热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
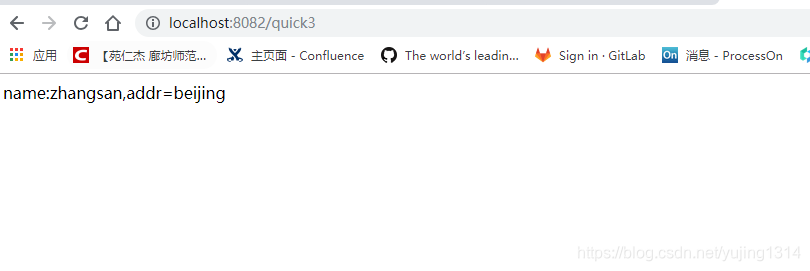
【SpringBoot】整合Mybatis
[Java 并发基础]多线程编程
【SpringBoot】如何使用策略模式+抽象工厂+反射
Redis 入门、基础。(五种基本类型使用场景)
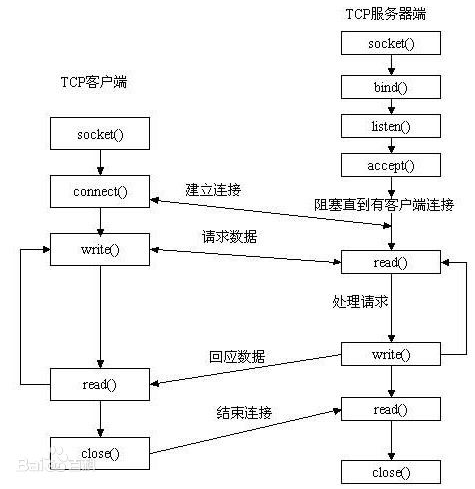
第十七章 Python网络编程
【vue】v-if和v-show的区别
三万字长文:JVM内存问题排查Cookbook
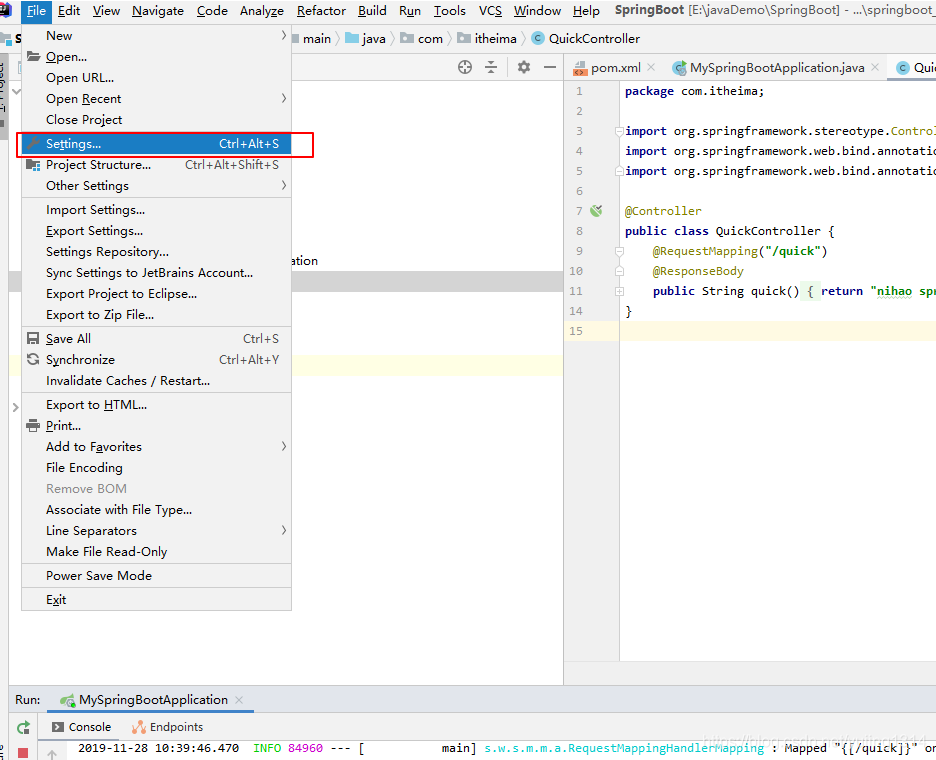
【SpringBoot】如何配置热部署
如何在GitHub上传项目
【vue】框架搭建
< 每日小技巧: 基于Vue状态的过渡动画 - Transition 和 TransitionGroup>
每天解析一个脚本(33)
Docker 镜像及其命令
【vue】setInterval的嵌套实例
Docker 下载加速
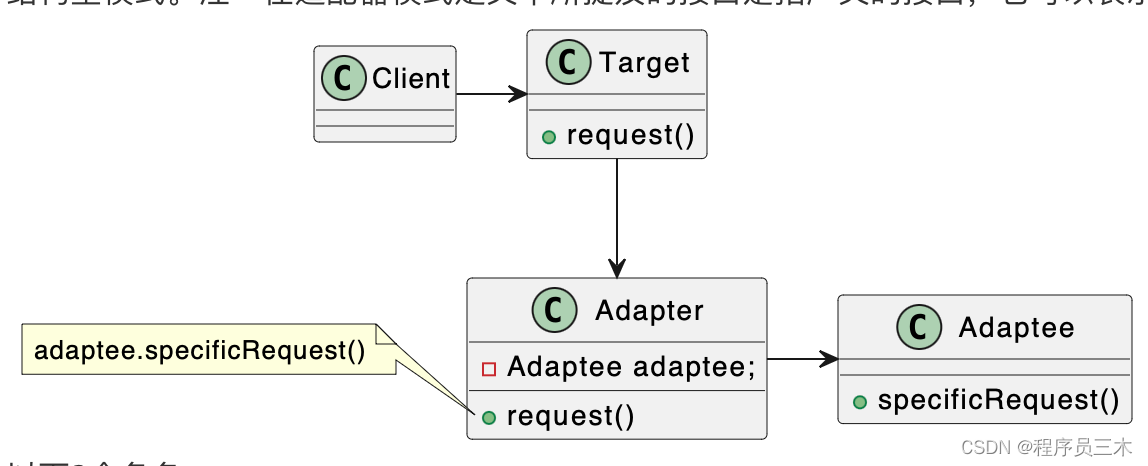
[设计模式Java实现附plantuml源码~结构型]不兼容结构的协调——适配器模式
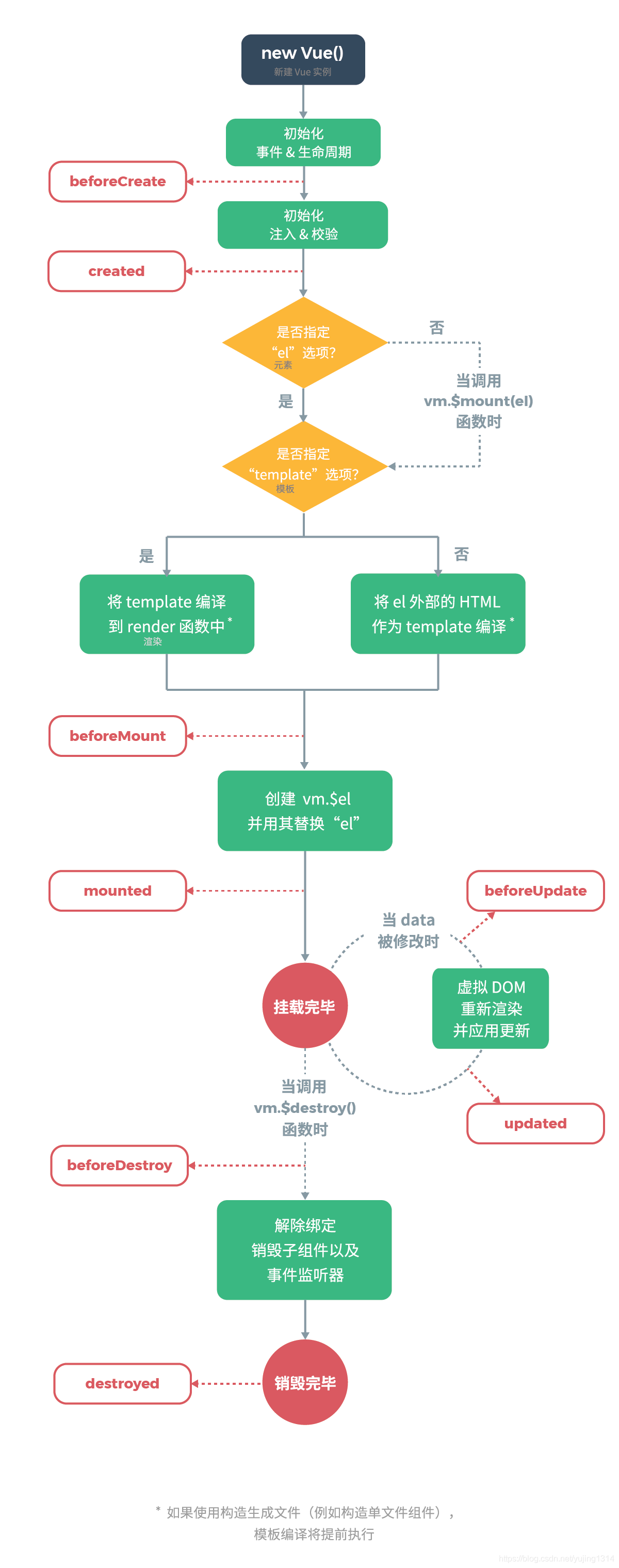
【vue】生命周期钩子函数的执行过程和父子组件钩子函数的执行顺序
Docker容器常用命令
构建高效机器学习模型:从数据预处理到模型优化
[并发编程基础] Java线程的创建方式
【vue】如何抽取公共组件并全局注册
MongoDB扩大与谷歌云的合作,助推各行业客户部署和扩展新型应用
[设计模式Java实现附plantuml源码~结构型]对象的间接访问——代理模式
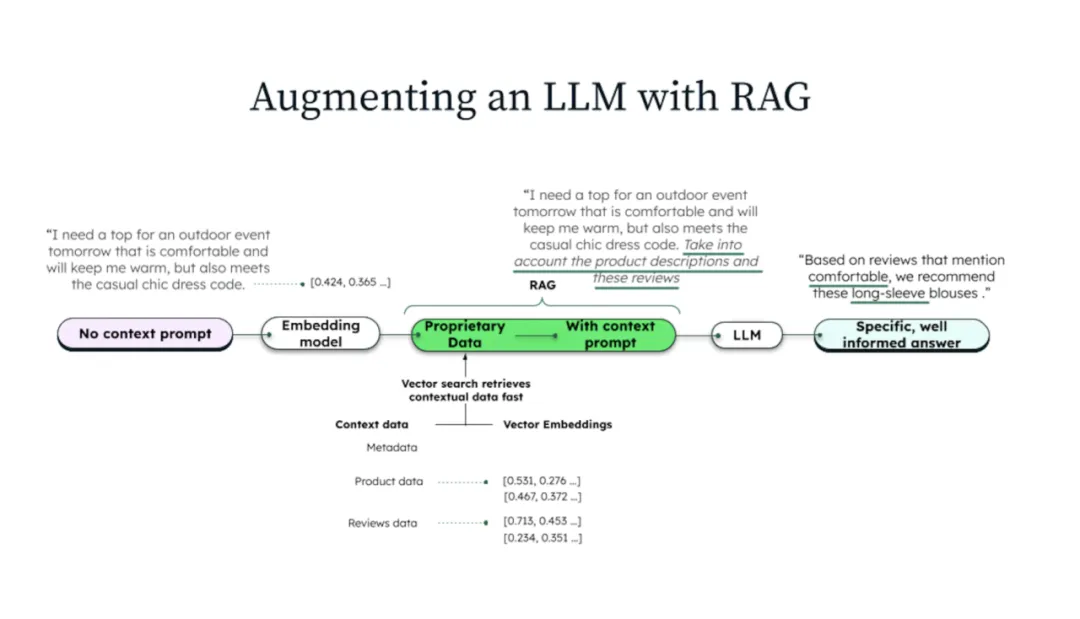
生成式AI入门必读:基本概念、数据挑战与解决方案
[m1pro ] ssh: connect to host localhost port 22: Connection refused
第十六章 Python正则表达式
Docker 概述与安装
MongoDB观点:让生成式AI成为业务增长的新动能,游戏公司可以这样做
OpenCV的版本
Linux 常用基本命令
每天解析一个脚本(32)
第十五章 Python多进程与多线程
MongoDB性能最佳实践:如何制定更有效的基准测试?
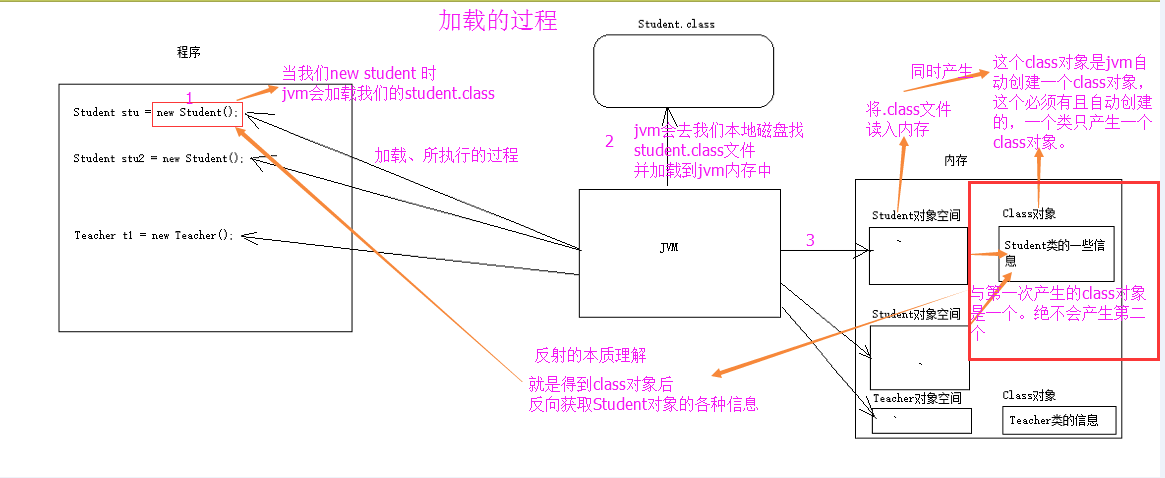
Java 反射
第十四章 Python发送邮件(常见四种邮件内容)
VM安装Centos(下)
第十三章 Python数据库编程
第十二章 Python文件操作
IDEA DeBug
第十一章 Python常用内建函数
Java 泛型(下)
Java 泛型(上)
第十章 Python常用标准库使用(必会)
OpenCV主要功能及模块介绍(2)
Java 核心类API(下)
OpenCV主要功能及模块介绍(1)