ELK+logback+kafka+nginx 搭建分布式日志分析平台
ELK(Elasticsearch , Logstash, Kibana)是一套开源的日志收集、存储和分析软件组合。而且不只是java能用,其他的开发语言也可以使用,今天给大家带来的是elk+logback+kafka搭建分布式日志分析平台。本文主要讲解一下两种流程,全程linux环境(模拟现实环境,可用内存一定要大于2G,当然也可以使用windows),至于elk这些组件的原理,百度太多了,我就不重复了,重在整合。
1.我们是通过logback打印日志,然后将日志通过kafka消息队列发送到Logstash,经过处理以后存储到Elasticsearch中,然后通过Kibana图形化界面进行分析和处理。
2.我们使用Logstash读取日志文件,经过处理以后存储到Elasticsearch中,然后通过Kibana图形化界面进行分析和处理。例如我们读取nginx的日志文件,可以统计访问用户的ip地域,请求地址等等。
一、文章案例环境
1.centos 7.2(linux)
2.elasticsearch / logstash / kibana 6.3.2 下载地址
3.nginx 1.12.2
4.kafka 2.12 下载地址
5.logback/springboot 使用springboot2.0.4.RELEASE和默认的logback
6.zookeeper 3.4.12 下载地址
二、安装Elasticsearch
1.创建用户
如果你是root用户,要新建一个用户,elasticsearch不允许root用户登录,如果不是root登录请忽略这一步。
adduser elsearch
su elsearch
2.下载安装elasticsearch,以下简称es
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz
tar -zxvf elasticsearch-6.3.2.tar.gz
3.修改配置
进入es的config目录,vi elasticsearch.yml,打开注释并修改
#如果配置集群的话,只要name一样就可以自动集群了,不需要单独配置
cluster.name: nelson
network.host: 0.0.0.0 #4个0表示外网可以访问
http.port: 9200 #默认http端口
transport.tcp.port: 9300 #默认tcp端口
vi jvm.options 修改一下内存配置,我这里内存不是很多所以修改为450Mb,两者保持一致,如果你内存足够,这个可以忽略。
-Xms450M
-Xmx450M
然后就可以启动es,执行 /bin/elasticsearch 启动的时候可能会有一些提示,比如修改一些配置等,复制提示然后百度就会找到解决方案。
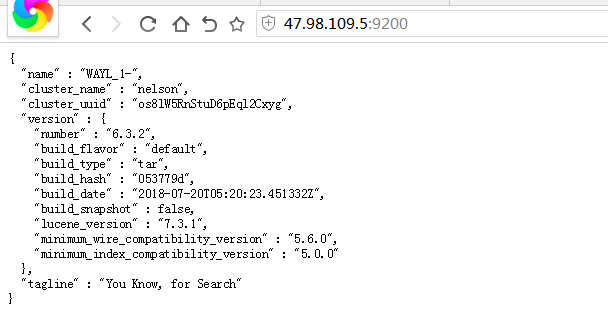
4.测试
如果es启动成功,可以通过浏览器访问 ip:9200,下图表示安装成功,如果无法访问,检查es是否成功启动或者是否防火墙拦截
二、安装Nginx
yum install -y nginx
然后 vi /etc/nginx/nginx.conf修改nginx的日志默认输出格式
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domian":"$host",'
'"host":"$server_addr",'
'"size":"$body_bytes_sent",'
'"responsetime":"$request_time",'
'"referer":"$http_referer",'
'"ua":"$http_user_agent"'
'}';
access_log /opt/access.log json;
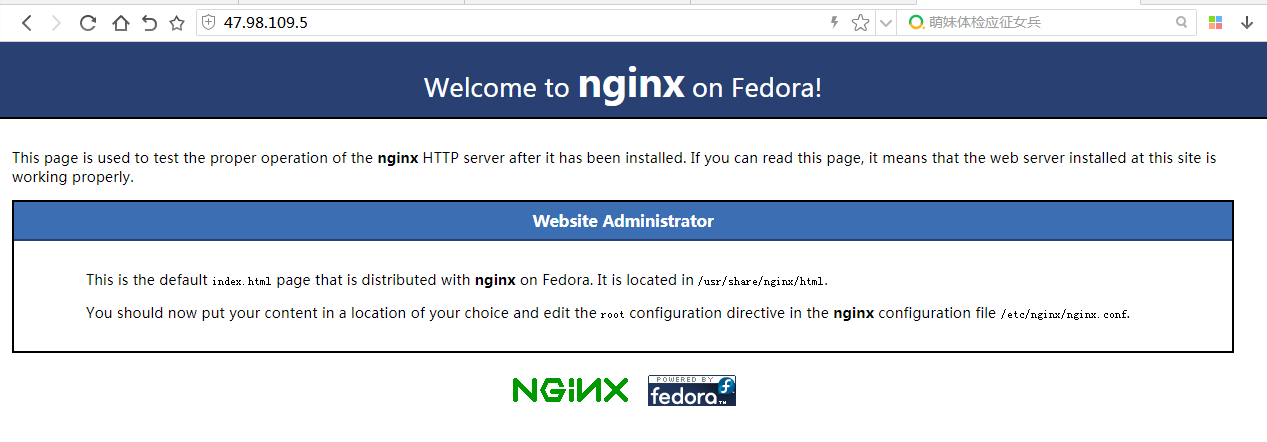
安装完成以后service nginx start启动nginx服务
打开浏览器访问 ip,nginx默认是80端口,如果可以访问表示成功安装
三、安装Logstash
1.下载安装 logstash
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz
tar -zxvf elasticsearch-6.3.2.tar.gz
2.修改内存 vi jvm.options,内存足够的话,跳过这一步
-Xms400M
-Xmx400M
3.配置输入输出
在config目录下新建文件nginx.conf
1)input表示输入源,他这里有好多插件,支持很多数据源包括文件,http等,我们这里首先收集nginx的日志。file表示读取文件;codec表示读取的文件格式,因为我们前边配置了nginx的日志格式为json,所以这里是json;start_position表示从那一行读取,他会记录上一次读取到那个位置,所以就不用担心遗漏日志了。type相当于一个tag一样,可能这里有很多输入源,后面会根据这个type进行过滤。
2)filter表示处理输入数据,因为我们前边配置了nginx的日志里边记录了用户的ip,所以我们使用geoip组件,可以根据ip匹配位置信息,下面表示你将使用那些fields字段;source表示输入json的那个属性。
3)output表示输出到哪里,可以文件、redis等,这里我们保存到es里。利用elasticsearch插件,然后配置一下es的地址,索引我们是通过日期自动生成,表示每天创建一个索引
input {
file {
path => "/var/log/nginx/access.log"
type => "nginx"
codec => "json"
start_position => "beginning"
}
}
filter {
geoip {
fields => ["city_name", "country_name", "latitude", "longitude", "region_name","region_code"]
source => "client"
}
}
output {
if [type] == "nginx" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nelson-nginx-%{+YYYY.MM.dd}"
}
stdout {}
}
}
4.启动
进入到logstash 目录执行以下命令,记得加-f
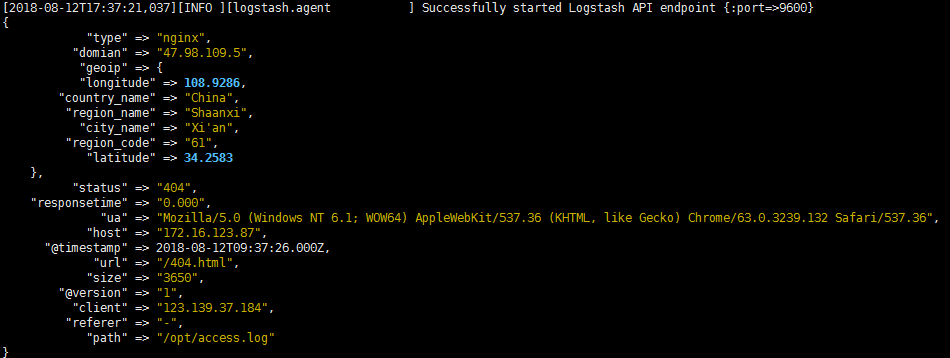
./bin/logstash -f ./config/nginx.conf
然后我们在浏览器访问nginx,输入ip就可以,这时候可以在控制台看到如下输出。
四、安装Kibana
1.下载解压
我买的服务器内存只有2G,所以我用的windows安装的Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-linux-x86_64.tar.gz
tar -zxvf kibana-6.3.2-linux-x86_64.tar.gz
windows下载地址,我这里用的是windows
https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-windows-x86_64.zip
2.修改配置
进入到config下,修改kibana.yml文件,如果你的kibana和es在一台机器上请忽略这一步,如果不在一台机器上,放开注释修改地址,我这里是在windows上运行的。
elasticsearch.url: "http://localhost:9200"
//我的配置
//elasticsearch.url: "http://47.98.109.5:9200"
3.启动
进入到kibana目录下
//linux
./bin/kibana
//windows 双击运行bin目录下的kibana.bat文件
4.实战
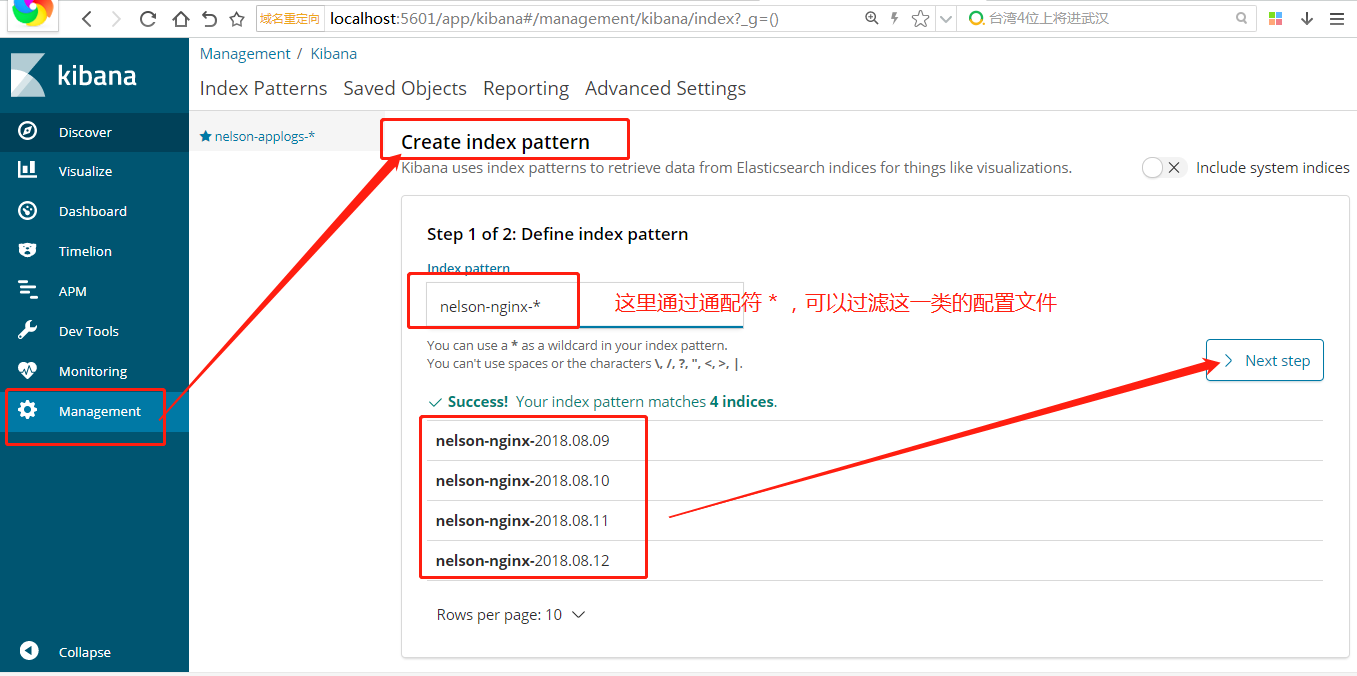
打开浏览器访问ip:5601
第一次进来我们要创建index pattern,因为我们的日志是按照日期每天存储的,所以要将这些日志聚合到一起。按照下图进行设置,因为我已经有4天的日志了,所以过滤后有四条满足。
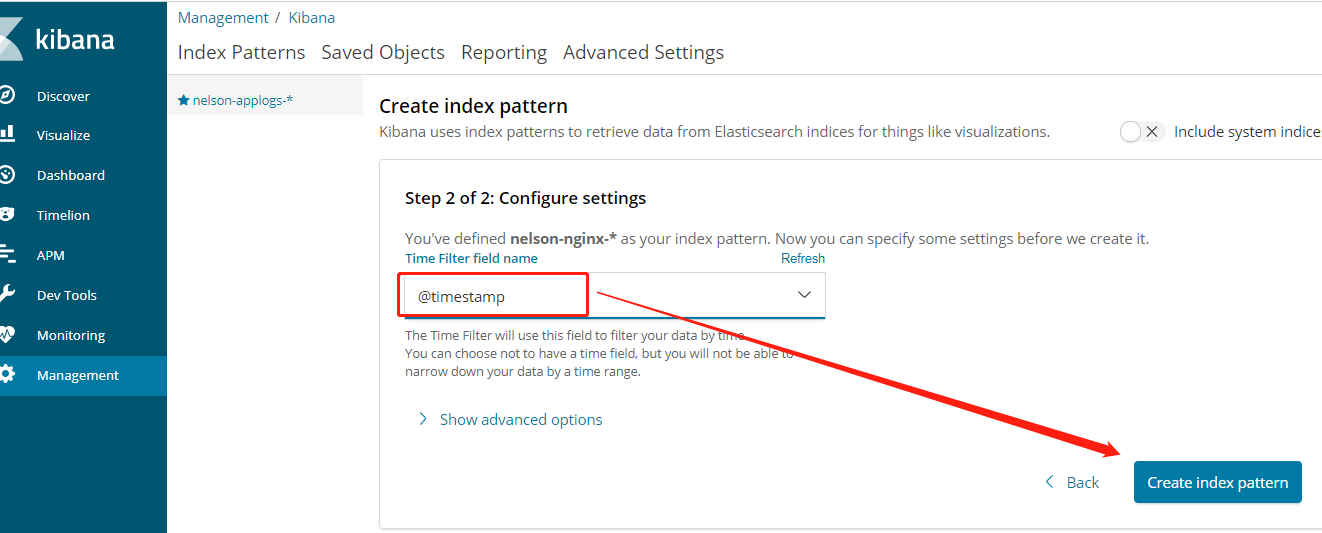
可以根据时间段过滤,查看数据的录入量,这也表示网站访问量。
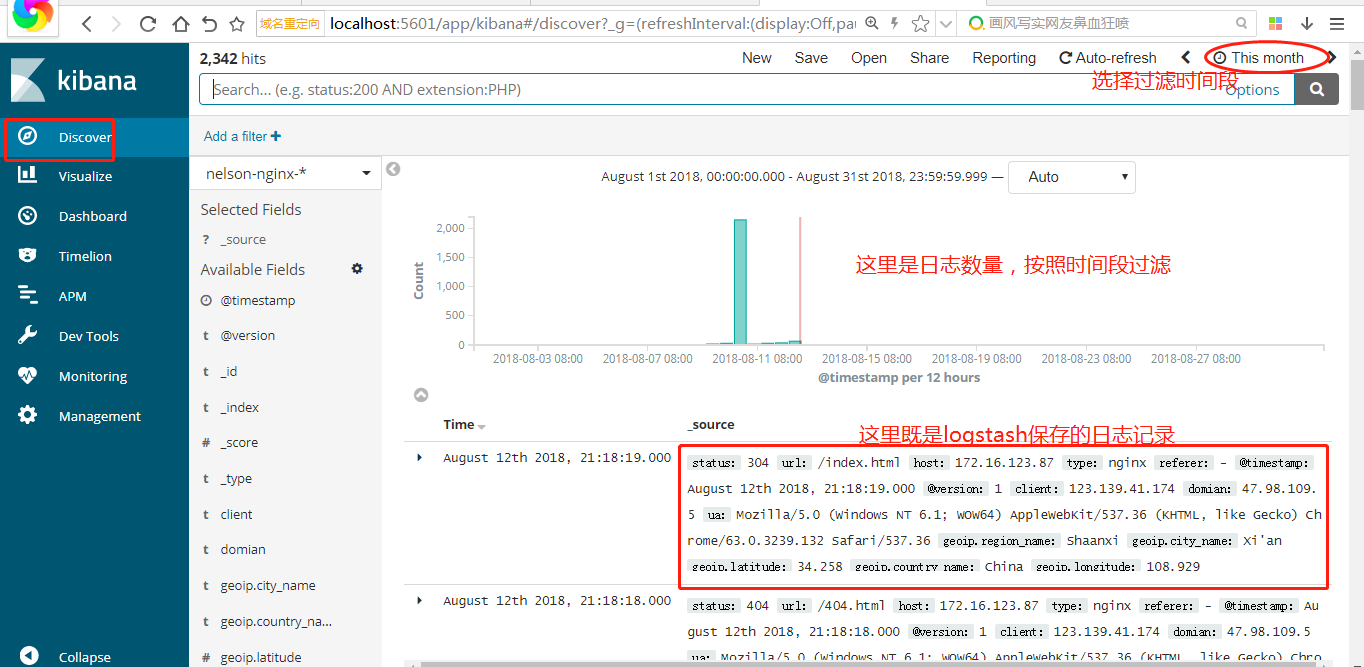
当然也可以通过rest api查询数据,支持复杂查询。索引也可以使用通配符
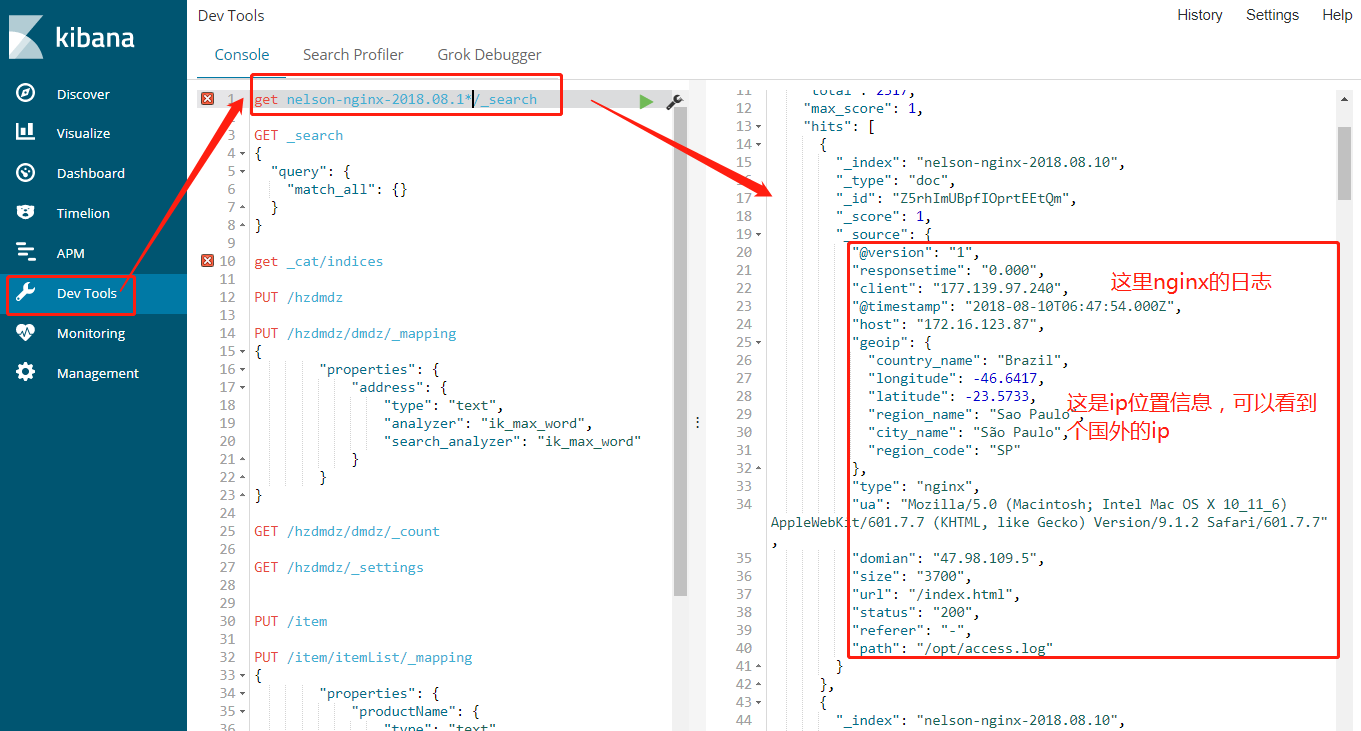
5.统计用户区域分布
我们要创建一个统计,然后选择饼状图,下一步选择你要统计的index pattern,这个在上一步已经创建成功
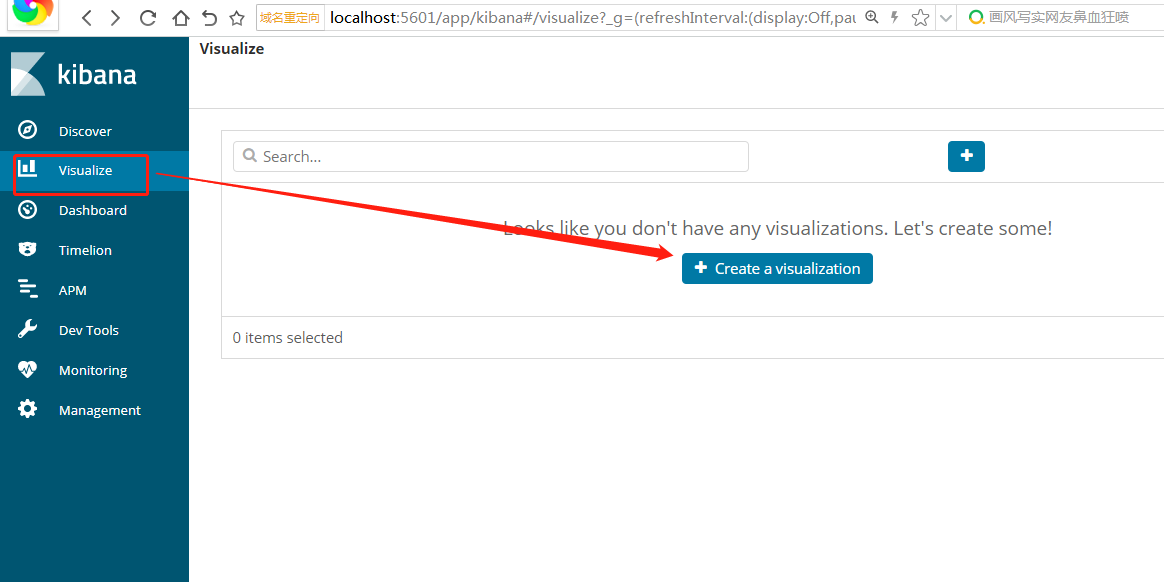
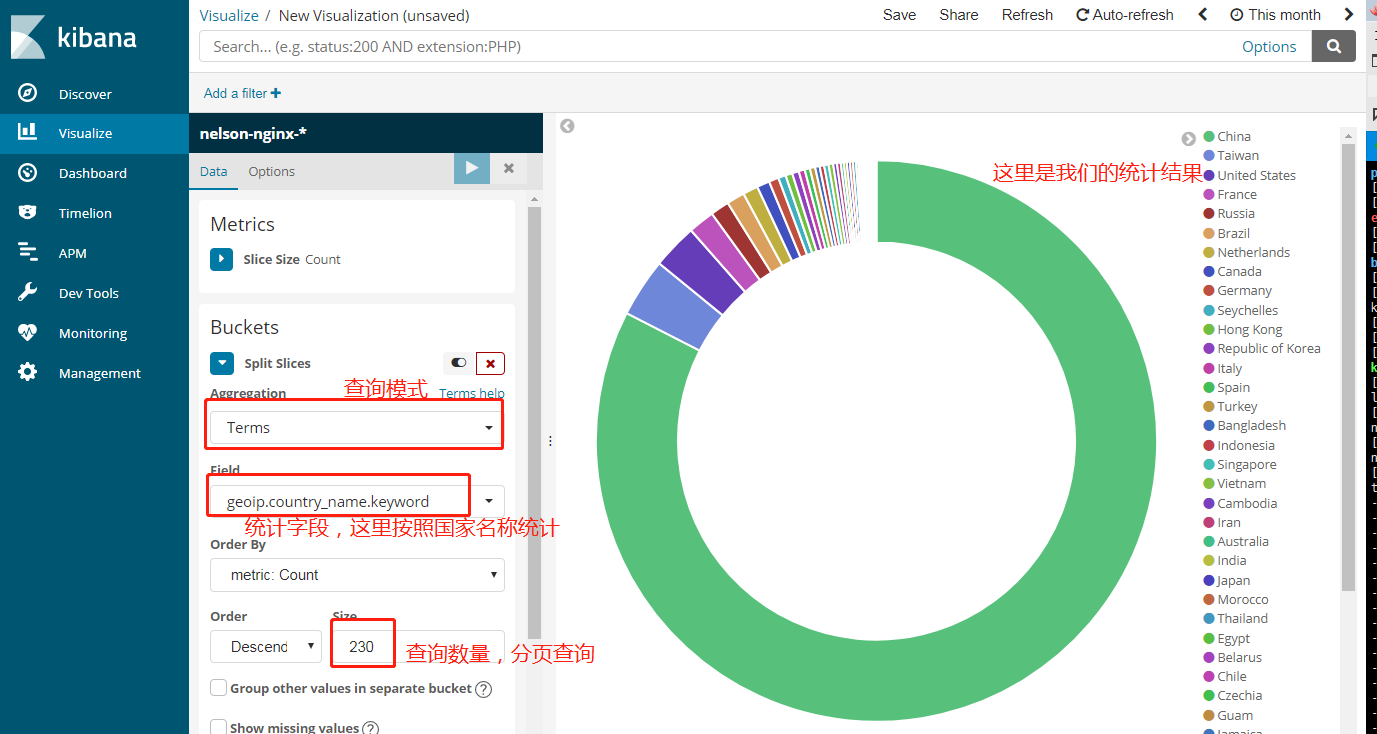
添加子查询
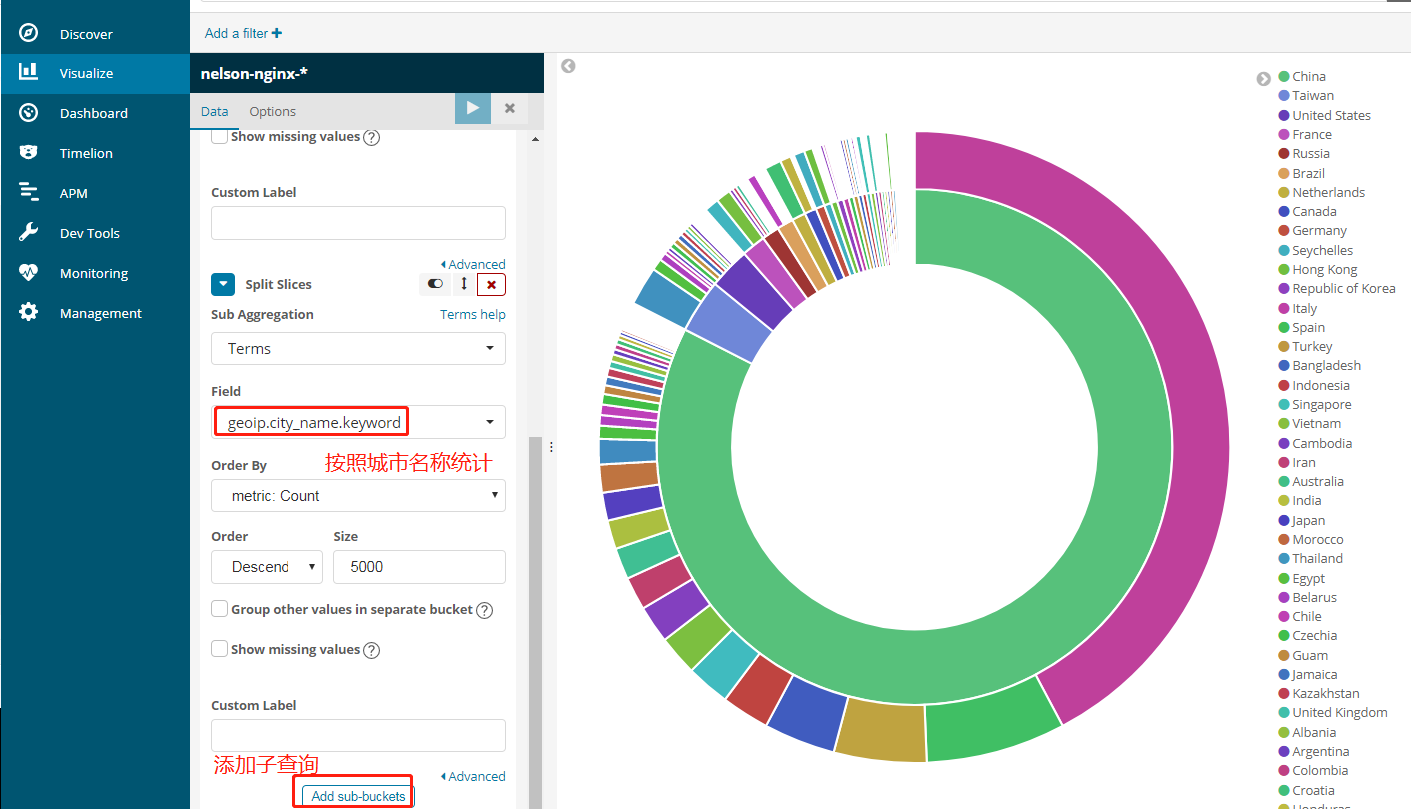
最后我们来一个很复杂的统计,按照国家->城市->浏览器类型,但是用kibana是很简单的,而且速度超快。
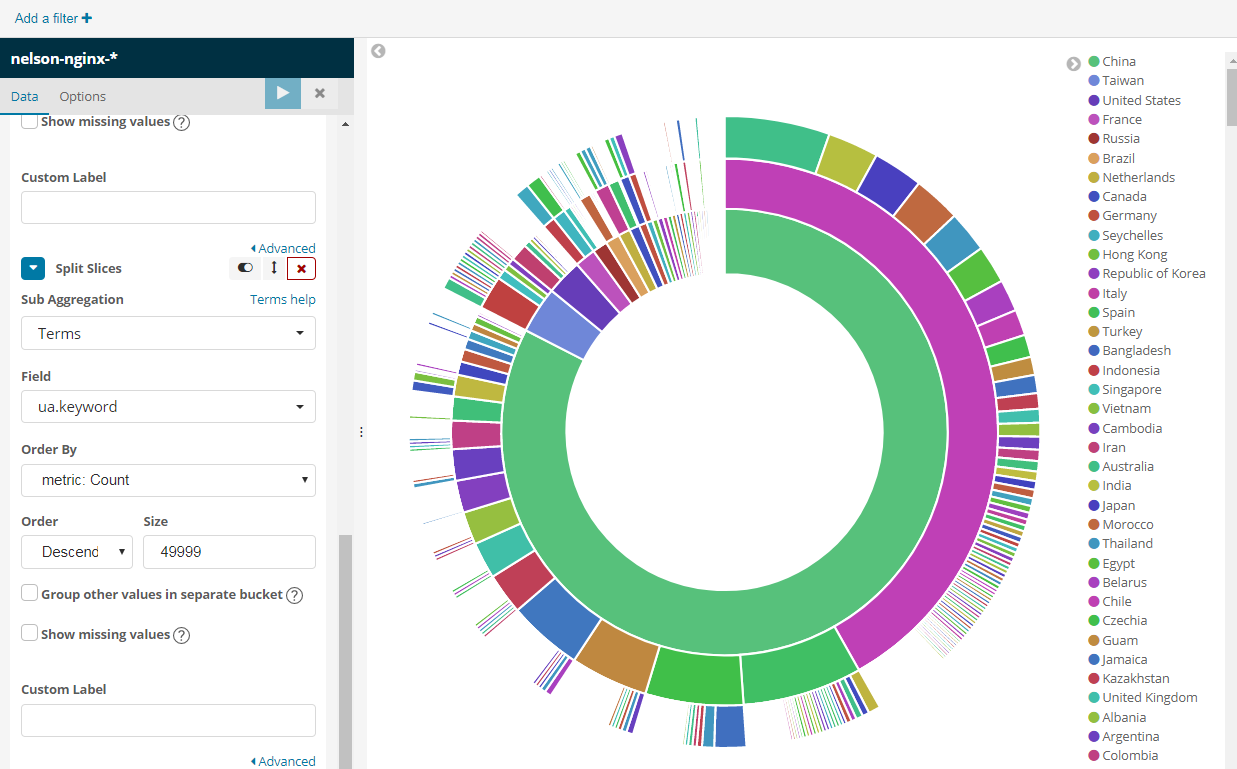
到这里利用elk分析nginx的日志就算完成了,剩下的自己研究,基本类似,一些基本概念还是要自己去百度了。
接下来是通过logback+kafka保存程序日志。因为生产环境中,分布式系统,你的服务可能有N个,例如基于docker,我们不可能给每个docker容器里安装一个logstash,所以需要通过网络向logbash传输数据。这里是通过logback产生日志,然后通过kafka消息队列传输到logstash。
五、安装Zookeeper
kafka 是需要zookeeper的,下面简称zk。
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
tar -zxvf zookeeper-3.4.12.tar.gz
#复制配置
cp zoo_sample.cfg zoo.cfg
修改配置
vi zoo.cfg
dataDir=/root/zk/data #改为你zk目录/data
然后进入zk目录启动,如果不保存说明就启动成功了。
./bin/zkServer.sh start
六、安装Kafka
安装解压
wget http://mirror.bit.edu.cn/apache/kafka/2.0.0/kafka_2.12-2.0.0.tgz
tar -zxvf kafka_2.12-2.0.0.tgz
cd kafka_2.12-2.0.0
然后修改config目录吓得server.properties,如果你的zk和你的kafka不在一台机器的话,你要修改zk的地址。
还有一点要注意的是如果你使用阿里云这一类产品的时候一定要注意下面配置,特别坑:
listeners=PLAINTEXT://172.31.167.25:9092 #阿里云内网地址
advertised.listeners=PLAINTEXT://47.104.255.217:9092 #阿里云外网地址
启动kafka server
bin/kafka-server-start.sh config/server.properties
创建一个 名称为applog 的topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic applog
查看所有topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
消息的生产者,启动以后,在控制台输入信息,然后回车发送
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic applog
消息的消费者,如果生产者那里给applog这个top输入信息发送,消费者这边就会在收到,然后在控制台打印出来。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic applog --from-beginning
接下来开发,我们只需要启动kafka server即可。上面这个消费者和生产者只是为了测试。
七、程序中使用logback
我们新建一个springboot项目,然后加入如下依赖。coding地址:点击访问
compile('org.springframework.boot:spring-boot-starter-webflux')
compile('org.springframework.kafka:spring-kafka')
compile group: 'net.logstash.logback', name: 'logstash-logback-encoder', version: '5.2'
compile group: 'com.github.danielwegener', name: 'logback-kafka-appender', version: '0.1.0'
因为springboot自带logback,所以我们也不需要手动增加依赖。然后我们在resource目录下新建文件logback-spring.xml,这样话,springboot自动读取配置文件优先顺序比较高,具体文章可以去springboot文档去查看。
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<contextName>logback</contextName>
<property name="log.path" value="logs/elk.log" />
<!--输出到控制台-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<!-- <filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>-->
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!--输出到文件-->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logback.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!--输出到kafka-->
<appender name="KafkaAppender" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder class="com.github.danielwegener.logback.kafka.encoding.LayoutKafkaMessageEncoder">
<layout class="net.logstash.logback.layout.LogstashLayout" >
<includeContext>false</includeContext>
<includeCallerData>true</includeCallerData>
<customFields>{"system":"test"}</customFields>
<fieldNames class="net.logstash.logback.fieldnames.ShortenedFieldNames"/>
</layout>
<charset>UTF-8</charset>
</encoder>
<!--kafka topic 需要与配置文件里面的topic一致 否则kafka会沉默并鄙视你-->
<topic>applog</topic>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.HostNameKeyingStrategy" />
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<producerConfig>bootstrap.servers=47.104.255.217:9092</producerConfig>
</appender>
<!--你可能还需要加点这个玩意儿-->
<logger name="Application_ERROR">
<appender-ref ref="KafkaAppender"/>
</logger>
<root level="info">
<appender-ref ref="console" />
<appender-ref ref="file" />
<appender-ref ref="KafkaAppender" />
</root>
</configuration>
然后我们新建controller
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
// 注意导包,不要导错
@RestController
public class IndexController {
private Logger logger = LoggerFactory.getLogger(this.getClass());
@RequestMapping("/")
public void index(){
logger.trace("日志输出 trace");
logger.debug("日志输出 debug");
logger.info("日志输出 info");
logger.warn("日志输出 warn");
logger.error("日志输出 error");
}
}
这个时候我们需要,修改一下logback的配置文件了,要加入kafka的输入。修改logbstash的config目录吓得nginx.conf
input {
#nginx日志的输入
file {
path => "/opt/access.log"
type => "nginx"
codec => "json"
start_position => "beginning"
}
#kafka日志输入
kafka {
topics => "applog"
type => "kafka"
bootstrap_servers => "47.104.255.217:9092"
codec => "json"
}
}
filter {
if [type] == "nginx" {
geoip {
fields => ["city_name", "country_name", "latitude", "longitude", "region_name","region_code"]
source => "client"
}
}
}
output {
#都输出到es中,但是索引不一样
if [type] == "nginx" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nelson-nginx-%{+YYYY.MM.dd}"
}
stdout {}
}
if [type] == "kafka" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nelson-applogs-%{+YYYY.MM.dd}"
}
stdout {}
}
}
然后执行../bin/logstash -f ./nginx.conf,启动logstash,这时候我们的logstash就有两个输入源了。
访问项目中controller地址,看日志是否打印出来。
idea的控制台打印了日志
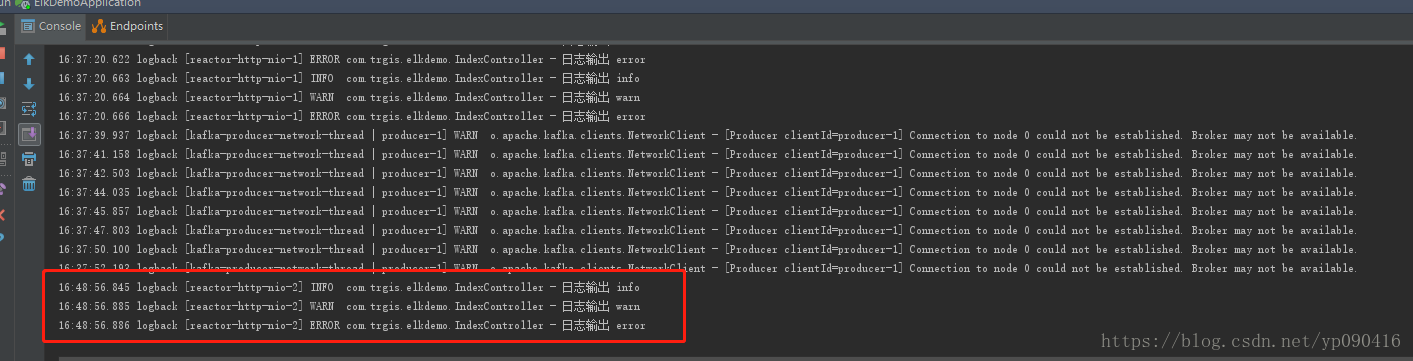
这是logstash打印出来的日志,如果这个出来基本可以说明成功了。
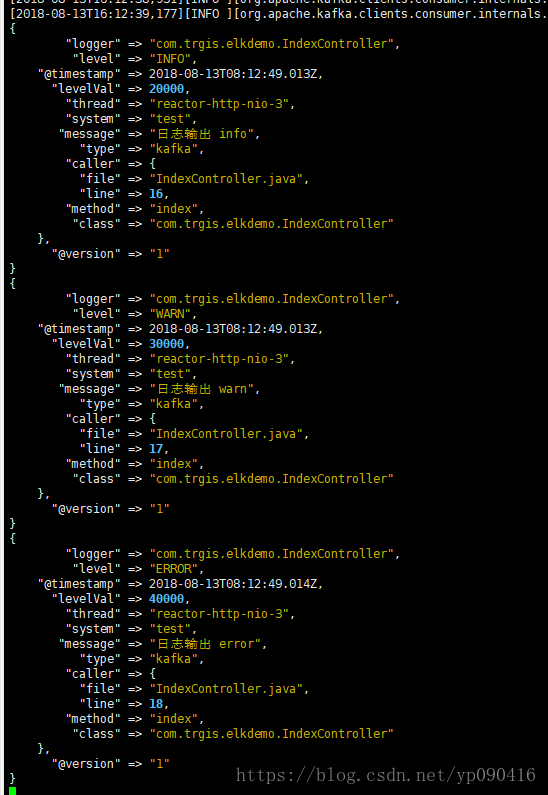
最后我们在kibana中通过rest请求es,这里表示查到数据。
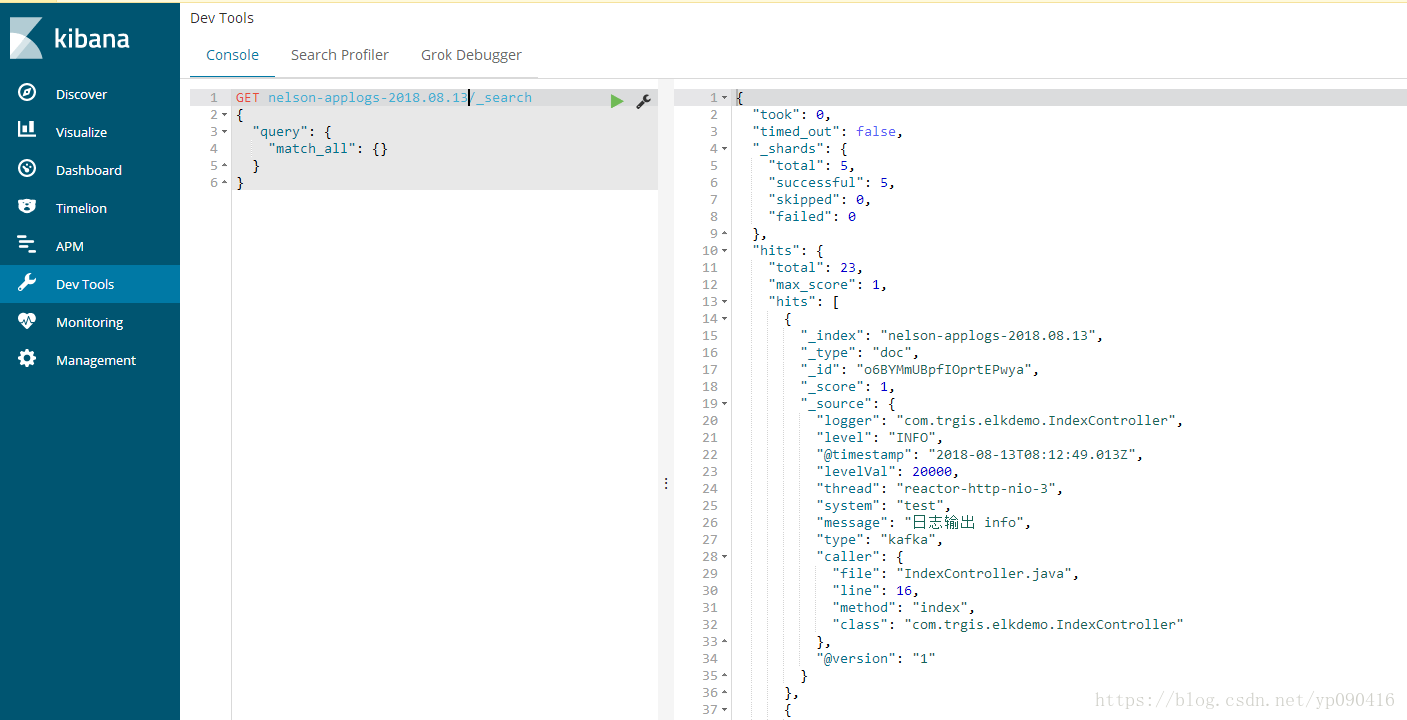
要是想统计日志,可以参考上边kibanam那一块,类似。
到这里,本篇文章就结束了,elk+nginx 和 elk+logback+kafka都已经实现了,考虑篇幅,所以这里没有细讲这些概念。这些呢就自行百度吧,不重复造轮子了,只要能串通,剩下的用到啥看官方文档或者百度。
关注
如果有问题,请在下方评论,或者加群讨论 200909980
关注下方微信公众号,可以及时获取到各种技术的干货哦,如果你有想推荐的帖子,也可以联系我们的。

