IOC,从某些角度讲,AOP就是IOC的一个扩展功能。
什么是IOC? IOC解决了什么问题?IOC的原理是什么?Spring的IOC是怎么实现的?今天我们将会将这几个问题一起解决。
1. 什么是IOC?
控制反转(Inversion of Control,缩写为IoC),是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。
其中最常见的方式叫做依赖注入(Dependency Injection,简称DI),还有一种方式叫“依赖查找”(Dependency Lookup)。
通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体,将其所依赖的对象的引用传递给它。也可以说,依赖被注入到对象中。
这是维基百科的说法,楼主按照自己的思路分析一下IOC,楼主认为,分析一个问题,或者说证明一个事情,有2种方法,一是正向验证,即按照该事物的逻辑去验证正确性,还有一种是反向验证,证明该事物是否正确。
楼主想反向证明IOC,我们提出一个疑问:如果没有IOC会怎么样?
想象一下,在没有IOC的世界里,我们的系统会有大量的对象,这些对象有些是数据,有些是处理数据的。
并且各个对象相互依赖,我们需要控制他们的依赖关系,什么时候new ,什么时候销毁,什么时候需要单例,什么时候不需要单例等等这些问题。
你能想象吗?当你一个系统有几千个类,你如何管理他们的依赖关系,说起依赖,我们可能会想起 maven 或者 gradle,他们管理着我们的 jar 包依赖,而我们的系统代码呢?
但是如果有一种东西,他能够帮助我们管理所有类的创建,销毁,是否是单例模式,类与类之间的多层依赖关系(在我们的MVC框架中,3层依赖已经是最少),那该多好,我们只需要关注业务逻辑。于是 ,IOC诞生了。
2. IOC 解决了什么问题?
简单来说, IOC 解决了类与类之间的依赖关系。程序员将控制类与类之间依赖的权利交给了IOC,即:控制被反转了。
3. IOC 的原理是什么?
其实 IOC 的原理很简单,底层就是java的反射。给定一个字符串能创建一个实例,利用set方法对实例的依赖进行注入。
我们来一段代码证明一下是多么的简单:
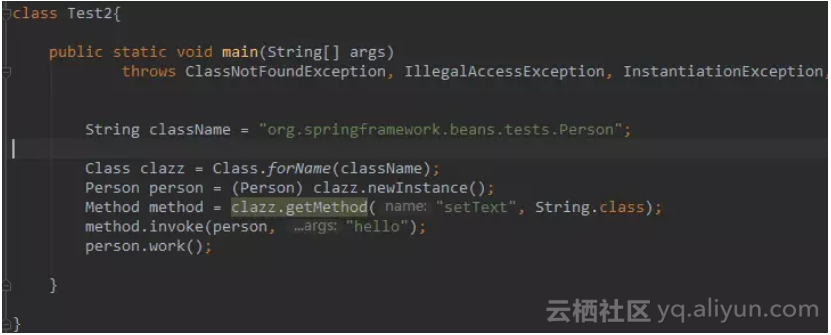
可以看到该代码非常的简单,但实际上IOC 就是这么简单,在真正的开发中,我们只需要在配置文件给定一个类名字符串,就什么都不用管了,对象就会创建出来,系统启动完毕之后,我们只需要直接使用该对象就好了,不必自己去new。
解决了我们的对象创建问题。我们通过反射调用该方法的setText方法,完成了依赖注入。我们不再需要去new,然后去set,IOC 已经为我们做好了一切。
介绍完了几个基本知识,其实都是为我们今天的重头戏做准备,Spring的IOC是怎么实现的?
4. Spring的IOC是怎么实现的?
这是一个浩大的问题,虽然底层实现可能就那么几行代码,但楼主说过,所有框架的底层技术都很简单,但是我们的框架大师们为了软件的健壮性,扩展性和性能,做了无数的优化,我们的系统源码也就变得越来越复。
spirng的 release 版本至今已经到了 5.0.3,和最初的 interface21 已经有了翻天复地的变化,现在也有了springboot, springcloud,俨然一个庞大的spring家族,想分析源码的我们该从哪里下手呢?
万剑归宗,始于一处。
Bean。
我们要研究spring的IOC,我们要了解的就是spring的bean,这是spring的核心的核心。虽然bena依赖着context 模块提供bean的环境,依赖core 提供着一系列强化的工具。
但今天我们不关心,我们只关系bean。只关心IOC。就像这个信息过载,技术不断更新的时代,程序们需要有自己的判断,自己需要研究什么,什么是最重要的?扯远了。
在开始研究源码之前,楼主有必要介绍一下IOC的一些核心组件,否则一旦进入源码,就会被细节捆住,无法从宏观的角度理解IOC。
BeanFactory:这是IOC容器的接口定义,如果将IOC容器定位为一个水桶,那么BeanFactory 就定义了水桶的基本功能,能装水,有把手。这是最基本的,他的实现类可以拓展水桶的功能。
ApplicationContext:这是我们最常见的,上面我们说水桶,BeanFactory是最基本的水桶,而 ApplicationContext 则是扩展后的水桶,它通过继承 MessageSource,ResourceLoader,ApplicationEventPublisher 接口,在BeanFactory 简单IOC容器的基础上添加了许多对高级容器的支持。
BeanDefinition:我们知道,每个bean都有自己的信息,各个属性,类名,类型,是否单例,这些都是bena的信息,spring中如何管理bean的信息呢?对,就是 BeanDefinition, Spring通过定义 BeanDefinition 来管理基于Spring的应用中的各种对象以及他们直接的相互依赖关系。BeanDefinition 抽象了我们对 Bean的定义,是让容器起作用的主要数据类型。对 IOC 容器来说,BeanDefinition 就是对依赖反转模式中管理的对象依赖关系的数据抽象,也是容器实现依赖反转功能的核心数据结构。
4.1. 搭建源码研究环境
楼主研究源码的思路有2个,一个是创建一个简单的spirng maven 项目,还有一个是直接从 spirng 的github 上 clone 源码。
这是楼主的普通 maven 项目:
这是楼主的 clone 的 spring-framework 源码:
注意:clone 该源码的时候,楼主很艰辛,因为要科学上网,否则 gradle 无法下载依赖会导致报错。如果各位无法科学上网,可以使用 maven 项目勉强学习。
4.2. 开启研究源码第一步
我们打开spring-framework 源码。
还记的我们初学spring的写的第一行代码是什么吗?
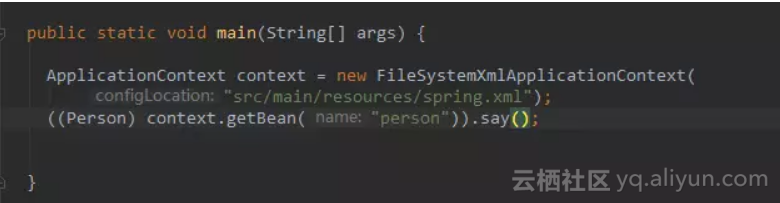
怎么写配置文件楼主就不说了,我们回忆一下我们最初学spring的时候,虽然现在都是2017年了,我们都用springboot,都是用注解了,但spring的核心代码还是 spring 之父 Rod Johnson 在 2001 年写的。所以不影响我们学习spring 的核心。
我们仔细看看该代码(该代码位置必须在spring-context模块下):
package
test;
import
org.springframework.beans.tests.Person;
import
org.springframework.context.ApplicationContext;
import
org.springframework.context.support.FileSystemXmlApplicationContext;
public
class
Test
{
public
static
void
main
(String[] args)
throws
ClassNotFoundException {
ApplicationContext ctx =
new
FileSystemXmlApplicationContext
(
"spring-beans/src/test/resources/beans.xml"
);
System.out.println(
"number : "
+ ctx.getBeanDefinitionCount());
((Person) ctx.getBean(
"person"
)).work();
}
}
熟悉的 ApplicatContext ,看名字是应用上下文,什么意思呢?就是spirng整个运行环境的背景,好比一场舞台剧,ApplicatContext 就是舞台,IOC 管理的Bean 就是演员,Core 就是道具。而ApplicatContext 的标准实现是 FileSystemXmlApplicationContext。
该类的构造方法中包含了容器的启动,IOC的初始化。所以我们 debug 启动该项目,运行main方法。打好断点。
4.3. 从 FileSystemXmlApplicationContext 开始剖析
从这里开始,我们即将进入复杂的源码。
我们进入 FileSystemXmlApplicationContext 的构造方法:
可以看到该构造方法被重载了,可以传递 configLocation 数组,也就是说,可以传递过个配置文件的地址。默认刷新为true,parent 容器为null。进入另一个构造器:
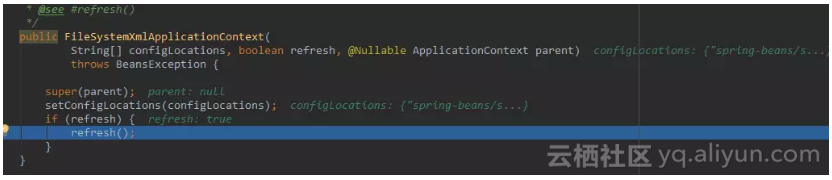
该构造器做了2件事情,一是设置配置文件,二是刷新容器,我们可以感觉到,refresh 方法才是初始化容器的重要方法。我们进入该方法看看:该方法是 FileSystemXmlApplicationContext 的父类 AbstractApplicationContext 的方法。
4.4. AbstractApplicationContext.refresh() 方法实现
/**
*
* 1. 构建Be按Factory,以便产生所需要的bean定义实例
* 2. 注册可能感兴趣的事件
* 3. 创建bean 实例对象
* 4. 触发被监听的事件
*
*/
@Override
public
void
refresh
()
throws
BeansException, IllegalStateException {
synchronized
(
this
.startupShutdownMonitor) {
// 为刷新准备应用上下文
prepareRefresh();
// 告诉子类刷新内部bean工厂,即在子类中启动refreshBeanFactory()的地方----创建bean工厂,根据配置文件生成bean定义
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 在这个上下文中使用bean工厂
prepareBeanFactory(beanFactory);
try
{
// 设置BeanFactory的后置处理器
postProcessBeanFactory(beanFactory);
// 调用BeanFactory的后处理器,这些后处理器是在Bean定义中向容器注册的
invokeBeanFactoryPostProcessors(beanFactory);
// 注册Bean的后处理器,在Bean创建过程中调用
registerBeanPostProcessors(beanFactory);
//对上下文的消息源进行初始化
initMessageSource();
// 初始化上下文中的事件机制
initApplicationEventMulticaster();
// 初始化其他的特殊Bean
onRefresh();
// 检查监听Bean并且将这些Bean向容器注册
registerListeners();
// 实例化所有的(non-lazy-init)单件
finishBeanFactoryInitialization(beanFactory);
// 发布容器事件,结束refresh过程
finishRefresh();
}
catch
(BeansException ex) {
if
(logger.isWarnEnabled()) {
logger.warn(
"Exception encountered during context initialization - "
+
"cancelling refresh attempt: "
+ ex);
}
// 为防止bean资源占用,在异常处理中,销毁已经在前面过程中生成的单件bean
destroyBeans();
// 重置“active”标志
cancelRefresh(ex);
throw
ex;
}
finally
{
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
可以说该方法就是整个IOC容器初始化的所有逻辑。因此,如果读懂了该方法的每一行代码,就了解了spring的整个功能。该方法的调用层次之深可以想象一下。
我们先大致说下该方法的步骤:
构建BeanFactory,以便于产生所需的 Bean。
注册可能感兴趣的事件。
常见Bean实例对象。
触发被监听的事件。
我们一个个来看: 首先构建BeanFactory,在哪里实现的呢?也就是obtainFreshBeanFactory 方法,返回了一个ConfigurableListableBeanFactory,该方法调用了 refreshBeanFactory() ,该方法是个模板方法,交给了 AbstractRefreshableApplicationContext 去实现。我们看看该方法实现:
@Override
protected
final
void
refreshBeanFactory
()
throws
BeansException {
if
(hasBeanFactory()) {
// 如果存在就销毁
destroyBeans();
closeBeanFactory();
}
try
{
// new DefaultListableBeanFactory(getInternalParentBeanFactory())
DefaultListableBeanFactory beanFactory = createBeanFactory();
// 设置序列化
beanFactory.setSerializationId(getId());
// 定制的BeanFactory
customizeBeanFactory(beanFactory);
// 使用BeanFactory加载bean定义 AbstractXmlApplicationContext
loadBeanDefinitions(beanFactory);
synchronized
(
this
.beanFactoryMonitor) {
this
.beanFactory = beanFactory;
}
}
catch
(IOException ex) {
throw
new
ApplicationContextException(
"I/O error parsing bean definition source for "
+ getDisplayName(), ex);
}
}
可以看到BeanFactory的创建过程,首先判断是否存在了 BeanFactory,如果有则销毁重新创建,调用 createBeanFactory 方法,该方法中就是像注释写的:创建了 DefaultListableBeanFactory ,也既是说,DefaultListableBeanFactory 就是 BeanFactory的默认实现。然后我们看到一个很感兴趣的方法。
就是 loadBeanDefinitions(beanFactory),看名字是加载 Definitions,这个我们很感兴趣,我们之前说过, Definition 是核心之一,代表着 IOC 中的基本数据结构。该方法也是个抽象方法,默认实现是 AbstractXmlApplicationContext ,我们看看该方法实现:
@Override
protected
void
loadBeanDefinitions
(DefaultListableBeanFactory beanFactory)
throws
BeansException, IOException {
// Create a new XmlBeanDefinitionReader for the given BeanFactory.
XmlBeanDefinitionReader beanDefinitionReader =
new
XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(
this
.getEnvironment());
beanDefinitionReader.setResourceLoader(
this
);
beanDefinitionReader.setEntityResolver(
new
ResourceEntityResolver(
this
));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
loadBeanDefinitions(beanDefinitionReader);
}
该方法我没有写中文注释,我们看看英文注释: 首先创建一个 XmlBeanDefinitionReader ,用于读取XML中配置,设置了环境,资源加载器,最后初始化,加载。可以说,该方法将加载,解析Bean的定义,也就是把用户定义的数据结构转化为 IOC容器中的特定数据结构。而我们关心的则是最后一行的 loadBeanDefinitions(beanDefinitionReader) 方法。
protected
void
loadBeanDefinitions
(XmlBeanDefinitionReader reader)
throws
BeansException, IOException {
Resource[] configResources = getConfigResources();
if
(configResources !=
null
) {
reader.loadBeanDefinitions(configResources);
}
String[] configLocations = getConfigLocations();
if
(configLocations !=
null
) {
// 加载给定的路径文件
reader.loadBeanDefinitions(configLocations);
}
}
该方法会略过第一个if块,进入第二个if块,进入 AbstractBeanDefinitionReader.loadBeanDefinitions(String… locations) 方法,该方法内部循环加载配置文件:
@Override
public
int
loadBeanDefinitions
(String... locations)
throws
BeanDefinitionStoreException {
Assert.notNull(locations,
"Location array must not be null"
);
int
counter =
0
;
for
(String location : locations) {
counter += loadBeanDefinitions(location);
}
return
counter;
}
我们关心的是 for 循环中的loadBeanDefinitions(location)方法,该方法核心逻辑在 AbstractBeanDefinitionReader.loadBeanDefinitions(String location, @Nullable SetactualResources) 方法中:
public
int
loadBeanDefinitions
(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
ResourceLoader resourceLoader = getResourceLoader();
if
(resourceLoader ==
null
) {
throw
new
BeanDefinitionStoreException(
"Cannot import bean definitions from location ["
+ location +
"]: no ResourceLoader available"
);
}
if
(resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try
{
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
int
loadCount = loadBeanDefinitions(resources);
// 根据配置文件加载bean定义
if
(actualResources !=
null
) {
for
(Resource resource : resources) {
actualResources.
add
(resource);
}
}
if
(logger.isDebugEnabled()) {
logger.debug(
"Loaded "
+ loadCount +
" bean definitions from location pattern ["
+ location +
"]"
);
}
return
loadCount;
}
catch
(IOException ex) {
throw
new
BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern ["
+ location +
"]"
, ex);
}
}
else
{
// Can only load single resources by absolute URL.
Resource resource = resourceLoader.getResource(location);
int
loadCount = loadBeanDefinitions(resource);
if
(actualResources !=
null
) {
actualResources.
add
(resource);
}
if
(logger.isDebugEnabled()) {
logger.debug(
"Loaded "
+ loadCount +
" bean definitions from location ["
+ location +
"]"
);
}
return
loadCount;
}
}
该方法首先获取资源加载器,然后进入 if 块,获取资源数组,调用 loadBeanDefinitions(resources) ,根据配置文件加载Bean定义。
进入该方法后,循环加载resource 资源数组,进入 loadBeanDefinitions(resource) 方法中,最后进入到 XmlBeanDefinitionReader.loadBeanDefinitions(EncodedResource encodedResource) 方法中,该方法主要调用 doLoadBeanDefinitions(inputSource, encodedResource.getResource()) 方法。我们有必要看看该方法实现:
protected
int
doLoadBeanDefinitions
(InputSource inputSource, Resource resource)
throws
BeanDefinitionStoreException {
try
{
Document doc = doLoadDocument(inputSource, resource);
return
registerBeanDefinitions(doc, resource);
// 真正的注册bean
}
catch
(BeanDefinitionStoreException ex) {
throw
ex;
}
catch
(SAXParseException ex) {
throw
new
XmlBeanDefinitionStoreException(resource.getDescription(),
"Line "
+ ex.getLineNumber() +
" in XML document from "
+ resource +
" is invalid"
, ex);
}
catch
(SAXException ex) {
throw
new
XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from "
+ resource +
" is invalid"
, ex);
}
catch
(ParserConfigurationException ex) {
throw
new
BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from "
+ resource, ex);
}
catch
(IOException ex) {
throw
new
BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from "
+ resource, ex);
}
catch
(Throwable ex) {
throw
new
BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from "
+ resource, ex);
}
}
可以看出该方法主要逻辑是根据输入流加载 Document 文档对象,然后根据得到的文档对象注册到容器,因此我们看看倒是是如何注册到容器的。
该方法首先创建一个 BeanDefinitionDocumentReader, 用于读取 BeanDefinition,该对象会调用 registerBeanDefinitions(doc, createReaderContext(resource)) 方法。
该方法最后从文档对象获取根元素,最后调用 DefaultBeanDefinitionDocumentReader.doRegisterBeanDefinitions(root) 进行注册。
该方法最核心的逻辑就是调用 parseBeanDefinitions(root, this.delegate),我们看看该方法具体实现:
protected
void
parseBeanDefinitions
(Element root, BeanDefinitionParserDelegate
delegate
) {
if
(
delegate
.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for
(
int
i =
0
; i < nl.getLength(); i++) {
Node node = nl.item(i);
if
(node instanceof Element) {
Element ele = (Element) node;
if
(
delegate
.isDefaultNamespace(ele)) {
parseDefaultElement(ele,
delegate
);
// 解析
}
else
{
delegate
.parseCustomElement(ele);
}
}
}
}
else
{
delegate
.parseCustomElement(root);
}
}
该方法就是一个解析XML 文档的步骤,核心是调用 parseDefaultElement(ele, delegate),我们进入该方法查看,该方法调用了 processBeanDefinition(ele, delegate) 方法进行解析。我们有必要看看该方法:
protected
void
processBeanDefinition
(Element ele, BeanDefinitionParserDelegate
delegate
) {
BeanDefinitionHolder bdHolder =
delegate
.parseBeanDefinitionElement(ele);
// 解析
if
(bdHolder !=
null
) {
bdHolder =
delegate
.decorateBeanDefinitionIfRequired(ele, bdHolder);
try
{
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
// 开始注册
}
catch
(BeanDefinitionStoreException ex) {
getReaderContext().error(
"Failed to register bean definition with name '"
+
bdHolder.getBeanName() +
"'"
, ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(
new
BeanComponentDefinition(bdHolder));
}
}
首先创建一个 BeanDefinitionHolder,该方法会调用 BeanDefinitionReaderUtils.registerBeanDefinition 方法, 最后执行容器通知事件。该静态方法实现如下:
*/
public
static
void
registerBeanDefinition
(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 注册
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if
(aliases !=
null
) {
for
(String
alias
: aliases) {
registry.registerAlias(beanName,
alias
);
}
}
}
可以看到首先从bean的持有者那里获取了beanName,然后调用 registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition()), 将bena的名字和 BeanDefinition 注册,我们看看最后的逻辑:
@Override
public
void
registerBeanDefinition
(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName,
"Bean name must not be empty"
);
Assert.notNull(beanDefinition,
"BeanDefinition must not be null"
);
if
(beanDefinition instanceof AbstractBeanDefinition) {
try
{
((AbstractBeanDefinition) beanDefinition).validate();
}
catch
(BeanDefinitionValidationException ex) {
throw
new
BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed"
, ex);
}
}
BeanDefinition oldBeanDefinition;
oldBeanDefinition =
this
.beanDefinitionMap.
get
(beanName);
if
(oldBeanDefinition !=
null
) {
if
(!isAllowBeanDefinitionOverriding()) {
throw
new
BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition ["
+ beanDefinition +
"] for bean '"
+ beanName +
"': There is already ["
+ oldBeanDefinition +
"] bound."
);
}
else
if
(oldBeanDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if
(
this
.logger.isWarnEnabled()) {
this
.logger.warn(
"Overriding user-defined bean definition for bean '"
+ beanName +
"' with a framework-generated bean definition: replacing ["
+
oldBeanDefinition +
"] with ["
+ beanDefinition +
"]"
);
}
}
else
if
(!beanDefinition.
equals
(oldBeanDefinition)) {
if
(
this
.logger.isInfoEnabled()) {
this
.logger.info(
"Overriding bean definition for bean '"
+ beanName +
"' with a different definition: replacing ["
+ oldBeanDefinition +
"] with ["
+ beanDefinition +
"]"
);
}
}
else
{
if
(
this
.logger.isDebugEnabled()) {
this
.logger.debug(
"Overriding bean definition for bean '"
+ beanName +
"' with an equivalent definition: replacing ["
+ oldBeanDefinition +
"] with ["
+ beanDefinition +
"]"
);
}
}
this
.beanDefinitionMap.put(beanName, beanDefinition);
}
else
{
if
(hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (
this
.beanDefinitionMap) {
this
.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions =
new
ArrayList<>(
this
.beanDefinitionNames.size() +
1
);
updatedDefinitions.addAll(
this
.beanDefinitionNames);
updatedDefinitions.
add
(beanName);
this
.beanDefinitionNames = updatedDefinitions;
if
(
this
.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons =
new
LinkedHashSet<>(
this
.manualSingletonNames);
updatedSingletons.
remove
(beanName);
this
.manualSingletonNames = updatedSingletons;
}
}
}
else
{
// Still in startup registration phase // 最终放进这个map 实现注册
this
.beanDefinitionMap.put(beanName, beanDefinition);
// 走这里 // private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
this
.beanDefinitionNames.
add
(beanName);
this
.manualSingletonNames.
remove
(beanName);
}
this
.frozenBeanDefinitionNames =
null
;
}
if
(oldBeanDefinition !=
null
|| containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
}
该方法可以说是注册bean的最后一步,将beanName和 beanDefinition 放进一个 ConcurrentHashMap(256) 中。
那么这个 beanDefinition 是时候创建的呢? 就是在 DefaultBeanDefinitionDocumentReader.processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) 方法中,在这里创建了 BeanDefinitionHolder, 而该实例中解析Bean并将Bean 保存在该对象中。
所以称为持有者。该实例会调用 parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) 方法,该方法用于解析XML文件并创建一个 BeanDefinitionHolder 返回,该方法会调用 parseBeanDefinitionElement(ele, beanName, containingBean) 方法, 我们看看该方法:
@
Nullable
public
AbstractBeanDefinition parseBeanDefinitionElement(
Element ele,
String
beanName,
@Nullable
BeanDefinition containingBean) {
this
.parseState.push(
new
BeanEntry(beanName));
String
className =
null
;
if
(ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
// 类全限定名称
}
String
parent =
null
;
if
(ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try
{
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 创建
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
parseMetaElements(ele, bd);
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
parseConstructorArgElements(ele, bd);
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
bd.setResource(
this
.readerContext.getResource());
bd.setSource(extractSource(ele));
return
bd;
}
catch
(ClassNotFoundException ex) {
error(
"Bean class ["
+ className +
"] not found"
, ele, ex);
}
catch
(NoClassDefFoundError err) {
error(
"Class that bean class ["
+ className +
"] depends on not found"
, ele, err);
}
catch
(Throwable ex) {
error(
"Unexpected failure during bean definition parsing"
, ele, ex);
}
finally
{
this
.parseState.pop();
}
return
null
;
}
我们看看该方法,可以看到,该方法从XML元素中取出 class 元素,然后拿着className调用 createBeanDefinition(className, parent) 方法,该方法核心是调用 BeanDefinitionReaderUtils.createBeanDefinition 方法,我们看看该方法:
public
static
AbstractBeanDefinition createBeanDefinition(
@Nullable
String
parentName,
@Nullable
String
className,
@Nullable
ClassLoader classLoader) throws ClassNotFoundException {
GenericBeanDefinition bd =
new
GenericBeanDefinition();
// 泛型的bean定义,也就是最终生成的bean定义。
bd.setParentName(parentName);
if
(className !=
null
) {
if
(classLoader !=
null
) {
bd.setBeanClass(ClassUtils.forName(className, classLoader));
// 设置Class 对象
}
else
{
bd.setBeanClassName(className);
}
}
return
bd;
}
该方法很简单,创建一个 Definition 的持有者,然后设置该持有者的Class对象,该对象就是我们在配置文件中配置的Class对象。最后返回。
到这里,我们一走完了第一步,创建bean工厂,生成Bean定义。但还没有实例化该类。
原文发布时间为:2018-09-6
本文作者:莫那鲁道


