一、前言
我们在《微服务是在双刃剑 http://www.jianshu.com/p/82ec12651d2d 》中提到了当我们将应用服务化以后,很多在单块系统中能够开展的数据统计和分析业务将会受到很大程度的影响,本文将延续上一篇文章深入分析服务化后,作为后端的数据统计和分析如何做。
注:本文的数据库是基于Oracle数据库
二、服务化后的现状分析
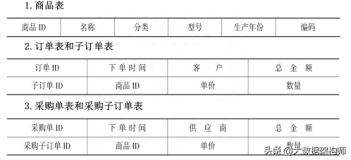
拿一个简单的快捷支付系统为例,服务化后的系统调用图如下所示:
通过上图我们可以看到,单块系统根据业务进行服务化后,每个系统功能单一、职责明确并且独立布署,这只是从系统的角度描述了服务化后的调用关系,那么从微服务的角度讲,还有一点是去中心化,也就是将数据库也按服务进行拆分,下图所示的正是每个服务与其对应的数据库间的关系。
上面我们可以看到,每个服务对应一个数据库,这样从上到下就已经全部拆分开了,再结合康威定律的理论,每个服务由一个团队负责管理,团队之间彼此协作和沟通。
三、数据抽取的技术选型
关于后台的数据统计需求,因为服务化后数据库已经拆分开,于是对后台数据统计造成了一定的困扰,针对这个问题我首先想到的是利用数据库同步来解决,将不同库或者表的数据统一汇总到一起。那么接下来,我将和大家一起逐步探讨和分析。
1、使用Oracle Golden Gate(简称OGG)工具
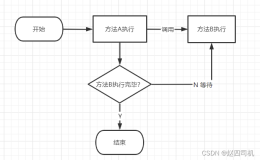
OGG的实现原理是抽取源端的redo log和archive log,然后通过TCP/IP协议投递到目标端,最后解析还原同步到目标端,使目标端实现源端的数据同步,如下图所示:
1.1 使用OGG的优点:
1、对生产系统影响小:实时读取交易日志,以低资源占用实现大交易量数据实时复制。
2、以交易为单位复制,保证交易一致性:只同步已提交的数据。
3、灵活的拓扑结构:支持一对一、一对多、多对一、多对多和双向复制等。
4、可以自定义基于表和行的过滤规则,可以对实时数据执行灵活影射和变换。
1.2 使用OGG需要注意的问题点:
1、在二个库之间做数据同步的时候,如果我们要在表中新加字段,必须要将OGG停下来加字段,然后再启动,新字段同步才会生效。
2、使用OGG做数据同步的时候,工具不是很稳定,经常会出现假死或者退出的情况。
3、OGG偶尔出现在同步过程中丢数据的时候。
2、使用Oracle Logminer
Logminer是oracle从8i开始提供的用于分析重做日志信息的工具,它包括DBMS_LOGMNR和DBMS_LOGMNR_D两个package,后边的D是字典的意思。它既能分析redo log file,也能分析归档后的archive log file。通过LogMiner可以跟踪Oracle数据库的所有DML、DDL和DCL操作。
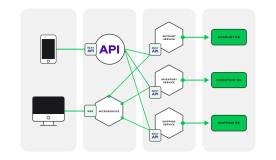
2.1 使用LogMiner进行数据同步的框架图如下所示:
2.2 数据同步流程图如下所示:
同步流程说明::
通过指定源端、目标端数据库信息、LogMiner 同步时间等配置信息,获取源端同步数据。
1、通过定时轮询的方式检测是否到达数据同步时间,如果是则进行数据同步,否则继续进行轮询。
2、定时加载数据库归档日志文件到动态表 v$logmnr_contents 中。
3、根据条件读取指定 sql 语句。
4、执行 sql 语句。
基于JAVA写的LogMiner的数据同步部分核心代码如下所示:
try {
ResultSet resultSet = null;
// 获取源数据库连接
sourceConn = DataBase.getSourceDataBase(); Statement statement = sourceConn.createStatement();
// 添加所有日志文件,本代码仅分析联机日志 StringBuffer sbSQL = new StringBuffer(); sbSQL.append(" BEGIN");
sbSQL.append("
dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"\\REDO01.LOG', options=>dbms_logmnr.NEW);");
sbSQL.append(" dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"\\REDO02.LOG', options=>dbms_logmnr.ADDFILE);");
sbSQL.append(" dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"\\REDO03.LOG', options=>dbms_logmnr.ADDFILE);");
sbSQL.append(" END;");
CallableStatement callableStatement = sourceConn.prepareCall(sbSQL+""); callableStatement.execute();
// 打印获分析日志文件信息
resultSet = statement.executeQuery("SELECT db_name, thread_sqn, filename FROM v$logmnr_logs");
while(resultSet.next()) {
System.out.println("已添加日志文件==>"+resultSet.getObject(3));
}
System.out.println("开始分析日志文件,起始scn号:"+Constants.LAST_SCN);
callableStatement = sourceConn.prepareCall("BEGINdbms_logmnr.start_logmnrstartScn=>'"+Constants.LAST_SCN+"',dictfilename=>'"+Constants.DATA_DICTIONARY+"\\dictionary.ora',OPTIONS =>DBMS_LOGMNR.COMMITTED_DATA_ONLY+dbms_logmnr.NO_ROWID_IN_STMT);END;");
callableStatement.execute();
System.out.println("完成分析日志文件");
// 查询获取分析结果 System.out.println("查询分析结果");
resultSet = statement.executeQuery("SELECT scn,operation,timestamp,status,sql_redo FROM v$logmnr_contents WHERE seg_owner='"+Constants.SOURCE_CLIENT_USERNAME+"' AND seg_type_name='TABLE' AND operation !='SELECT_FOR_UPDATE'");
// 连接到目标数据库,在目标数据库执行redo语句
targetConn = DataBase.getTargetDataBase();
Statement targetStatement = targetConn.createStatement();
String lastScn = Constants.LAST_SCN; String operation = null;
String sql = null;
boolean isCreateDictionary = false; while(resultSet.next()){
lastScn = resultSet.getObject(1)+"";
if( lastScn.equals(Constants.LAST_SCN) ) {
continue;
}
operation = resultSet.getObject(2)+"";
if( "DDL".equalsIgnoreCase(operation) ) {
isCreateDictionary = true;
}
sql = resultSet.getObject(5)+"";
// 替换用户
sql = sql.replace("\""+Constants.SOURCE_CLIENT_USERNAME+"\".", ""); System.out.println("scn="+lastScn+",自动执行sql=="+sql+"");
try {
targetStatement.executeUpdate(sql.substring(0, sql.length()-1));
} catch (Exception e) {
System.out.println("测试一下,已经执行过了"); }
}
// 更新scn
Constants.LAST_SCN = (Integer.parseInt(lastScn))+"";
// DDL发生变化,更新数据字典
if( isCreateDictionary ){
System.out.println("DDL发生变化,更新数据字典");
createDictionary(sourceConn);
System.out.println("完成更新数据字典");
isCreateDictionary = false;
}
System.out.println("完成一个工作单元");
} finally {
if( null != sourceConn ) {
sourceConn.close();
}
if( null != targetConn ) {
targetConn.close();
}
sourceConn = null;
targetConn = null;
}
}
2.3 使用LogMiner做数据同步需要注意的点:
1、LogMiner是针对数据库级别的同步。
2、LogMiner工具的时效性较差,同步延时时间很长。
3、目标库必须与源库版本相同,或者比源库版本更高;目标库与源库字符集一致,或者是源库字符集的超集。
4、源数据库与目标库,必须运行在相同的硬件平台。
5、通过LogMiner方式获取日志的,通过oracle提供工具读取redo日志的信息,然后解析成SQL队列。有些特殊的数据类型,数据的变化是不记录到redo的,比如LOB字段的变化
3、总结
上面二种方案各有优缺点,但是实际工作中更需要同步延时小,同时稳定性极佳并且数据丢失率极低的方案,可以看到这二个方案并不适合做真正的数据抽取工具,来实现一个如下的方案:
在下一文中,我将结合工作实战为大家介绍一款高效的数据库同步工具,最终解决微服务实施中所带来的数据统计的痛点。