
Python数据分析
本文是“五个不容忽视的机器学习项目”一文的续篇。和上篇文章相比,这次选出的项目涉及更多数据科学领域,并且都是GitHub上的开源项目,我们为每个项目都附上了Repo、文档和入门指南的链接,并对每个项目进行了简单介绍。
下面一起来了解一下这些新兴的热门Python库吧,希望本文对你的工作能有所帮助:
1. Auto-Keras自动机器学习库
项目链接:https://github.com/jhfjhfj1/autokeras
文档:http://autokeras.com
入门指南:https://autokeras.com/#example
Auto-Keras是用于自动机器学习(AutoML)的开源软件库。自动机器学习的最终目标是让仅拥有一定数据科学知识或机器学习背景的行业专家可以轻松地应用深度学习模型。Auto-Keras提供了很多用于自动研究深度学习模型架构与超参数的函数。
2. Finetune Scikit-Learn风格的自然语言处理模型微调器
项目链接:https://github.com/IndicoDataSolutions/finetune
文档:https://finetune.indico.io
入门指南:https://finetune.indico.io
Finetune提供了“通过生成式预训练改进对语言的理解”的预训练语言模型,并扩充了OpenAI/finetune-language-model库。
3. GluonNLP - 让自然语言处理变得更简单
项目链接:https://github.com/dmlc/gluon-nlp
文档:http://gluon-nlp.mxnet.io
入门指南: https://github.com/dmlc/gluon-nlp#quick-start-guide
GluonNLP可以使文本处理、数据加载及构建神经模型变得更容易,加快自然语言处理研究的速度。
4. animatplot - 基于Matplotlib的Python动图库
项目链接:https://github.com/t-makaro/animatplot
文档:https://animatplot.readthedocs.io/en/latest
入门指南:https://animatplot.readthedocs.io/en/latest/tutorial/getting_started.html
请注意,本库文档里的例子比较简单,本文引用的是该库在GitHub上列出的功能更全、形式更酷的示例图。
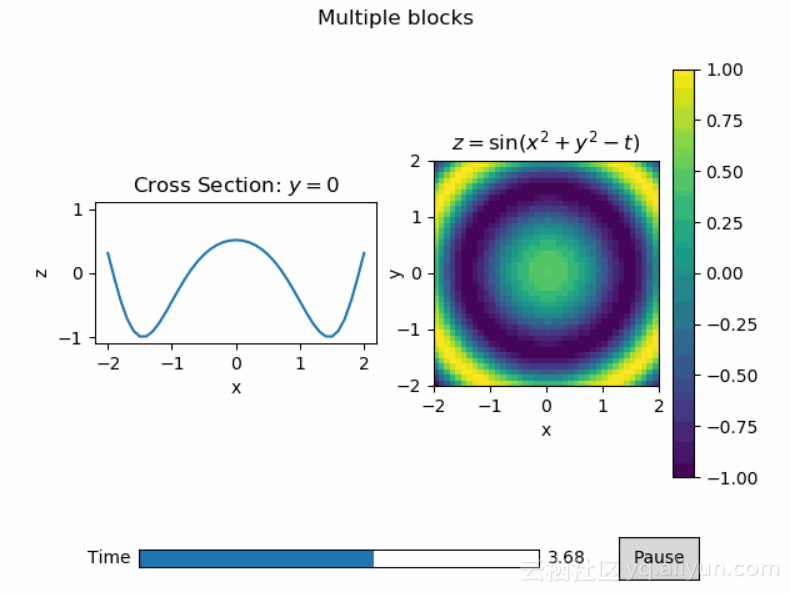
animatplot
5. MLflow - 机器学习生命周期的开源平台
项目链接:https://github.com/mlflow/mlflow
文档:https://mlflow.org/docs/latest/index.html
入门指南:https://mlflow.org/docs/latest/quickstart.html
MLflow是用来管理机器学习整体生命周期的开源平台,这个平台提供了以下主要三个功能:
● MLflow Projects :以可复用、可再现的形式,将机器学习的代码进行打包,以便分享给其他数据科学家或传递给生产环境。
原文发布时间为:2018-09-3
本文作者:Matthew Mayo
本文来自云栖社区合作伙伴“Python爱好者社区”,了解相关信息可以关注“Python爱好者社区”。

