很久没有做技术方面的分享了,今天闲来有空写一篇关于Kafka通信方面的文章与大家共同学习。
一、Kafka通信机制的整体结构
这个图采用的就是我们之前提到的SEDA多线程模型,链接如下:
http://www.jianshu.com/p/e184fdc0ade4
1、对于broker来说,客户端连接数量有限,不会频繁新建大量连接。因此一个Acceptor thread线程处理新建连接绰绰有余。
2、Kafka高吐吞量,则要求broker接收和发送数据必须快速,因此用proccssor thread线程池处理,并把读取客户端数据转交给缓冲区,不会导致客户端请求大量堆积。
3、Kafka磁盘操作比较频繁会且有io阻塞或等待,IO Thread线程数量一般设置为proccssor thread num两倍,可以根据运行环境需要进行调节。
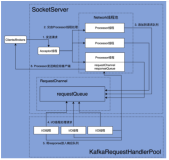
二、SocketServer整体设计时序图
说明:
Kafka SocketServer是基于Java NIO来开发的,采用了Reactor的模式,其中包含了1个Acceptor负责接受客户端请求,N个Processor线程负责读写数据,M个Handler来处理业务逻辑。在Acceptor和Processor,Processor和Handler之间都有队列来缓冲请求。
下面我们就针对以上整体设计思路分开讲解各个不同部分的源代码。
2.1 启动初始化工作
def startup() {
val quotas = new ConnectionQuotas(maxConnectionsPerIp, maxConnectionsPerIpOverrides)
for(i <- 0 until numProcessorThreads) {
processors(i) = new Processor(i,
time,
maxRequestSize,
aggregateIdleMeter,
newMeter("IdlePercent", "percent", TimeUnit.NANOSECONDS, Map("networkProcessor" -> i.toString)),
numProcessorThreads,
requestChannel,
quotas,
connectionsMaxIdleMs)
Utils.newThread("kafka-network-thread-%d-%d".format(port, i), processors(i), false).start()
}
newGauge("ResponsesBeingSent", new Gauge[Int] {
def value = processors.foldLeft(0) { (total, p) => total + p.countInterestOps(SelectionKey.OP_WRITE) }
})
// register the processor threads for notification of responses
requestChannel.addResponseListener((id:Int) => processors(id).wakeup())
// start accepting connections
this.acceptor = new Acceptor(host, port, processors, sendBufferSize, recvBufferSize, quotas)
Utils.newThread("kafka-socket-acceptor", acceptor, false).start()
acceptor.awaitStartup
info("Started")
}
说明:
ConnectionQuotas对象负责管理连接数/IP, 创建一个Acceptor侦听者线程,初始化N个Processor线程,processors是一个线程数组,可以作为线程池使用,默认是三个,Acceptor线程和N个Processor线程中每个线程都独立创建Selector.open()多路复用器,相关代码在下面:
val numNetworkThreads = props.getIntInRange("num.network.threads", 3, (1, Int.MaxValue));
val serverChannel = openServerSocket(host, port);
范围可以设定从1到Int的最大值。
2.2 Acceptor线程
def run() {
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
startupComplete()
var currentProcessor = 0
while(isRunning) {
val ready = selector.select(500)
if(ready > 0) {
val keys = selector.selectedKeys()
val iter = keys.iterator()
while(iter.hasNext && isRunning) {
var key: SelectionKey = null
try {
key = iter.next
iter.remove()
if(key.isAcceptable)
accept(key, processors(currentProcessor))
else
throw new IllegalStateException("Unrecognized key state for acceptor thread.")
// round robin to the next processor thread
currentProcessor = (currentProcessor + 1) % processors.length
} catch {
case e: Throwable => error("Error while accepting connection", e)
}
}
}
}
debug("Closing server socket and selector.")
swallowError(serverChannel.close())
swallowError(selector.close())
shutdownComplete()
}
2.1.1 注册OP_ACCEPT事件
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
2.1.2 内部逻辑
此处采用的是同步非阻塞逻辑,每隔500MS轮询一次,关于同步非阻塞的知识点在http://www.jianshu.com/p/e9c6690c0737
当有请求到来的时候采用轮询的方式获取一个Processor线程处理请求,代码如下:
currentProcessor = (currentProcessor + 1) % processors.length
之后将代码添加到newConnections队列之后返回,代码如下:
def accept(socketChannel: SocketChannel) { newConnections.add(socketChannel) wakeup()}
//newConnections是一个线程安全的队列,存放SocketChannel通道
private val newConnections = new ConcurrentLinkedQueue[SocketChannel]()
2.3 kafka.net.Processor
override def run() {
startupComplete()
while(isRunning) {
// setup any new connections that have been queued up
configureNewConnections()
// register any new responses for writing
processNewResponses()
val startSelectTime = SystemTime.nanoseconds
val ready = selector.select(300)
currentTimeNanos = SystemTime.nanoseconds
val idleTime = currentTimeNanos - startSelectTime
idleMeter.mark(idleTime)
// We use a single meter for aggregate idle percentage for the thread pool.
// Since meter is calculated as total_recorded_value / time_window and
// time_window is independent of the number of threads, each recorded idle
// time should be discounted by # threads.
aggregateIdleMeter.mark(idleTime / totalProcessorThreads)
trace("Processor id " + id + " selection time = " + idleTime + " ns")
if(ready > 0) {
val keys = selector.selectedKeys()
val iter = keys.iterator()
while(iter.hasNext && isRunning) {
var key: SelectionKey = null
try {
key = iter.next
iter.remove()
if(key.isReadable)
read(key)
else if(key.isWritable)
write(key)
else if(!key.isValid)
close(key)
else
throw new IllegalStateException("Unrecognized key state for processor thread.")
} catch {
case e: EOFException => {
info("Closing socket connection to %s.".format(channelFor(key).socket.getInetAddress))
close(key)
} case e: InvalidRequestException => {
info("Closing socket connection to %s due to invalid request: %s".format(channelFor(key).socket.getInetAddress, e.getMessage))
close(key)
} case e: Throwable => {
error("Closing socket for " + channelFor(key).socket.getInetAddress + " because of error", e)
close(key)
}
}
}
}
maybeCloseOldestConnection
}
debug("Closing selector.")
closeAll()
swallowError(selector.close())
shutdownComplete()
}
先来重点看一下configureNewConnections这个方法:
private def configureNewConnections() {
while(newConnections.size() > 0) {
val channel = newConnections.poll()
debug("Processor " + id + " listening to new connection from " + channel.socket.getRemoteSocketAddress)
channel.register(selector, SelectionKey.OP_READ)
}
}
循环判断NewConnections的大小,如果有值则弹出,并且注册为OP_READ读事件。
再回到主逻辑看一下read方法。
def read(key: SelectionKey) {
lruConnections.put(key, currentTimeNanos)
val socketChannel = channelFor(key)
var receive = key.attachment.asInstanceOf[Receive]
if(key.attachment == null) {
receive = new BoundedByteBufferReceive(maxRequestSize)
key.attach(receive)
}
val read = receive.readFrom(socketChannel)
val address = socketChannel.socket.getRemoteSocketAddress();
trace(read + " bytes read from " + address)
if(read < 0) {
close(key)
} else if(receive.complete) {
val req = RequestChannel.Request(processor = id, requestKey = key, buffer = receive.buffer, startTimeMs = time.milliseconds, remoteAddress = address)
requestChannel.sendRequest(req)
key.attach(null)
// explicitly reset interest ops to not READ, no need to wake up the selector just yet
key.interestOps(key.interestOps & (~SelectionKey.OP_READ))
} else {
// more reading to be done
trace("Did not finish reading, registering for read again on connection " + socketChannel.socket.getRemoteSocketAddress())
key.interestOps(SelectionKey.OP_READ)
wakeup()
}
}
说明
1、把当前SelectionKey和事件循环时间放入LRU映射表中,将来检查时回收连接资源。
2、建立BoundedByteBufferReceive对象,具体读取操作由这个对象的readFrom方法负责进行,返回读取的字节大小。
- 如果读取完成,则修改状态为receive.complete,并通过requestChannel.sendRequest(req)将封装好的Request对象放到RequestQueue队列中。
- 如果没有读取完成,则让selector继续侦听OP_READ事件。
2.4 kafka.server.KafkaRequestHandler
def run() {
while(true) {
try {
var req : RequestChannel.Request = null
while (req == null) {
// We use a single meter for aggregate idle percentage for the thread pool.
// Since meter is calculated as total_recorded_value / time_window and
// time_window is independent of the number of threads, each recorded idle
// time should be discounted by # threads.
val startSelectTime = SystemTime.nanoseconds
req = requestChannel.receiveRequest(300)
val idleTime = SystemTime.nanoseconds - startSelectTime
aggregateIdleMeter.mark(idleTime / totalHandlerThreads)
}
if(req eq RequestChannel.AllDone) {
debug("Kafka request handler %d on broker %d received shut down command".format(
id, brokerId))
return
}
req.requestDequeueTimeMs = SystemTime.milliseconds
trace("Kafka request handler %d on broker %d handling request %s".format(id, brokerId, req))
apis.handle(req)
} catch {
case e: Throwable => error("Exception when handling request", e)
}
}
}
说明
KafkaRequestHandler也是一个事件处理线程,不断的循环读取requestQueue队列中的Request请求数据,其中超时时间设置为300MS,并将请求发送到apis.handle方法中处理,并将请求响应结果放到responseQueue队列中去。
代码如下:
try{
trace("Handling request: " + request.requestObj + " from client: " + request.remoteAddress)
request.requestId match {
case RequestKeys.ProduceKey => handleProducerOrOffsetCommitRequest(request)
case RequestKeys.FetchKey => handleFetchRequest(request)
case RequestKeys.OffsetsKey => handleOffsetRequest(request)
case RequestKeys.MetadataKey => handleTopicMetadataRequest(request)
case RequestKeys.LeaderAndIsrKey => handleLeaderAndIsrRequest(request)
case RequestKeys.StopReplicaKey => handleStopReplicaRequest(request)
case RequestKeys.UpdateMetadataKey => handleUpdateMetadataRequest(request)
case RequestKeys.ControlledShutdownKey => handleControlledShutdownRequest(request)
case RequestKeys.OffsetCommitKey => handleOffsetCommitRequest(request)
case RequestKeys.OffsetFetchKey => handleOffsetFetchRequest(request)
case RequestKeys.ConsumerMetadataKey => handleConsumerMetadataRequest(request)
case requestId => throw new KafkaException("Unknown api code " + requestId)
}
} catch {
case e: Throwable =>
request.requestObj.handleError(e, requestChannel, request)
error("error when handling request %s".format(request.requestObj), e)
} finally
request.apiLocalCompleteTimeMs = SystemTime.milliseconds
}
说明如下:
| 参数 | 说明 | 对应方法 |
|---|---|---|
| RequestKeys.ProduceKey | producer请求 | ProducerRequest |
| RequestKeys.FetchKey | consumer请求 | FetchRequest |
| RequestKeys.OffsetsKey | topic的offset请求 | OffsetRequest |
| RequestKeys.MetadataKey | topic元数据请求 | TopicMetadataRequest |
| RequestKeys.LeaderAndIsrKey | leader和isr信息更新请求 | LeaderAndIsrRequest |
| RequestKeys.StopReplicaKey | 停止replica请求 | StopReplicaRequest |
| RequestKeys.UpdateMetadataKey | 更新元数据请求 | UpdateMetadataRequest |
| RequestKeys.ControlledShutdownKey | controlledShutdown请求 | ControlledShutdownRequest |
| RequestKeys.OffsetCommitKey | commitOffset请求 | OffsetCommitRequest |
| RequestKeys.OffsetFetchKey | consumer的offset请求 | OffsetFetchRequest |
2.5 Processor响应数据处理
private def processNewResponses() {
var curr = requestChannel.receiveResponse(id)
while(curr != null) {
val key = curr.request.requestKey.asInstanceOf[SelectionKey]
curr.responseAction match {
case RequestChannel.SendAction => {
key.interestOps(SelectionKey.OP_WRITE)
key.attach(curr)
}
}
curr = requestChannel.receiveResponse(id)
}
}
我们回到Processor线程类中,processNewRequest()方法是发送请求,那么会调用processNewResponses()来处理Handler提供给客户端的Response,把requestChannel中responseQueue的Response取出来,注册OP_WRITE事件,将数据返回给客户端。