热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
使用 Python 循环创建多个列表
< 每日算法:一文带你认识 “ 双指针算法 ” >
前端UI组件
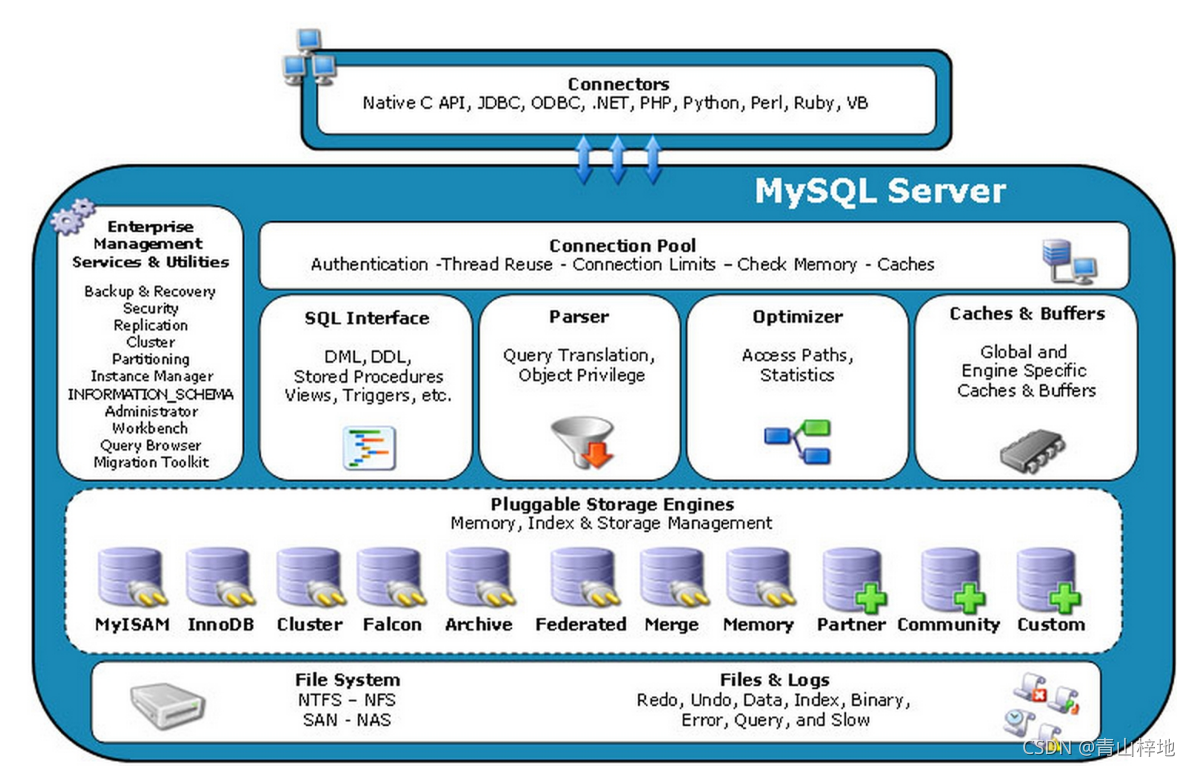
MySQL学习手册(第一部分)
入门篇: 快速升级或迁移您的Confluence知识库
【代码片段】【C++】获取当前时间戳并生成固定格式字符串
云计算数据库应用
详聊Java的四种引用类型
【代码片段】【C++】C++11线程安全单例模式
Python 标准库functools高阶函数用法
字符组的输入输出
Java实现的常用八种排序算法
< 今日小技巧:Axios封装,接口请求增加防抖功能 >
2021年职业院校技能大赛“网络安全”项目 江西省比赛任务书—B模块
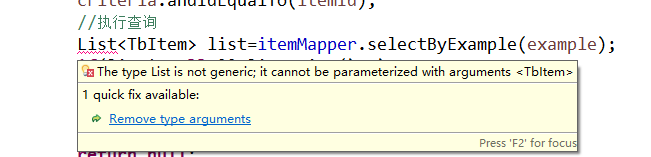
The type List is not generic; it cannot be parameterized with arguments <TbItem>
Linux运维比较实用的工具
MidJourney以图生图的详细教程(含6种案例介绍)(下)
2021年职业院校技能大赛“网络安全”项目 江西省比赛任务书—A模块
MidJourney以图生图的详细教程(含6种案例介绍)(上)
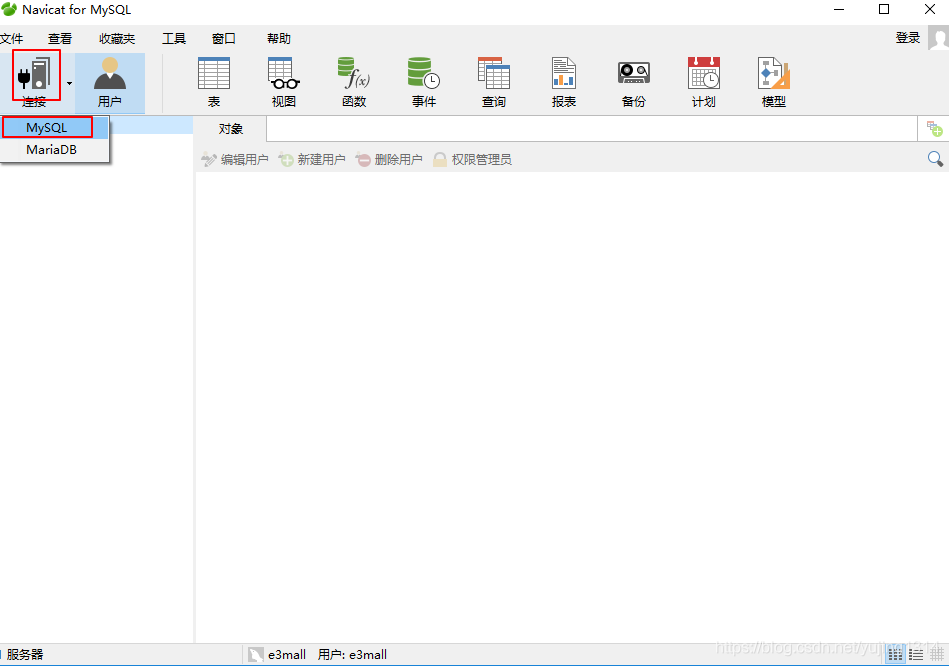
使用Navicate连接Mysql过程详解
python 海龟画图tutle螺旋线
< JavaScript小技巧:如何优雅的用【一行代码 】实现Js中的常用功能 >
Centos7 sendmail服务安装与配置
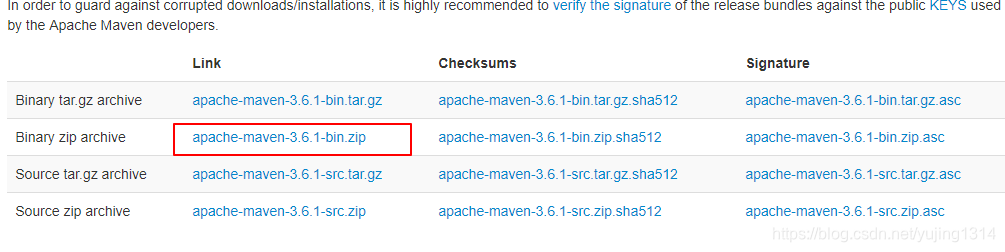
Maven安装配置(Windows10)
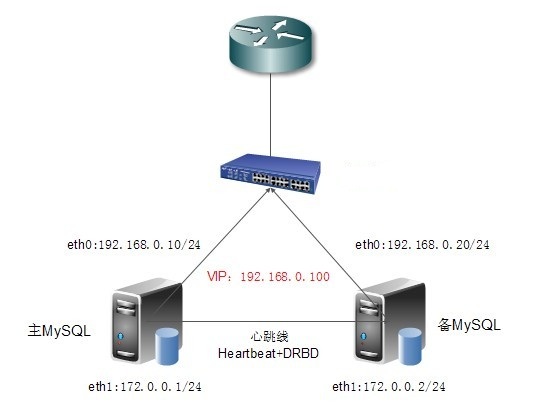
MySQL高可用性之MySQL+DRBD+Heartbeat
< JavaScript技巧:如何优雅的使用 【正则】校验 >
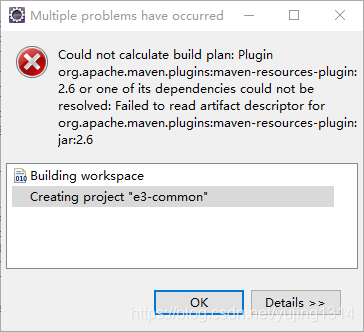
CoreException: Could not get the value for parameter compilerId for plugin execution default-compile
Linux网络配置和操作命令
【代码片段】Linux C++打印当前函数调用堆栈
【运维系列】Centos7安装并配置PXE服务
Go语言入门|包、关键字和标识符
eclipse的详细安装教程
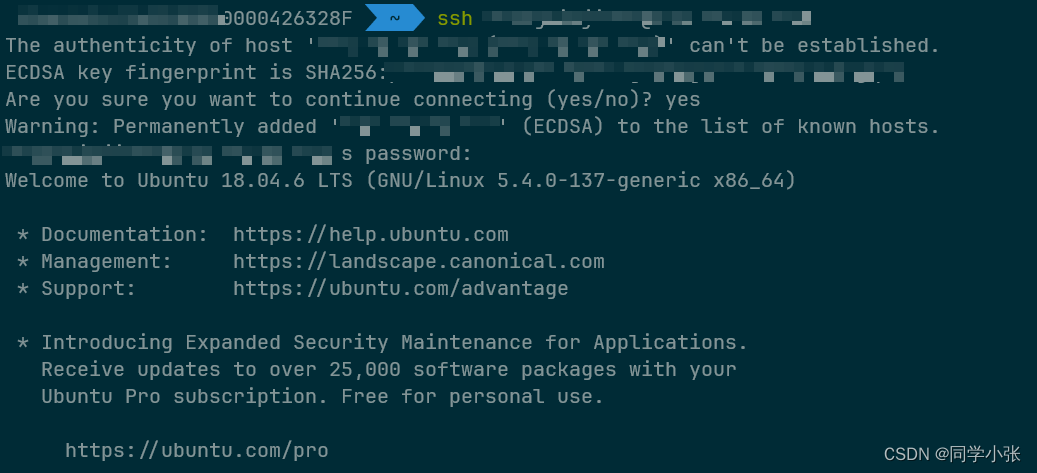
【新人必会】远程开发可视化 - VSCode篇
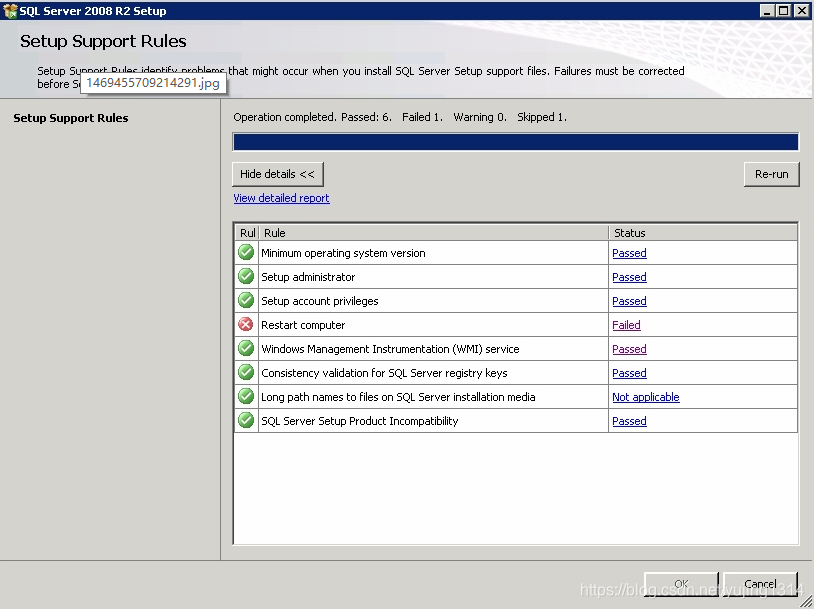
SQL Server2008 安装报错Restart computer failed的解决办法
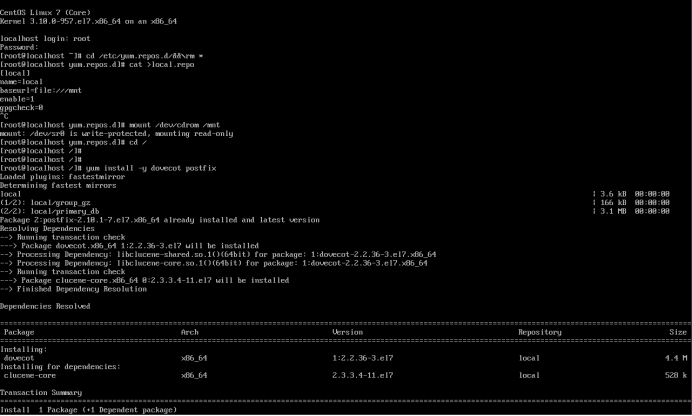
【运维系列】Centos7安装并配置postfix服务
Python 应知应会的Pandas高级操作
Windows11搭建Python环境(Anaconda安装与使用)
ionic4 路由跳转刷新实战
【代码片段】【HTML】弹出对话框点选加载文件
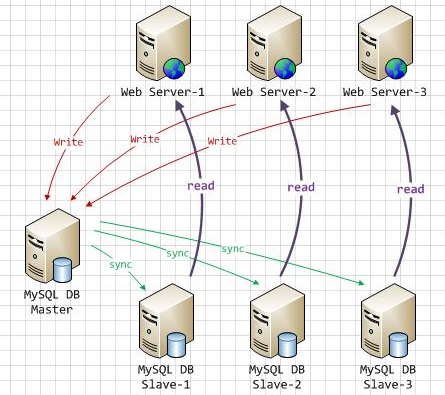
MySQL-Proxy实现MySQL读写分离提高并发负载
vscode + springboot + HTML 搭建服务端(二)
vscode + springboot + HTML 搭建服务端(一)
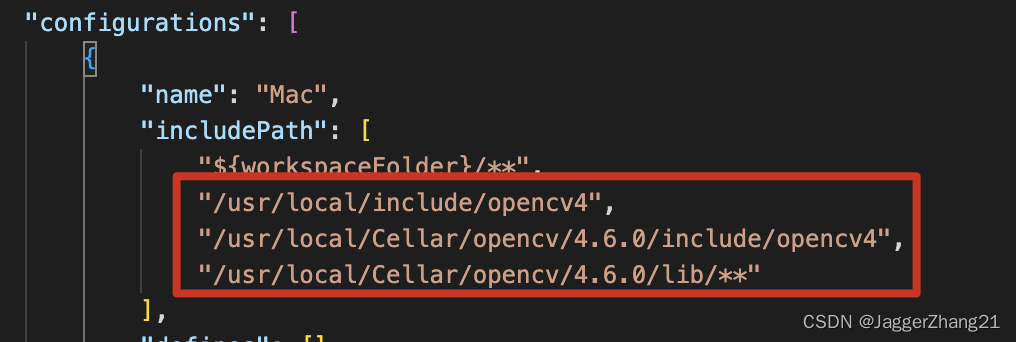
Mac系统下vscode调试opencv环境搭建
【Vue】小例子入门以及生命周期探讨
Mac上pyCharm找不到已安装的库
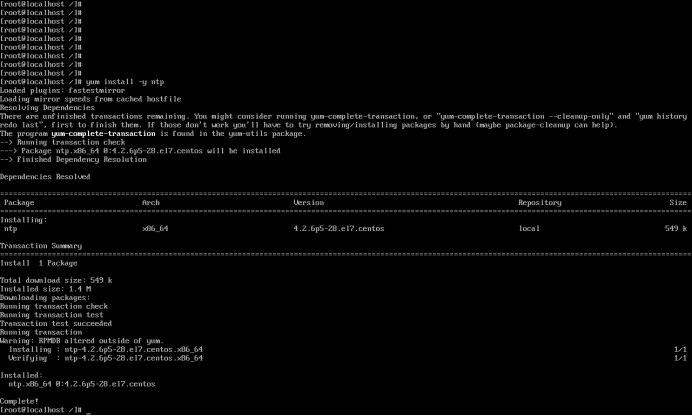
【运维系列】Centos7安装配置ntp服务