【编者按】阿里一站式大数据平台——“数加”平台发布后,业内对其核心ODPS也就是现在的大数据计算服务MaxCompute极为关注。平台介绍以及开发背景可见《阿里十年经验输出,大数据平台“数加”的前世今生》。特别分享一篇阿里大数据技术专家刘吉哲的一篇关于MPI机器学习编程框架的文章。
下为正文:
ODPS作为一个大数据处理服务,有着得天独厚的优势去承载大规模机器学习,PAI就是这样一个孕育在ODPS之上的大规模机器学习平台。
在PAI平台上,为了支持亿级的数据量、千万级的特征,所有机器学习算法都是分布式的。你可以使用耳熟能详的逻辑回归、支持向量机、随机森林等算法,也可以使用被业界称道的如XGBOOST等优秀开源算法,还可以使用聚类、自然语言、图、深度学习、协同过滤等领域相关的算法。
除了丰富的、分门别类的机器学习算法,PAI平台支持算法开发者开发自己的算法,并随时在PAI平台发布。统一的调用命令、便捷的编程接口大大简化了开发者的工作。作为一个开发者,要做的就是定义自己的算法名称、参数和基于编程框架开发算法逻辑,无需关心任何平台层面的事情。本文以逻辑回归为例,介绍如何在PAI平台上基于MPI框架开发分布式算法。
ODPS支持MPICH,接口与标准MPICH无异,详细可参考其官网介绍。本文介绍的逻辑回归使用LBFGS作为优化算法,原理不再详述,我们需要解决的是如何基于MPI实现亿级的样本量、千万级特征的LBFGS。
LBFGS的迭代过程涉及到两个重要的计算:
计算似然函数的全局值
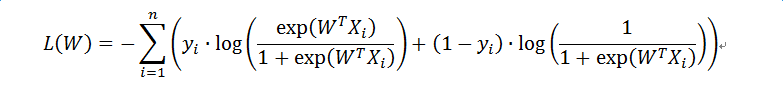
计算梯度向量
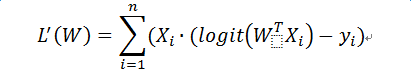

好了,原理就是这样,下面看看ODPS的PAI平台提供了哪些编程接口,可以达到上述并行化的目的。
编程框架和接口是C++的。基于MPI框架的算法,都需要继承自MPIAlgorithm基类,并实现纯虚函数Run,逻辑回归当然也不例外。

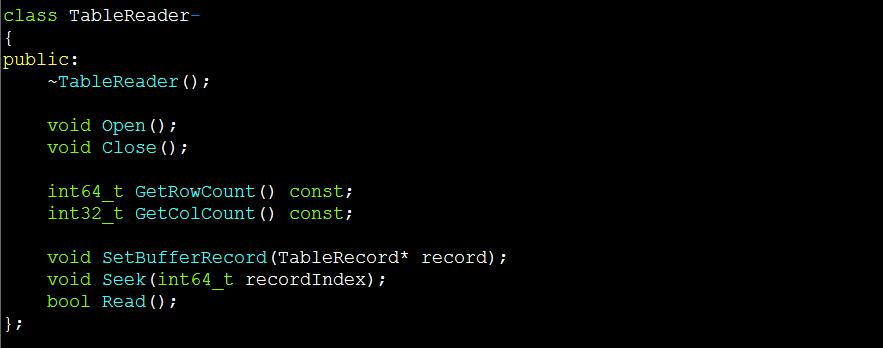
MPIContext定义了运行时上下文,可以获取环境参数、创建输入输出接口等。逻辑回归的输入数据位于ODPS表中,那么可以这样创建表的读接口:
通过表的读接口,可以获取输入表的总行数(样本数)、总列数(特征数)、跳转到指定行开始读等。具体定义如下:
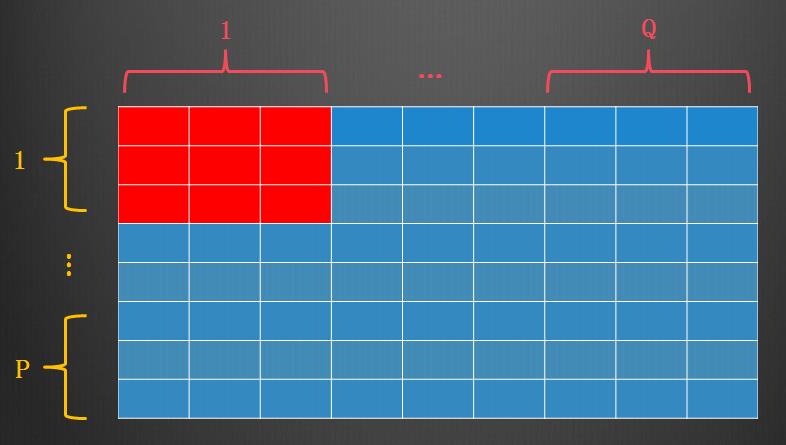
如果知道了总的并行机器数、自己所在的机器序号、表的总行数,要计算平均每个机器读多少行、自己该从第几行开始读,不难吧?特征的切片方式和样本类似,只是被切分的是总的列数。因此,我们需要知道总的机器数和自己机器的序号,该MPI函数出场了。标准MPI库函数MPI_Comm_size和MPI_Comm_rank可以达到我们的目的。

有了这些接口,可以完成本机器上数据的计算,如何实现之前提到的机器间通信?熟悉MPI的人应该并不陌生,MPI提供了大量通信函数,最基础的MPI_Send、MPI_Recv,高级的MPI_Allgather、MPI_Allreduce,都可以信手拈来。
说到这里,已经具备了所有实现并行LBFGS的条件,现在所要做的是根据LBFGS原理去实现Run函数,再把实现代码编译成动态链接库(.so)。除此之外,还需要一个XML格式的文件,我们称之为“算法描述文件”,定义算法需要的参数等,最难的并行框架都搞定了,这个一定难不倒你。把.so和“算法描述文件”一起上传到ODPS,就完成了整个算法的发布过程。如果你愿意授权,那别人就可以在ODPS上使用你的算法了。
ODPS已经在云栖社区有了自己的圈子——ODPS,欢迎加入讨论。 :)